SynthWorlds: Controlled Parallel Worlds for Disentangling Reasoning and Knowledge in Language Models
Abstract: Evaluating the reasoning ability of LMs is complicated by their extensive parametric world knowledge, where benchmark performance often reflects factual recall rather than genuine reasoning. Existing datasets and approaches (e.g., temporal filtering, paraphrasing, adversarial substitution) cannot cleanly separate the two. We present SynthWorlds, a framework that disentangles task reasoning complexity from factual knowledge. In SynthWorlds, we construct parallel corpora representing two worlds with identical interconnected structure: a real-mapped world, where models may exploit parametric knowledge, and a synthetic-mapped world, where such knowledge is meaningless. On top of these corpora, we design two mirrored tasks as case studies: multi-hop question answering and page navigation, which maintain equal reasoning difficulty across worlds. Experiments in parametric-only (e.g., closed-book QA) and knowledge-augmented (e.g., retrieval-augmented) LM settings reveal a persistent knowledge advantage gap, defined as the performance boost models gain from memorized parametric world knowledge. Knowledge acquisition and integration mechanisms reduce but do not eliminate this gap, highlighting opportunities for system improvements. Fully automatic and scalable, SynthWorlds provides a controlled environment for evaluating LMs in ways that were previously challenging, enabling precise and testable comparisons of reasoning and memorization.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SynthWorlds, a way to fairly test whether AI LLMs (like the ones behind chatbots) are truly “reasoning” or just “remembering.” The authors build two matching versions of a mini‑Wikipedia:
- One version uses real names (like “Geoffrey Hinton”) where the model’s built‑in memory helps.
- The other uses made‑up names (like “Caleb Ardent”) so memorized facts don’t help, but the structure and difficulty are exactly the same.
By comparing how well models do in both versions, the paper measures how much of their success comes from reasoning vs. from memorized knowledge.
What questions does the paper try to answer?
The paper focuses on simple, testable questions:
- How much better do models perform when they can rely on what they’ve memorized (their internal “world knowledge”)?
- If we let models look up information (retrieve documents) and think step‑by‑step, does that reduce their advantage from memorization?
- Do models still struggle in unfamiliar environments where names and facts are new, even when they can read helpful pages?
How did the researchers run their tests?
Think of the setup like building two parallel worlds with the same shape:
- A “world” here is a set of pages linked together (like Wikipedia). Pages talk about people, places, awards, universities, etc., and link to each other.
Here’s the approach, explained with everyday analogies:
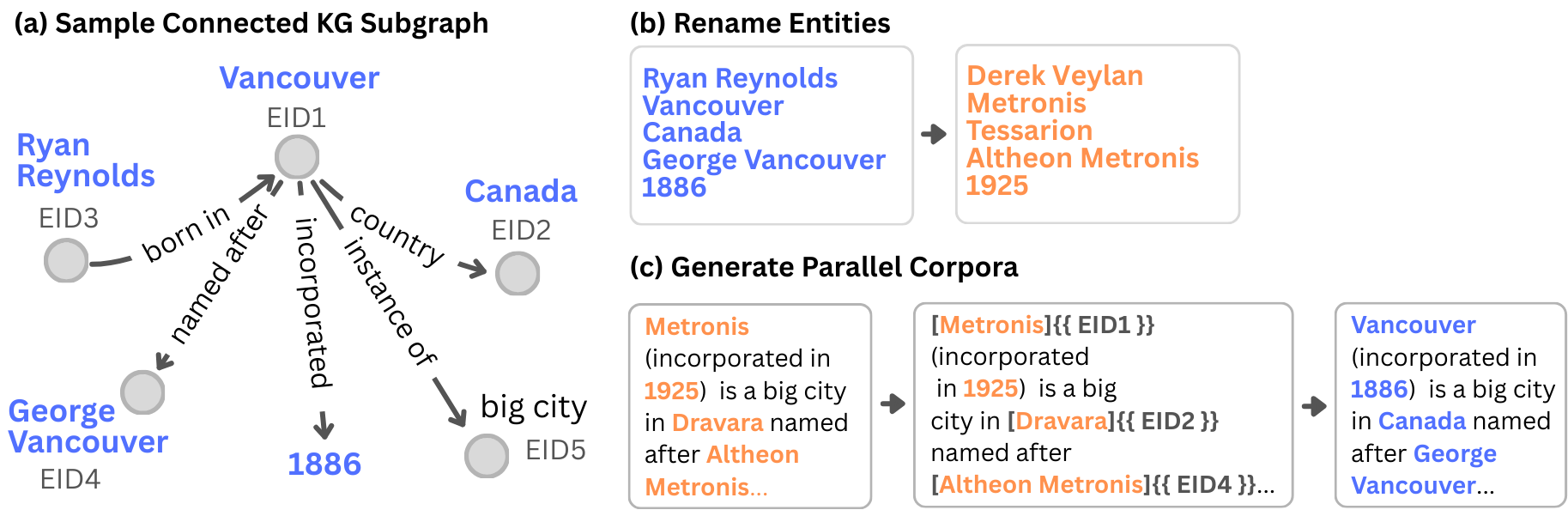
- Building the world’s “web” of facts:
- They start from a big, reliable knowledge graph (like a huge spiderweb of facts: subject → relation → object, e.g., “Marie Curie → won → Nobel Prize”).
- They sample connected pieces of this web so everything fits together.
- Renaming to hide memorized knowledge:
- In the synthetic version, they swap real names for realistic‑sounding fake names that still “feel” right for their type (cities sound like cities, people sound like people). This keeps the world coherent but makes memorized facts useless.
