studentSplat: Your Student Model Learns Single-view 3D Gaussian Splatting
Abstract: Recent advance in feed-forward 3D Gaussian splatting has enable remarkable multi-view 3D scene reconstruction or single-view 3D object reconstruction but single-view 3D scene reconstruction remain under-explored due to inherited ambiguity in single-view. We present \textbf{studentSplat}, a single-view 3D Gaussian splatting method for scene reconstruction. To overcome the scale ambiguity and extrapolation problems inherent in novel-view supervision from a single input, we introduce two techniques: 1) a teacher-student architecture where a multi-view teacher model provides geometric supervision to the single-view student during training, addressing scale ambiguity and encourage geometric validity; and 2) an extrapolation network that completes missing scene context, enabling high-quality extrapolation. Extensive experiments show studentSplat achieves state-of-the-art single-view novel-view reconstruction quality and comparable performance to multi-view methods at the scene level. Furthermore, studentSplat demonstrates competitive performance as a self-supervised single-view depth estimation method, highlighting its potential for general single-view 3D understanding tasks.
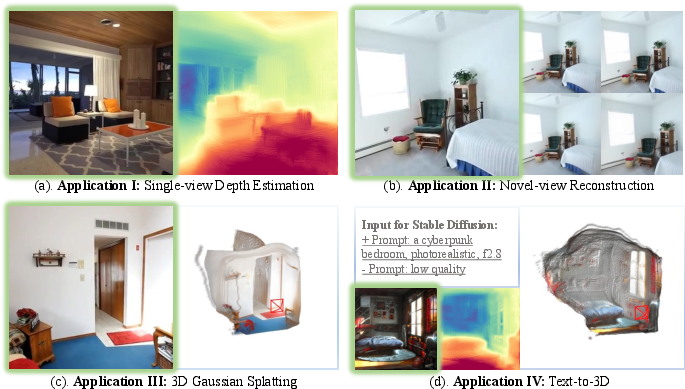









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces studentSplat, a computer method that builds a 3D scene from just one picture. It uses a smart trick: during training, it learns from a “teacher” that sees multiple pictures of the same place, so later the “student” can handle a single picture on its own. The method represents 3D scenes using lots of tiny, soft, colored blobs called “3D Gaussians,” which together form the shape and look of the scene.
Key Questions the Paper Asks
- How can we reconstruct a full 3D scene from only one image, without needing the camera’s position or lots of 3D labels?
- How do we fix two big problems with single-image 3D: 1) Scale ambiguity: from one picture, you can’t tell if something is small and close or big and far. 2) Extrapolation: one picture can’t show what’s behind walls or outside the frame, so how do we “fill in” missing areas without warping the 3D shape?
How the Method Works (In Simple Terms)
Think of the method as two helpers and one main learner:
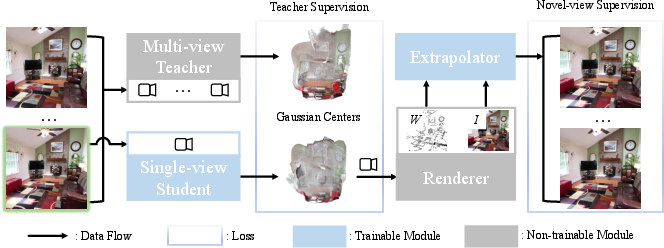
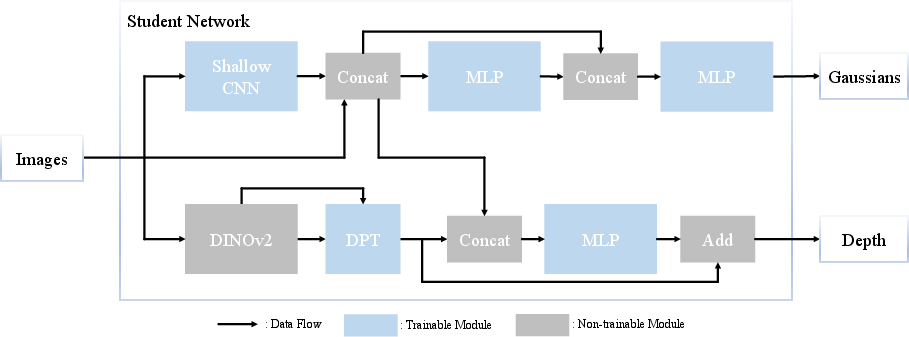
- The student: a model that takes one image and produces a 3D scene made of many tiny, semi-transparent blobs (the “3D Gaussians”). These blobs have positions, sizes, colors, and how see-through they are.
