WEAVE: Unleashing and Benchmarking the In-context Interleaved Comprehension and Generation
Abstract: Recent advances in unified multimodal models (UMMs) have enabled impressive progress in visual comprehension and generation. However, existing datasets and benchmarks focus primarily on single-turn interactions, failing to capture the multi-turn, context-dependent nature of real-world image creation and editing. To address this gap, we present WEAVE, the first suite for in-context interleaved cross-modality comprehension and generation. Our suite consists of two complementary parts. WEAVE-100k is a large-scale dataset of 100K interleaved samples spanning over 370K dialogue turns and 500K images, covering comprehension, editing, and generation tasks that require reasoning over historical context. WEAVEBench is a human-annotated benchmark with 100 tasks based on 480 images, featuring a hybrid VLM judger evaluation framework based on both the reference image and the combination of the original image with editing instructions that assesses models' abilities in multi-turn generation, visual memory, and world-knowledge reasoning across diverse domains. Experiments demonstrate that training on WEAVE-100k enables vision comprehension, image editing, and comprehension-generation collaboration capabilities. Furthermore, it facilitates UMMs to develop emergent visual-memory capabilities, while extensive evaluations on WEAVEBench expose the persistent limitations and challenges of current approaches in multi-turn, context-aware image generation and editing. We believe WEAVE provides a view and foundation for studying in-context interleaved comprehension and generation for multi-modal community.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces weaveW, a project that helps AI models understand and create images in a realistic, multi-step way—like how people edit pictures or make comics over several rounds. It builds:
- A big training dataset with many “multi-turn” examples (where text and images are mixed over several steps).
- A carefully designed test set (benchmark) to check if models can remember past images, follow editing instructions over time, and use world knowledge.
The main idea: real image creation isn’t one-and-done. You tweak, change, and sometimes undo edits while keeping characters, styles, and scenes consistent. weaveW teaches and tests AI to do exactly that.
Objectives: What questions does the paper try to answer?
The paper focuses on three simple questions:
- Can AI models handle multi-step image editing and generation, not just single quick edits?
- Can they remember important visual details from earlier steps (like a character’s clothes or the scene’s lighting)?
- Can they use world knowledge and follow complex instructions across several rounds to keep everything consistent?
Methods: How did the researchers do this?
The authors created two main parts:
- The weaveW Dataset: A large collection of 100,000 examples with over 370,000 dialogue turns and about 500,000 images. Each example mixes text and images across several steps. Tasks include:
- Comprehension: understanding what’s in images and the instructions.
- Editing: changing specific parts of images without breaking the rest.
- Generation: creating new images that fit the story so far.
- The weaveW Benchmark: A human-checked test set with 100 tasks and 480 images. It uses a “VLM-as-judge” system, which means a strong AI model looks at the outputs and scores them using clear rules.
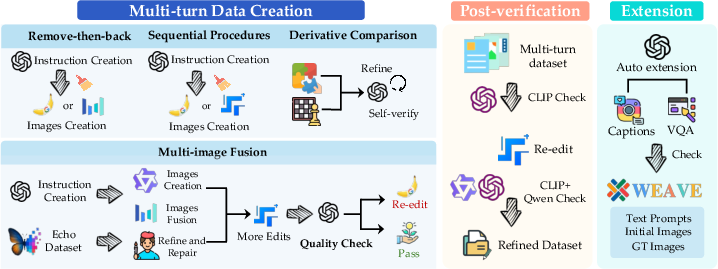
To build truly multi-step tasks, they used four simple patterns:
- Multi-image fusion: combine parts from different steps to keep the story consistent.
- Remove-then-back: take something out in one step, then bring it back later correctly.
- Derivative imagination and comparison: try variations first, then choose or blend the best.
- Sequential procedures: follow a logical storyline with ordered edits.
They also used four scoring metrics to judge performance:
- Key Point Correctness: Did the edit follow the main instructions?
- Visual Consistency: Did non-target parts stay the same? Did identities and styles stay coherent?
- Image Quality: Does the image look good?
- Accuracy: Is the reasoning correct for comprehension tasks?
Main Findings: What did they discover and why does it matter?
Here are the most important results, stated simply:
- Training works: Models trained on the weaveW dataset got noticeably better on existing tests:
- +9.8% on a tough visual understanding benchmark (MMMU).
- +4.8% on a popular image editing benchmark (GEditBench).
- Big gains on tasks that combine understanding and generation (RISE), roughly +50%.
- On the weaveW benchmark itself, a fine-tuned model improved by about 42.5% compared to its original version.
