The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
Abstract: Real-world language agents must handle complex, multi-step workflows across diverse Apps. For instance, an agent may manage emails by coordinating with calendars and file systems, or monitor a production database to detect anomalies and generate reports following an operating manual. However, existing language agent benchmarks often focus on narrow domains or simplified tasks that lack the diversity, realism, and long-horizon complexity required to evaluate agents' real-world performance. To address this gap, we introduce the Tool Decathlon (dubbed as Toolathlon), a benchmark for language agents offering diverse Apps and tools, realistic environment setup, and reliable execution-based evaluation. Toolathlon spans 32 software applications and 604 tools, ranging from everyday platforms such as Google Calendar and Notion to professional ones like WooCommerce, Kubernetes, and BigQuery. Most of the tools are based on a high-quality set of Model Context Protocol (MCP) servers that we may have revised or implemented ourselves. Unlike prior works, which primarily ensure functional realism but offer limited environment state diversity, we provide realistic initial environment states from real software, such as Canvas courses with dozens of students or real financial spreadsheets. This benchmark includes 108 manually sourced or crafted tasks in total, requiring interacting with multiple Apps over around 20 turns on average to complete. Each task is strictly verifiable through dedicated evaluation scripts. Comprehensive evaluation of SOTA models highlights their significant shortcomings: the best-performing model, Claude-4.5-Sonnet, achieves only a 38.6% success rate with 20.2 tool calling turns on average, while the top open-weights model DeepSeek-V3.2-Exp reaches 20.1%. We expect Toolathlon to drive the development of more capable language agents for real-world, long-horizon task execution.