- The teacher: another model trained with multiple images of the same scene. It can figure out more reliable 3D structure (even if only “up to scale,” meaning it knows the shape but not the absolute size). During training, the teacher gives the student guidance on where the 3D blobs should go.
- The extrapolator: a small network that “fills in” parts of new viewpoints that weren’t visible in the original picture, so the student doesn’t bend or stretch the 3D blobs in bad ways just to match missing pixels.
Here are the two main ideas:
- Teacher–Student Training
- Analogy: A coach (teacher) watches the game from multiple cameras and gives the player (student) correct tips about where to stand.
- The teacher looks at several images of the same scene to estimate 3D points. The student, seeing only one image, tries to match the teacher’s 3D structure. This reduces “scale confusion” and keeps the 3D shape realistic.
- Extrapolation Without Distortion
- Analogy: If you take a single photo of a room and then turn your head in VR, you’ll see areas the photo didn’t capture. Instead of stretching the visible parts to cover the unknown areas, the extrapolator paints in the missing regions.
- The method also builds a “confidence mask” that says which pixels are well-supported by the 3D blobs and which are guessed. This way, the system learns to keep the real 3D parts solid and lets the extrapolator handle the unknown parts, avoiding warped, “jelly-like” shapes.
A helpful analogy for 3D Gaussians: imagine building a 3D scene from lots of tiny, colored fog balls. When you look from any angle, the system renders the view by adding up how these fog balls overlap, giving you a realistic picture of the scene.
Main Findings and Why They Matter
- Better single-image 3D scenes: studentSplat outperforms other single-view methods on common tests, producing clearer and more accurate new views of scenes from a single photo.
- Close to multi-view quality: Even though it uses only one image at test time, its results are surprisingly close to methods that require two or more images.
- Fewer distortions: Thanks to the extrapolator and the confidence mask, it avoids the common problem where models stretch or smear the 3D shape at the edges of the visible area.
- Good at depth from one image: It also works well as a self-supervised depth estimator (figuring out how far things are), performing similarly to strong depth-only methods—without needing ground-truth 3D data.
Why it’s important:
- Making 3D from one picture is useful for AR/VR, robotics, navigation, and creating 3D content quickly.
- Not needing camera poses or 3D labels makes it much easier and cheaper to use in the real world.
- It can plug into text-to-image tools (like Stable Diffusion): generate an image from text, then turn that single image into a 3D scene.
What This Could Change
- Easier 3D creation: Designers, game developers, and hobbyists could turn single photos into explorable 3D scenes more reliably.
- Better understanding from one view: Robots and phones could learn depth and scene structure from just one shot, helping with tasks like obstacle avoidance or scene labeling.
- A bridge between fields: The approach connects modern 3D “splatting” techniques with classic single-image vision tasks, opening the door to better segmentation or scene understanding from a single image.
Limitations and future work:
- The student learns from a teacher that uses multiple views during training, so it inherits some teacher limitations.
- Single-image 3D is still harder than multi-view 3D, so there’s room to improve sharpness and detail.
- Bigger models and better extrapolation (for example, diffusion-based inpainting) could make results even more realistic.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to enable actionable follow-up research:
- Absolute metric scale remains unresolved: the student operates on a relative scale inherited from the teacher. Methods to recover or predict metric scale at inference (e.g., learning scene priors, leveraging known object sizes, monocular calibration, or weak geodesic cues) are not explored.
- Dependence on a multi-view teacher during training: how to eliminate or reduce teacher reliance (e.g., teacher-free self-supervision, cycle-consistency across synthetic views, generative 3D priors, or pseudo-labeling with uncertainty) and quantify how teacher errors propagate to the student is not addressed.
- No uncertainty modeling for teacher-student supervision: the framework lacks confidence/uncertainty maps to weight geometric and photometric losses; strategies to estimate and exploit uncertainty (from both teacher and student) are missing.