- Visual memory emerged: After training, some models started showing “visual memory”—they could remember and reuse details from earlier steps, like restoring a previously removed object or keeping a character’s look consistent.
- Multi-step is hard: Many current models still struggle when the story gets longer and the number of steps grows. Performance often drops as the “context” gets bigger. Open-source models often did worse when more past information was included; some closed-source models used the extra context better.
- Order matters: Feeding images in the original step-by-step order worked better than stacking all images together. This shows that models benefit from seeing the proper sequence.
- The judge is reliable: The AI judge’s scores matched human expert ratings well (high correlation), meaning the automatic evaluation is trustworthy.
Implications: Why is this research important?
- For creators and designers: AI that remembers and edits across steps can help make comics, ads, or visual stories more consistent and easier to refine.
- For education and science: Models that use world knowledge and visual memory can better explain scientific scenes or solve multi-step visual problems.
- For AI research: weaveW gives the community a foundation to build and test models that can truly handle multi-turn, mixed text-and-image tasks. It highlights where current systems fall short and points to the need for better memory, reasoning, and instruction-following over longer contexts.
In short, this work moves AI image systems closer to how humans actually work: not in one shot, but through a thoughtful, step-by-step process that remembers the past and plans ahead.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of concrete gaps that remain unresolved and could guide future research.
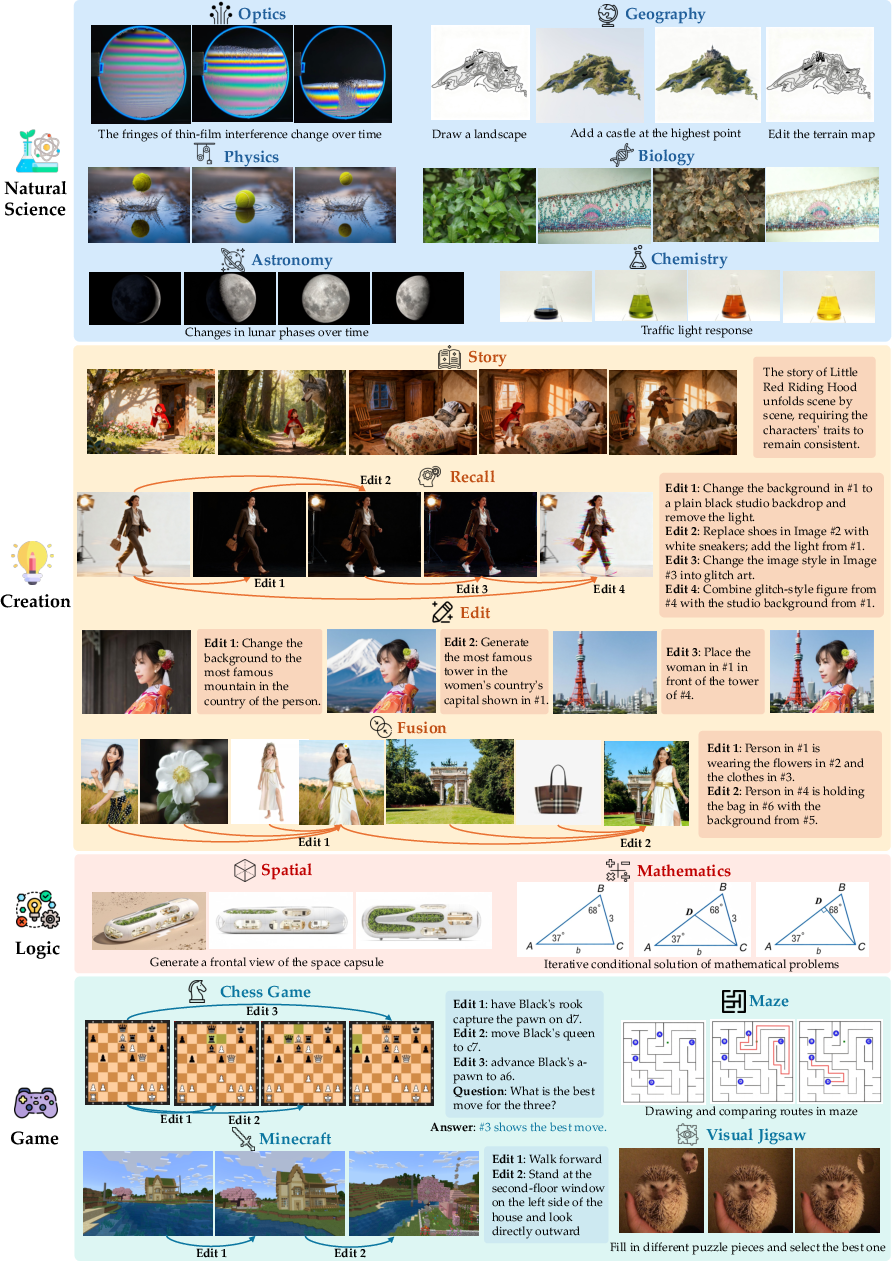
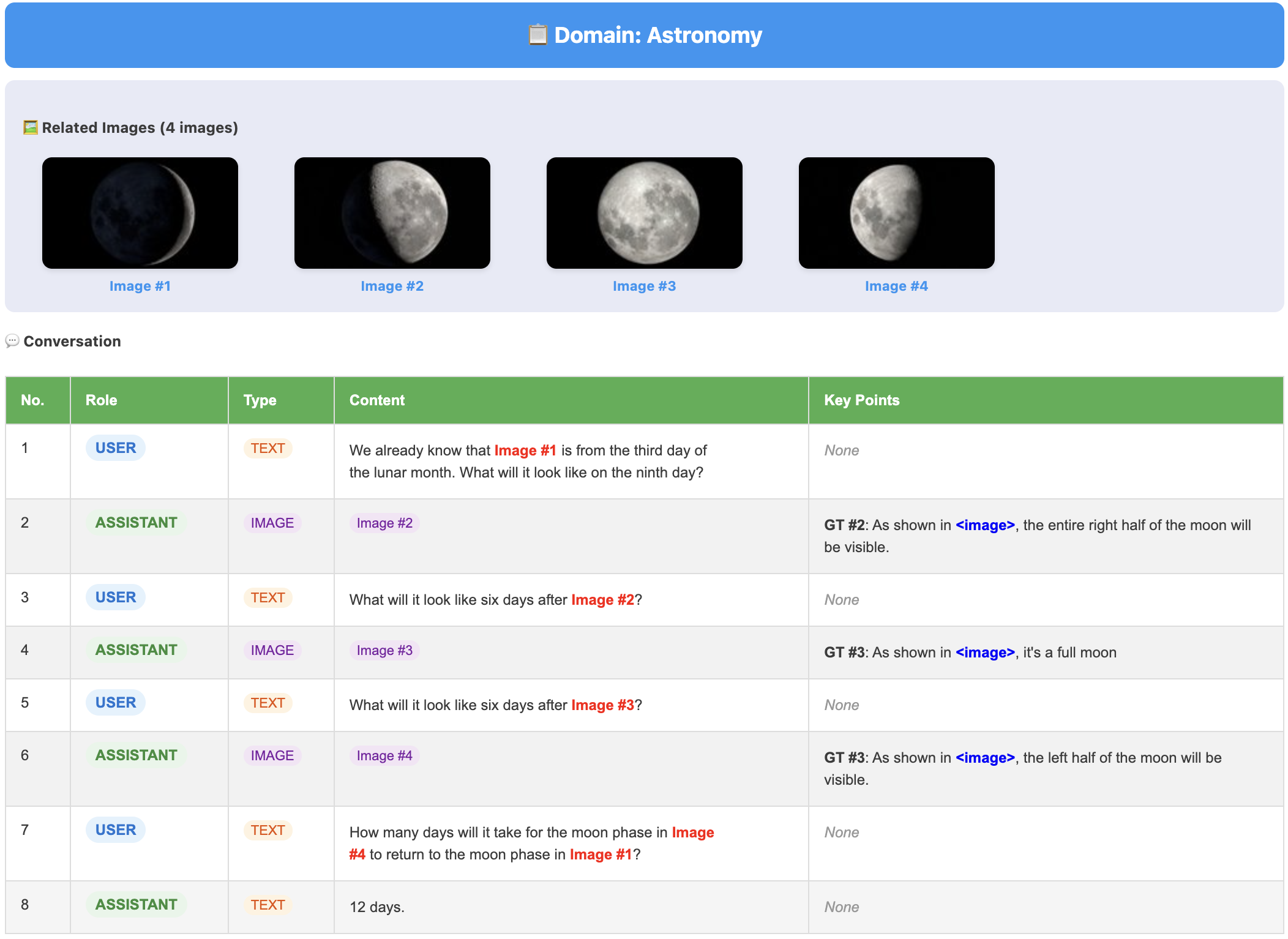