- Making readable pages:
- Using a LLM, they turn those facts into page content.
- They create two matching sets of pages: real‑mapped (real names) and synth‑mapped (fake names).
- The pages have the same sentences and links; only the names differ.
- Creating two mirrored tasks:
- Multi‑hop Question Answering (QA): Answer questions that require combining clues across multiple pages (like solving a mystery by visiting several articles).
- Page Navigation: Start on one page and reach a target page by clicking links (like playing WikiRace). They control difficulty by choosing pairs that are farther apart in the link network.
- Measuring “Knowledge Advantage”:
- They define the “knowledge advantage gap” as the performance difference: KA = performance in the real‑names world minus performance in the fake‑names world.
- If KA is big, the model is gaining a lot from memorized knowledge. If KA shrinks when given tools (like search and reading), those tools help replace memorization with actual reasoning.
What did they find, in simple terms?
Below are the main results, explained clearly and with key numbers to give a feel for the size of the effects.
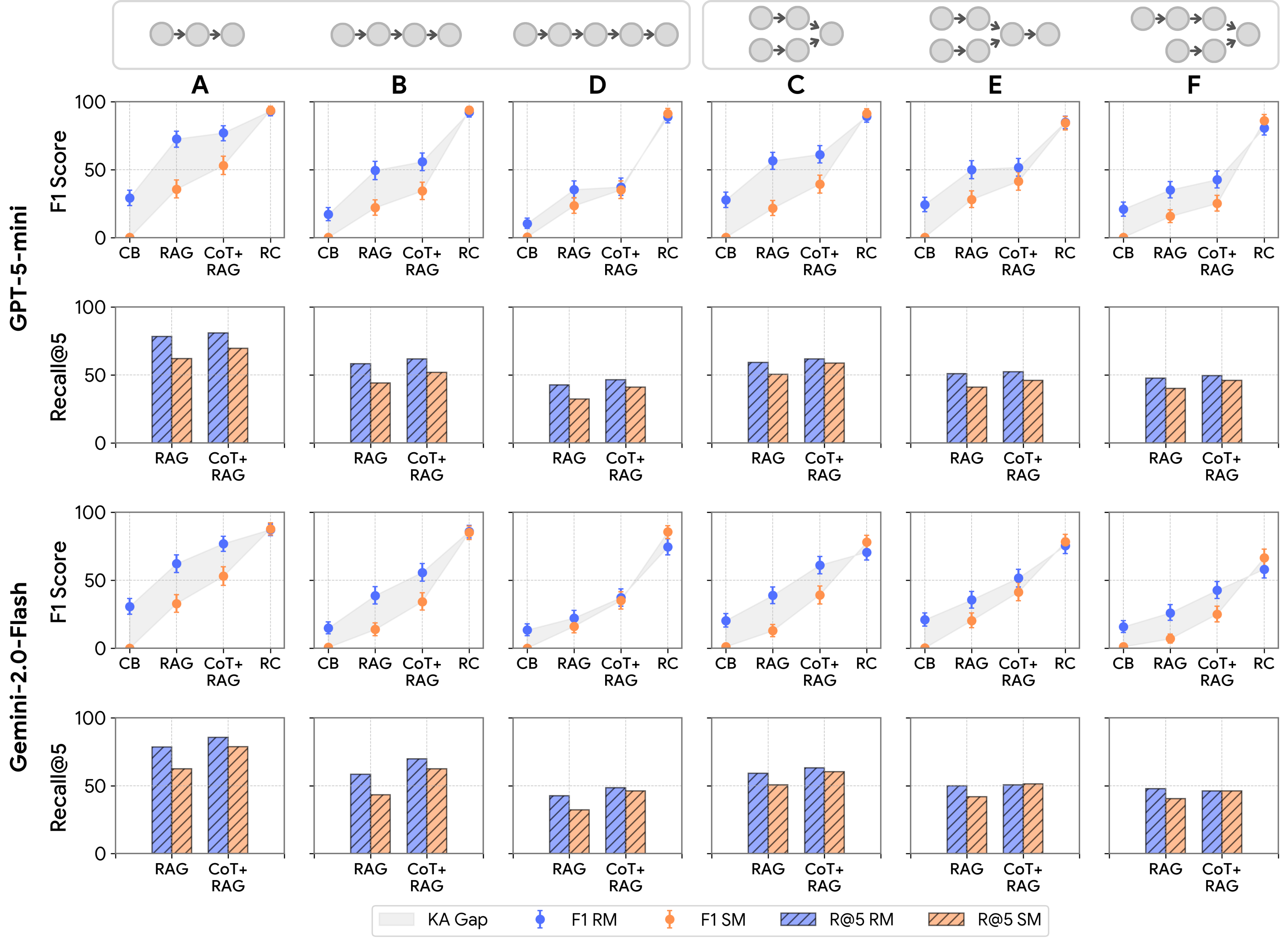
- Multi‑hop QA (answering multi‑step questions):
- Closed‑book (no reading, just memory):
- Models did much better with real names than with fake names. The gap (KA) was large—around 19–21 F1 points. In the synthetic world, scores were near zero because memorized facts didn’t help.
- Reading comprehension (given the right pages to read):
- Both worlds scored high (about 75–90 F1), and the gap disappeared or even slightly reversed. This shows that when relevant evidence is provided, models can reason similarly in new environments.
- One‑step Retrieval‑Augmented Generation (RAG):
- Letting the model retrieve pages once increased scores, but surprisingly made the gap bigger. The real‑names world benefited more because memorization helped retrieval choose better pages.