First 10 authors:


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Toolathlon (short for “Tool Decathlon”), a big test to see how well AI “agents” can do real, real-world tasks that take many steps and use many apps. Think of it like a school decathlon for AIs: instead of running and jumping, they have to schedule events, check emails, update databases, analyze spreadsheets, and more—often switching between tools like calendars, documents, stores, and servers.
Goals in Simple Terms
The researchers set out to answer a few clear questions:
- Can today’s top AI agents handle long, complicated tasks that look like real work, not just toy examples?
- How well do they switch between different apps (like email, calendars, spreadsheets, and databases) to finish one job?
- Can we build a fair, automatic way to check if the agent actually solved the task, not just wrote a good-sounding answer?
- Where do agents most often fail (for example, getting overwhelmed by long information or misusing tools)?
How They Did It (Methods)
To test agents properly, the team built a realistic playground and a strict scoring system.
Here’s what they set up:
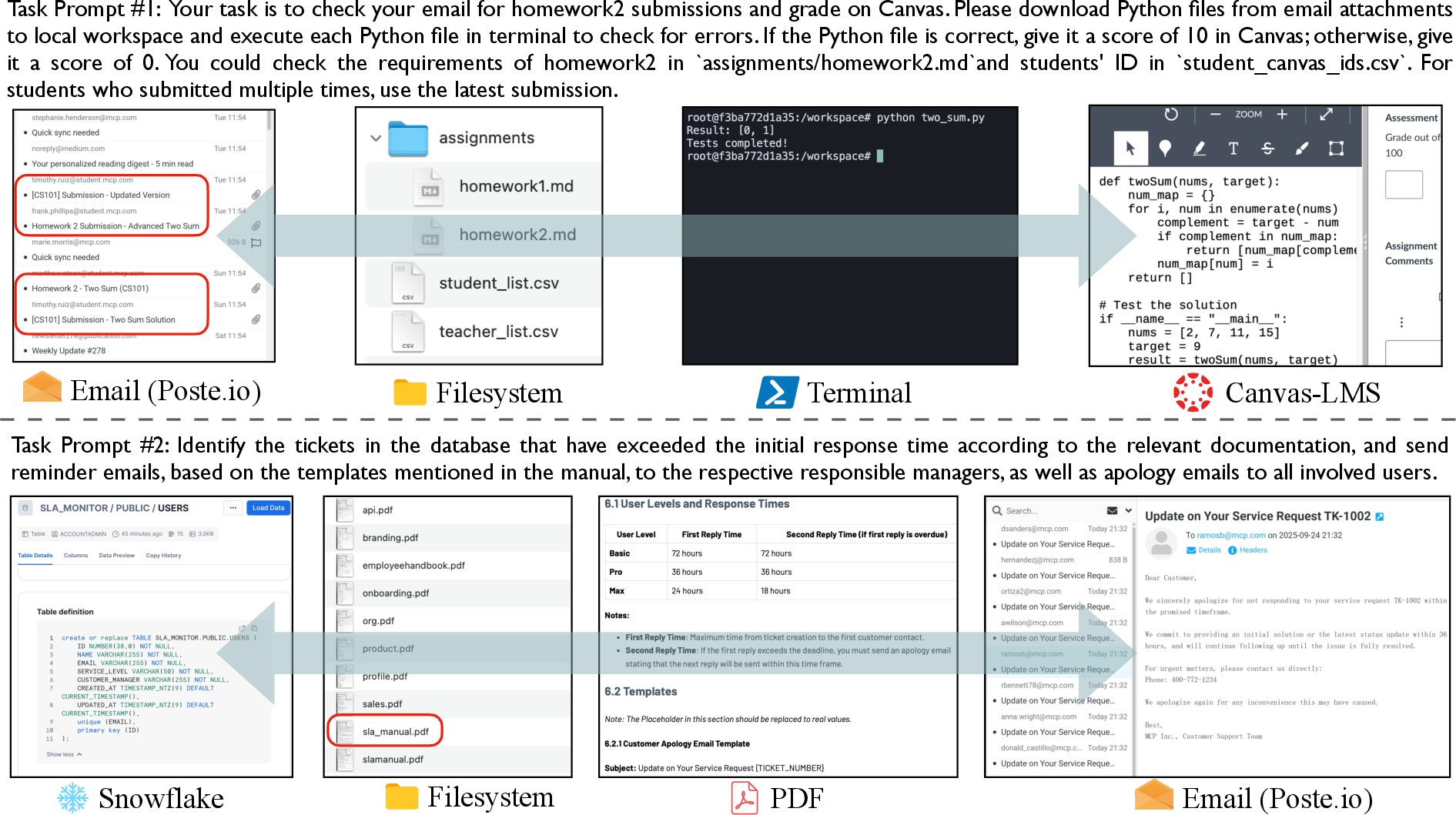
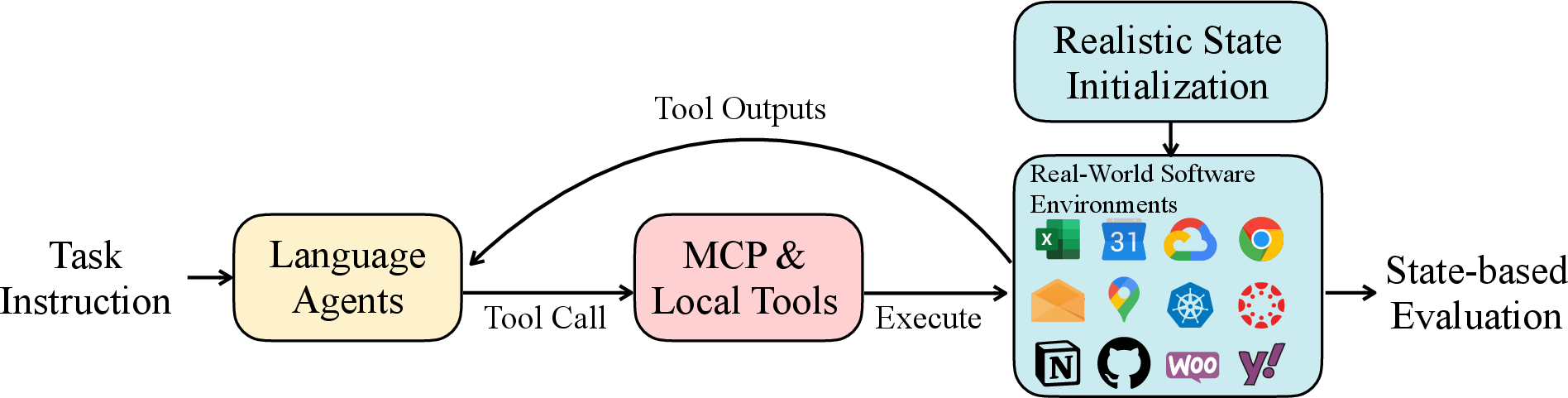
- A wide “toolbox” of real apps: They connected 32 real applications offering 604 tools. Examples include Google Calendar, Notion, Google Sheets, BigQuery (for data), Kubernetes (for servers), WooCommerce (for online stores), Canvas (for courses), and email systems. They used something called MCP (Model Context Protocol), which is like a standard plug that lets AIs talk to different apps safely and consistently.