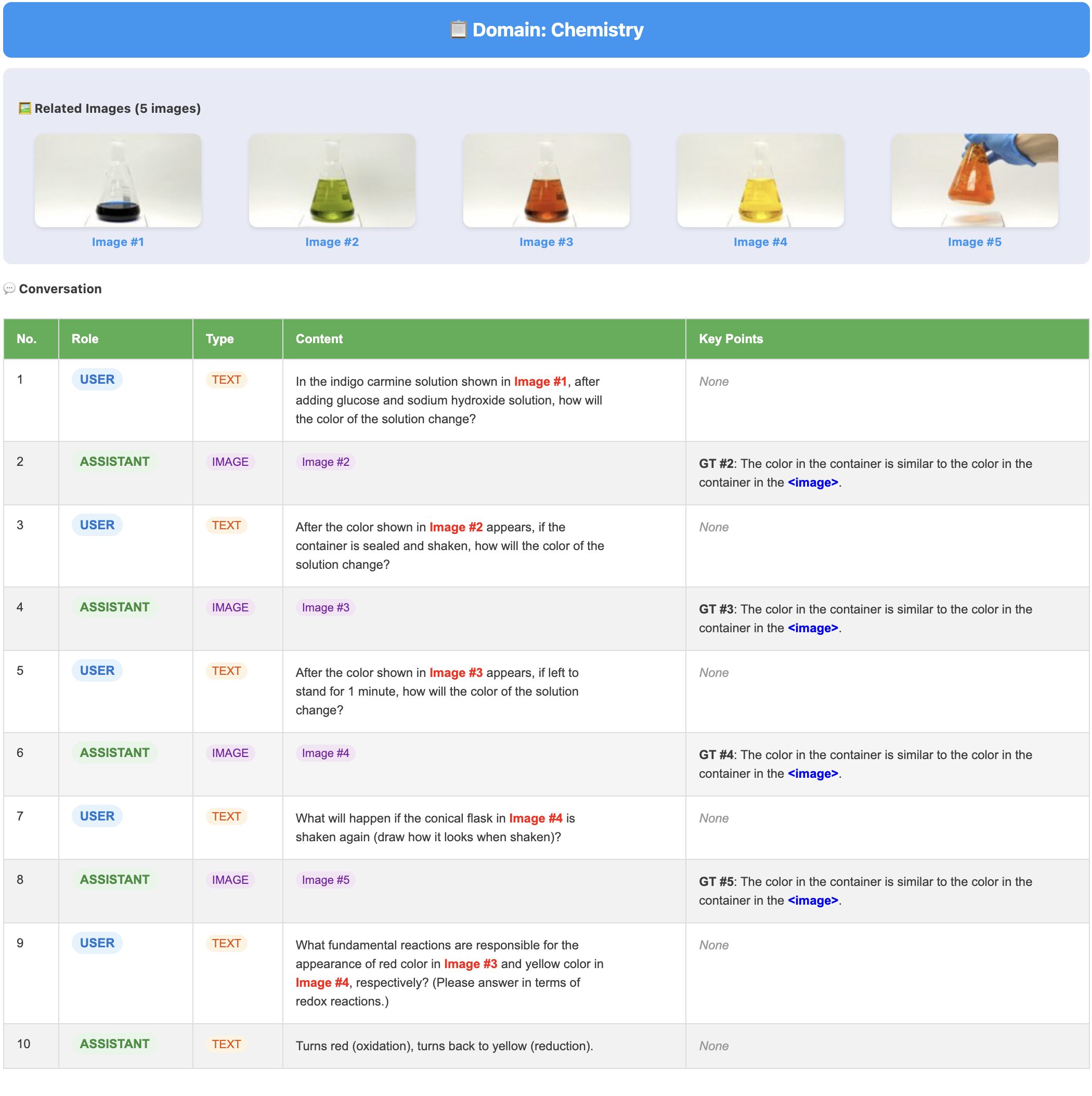
- Benchmark scale and coverage: The human-annotated benchmark includes only 100 tasks and 480 images, which may be insufficient to robustly assess long-horizon, multi-turn behaviors, diverse domains, and edge cases (e.g., rare object identities, complex scene compositions, high-precision scientific diagrams).
- Multi-turn depth: The average of 3.79 turns and maximum of 8 images per chat limits exploration of truly long-horizon editing (e.g., 10–20+ turns), reversion, and iterative refinement workflows typical of professional pipelines (storyboards, comics, enterprise design reviews).
- Formal “visual memory” measurement: The paper claims emergent visual memory but provides no standardized, memory-specific metrics (e.g., identity embedding stability, cross-turn edit localization accuracy, exact reversion fidelity) or human-validated gold standards to quantify memory capabilities separately from general visual consistency.