- IRCoT + RAG (interleaving step‑by‑step reasoning with retrieval):
- This reduced the gap compared to closed‑book. Thinking out loud while retrieving helps align search with the actual reasoning steps, so synthetic‑world performance improves more.
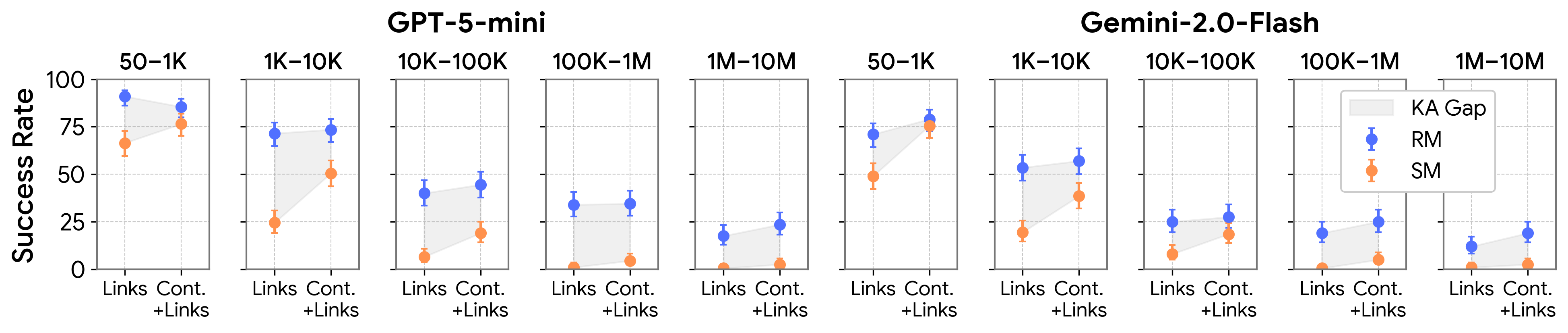
- Page Navigation (clicking links to reach a target page):
- Links Only (see only link text, no page content):
- Models did much better in the real‑names world. The gap was big (about 20–31 percentage points). Recognizing familiar names helps choose the right links.
- Content + Links (see the whole page):
- Scores improved in both worlds, but synthetic‑world scores improved more. This narrowed the gap (down to ~13–22 points), showing that reading page content gives useful clues even without memorized facts.
- Dataset realism and scale:
- The worlds contain 6,290 pages, about 1.5 million tokens, and 161,000 facts, with link structures like real websites (a few hubs, many small pages). Tasks include 1,200 multi‑hop questions and 1,000 navigation pairs across difficulty levels.
Why does this matter?
- Fair testing: SynthWorlds gives researchers a controlled way to separate “reasoning” from “remembering.” The two worlds are identical in structure and difficulty, so differences in performance are clearly tied to memorized knowledge.
- Better AI design: The fact that the knowledge advantage gap persists—even with retrieval—means current systems still lean heavily on what they already know. Interleaving reasoning and retrieval helps but doesn’t fully solve it.
- Real‑world reliability: If we want AI to work well in new domains (new science, new events, private data), it must succeed without relying on old memorized facts. SynthWorlds shows where today’s models struggle and points to improvements: smarter retrieval, stronger grounding in the retrieved content, and better step‑by‑step planning.
- Reusable and scalable: The framework is automatic and can create fresh, realistic test worlds in the future, reducing the need for constant manual dataset building. The authors released their data and code to help the community.
In short, SynthWorlds is like testing a student with two copies of the same textbook: one with familiar names and one with made‑up names. If the student still solves problems in the made‑up version, they’re truly reasoning. This paper shows today’s AI is good, gains a big boost from memorization, and can be helped by better tools and methods—but there’s room to grow in genuine reasoning, especially in unfamiliar settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following concrete gaps and unresolved questions that future work could address:
- Validity of “equal reasoning difficulty” across RM and SM
- No empirical audit that RM and SM instances are matched on non-knowledge confounds (e.g., tokenization length, character n-gram familiarity, name morphology, answer-type distribution). Action: measure and control for token/byte length, subword rarity, and lexical overlap in queries, documents, and answers across RM/SM; re-run results after equalization.
- Lack of human or independent assessment that reasoning difficulty is perceived as equal across worlds. Action: expert or crowd annotations rating difficulty and ambiguity per instance (blinded to RM/SM) and test-retest reliability.
- Synthetic renaming may introduce unintended signals or artifacts
- Synthetic names may carry morphological cues (e.g., gender, nationality cues, grapheme patterns) or OOV subword splits that change retrieval/encoding difficulty. Action: quantify and control for name morphology, subword rarity, and OOV rates; generate counterbalanced names with matched subword statistics.
- Unclear robustness of timestamp perturbations; numeric patterns could inadvertently simplify or complicate tasks. Action: audit numeric distributions/prevalence and ablate timestamp perturbations’ impact on KA.
- LM-generated documents may differ from natural corpora
- Document style and discourse structure are LM-generated from triplets, potentially reducing natural variability (e.g., coreference, discourse markers, noise, contradictions). Action: compare linguistic/discourse metrics (coreference density, syntactic variety, factual redundancy) to Wikipedia; evaluate KA on human-written vs LM-written variants.
- Risk of hallucinations or subtle inconsistencies in generated text not caught by automatic checks. Action: add fact-spotting validators and human audits; release contradiction/error annotations.
- Novelty and leakage not rigorously verified
- “Novelty validation” relies on an LM (GPT-5-mini), which may miss overlaps with pretraining data. Action: perform approximate nearest-neighbor search against large web/Wikipedia snapshots; run n-gram and embedding overlap audits; report estimated contamination risk.