- Extrapolator context mask quality is unevaluated: there is no quantitative assessment of the accuracy of the learned visibility/context mask
W(e.g., against ground-truth visibility or SfM visibility proxies), nor error modes whenWmisclassifies regions. - Risk of
Wcollapse or misallocation is only argued qualitatively: formal constraints, regularizers (e.g., entropy or sparsity), or proofs ensuring non-trivialWand correct gradient routing are absent. - Inpainting “cheating” vs. true geometry is not disentangled: the extrapolator
gcan reduce photometric loss without improving geometry. Geometry-only metrics and controlled experiments to separate inpainting gains from genuine 3D improvements are needed. - Supervision is limited to Gaussian centers: the student’s covariance, opacity, and color are not geometrically regularized. Losses/priors for covariance shape consistency, normal alignment, opacity/transmittance regularization, and view-dependent appearance are not investigated.
- Camera pose/intrinsics at inference remain under-specified: while relative poses are not required, practical control over novel viewpoints (with unknown intrinsics/extrinsics) and calibration-free rendering is not fully defined or evaluated.
- Sampling strategy for extrapolated targets is unspecified: the distribution, difficulty, and curriculum for target views outside the input frustum—and their impact on training stability and generalization—are not analyzed.
- Photometric-centric evaluation overlooks geometry fidelity: lack of geometry metrics (e.g., Chamfer against LiDAR/SfM reconstructions, depth RMSE, surface normal accuracy, plane consistency, multi-view consistency scores) limits conclusions about 3D validity.
- Depth estimation scale alignment is unclear: protocols for aligning predicted relative depth to metric ground truth (or learning metric depth) are not fully detailed; comparisons to monocular metric depth methods and scale-recovery strategies are missing.
- Limited domain coverage: tests exclude dynamic/non-rigid scenes, moving objects, and challenging materials (specular, transparent). Extensions to dynamic scenes with temporal coherence and view-dependent appearance in 3DGS remain unexplored.
- Robustness to input degradations is untested: effects of noise, blur, compression, exposure changes, lens distortions, extreme FOV (fisheye), and unknown intrinsics on reconstruction quality and
Waccuracy are not evaluated. - Scalability to high resolutions and large scenes is not quantified: memory/time trade-offs, Gaussian density allocation, multi-scale representations, and runtime vs. quality benchmarks (training/inference) are absent.
- Hyperparameter sensitivity is not studied: there is no systematic analysis of loss weights (e.g.,
λ_geo,λ_grad,λ_lpips,λ_l2), their robustness across datasets, or adaptive weighting schemes. - Teacher-student coordinate alignment and drift: strategies for canonicalization, normalization, or cross-scene consistency to avoid scale/orientation drift are not provided or measured.
- Visibility proxy via opacity (alpha compositing) may fail: cases where opacity is an unreliable proxy for missing context (e.g., semi-transparent, reflective, or thin structures) are not analyzed; alternative visibility estimators (e.g., accumulated transmittance, depth-based occlusion) are not explored.
- Integration of richer priors for occluded geometry is missing: semantic or generative 3D priors that could predict plausible geometry in unseen regions are not incorporated or evaluated.
- Teacher-refine pipeline (Appendix) lacks rigorous evaluation: quantitative gains, computational cost, stability, and convergence properties of the iterative student→fake views→teacher refinement loop are not reported.
- Text-to-3D scene generation integration is only demonstrated qualitatively: there is no quantitative evaluation (e.g., layout consistency, scale plausibility, user studies), nor controls for semantics, scale, or scene structure when using diffusion-generated inputs.
- Fairness of comparisons under differing Gaussian counts/resolutions is limited: single-view methods render fewer Gaussians than multi-view baselines; matched-Gaussian or resolution-normalized comparisons are not provided.
- Failure case taxonomy is limited: systematic characterization of common errors (e.g., scale drift, jelly distortions at context borders, misplacement in extrapolated regions), their correlation with scene attributes, and targeted mitigations are not included.
- Safety and downstream reliability are not addressed: confidence calibration and fail-safe detection for robotics/navigation use are not provided, especially in extrapolated or low-confidence regions.
- Data and benchmark expansion are needed: broader, public benchmarks for single-view scene-level 3DGS (with visibility labels, geometry proxies, dynamic content, and extreme viewpoints) would enable more comprehensive evaluation and progress.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now, drawing directly from the paper’s findings and released techniques.
- Single‑photo 3D scene previews for real estate and e‑commerce (sectors: real estate, retail, media)
- What: Generate approximate 3D walkthroughs or product-view experiences from a single listing or catalog photo, including out-of-frustum regions via the extrapolator.
- Tools/workflows: Image-to-3D Gaussian Splat API; web viewer using 3DGS rasterization; integration into listing CMS; “studentSplat + Stable Diffusion” pipeline for staged rooms or product scenes.