- Evaluation reliability and generalization: VLM-as-judge correlation (>0.8) is reported on only 100 instances per model; statistical power, domain-specific reliability, and sensitivity to prompt templates remain unclear. A larger-scale human study and inter-judge calibration (including task- and domain-specific reliability) are needed.
- Potential data bias from synthetic sources: Benchmark images are partly generated by specific proprietary models (Seedream, Nano Banana, SeedEdit). This raises concerns about style or distribution biases, and potential advantages for models trained on or aligned with these generators.
- Data contamination and overlap analysis: The paper fine-tunes Bagel on the proposed dataset and reports gains on external benchmarks (MMMU, GEditBench, RISE), but does not analyze overlap (semantic, stylistic, or instance-level) or leakage risk, which could inflate reported improvements.
- Fairness of input protocols across models: Differences in in-context modes (no/partial/complete), image placement (“yes-front” vs “yes-first”), and handling of sequential vs concatenated inputs may systematically favor certain architectures; a standardized, model-agnostic protocol is needed for fair comparisons.
- Stochasticity control: Generative models are inherently non-deterministic. The paper does not report controlled seeding, sampling parameters, or variance estimates across runs, complicating reproducibility and comparative fairness.
- Metrics sufficiency: KP, VC, IQ, and Acc mix subjective and general criteria. Missing are edit localization accuracy, identity preservation scores (face/object recognition consistency), compositionality checks, causal/world-knowledge correctness with structured labels, and robustness to distractor context and adversarial instructions.
- Context length effects: The paper notes performance degradation as context length increases but lacks quantitative characterization (e.g., curves vs number of prior images/turns, thresholds where degradation starts, sensitivity by model type, mitigation strategies like context pruning or memory modules).
- Mechanistic understanding of memory: Claims of emergent memory are not investigated mechanistically (e.g., attention trace analyses, memory token utilization, state caching, retrieval from prior turns), leaving open how models encode, retain, and reuse visual context.
- Pipeline ablations: The four data-generation pathways (multi-image fusion, remove-then-back, derivative imagination, sequential procedures) are not individually ablated to quantify their contribution to training efficacy, generalization, or memory emergence.
- World-knowledge rigor: Tasks requiring world knowledge (science, physics, chemistry) lack formal correctness criteria and structured labels; there is no analysis of failure modes (hallucinations, physical implausibility), nor calibration against expert judgments in those domains.
- Multilingual coverage: The dataset and benchmark appear primarily in English; the paper does not assess multilingual capabilities or cross-lingual transfer in multi-turn, interleaved image editing and generation.
- Ethical, legal, and safety considerations: The paper does not address licensing and consent for web-sourced images, identity-related risks (deepfakes, identity preservation with real people), content moderation, or potential misuse in sensitive domains.
- Real user-in-the-loop interactions: The dataset simulates multi-turn editing but does not evaluate interactive performance with real users (e.g., responsiveness, adherence to evolving intent, handling ambiguous instructions, recoverability from misunderstandings).
- Scalability and efficiency: No analysis of computational costs, memory load, inference latency, or efficiency trade-offs when processing long interleaved contexts—critical for practical deployment in creative workflows.
- Cross-modal breadth: Despite the “unified multimodal” framing, the dataset is limited to text–image; extensions to video, audio, 3D assets, or temporal consistency across frames are unaddressed.
- Generalization of training benefits: Fine-tuning is demonstrated on a single UMM (Bagel); it remains unknown whether similar gains and memory behaviors transfer across architectures and training paradigms.
- Robustness and safety testing: There is no stress test for adversarial or noisy context (irrelevant or conflicting prior turns), nor safety checks for harmful content synthesis under multi-turn instructions.
- Reproducibility details: Key training specifics (data splits, hyperparameters, prompt templates, pre/post-processing, augmentation) are deferred to the appendix and not fully described here; clear, publicly accessible protocols and scripts are needed.
- Release, licensing, and access: The paper links a website but does not specify dataset/benchmark licensing terms, availability of full annotations, judge prompts, or tools to reproduce the evaluation pipeline.
- Standardization of interleaving interfaces: Many models cannot process truly interleaved sequences and require concatenation, undermining the core setting; a common interface/API for interleaved text–image streams is needed to ensure comparable evaluations.
- Error taxonomy: Beyond a few qualitative examples, there is no systematic error analysis (e.g., types and frequencies of failures by domain, turn depth, or instruction category) to inform targeted model improvements.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, grounded in the paper’s dataset, benchmark, evaluation framework, and empirical findings.
- Industry — Creative production and marketing
- Application: Context-aware, multi-turn image editing in creative workflows (storyboards, comics, ads, product imagery) that maintains identity, style, and layout consistency across iterations.