- Potential residual real names or unchanged surface forms slipping through renaming. Action: publish coverage of rename success rates and a blacklist of unchanged or partially changed entities.
- Confounds in retrieval and indexing pipelines
- Only HippoRAG 2 is evaluated; retrieval performance may be disproportionately harmed on SM due to OOV/rare tokens and absent entity priors. Action: benchmark multiple retrievers (BM25, DPR, ColBERT, Contriever, multi-vector, re-rankers) and name-normalized/query-rewriting variants; report per-retriever KA.
- No control for lexical matching advantages in RM queries (familiar entity strings). Action: evaluate retrieval on name-ablated or alias-normalized queries; use entity IDs or description-based queries to remove surface-form bias.
- Retrieval metrics limited to Recall@5; no error decomposition. Action: provide precision@k, nDCG, coverage of supporting passages, and ablations on k; analyze failure modes (missed hop vs wrong page vs distractor attraction).
- Measurement and evaluation limitations
- Token-level F1 for QA may penalize SM entity answers more (rare tokens, longer spans). Action: add span-level exact match variants, entity-linking–based scoring, and answer normalization analyses; report per answer-type KA (entity, numeric, date).
- No process-level evaluation of reasoning faithfulness. Action: evaluate chains of thought, intermediate retrieval steps, and consistency with gold evidence (e.g., step-accuracy, attribution metrics).
- Lack of per-motif/hops difficulty decomposition beyond aggregated plots. Action: report KA vs number of hops, branching factor, and path redundancy.
- Scope of tasks and settings is narrow
- Only two tasks (multi-hop QA, page navigation). Action: add tasks that stress different reasoning forms: temporal/causal reasoning, graph completion, long-context reading, summarization with evidence attribution, entailment/consistency checks, tool-use with APIs, math/program synthesis.
- Navigation agent is limited to click_link/backtrack with a static graph. Action: evaluate richer toolsets (search within corpus, summarization, multi-step planning), stochastic/dynamic environments, and partial observability; analyze policy learning vs zero-shot prompting.
- Generalization and external validity
- Single knowledge graph source (Wikidata-derived) and English-only; unclear cross-domain or cross-lingual portability. Action: instantiate SynthWorlds over other KGs (domain-specific: biomedical, legal; commonsense), across multiple languages, and multimodal settings.
- Limited model diversity (two closed models). Action: include open models across sizes, instruction-tuned vs base, retrieval-augmented vs memory-augmented, and analyze KA vs model scale and training recipe.
- Interpretation of the knowledge advantage gap (KA)
- KA may conflate parametric knowledge with distributional familiarity (token frequencies, stylistic priors) and retrieval ease. Action: decompose KA into components attributable to retrieval recall, reranking, reading comprehension, and generation; run controlled ablations with “oracle retrieval” and “oracle grounding.”
- Reading-comprehension results suggest interference from parametric knowledge in RM (glitch effects), but root causes remain unclear. Action: measure contradiction susceptibility, prior override rates, and mitigation by explicit grounding instructions.
- Graph sampling and dataset design uncertainties
- Subgraph sampling may bias toward hubs/popular entities; KA could correlate with entity popularity in pretraining. Action: report KA vs entity/page popularity proxies (in/out-degree, Wikipedia pageviews, link centrality).
- Bridge-entity masking in questions may leak via synonyms or descriptive phrases. Action: audit question text for implicit bridge cues; apply automated masking of near-synonyms/aliases and measure KA impact.
- Reproducibility and sustainability
- Pipeline depends on proprietary LMs; regeneration under new models may shift distributions. Action: release an open-source, fully reproducible pipeline with open models; provide seeds, prompts, and deterministic sampling; quantify generation variance across runs.
- Dataset size may be insufficient for long-term benchmarking (risk of overfitting). Action: demonstrate scalable regeneration protocol (e.g., periodic refreshes), evaluate “benchmark saturation” by tracking performance over releases.
- Ethical and safety considerations
- Real-mapped texts reference real people via LM-generated narratives; risk of inaccuracies or harmful associations. Action: add safety filters, fact-checking, and redaction policies; provide error-reporting channels and datasheets.
- Synthetic naming could inadvertently generate culturally sensitive or offensive names. Action: incorporate toxicity/sensitivity screening and culturally aware name generation constraints.
- Open methodological questions
- Can targeted training (e.g., retrieval fine-tuning or grounding alignment) close KA without harming RM performance? Action: run fine-tuning on SM-only supervision, measure transfer to RM, and check trade-offs.
- Can name-agnostic representations (entity IDs, description-based mentions) eliminate surface-form biases in both retrieval and generation? Action: evaluate ID-based indexing and text-to-ID/query rewriting pipelines.
- To what extent can structural signals (graph topology) let models de-anonymize SM by aligning with RM? Action: attempt graph matching/de-anonymization attacks; quantify leakage risk and design countermeasures (e.g., perturb structure while preserving reasoning motifs).
- Practical deployment implications
- No analysis of cost-performance trade-offs for augmentation strategies across RM/SM. Action: report latency, token, and dollar costs vs KA reduction; provide Pareto frontiers.
- Unclear if KA persists in truly open-world web environments. Action: replicate experiments with live web retrieval (time-bounded) and with crawl snapshots unseen by models.