- Assumptions/dependencies: Non-metric scale unless calibrated; performance best on indoor/outdoor scenes similar to RE10K/ACID; image resolution may need upscaling; extrapolator quality influences plausibility in occluded areas.
- Mobile “3D photo” parallax and novel-view effects (sectors: consumer software, social media, smartphones)
- What: Create interactive parallax, depth-of-field, and slight viewpoint changes from a single photo for feed posts, stories, and galleries.
- Tools/workflows: On-device feed-forward student model to produce depth and 3D splats; lightweight extrapolator to fill missing context; mask W to limit view shifts to confident regions.
- Assumptions/dependencies: Scale ambiguity acceptable for visual effects; device inference constraints; ensure user-visible areas fall within higher-opacity mask W.
- Rapid scene blockout from concept art and generated images (sectors: gaming, VFX, design)
- What: Convert a single concept frame or a Stable Diffusion image into a 3DGS scene for previsualization, level layout, and set design.
- Tools/workflows: DCC plugins (Blender/Unity/Unreal) that import 3D splats; “text-to-image → studentSplat” workflow; optional teacher-refine pass to clean artifacts using pseudo-views.
- Assumptions/dependencies: Non-metric reconstructions; extrapolated regions may need artist pass; lower sharpness vs multi-view assets due to fewer Gaussians.
- Robotics perception fallback from single frames (sectors: robotics, automation)
- What: Obtain single-view depth maps and uncertainty (via opacity/alpha mask W) for navigation or manipulation when multi-view or SLAM is unavailable.
- Tools/workflows: Perception stack module: camera frame → studentSplat depth + W → planner filters low-confidence areas; optional fusion with IMU or wheel odometry for scale.
- Assumptions/dependencies: Relative (not metric) scale unless calibrated; caution in safety-critical contexts; teacher model’s training domain should match deployment scenes.
- Interactive product spins from one image (sectors: retail, marketing)
- What: Approximate 360° product views or minor viewpoint changes from a single shot.
- Tools/workflows: Web 3D viewer with 3DGS; mask W to constrain user rotations; optional differential diffusion for high-quality inpainting guided by W.
- Assumptions/dependencies: Works best for rigid products and uncluttered backgrounds; risk of hallucinations in unseen sides.
- Previs/set layout for film and VFX (sectors: media, entertainment)
- What: Quick 3D reconstructions from storyboard frames or scouting photos to plan camera moves and blocking.
- Tools/workflows: Pipeline node producing splats and depth; W-guided extrapolation to inform feasible camera paths; export to scene graph for previs tools.
- Assumptions/dependencies: Non-metric geometry; cinematographers should validate extrapolated areas.
- Academic use as a baseline for single-view 3D and depth (sectors: academia, education)
- What: Teach and study scale ambiguity, teacher-student supervision, gradient-matching in 3D, and extrapolation strategies.
- Tools/workflows: Open training scripts with multi-view teacher and single-view student; assignments demonstrating mask W utility and failure modes.
- Assumptions/dependencies: Access to datasets similar to RE10K/ACID; reproducible training environment.
- Pseudo-depth generation for unlabeled datasets (sectors: AI/data engineering)
- What: Create self-supervised depth labels and confidence masks for downstream tasks (e.g., monocular depth fine-tuning, segmentation pretraining).
- Tools/workflows: Batch inference over image corpora → store depth + W; filter out low-confidence pixels for training.
- Assumptions/dependencies: Labels are relative scale; downstream tasks must be robust to pseudo-label noise.
- Photogrammetry pipeline bootstrap when poses are missing (sectors: mapping, AR)
- What: Initialize geometry from a single image before pose recovery, reducing cold-start issues.
- Tools/workflows: Generate pseudo-novel views using fake poses → run teacher-refine or SfM variants; use W to prune unreliable regions.
- Assumptions/dependencies: Later stages must recover metric scale; teacher-refine assumes teacher outperforms student.
- Privacy and policy assessment demos (sectors: policy, cybersecurity)
- What: Illustrate how single images can yield reconstructive 3D views of private spaces, informing privacy guidelines and disclosure.
- Tools/workflows: Policy demos showing reconstruction breadth and limitations; W-based uncertainty visualization to contextualize risk.
- Assumptions/dependencies: Ethical review; consent for demo data; communicate limitations to avoid overconfidence.