- Tools/Products: “Visual Memory Editor” plugins for existing editors (Photoshop, Affinity, GIMP), SDKs for generative platforms (Stable Diffusion, Flux, OmniGen) supporting sequential inputs and reversible edits (remove-then-restore).
- Workflow: Iterative brief-to-asset loop with history-aware recall and selective reversion; standardized acceptance tests using Key Point Correctness (KP), Visual Consistency (VC), Image Quality (IQ).
- Assumptions/Dependencies: Models must handle sequential image inputs; integration with asset/version management; licensing for weaveW dataset; GPU capacity for in-context runs.
- Industry — E-commerce and retail
- Application: Brand-consistent catalog generation and batch editing (e.g., consistent lighting, backgrounds, and identity preservation across hundreds of SKUs).
- Tools/Products: “Catalog Copilot” with automated KP/VC/IQ gatekeeping; style lock-in templates that reuse prior frames; batch-edit pipelines using hybrid VLM-as-judge scoring to auto-approve/reject assets.
- Workflow: Bulk generation with in-context references (previous approved images as ground truth exemplars) and CI-like gating before publishing.
- Assumptions/Dependencies: High-throughput inference; robust data governance for product imagery; hybrid judge reliability above target correlation thresholds.
- Software — Model evaluation and QA
- Application: Immediate adoption of the weaveW Benchmark and hybrid VLM-as-judge scoring for automated acceptance testing of multimodal models (editing, generation, comprehension).
- Tools/Products: Evaluation dashboards implementing KP/VC/IQ/Acc; routing policies that select models by domain (creative vs science/logical) based on performance profiles.
- Workflow: CI/CD gates in MLops; regression checks when retraining or finetuning; alerting for long-context performance degradation.
- Assumptions/Dependencies: Access to large-context models (or adapters); standardized prompts/templates; reproducible judge setup (e.g., GPT-4.1, Claude variants).
- Academia — Research benchmarking and curriculum
- Application: Benchmarking UMMs for multi-turn, interleaved comprehension-generation; hands-on coursework featuring visual memory tasks, sequential input studies, and long-context degradation analysis.
- Tools/Products: Public benchmark suites; teaching modules using weaveW’s metrics and ablation patterns (sequential vs concatenated inputs).
- Workflow: Reproducible experiments, shared leaderboards, and class projects on emergent memory capabilities and evaluation reliability.
- Assumptions/Dependencies: Dataset availability; compute resources; adherence to ethical image usage.
- Policy and governance — Procurement and compliance testing
- Application: Standardizing multi-turn evaluation in procurement and compliance for generative tools (requiring minimum KP/VC/IQ thresholds and full history-aware editing support).
- Tools/Products: Compliance checklists and report templates based on hybrid judge metrics; model certification processes emphasizing context-coherent editing.
- Workflow: Vendor self-tests plus third-party audits; periodic reevaluation to monitor long-context degradation risks.
- Assumptions/Dependencies: Verification of VLM-as-judge reliability (human correlation ≥ 0.8, as shown); policy adoption by regulators and procurement teams.
- Daily life — Personal photo and project editing
- Application: History-aware photo assistants for albums, DIY projects, and event collages that preserve identities and styles across multiple edits and scenes.
- Tools/Products: Consumer apps with “restore previous elements” and “maintain series consistency” features; guided multi-step editing for social media series.
- Workflow: Sequential edit threads with automatic recall of prior steps and reversible modifications.
- Assumptions/Dependencies: On-device or cloud model support for sequential inputs; privacy-preserving storage and consent for personal images.
- Data creation — Domain-specific interleaved datasets
- Application: Replicating the paper’s four-path pipeline (multi-image fusion, remove-then-back, derivative imagination, sequential procedures) to build proprietary, domain-specific interleaved datasets (e.g., brand assets).
- Tools/Products: Internal data annotation playbooks; quality filters; two-round validation workflows.
- Workflow: Controlled dataset construction and refinement; targeted finetuning for emergent visual memory in specific domains.
- Assumptions/Dependencies: Annotation staff; image rights; quality assurance systems; finetuning budget and infra.
Long-Term Applications
These use cases require additional research, scaling, or development (e.g., improved long-context handling, video support, domain-specific data).
- Media and entertainment — End-to-end continuity management
- Application: Art director copilots that ensure narrative and identity continuity across scenes/shots (pre-vis, storyboards, animation).
- Tools/Products: Multi-turn editorial agents integrated with asset libraries, shot trackers, and style “locks.”
- Workflow: Client-in-the-loop iterative revisions with context-aware generation and automatic continuity checks.