Practical Applications
Overview
The paper introduces SynthWorlds—automatically generated, parallel corpora and tasks that isolate LLM (LM) reasoning from memorized, entity-specific “parametric” knowledge—together with the “Knowledge Advantage” gap (KA), a measurable difference between performance on real-mapped (RM) tasks and synthetic-mapped (SM) tasks. The framework provides controlled, scalable evaluations for multi-hop question answering and page navigation, revealing persistent reliance on memorization that is only partially mitigated by better retrieval and reasoning workflows (e.g., IRCoT + RAG). Below are practical applications derived from the paper’s findings, methods, and innovations.
Immediate Applications
The following items can be deployed now, using the released datasets, code, and workflows (GitHub/Hugging Face) and standard LM/RAG stacks.
- LM evaluation and benchmarking for industry and academia
- Sector: software/AI; academia
- Application: Use SynthWorld-RM/SM and the KA metric to audit whether model performance comes from genuine reasoning or parametric recall.
- Tools/workflows: “KA dashboard” in CI; scripted runs across Closed-book, One-step RAG, IRCoT + RAG; recall@5 tracking; Reading Comprehension upper bound checks.
- Assumptions/dependencies: Access to the released corpora; stable prompts; retriever configuration; parallelism validity between RM/SM tasks.
- RAG stack tuning and retrieval-orchestration improvements
- Sector: software/AI; enterprise search; knowledge management
- Application: Implement IRCoT-style interleaving of reasoning and retrieval to reduce the KA gap and improve retrieval alignment with multi-hop task needs.
- Tools/workflows: Retrieval orchestration layer (IRCoT); HippoRAG-like retrievers; recall diagnostics; “content grounding” mode that provides full-page text when novel entities are detected.
- Assumptions/dependencies: High-quality retrievers; access to relevant document stores; prompt discipline to avoid parametric shortcuts.
- Agent evaluation for web/intranet navigation
- Sector: automation, e-commerce, customer support, IT operations
- Application: Use page navigation tasks (Links Only vs Content + Links) to train and evaluate function-calling agents for browsing, catalog navigation, and site exploration.
- Tools/workflows: Agent harness with click_link/backtrack tools; difficulty bucketing by expected random-walk distance; success-rate reporting.
- Assumptions/dependencies: Representative hyperlink graphs; page content quality; reasonable step limits for agents.
- Enterprise governance and procurement scorecards
- Sector: policy/compliance; healthcare; finance
- Application: Add KA-gap reporting to vendor assessments to evaluate generalization-to-novelty claims; prioritize systems that ground answers in retrieved content.
- Tools/workflows: Procurement templates with KA thresholds; periodic “novelty stress tests” before deployment.
- Assumptions/dependencies: Organizational buy-in; agreed-upon thresholds; availability of domain-specific test corpora.
- Education and assessment design
- Sector: education; edtech
- Application: Create parallel RM/SM exercises to measure reasoning independent of memorized facts; develop grading rubrics focused on evidence-grounded reasoning.
- Tools/workflows: Assessment generators that surface-form–rename entities; multi-hop composition aligned with curriculum topics.
- Assumptions/dependencies: Instructor adoption; validation that renamed content remains semantically and ontologically consistent.
- Clinical and scientific assistant evaluation
- Sector: healthcare; pharma/biotech; scientific publishing
- Application: Test health/science assistants on synthetic-mapped corpora derived from medical/scientific KGs to verify robust reasoning and evidence grounding rather than parametric recall.
- Tools/workflows: “Clinical KA test” suites; reading comprehension mode to force citations; retrieval audits.
- Assumptions/dependencies: High-quality domain knowledge graphs; rigorous validation protocols for safety-critical advice.
- Internal synthetic corpora for secure agent testing
- Sector: software/AI; enterprises with proprietary KGs
- Application: Apply SynthWorlds’ surface-form renaming and document-generation pipeline to corporate knowledge graphs to create privacy-preserving testbeds for agents.
- Tools/workflows: Transformation service (entity/timestamp renaming); LM-driven doc synthesis; symbolic references for RM↔SM mapping.
- Assumptions/dependencies: Availability and cleanliness of internal KGs; API costs and quality controls; guardrails preventing accidental data leakage.
- Product “novelty mode” for assistants
- Sector: consumer AI assistants; B2B copilots
- Application: Offer a feature that estimates how well the assistant will perform in unfamiliar domains by running parallel RM/SM tasks and reporting a KA score.
- Tools/workflows: Lightweight KA probes; trigger “grounded mode” (page content provided) when KA is high.
- Assumptions/dependencies: UX for communicating uncertainty; computational budget for probes.
- IR/QA research baselines and reproducible studies
- Sector: academia; research labs
- Application: Use SynthWorlds as standard baselines for multi-hop reasoning and navigation; replicate KA findings across models and motifs; test new retrieval/agent methods.
- Tools/workflows: Shared datasets/prompts; motif-aware sampling; confidence intervals for F1/success.
- Assumptions/dependencies: Community adoption; stable releases of datasets and prompts.
Long-Term Applications
The following items require further research, scaling, standardization, or domain-specific adaptation.
- Standardized KA-gap certification and reporting
- Sector: policy/regulation; procurement; healthcare; finance
- Application: Develop formal standards for KA-gap measurement, reporting, and thresholds; third-party certification for generalization-to-novelty claims.
- Tools/products: Certification programs; standardized test suites per sector; independent labs.
- Assumptions/dependencies: Regulatory consensus; sector-specific corpora covering safety-critical workflows.
- Training curricula that minimize KA reliance
- Sector: AI model development
- Application: Design training regimes (e.g., RL from synthetic worlds, retrieval-aware objectives) that penalize overreliance on parametric memory and reward grounded reasoning.
- Tools/products: Curriculum schedulers; synthetic-world pretraining; retrieval+reasoning loss functions.