- Realistic starting worlds: Instead of giving the agent an empty inbox or a blank spreadsheet, they started tasks with realistic data—like an inbox already full of emails or a course with dozens of students. This matters because real life is messy.
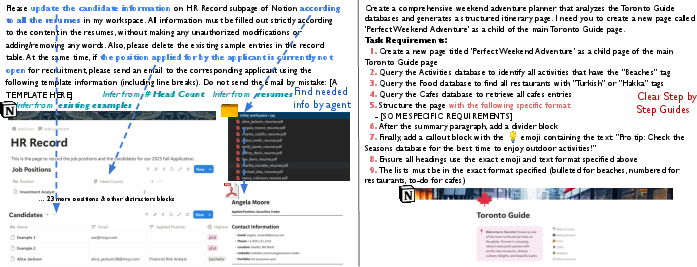
- Tasks that feel like actual requests: They built 108 tasks based on real needs (for example, “Update the HR records from a bunch of resumes” or “Check a database and send emails if tickets are late”). The instructions are “fuzzy” on purpose—like a real person’s short message—so the AI has to figure out what to do by looking around, not just follow a recipe.
- Long, multi-step work: Tasks often took about 20–27 tool calls (turns) to complete. Many required using more than one app in one job, like checking a database, reading a PDF manual, and then emailing people based on what was found.
- Safe, reliable scoring: Instead of asking another AI to “judge” answers, they wrote code to automatically check whether the final state is correct (for example, “Is the spreadsheet updated in exactly this way?”). This makes results fair and repeatable.
- Sandboxed test runs: They ran each task in its own container (like a safe, sealed sandbox) so tests wouldn’t interfere with each other and could run in parallel quickly.
A quick analogy for the tech terms:
- Tool calling: Asking an app to do something (like “add an event to Calendar”).
- MCP server: A universal power adapter that lets the AI plug into many different apps.
- Container: A safe box where one test runs without messing up others.
- “Execution-based evaluation”: Instead of grading the AI’s explanation, you check whether the actual apps and data got changed the right way.
Main Findings (Results)
The headline result: even the best current models struggled.
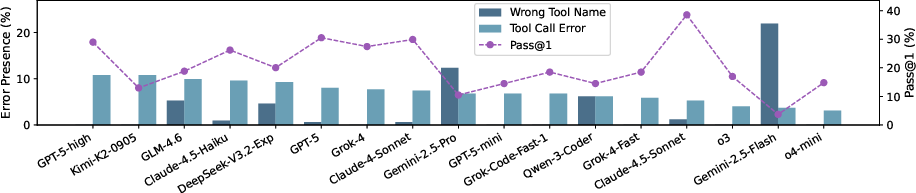
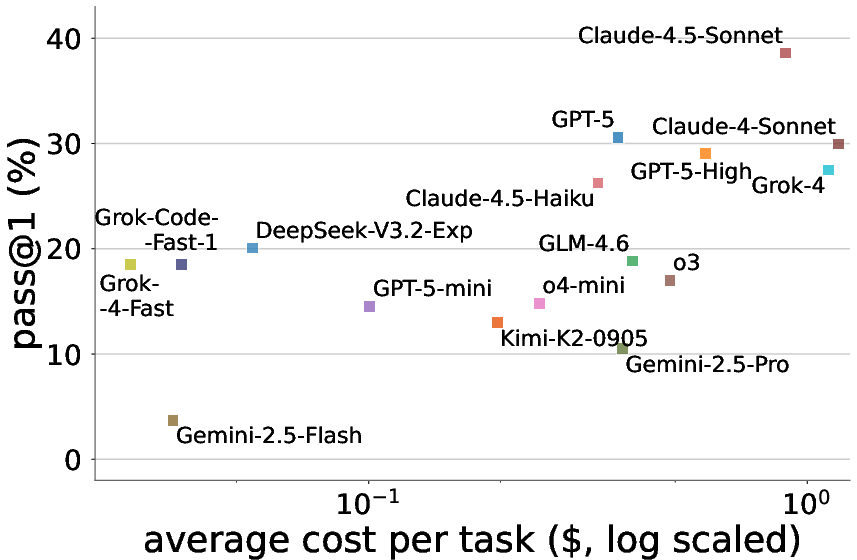
- The top model reached only about 38.6% success. The best open-source model reached about 20.1%.
