- The paper presents a new benchmark evaluating high-order ToM with up to fourth-order questions using deceptive agent communications to rigorously test LLMs.
- It applies both Vanilla and chain-of-thought prompting, highlighting the limitations of current LLMs in handling recursive and multi-step reasoning.
- Error analysis reveals recurring issues like commonsense lapses and hallucinations, suggesting future directions for integrating intuitive and logical reasoning.
Theory of Mind (ToM) in LLMs: HI-TOM Benchmark
HI-TOM is an initiative aimed at evaluating the Theory of Mind (ToM) abilities of LLMs. ToM refers to the cognitive capacity to understand others' mental states, such as beliefs and intentions. HI-TOM provides a framework for testing higher-order ToM, extending beyond the more commonly explored first- and second-order ToM. This benchmark facilitates assessing how current LLMs handle complex recursive reasoning tasks involving agent dynamics and intentional deception.
Background and Dataset Design
Theory of Mind is instrumental in assessing intelligence and understanding language, as well as socio-cognitive functionalities. Previously, most studies have restricted their scope to first- and second-order ToM due to the lack of data complexity required for higher-order operations. HI-TOM fills this gap with a dataset that incorporates up to fourth-order ToM questions while integrating elements of deception and agent communication, thus providing a more robust testing ground for LLMs.
HI-TOM stories comprise fundamental components such as agents, objects, containers, and rooms, and they are structured into chapters. These narratives mimic realistic scenarios with embedded agent communications, either public or private, allowing for diverse questioning from direct reality to multi-level belief attributions.
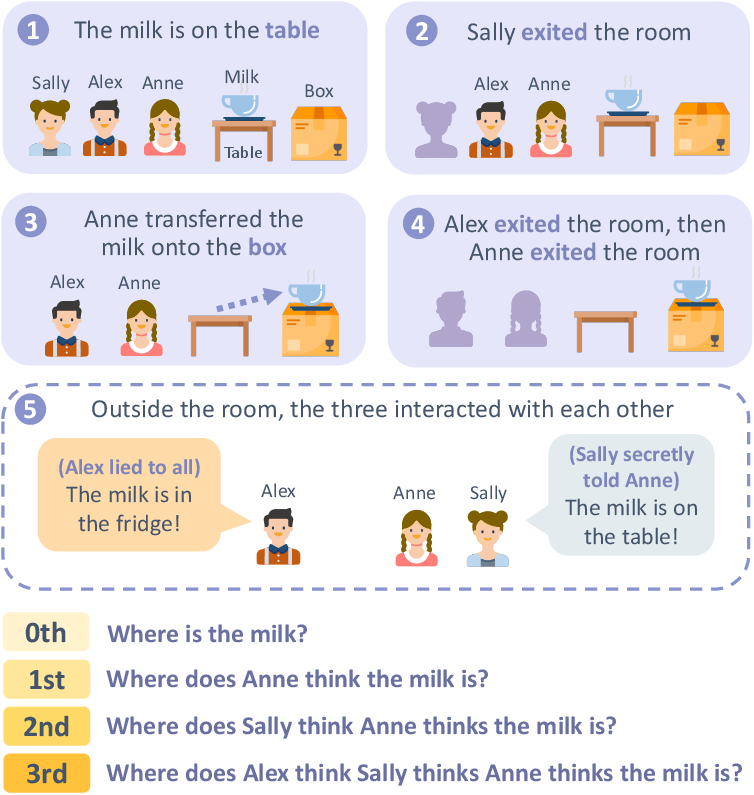
Figure 1: A sample from Hi-ToM dataset, which contains communications among agents, and questions that address 0-th (reality) to 3-rd ToM reasoning.
Evaluating LLMs
The benchmark was used to assess popular LLMs like GPT-4, GPT-3.5-turbo, Claude-instant, and Guanaco 65B through zero-shot evaluations using two prompting styles: Vanilla Prompting (VP) and Chain-of-Thought Prompting (CoTP). Two key performance metrics are utilized: standard accuracy and joint accuracy. Joint accuracy only credits higher-order questions if all previous lower-order ones in the same story are correct.
From the experiments, LLM performance on HI-TOM is vastly limited on higher-order ToM, especially as tasks require recursive multi-step reasoning. The added complexity of deception in communications significantly further reduces the models' effective reasoning capabilities.