- Assumptions/dependencies: Stable signals that correlate with reasoning quality; compute budgets; avoidance of catastrophic forgetting.
- Domain-agnostic “Parallel World Simulators” (PWS)
- Sector: legal, finance, healthcare, public sector, industrial operations
- Application: SaaS platforms that auto-generate RM/SM corpora and tasks from domain KGs to stress-test agents for novelty, privacy, and safety.
- Tools/products: Data pipelines for entity renaming; LM doc synthesis tuned to domain genres; governance features.
- Assumptions/dependencies: Access to high-quality KGs; robust semantic consistency; cost-effective generation at scale.
- Agent architecture innovations for retrieval planning
- Sector: software/AI agents; search and knowledge management
- Application: New agent designs that integrate IRCoT-like loops, retrieval planning, memory gating, and content-grounding when novelty is detected.
- Tools/products: Retrieval planners; novelty detectors; memory firewalls to prevent shortcutting via parametric recall.
- Assumptions/dependencies: Reliable novelty detection; cooperative retrievers; interpretable agent state.
- Safety/privacy “memorization firewall”
- Sector: privacy/legal/compliance
- Application: Mechanisms to detect and block outputs based primarily on memorized proprietary or PII content, validated via SM stress tests.
- Tools/products: Memorization detectors; KA-based alarms; policy engines.
- Assumptions/dependencies: Accurate detection of parametric reliance; clear legal standards; minimal impact on usability.
- Education assessment reform and edtech products
- Sector: education; edtech
- Application: Widespread adoption of RM/SM parallel tasks for fair testing of reasoning growth; adaptive curricula that emphasize evidence-grounded answers.
- Tools/products: Assessment platforms; teacher dashboards; student feedback on reasoning chains.
- Assumptions/dependencies: Policy endorsement; teacher training; validation across subjects and levels.
- Cross-lingual and low-resource extensions
- Sector: global AI deployment; localization
- Application: Build SynthWorlds variants in multiple languages and domains to evaluate generalization beyond English and high-resource corpora.
- Tools/products: Multilingual NER, surface-form renaming modules; language-specific style generators.
- Assumptions/dependencies: High-quality linguistic resources; careful handling of name morphology and orthography.
- Dynamic, contamination-resistant benchmark ecosystems
- Sector: academia; AI vendors
- Application: Periodically regenerate synthetic worlds to avoid benchmark leakage into training data; maintain blind, rotating test suites.
- Tools/products: Benchmark rotation services; audit trails; contamination checks.
- Assumptions/dependencies: Community infrastructure; versioning; incentives to prevent overfitting.
- Scientific discovery and literature synthesis tools
- Sector: academia; R&D
- Application: Use KA-guided evaluations to improve systems that navigate and compose evidence from unfamiliar papers; measure how retrieval/planning upgrades translate to better hypotheses.
- Tools/products: Discovery copilots with IRCoT retrieval; motif-aware evidence synthesis; provenance tracking.
- Assumptions/dependencies: High-quality corpora; robust citation grounding; domain evaluation protocols.
- Enterprise search and UX improvements
- Sector: enterprise software; intranet search
- Application: Redesign search/browse experiences to leverage the finding that page content narrows the KA gap in novel environments—e.g., richer previews, contextual link annotations.
- Tools/products: Content+Links navigators; path suggestions; semantic link clustering.
- Assumptions/dependencies: Usable content metadata; scalable UI experiments; privacy controls.
- MLOps for reasoning generalization
- Sector: software engineering; DevOps/MLOps
- Application: KA-based regression tests in CI/CD; drift detection when KA widens; pre-deployment gates requiring minimal KA on critical tasks.
- Tools/products: KA monitors; alerting; policy-as-code integrations.
- Assumptions/dependencies: Repeatable test environments; cost budgets; organizational processes to act on alerts.
Glossary
- Agentic reasoning: An approach where LLMs act as agents that plan, decide actions, and use tools in multi-step tasks. "This task is broadly related to web navigation and agentic reasoning."