Long‑Term Applications
These use cases require further research, scaling, or engineering beyond the current prototype (e.g., higher resolution, metric scale, broader domain coverage, or mature extrapolation).
- Text‑to‑3D scene generation platforms (sectors: creative tools, VR/AR)
- What: From a text prompt, generate an image (diffusion) and lift it into a consistent 3DGS scene; iterate with W-guided differential diffusion for high-quality out-of-view synthesis.
- Tools/products: End-to-end “Prompt → Image → 3DGS → VR scene” editors; asset stores of splat-based worlds; creator SDKs.
- Assumptions/dependencies: Stronger extrapolators (diffusion with geometry priors); large-scale training on diverse scenes; consistency and lighting control.
- Metric reconstruction for architecture and interior design (sectors: AEC)
- What: Produce dimensional estimates and 3D layout from a single photo to accelerate quoting, remodeling, and space planning.
- Tools/workflows: Scale calibration using known camera intrinsics, AR markers, or known object priors; post-optimization to metric depth; CAD conversion from splats.
- Assumptions/dependencies: Accurate intrinsics/EXIF; robust scale recovery; domain adaptation to indoor scenes; safety margins for measurements.
- Enhanced semantic segmentation and scene understanding via single-view geometry (sectors: computer vision, autonomous systems)
- What: Use studentSplat depth and local 3D gradients for geometric cues that improve segmentation and affordance detection in monocular settings.
- Tools/workflows: Multi-task training with depth + segmentation targets; plug-in geometry heads; W to mask unreliable pixels during training.
- Assumptions/dependencies: Joint training pipelines; better 3D-aware losses; diverse domain coverage.
- Accessibility and AR navigation (sectors: healthcare, mobility, assistive tech)
- What: Single-frame 3D understanding for obstacle awareness and path hints, running on mobile devices or wearables.
- Tools/workflows: Edge inference with student model; fusion with IMU/GPS for scale; W-driven user feedback (e.g., “uncertain area ahead”).
- Assumptions/dependencies: Reliability thresholds for assistive use; real-world calibration; robust performance in diverse lighting/weather.
- Monocular depth enhancements for autonomous driving (sectors: automotive)
- What: Complement multi-view systems with robust single-frame depth and uncertainty during sensor degradation or sparse views.
- Tools/workflows: Perception fusion module using W for downstream filters; retraining on driving datasets; calibration for metric scale.
- Assumptions/dependencies: Safety validation; harsh domain generalization (night, rain, motion blur); high-resolution inference.
- Cultural heritage and GIS reconstructions from archival photos (sectors: public sector, museums, geospatial)
- What: Lift historical single images into approximate 3D scenes for educational experiences and urban change studies.
- Tools/workflows: Archive ingestion pipeline; W-guided expert curation; alignment to modern maps via landmarks.
- Assumptions/dependencies: Non-metric geometry; significant extrapolation needed; domain gaps (film scans, aging artifacts).
- Real-time, on-device single-view 3DGS (sectors: mobile silicon, XR)
- What: Hardware-accelerated inference pipelines for splat generation and rendering with efficient extrapolation.
- Tools/workflows: GPU/NPUs with specialized kernels; quantization of student/extrapolator networks; streaming splat updates.
- Assumptions/dependencies: Model compression; memory bandwidth; energy constraints.
- Synthetic data generation for training perception models (sectors: AI/ML tooling)
- What: From single images, generate multiview-like datasets (novel views + depth) to augment training corpora.
- Tools/workflows: Batch synthesis with W gating; curriculum learning favoring high-confidence pixels; domain randomization via diffusion.
- Assumptions/dependencies: Bias and artifacts management; validation against real multiview data.
- Safety-aware teleoperation in robotics (sectors: industrial robotics)
- What: Approximate 3D from a single operator snapshot to visualize remote workcells; W highlights uncertain regions to avoid risky maneuvers.
- Tools/workflows: Teleop UI overlays of depth and uncertainty; optional teacher-refine when additional images become available.
- Assumptions/dependencies: Conservative thresholds; operator training; gradual handoff to multi-view sensors when possible.
Cross-cutting assumptions and dependencies
- Scale ambiguity: Outputs are up to a relative scale; metric applications require calibration (intrinsics, fiducials, known object sizes, or sensor fusion).
- Extrapolation quality: The feed-forward extrapolator suffices for guidance but high-fidelity synthesis may need diffusion-based methods; accuracy of mask W is pivotal.