- Assumptions/Dependencies: Robust long-context memory; integration with production asset managers; multimodal version control; potential extension to video.
- Robotics and embodied AI — Long-horizon visual memory
- Application: Consistent object/location recall across multistep tasks (assembly, navigation) by training perception on interleaved sequential imagery.
- Tools/Products: Perception modules with visual memory layers; simulation-to-real pipelines leveraging context-aware datasets.
- Workflow: Plan-execute loops with step-aware perception and reversible action recall.
- Assumptions/Dependencies: Extension from static images to video/embodied streams; safety and reliability benchmarks; domain-specific data.
- Healthcare — Longitudinal visual reasoning
- Application: Consistency-aware analysis of longitudinal medical images (e.g., tracking changes across visits), with strict editing controls for annotations and overlays.
- Tools/Products: Clinical-grade memory-aware viewers; audit trails that record every edit and its rationale.
- Workflow: Multi-turn diagnostic workflows referencing prior studies; compliance with visual consistency and accuracy checks.
- Assumptions/Dependencies: Medical-grade datasets; regulatory approvals; strong guardrails to prevent unsafe image manipulation; explainability requirements.
- Public policy — Standards for multi-turn generative reliability and forensics
- Application: Regulatory standards that mandate multi-turn context-coherence tests, chain-of-edits logs, and watermarking for edited/generated images.
- Tools/Products: Certification bodies; forensic toolkits to trace multi-step manipulations; watermark standards for interleaved workflows.
- Workflow: Audited pipelines with mandatory hybrid judge scoring; incident response for misinformation risks.
- Assumptions/Dependencies: Broad adoption by platforms and vendors; legal frameworks; interoperable watermarking and provenance protocols.
- Education — Design studio tutors and assessment
- Application: Multimodal tutors that track student visual artifacts across iterations, provide context-aware feedback, and assess consistency and instruction-following.
- Tools/Products: Classroom LMM agents; formative assessment tools using KP/VC/IQ metrics tailored to design tasks.
- Workflow: Iterative assignment cycles with feedback loops and history-aware evaluation.
- Assumptions/Dependencies: School-approved datasets; fairness and transparency in automated grading; student privacy.
- E-commerce at scale — Autonomous catalog governance
- Application: Large-scale catalog management that enforces brand rules over thousands of SKUs using interleaved references and automated QC gates.
- Tools/Products: Policy engines that encode visual rules; auto-repair bots that propose compliant revisions.
- Workflow: Continuous ingestion and correction of imagery with full audit trails.
- Assumptions/Dependencies: High-throughput inference; effective routing among closed- and open-source models depending on domain; robust data governance.
- Science- and physics-aware generation
- Application: Models that integrate world knowledge and physical constraints during generation (reducing domain performance gaps seen in the benchmark).
- Tools/Products: Physics-informed UMMs; domain-specific datasets and evaluators extending KP/VC/IQ with scientific validity checks.
- Workflow: Research and engineering pipelines that use interleaved context to preserve scientific correctness over iterative edits.
- Assumptions/Dependencies: New architectures for reasoning under long context; curated domain data; stronger evaluators beyond VLM-as-judge.
- Video and 3D extensions
- Application: Multi-turn, context-aware video editing and 3D scene generation with consistent identity, lighting, and narrative across frames and time.
- Tools/Products: Video/3D UMMs with interleaved memory; temporal VC metrics; hybrid evaluators for dynamic content.
- Workflow: Iterative film/VR pipeline that maintains coherence over long sequences.
- Assumptions/Dependencies: Temporal models, scalable training, higher compute budgets; new benchmarks for dynamic consistency.
Across both immediate and long-term adoption, key dependencies include model support for full in-context sequential inputs, the reliability of hybrid VLM-as-judge scoring (validated but still needing governance), data rights and safety controls, compute capacity for long-context processing, and organizational readiness to integrate history-aware workflows.
Glossary
- Autoregressive next-token prediction: A generative modeling approach where the model predicts the next token in a sequence conditioned on previous tokens. Example: "leverage image tokenization and autoregressive next-token prediction to generate visual tokens."
- Comprehension-generation collaboration: The coordinated use of understanding (comprehension) to inform content creation (generation) in multimodal models. Example: "comprehension-generation collaboration capabilities."
- Concatenated input: An input formatting strategy that stitches multiple images together into a single composite for models that can’t process sequences. Example: "significant performance advantages over concatenated input."
- Cross-modality: Involving interactions across different data modalities (e.g., text and images). Example: "in-context interleaved cross-modality comprehension and generation."