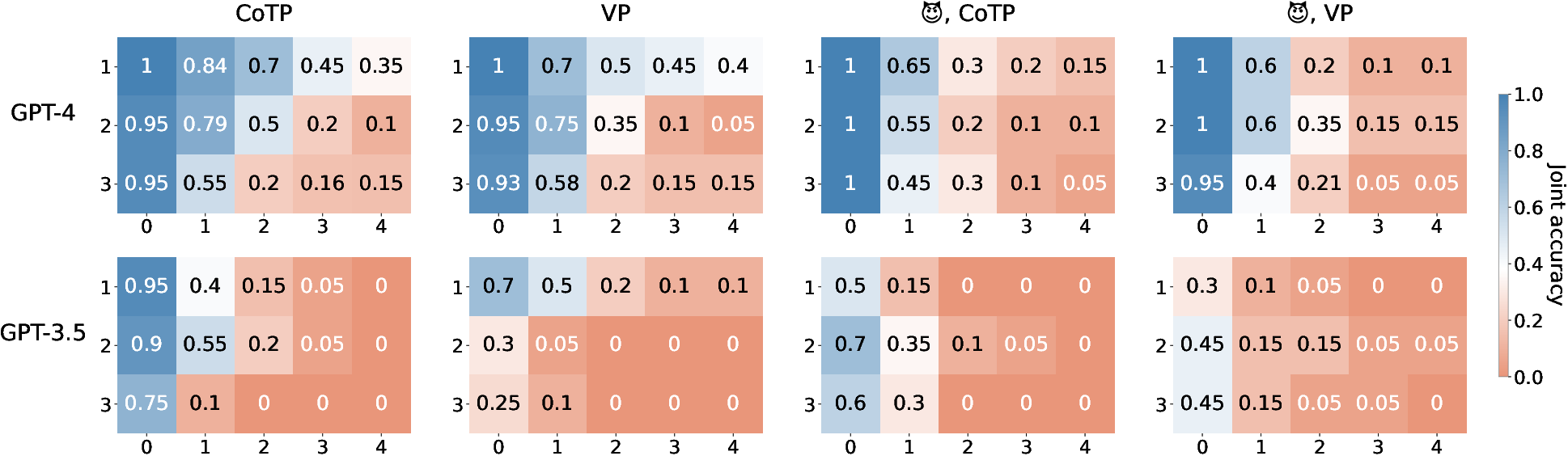

Figure 2: Joint accuracy of GPT-4 and GPT-3.5 on Hi-ToM stories w/ or w/o deceptive agent communications. The x-axis stands for ToM orders, and the y-axis is for story lengths (number of chapters). CoTP and VP respectively represent chain-of-thought and multiple-choice-w/o-explanation prompting styles.
Error Analysis and Future Directions
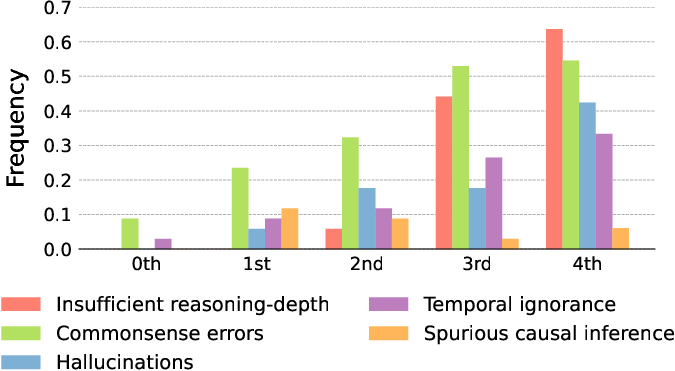
In-depth analysis of LLM responses highlighted frequent errors:
These findings underscore the need for novel approaches integrating both intuitive (System 1) and logical (System 2) reasoning processes and highlight challenges in applying lessons from human intelligence to artificial models. Future research should also address the limitations of current datasets and the necessity for LLMs to adapt to nuanced real-world interactions.
Conclusion
HI-TOM benchmark serves as a crucial tool in evaluating and ultimately improving the ToM capabilities of LLMs. Current LLMs underperform in higher-order ToM reasoning, indicating room for advancement in model architecture and training methodologies to bridge gaps between artificial and human cognitive processes. Future directions should focus on enhancing ToM faculties, drawing inspiration from human intelligence models, and broadening NLP applications through better understanding and integration of nuanced human interactivity.