- Domain generalization: Best performance is on scenes similar to training datasets (RE10K, ACID); deploying to novel domains (e.g., automotive, aerial) requires fine-tuning.
- Resolution and sharpness: Single-view produces fewer splats than multi-view; production systems may need super-resolution or multi-pass refinement.
- Teacher dependence: Training inherits teacher limitations; future work can reduce this reliance or improve teacher robustness.
- Ethics and safety: Single-image reconstructions can hallucinate; applications should expose uncertainty (mask W), include disclaimers, and avoid high-stakes decisions without validation.
Glossary
- 3D Gaussian splatting (3DGS): A scene representation that models geometry and appearance using many 3D Gaussian primitives, enabling fast differentiable rendering. "3D Gaussian splatting"
- Alpha compositing: A blending technique that uses per-pixel opacity to combine layers, here used to estimate visible versus missing context in rendered views. "alpha compositing of the 3DGS"
- Camera projection matrix: The matrix mapping 3D points to the 2D image plane, combining camera intrinsics and extrinsics. "camera projection matrices"
- Camera view frustum: The 3D volume of space visible to a camera given its pose and intrinsics; used to bound novel views. "input view frustums"
- Cost-volume: A 3D tensor of matching costs over depth/disparity used to aggregate multi-view correspondences for geometry. "incorporated cost-volume to improve both efficiency and performance"
- Cross-view feature matching: Matching visual features across different camera views to establish correspondences for 3D estimation. "cross-view feature matching can be performed"
- Differentiable rendering: Rendering whose operations are differentiable, allowing gradients to optimize 3D representations end-to-end. "the efficient differentiable rendering implementation of 3DGS enables direct optimization of point clouds (3D Gaussians)"
- Differential diffusion: A diffusion-based generative technique referenced for potential extrapolation with differentiable components. "such as differential diffusion~\citep{levin2023differential}"
- Extrapolation: Predicting or filling content outside the observed regions or camera frustums, required when supervising from a single view. "single-view 3D reconstruction inevitably needs to extrapolate"
- Extrapolation network (Extrapolator): A network that completes missing scene context in rendered views to guide losses and reduce distortion. "an extrapolation network that completes missing scene context"
- Geometric supervision: Training signals that enforce correct 3D structure (e.g., Gaussian centers) rather than just image appearance. "provides geometric supervision to the single-view student during training"
- Gradient matching: A regularization that aligns spatial gradients of predicted geometry (e.g., Gaussian centers) between teacher and student. "we match the gradients of the teacher and student Gaussian centers"
- Learned Perceptual Image Patch Similarity (LPIPS): A perceptual distance metric computed from deep features to assess image similarity. "Learned Perceptual Image Patch Similarity"
- Neural Radiance Field (NeRF): A neural representation that models radiance as a function of position and view direction, learned from multi-view images. "Neural Radiance Field (NeRF) is proposed to learn a view-based rendering function from multi-view supervision"
- Novel-view reconstruction loss: The objective comparing rendered novel views to target images, central to view-synthesis training. "novel view reconstruction loss"
- Peak Signal-To-Noise Ratio (PSNR): A pixel-level metric measuring reconstruction fidelity relative to ground-truth images. "Peak Signal-To-Noise Ratio (PSNR)"
- Photometric supervision: Training signals derived from image intensities/appearance (e.g., L2, LPIPS) rather than explicit 3D annotations. "novel views to provide photometric supervision"
- Rastrizer: The rasterization module that converts 3D Gaussian parameters into a 2D rendered image. "Rastrizer(\mathbf{P}j|\bm{\mu}i, \alphai, \bm{\Sigma}i, \bm{c}i)"
- Scale ambiguity: The inability to determine absolute scene scale from single-view data without additional constraints. "scale ambiguity"
- Single-view depth estimation: Estimating depth from one image, often trained with self-supervised photometric cues instead of ground-truth depth. "self-supervised single-view depth estimation"
- Structural Similarity Index Measure (SSIM): A perceptual metric that evaluates image similarity based on structural information. "Structural Similarity Index Measure (SSIM)"
- Structure from Motion (SfM): A pipeline that recovers camera poses and 3D structure from multiple images via feature matching and optimization. "Structure from motion algorithm"
- Triangulation: Recovering 3D points by intersecting rays from multiple camera views based on matched features. "cross-view feature matching and triangulation"
Collections
Sign up for free to add this paper to one or more collections.