- Chain-of-thought (CoT): A prompting technique that elicits step-by-step reasoning from a model to solve complex problems. "IRCoT + RAG~\citep{trivedi-etal-2022-musique}, which interleaves retrieval with chain-of-thought reasoning, enabling iterative reasoning and retrieval steps"
- Closed-book: An evaluation setting where the model answers without access to external documents, relying solely on its internal parameters. "Closed-book, where the model has no access to documents and answers directly from its parametric knowledge"
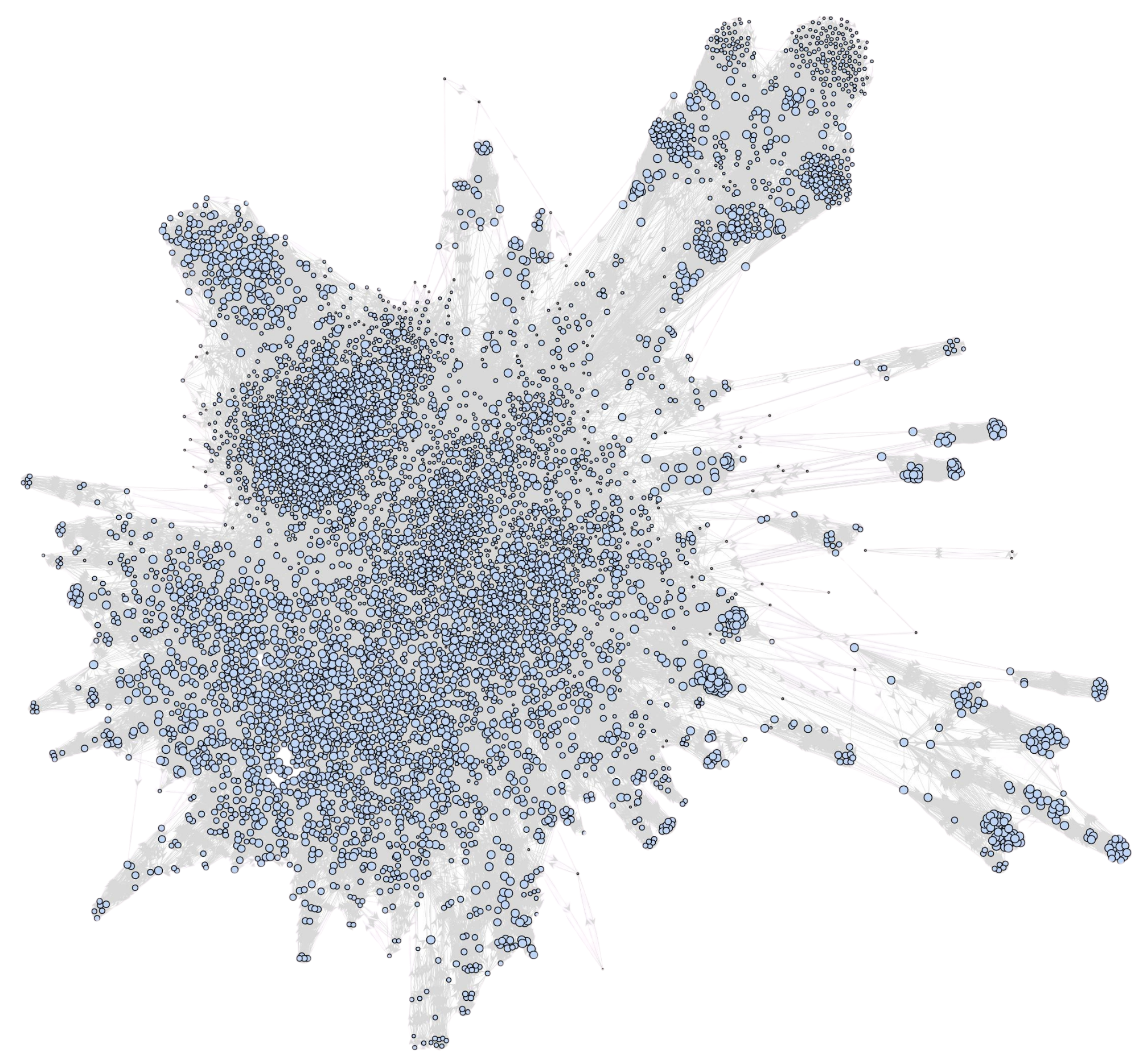
- Edge density: The ratio of existing edges to all possible edges in a graph, indicating sparsity or connectivity. "The hyperlink graph is sparse, with an edge density of 0.23\%."
- Expected random walk distance: The expected number of steps a random walker takes to travel between two nodes in a graph, used as a measure of navigation difficulty. "we use the expected random walk distance (i.e., expected number of steps for a random walk) between two nodes as a proxy for task difficulty"
- F1 score: A metric for answer correctness that combines precision and recall via their harmonic mean. "We report F1 scores on SynthWorld-RM ({RM}) and SynthWorld-SM ({SM}), along with the knowledge advantage gap"
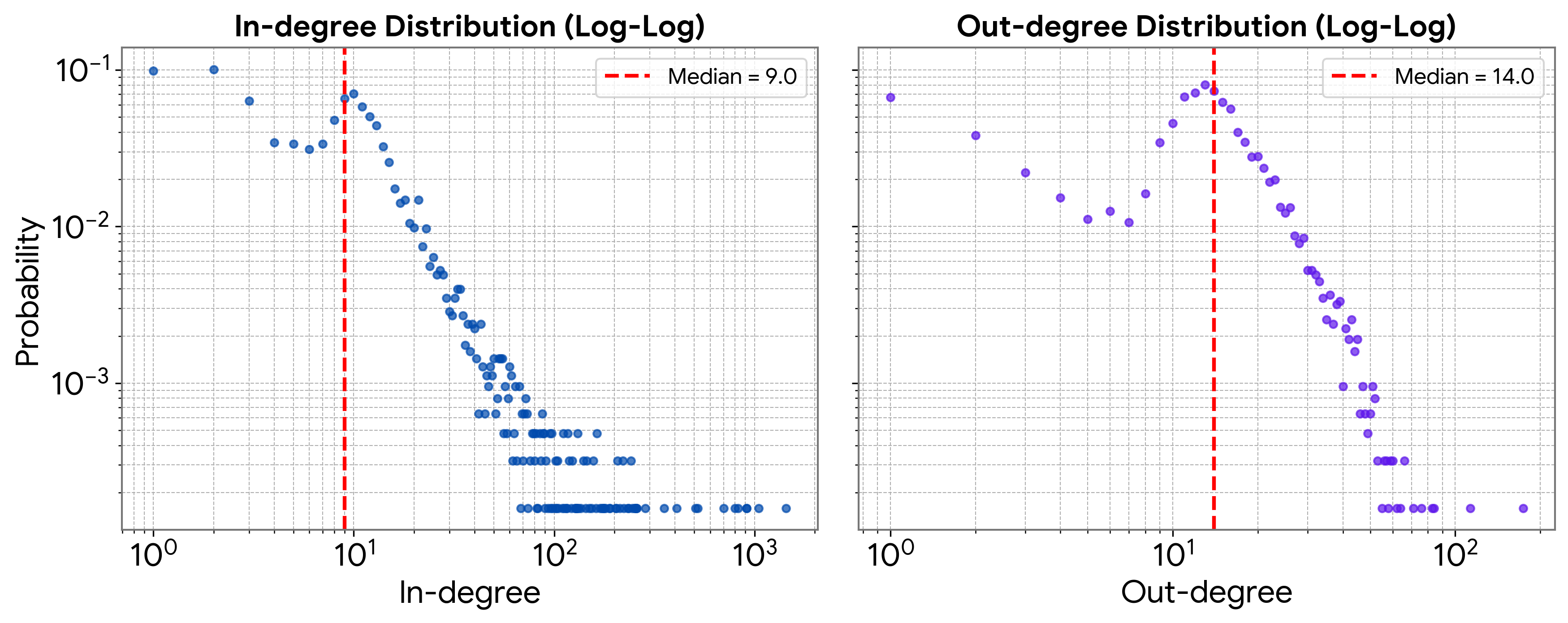
- Heavy-tailed degree distribution: A graph property where most nodes have few connections and a small number of nodes (hubs) have many, creating long tails in the distribution. "Its degree distribution is heavy-tailed: most pages have only a few links, while a small number act as hubs with disproportionately many incoming or outgoing connections."