- Derivative imagination and comparison: A data-creation step where alternative images are imagined or derived and then compared before fusion. Example: "Derivative imagination and comparison."
- Diffusion-based: Refers to generative models that iteratively refine noise into data samples via a diffusion process. Example: "diffusion-based or flow-matching heads."
- Emergent visual-memory capabilities: Unplanned or unexpected abilities of a model to recall and use prior visual information after training. Example: "emergent visual-memory capabilities."
- Fidelity (to original images): The degree to which generated/edited images preserve the content and appearance of the original. Example: "fidelity to original images."
- Flow matching: A generative modeling technique that learns probability flows to synthesize data, often used as an alternative to diffusion. Example: "flow-matching heads."
- GEditBench: A benchmark for evaluating general-purpose image editing systems across diverse edit types. Example: "image editing ($4.8$\% on GEditBench)."
- GenEval: An object-focused evaluation framework for text-to-image alignment and controllable generation. Example: "GenEval and RISEBench."
- Hybrid VLM judge evaluation framework: An assessment setup using a vision-LLM as an automatic judge, combining multiple reference signals. Example: "a hybrid VLM judge evaluation framework with four metrics."
- Identity preservation: Maintaining the identity (e.g., person, character) of subjects during editing or generation. Example: "assesses identity preservation of edited objects."
- Image tokenization: Converting images into discrete tokens that can be processed by language-like generative models. Example: "leverage image tokenization and autoregressive next-token prediction."
- In-context: Using prior interactions or examples provided in the prompt/history to guide current reasoning or generation. Example: "In-context usage matters."
- Interleaved: Alternating or mixing different modalities and steps (e.g., text and images) within multi-turn interactions. Example: "interleaved samples."
- Key Point Correctness (KP): A metric assessing whether specific, predefined editing requirements are satisfied. Example: "Key Point Correctness (KP): Measures whether the edited image satisfies the specified editing requirements."
- Key-point-based scoring: An evaluation method that scores outputs against specific, enumerated criteria or “key points.” Example: "we employ a key-point-based scoring approach."
- Long-horizon reasoning: Reasoning that spans many steps or turns, requiring consistent use of historical context. Example: "long-horizon reasoning required for authentic interactive image creation."
- MMB: A benchmark for multimodal understanding (often testing general visual-language capabilities). Example: "MMB."
- MMMU: A massive multi-discipline multimodal understanding benchmark for expert-level reasoning. Example: "($9.8$\% on MMMU)."
- MMVet: A benchmark evaluating integrated capabilities of multimodal LLMs. Example: "MMVet."
- Multi-image composition: Combining multiple images into a coherent output guided by instructions or context. Example: "and multi-image composition."
- Multi-image fusion: Merging information from multiple images (often across turns) to maintain or reuse visual references. Example: "Multi-image fusion."
- Multi-turn editing: Performing image edits over multiple conversational turns with dependencies across steps. Example: "multi-turn editing."
- Pearson correlation coefficients: A statistical measure of linear correlation between two sets of scores (e.g., human vs. model judge). Example: "Pearson correlation coefficients."
- RISE: A benchmark focused on reasoning-intensive scenarios for generation with world knowledge. Example: "approximately $50$\% on RISE."
- RISEBench: A benchmark evaluating text-to-image systems on temporal, causal, spatial, and logical reasoning. Example: "RISEBench."
- Sequential image input: Providing images to a model in the chronological order they were produced/mentioned. Example: "sequential image input."
- Sequential procedures: Applying a series of structured editing operations aligned with a narrative or process. Example: "Sequential procedures."
- Temporal dependencies: Relationships where current outputs depend on earlier states or edits across time/turns. Example: "capturing the temporal dependencies."
- Unified Multimodal Models (UMMs): Models that jointly handle understanding and generation across modalities within one architecture. Example: "unified multimodal models (UMMs)."
- Visual Consistency (VC): A metric assessing whether non-target elements remain unchanged and styles/identities stay coherent. Example: "Visual Consistency (VC): Ensures non-target elements remain unchanged."
- Visual memory: The ability of a model to recall and reuse visual elements from previous turns or images. Example: "visual memory."
- Visual tokens: Discrete representations of image content used by token-based generative models. Example: "generate visual tokens."
- VLM-as-judge: Using a vision-LLM to automatically score or rank generated outputs. Example: "We adopt the VLM-as-judge automated evaluation framework."
- World-knowledge reasoning: Using real-world facts and concepts (e.g., cultural or physical phenomena) within generation/editing. Example: "world-knowledge reasoning across diverse domains."
Collections
Sign up for free to add this paper to one or more collections.