- HippoRAG 2 (retriever): A retrieval system optimized for factual, multi-hop contexts used to fetch relevant documents. "For retrieval, we use the HippoRAG 2 retriever, designed for factual, multi-hop contexts"
- Interleaved Retrieval Chain-of-Thought (IRCoT): A method that alternates CoT reasoning with retrieval steps to iteratively refine evidence and answers. "IRCoT + RAG~\citep{trivedi-etal-2022-musique}, which interleaves retrieval with chain-of-thought reasoning, enabling iterative reasoning and retrieval steps"
- Knowledge advantage gap (KA): The performance difference attributable to parametric knowledge when comparing real-mapped and synthetic-mapped settings. "The knowledge advantage gap (KA) is the performance difference between parallel tasks mapped to {real-world} (RM) and {synthetic} (SM) entities."
- Knowledge augmentation: Providing external information (e.g., retrieved documents or page content) to enhance model performance beyond parametric memory. "knowledge augmentation (retrieval for QA, access to page contents for navigation)"
- Knowledge graph: A structured representation of entities and relations, often using triplets, that encodes interconnected facts. "triplet facts in a knowledge graph (\S\ref{sec:framework})."
- Multi-hop question answering (QA): Answering questions that require reasoning across multiple pieces of evidence or documents. "On top of these corpora, we design two mirrored tasks as case studies: multi-hop question answering and page navigation"
- Named entities: Proper nouns recognized as specific entities (e.g., people, places, organizations) by linguistic conventions or NER systems. "Practically, we define named entities as proper nouns (i.e., capitalized) in common usage~\citep{wikidata_help_label} or recognized by NER models"
- One-step RAG: A retrieval-augmented generation setup where the model performs a single retrieval round before answering. "One-step RAG, where the model retrieves supporting documents once before answering"
- Parametric world knowledge: Factual information stored in a model’s parameters from training data, used without external sources. "Evaluating the reasoning ability of LMs is complicated by their extensive parametric world knowledge"
- Power-law degree distribution: A degree distribution where the probability of a node having k links follows a power law, typical of many real-world networks. "Our corpora preserve the interconnected and structured nature of knowledge networks (i.e., power-law degree distribution), matching the complexity of real-world information ecosystems."
- Recall@5: A retrieval metric indicating whether the relevant item appears among the top five retrieved results. "We show Recall@5 for RAG baselines (by construction, CB has recall and RC has recall )."
- Reading Comprehension: An evaluation condition where the model is provided with the gold supporting documents (plus distractors) to assess reasoning separate from retrieval. "In addition, we include a Reading Comprehension condition in which the model is given all gold (2-4 documents depending on graph motif, examples in Table~\ref{tab:graph_types}) and additional distractor documents equaling 10 total."
- Random walk: A stochastic process that moves between nodes by randomly selecting outgoing edges at each step, used to model or measure navigation difficulty. "expected number of steps for a random walk"
- Scale-free topology: A network structure characterized by a few highly connected hubs and many nodes with few links. "SynthWorld-RM/SM Hyperlink Graph illustrating a scale-free topology, where a few highly connected hubs dominate while most nodes have relatively few links."
- Semantic consistency: Ensuring that surface forms remain compatible with the entity’s ontological type so names signal the correct categories (e.g., river-like names for rivers). "semantic consistency, where semantic consistency requires that surface forms remain compatible with the entity’s ontological type"
- Subgraph: A subset of a graph’s nodes and edges used to define specific reasoning motifs or tasks. "From this graph, we sample subgraphs $S \subseteq G_{\mathrm{facts}$ that match desired reasoning motifs"
- Surface-form perturbation: Systematic modification of entity names or timestamps while preserving type and contextual coherence to obscure parametric knowledge. "surface-form perturbation of named entities and timestamps"
- Symbolic references: Explicit markers inserted in text that link mentions to specific entities, used to construct hyperlinks and mappings. "We then insert symbolic references to entities in the text."
- Tool-use agents: LLM agents equipped with function-calling tools to interact with environments (e.g., clicking links, backtracking). "we follow the design of existing tool-use agents"
- Triplet facts: Facts represented as subject–relation–object triples, forming the basic units in knowledge graphs. "triplet facts (i.e., subject â relation â object)"
Collections
Sign up for free to add this paper to one or more collections.