- Most tasks needed around 20 tool calls. Longer tasks tended to be harder for nearly all models.
- Common stumbling blocks included:
- Tool errors: Sometimes the AI tried to call a tool with the wrong name or wrong settings. “Imaginary tools” (calling tools that don’t exist) hurt more than normal tool errors (which sometimes helped the AI learn from the error message).
- Overlong outputs: If a tool returned a very long result (like a huge web page or big database dump), many models got stuck or lost track.
- Not exploring enough: Some models stopped early or skipped steps instead of checking all the needed places.
- Thinking more didn’t always help: “Extra-reasoning” versions of models didn’t necessarily perform better. Exploring the environment and using tools well mattered more than just writing longer internal thoughts.
- Cost and efficiency: Some models were expensive per task; others were cheaper but less accurate. The best model wasn’t the costliest, and some low-cost models made decent budget-friendly options.
Why this is important:
- Real life is messy, multi-step, and cross-app. This benchmark shows that even strong models are far from dependable for many real workflows.
- It pinpoints where to improve next: handling long contexts, using tools robustly, and staying on track through many steps.
What This Means (Implications)
- For AI builders: Toolathlon gives a tough, realistic testbed to measure progress. Because the tasks and checks are open and automatic, teams can compare fairly and see exactly where their agents fail.
- For future agents: Success will require better planning across many steps, being careful with tools, handling long and noisy information, and staying persistent until the job is really done.
- For real-world use: Before trusting agents with business-critical workflows, we need models that can reliably operate across multiple apps and data sources. Toolathlon can guide that progress.
- For the community: This benchmark can speed up research on practical agents and help standardize how we evaluate them in complex, realistic settings.
Knowledge Gaps
Below is a consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research.
- Benchmark scope and coverage
- Limited task/app diversity: only 108 tasks and 32 apps; missing domains such as GUI/web browsing, mobile, robotics/IoT, speech, and multimodal vision-grounded tool use.
- English-only prompts and tasks; no multilingual or cross-lingual evaluation of tool-use agents.
- Single-agent focus; no multi-agent collaboration, delegation, or human-in-the-loop correction workflows.
- Few long-running or temporally extended workflows (e.g., background jobs, multi-day calendars), limiting assessment of persistence and temporal reasoning.
- Realism, external validity, and reproducibility
- Substituting real SaaS (e.g., Gmail/Shopify) with local clones (Poste.io/WooCommerce) may reduce external validity; generalization to production services is untested.
- Mixing remote SaaS with local containers raises reproducibility concerns (resetting remote states, API rate limits, time zones); protocols for consistent resets and rollback are not detailed.
- Authentication realities (OAuth/OIDC, 2FA, token refresh, permission scopes) are largely bypassed; how agents handle realistic auth flows remains unexplored.
- Dynamic tasks that rely on live data (e.g., shareholders, schedules) introduce non-determinism; the benchmark lacks controls for temporal drift, locale/time-zone variance, and data update frequency.
- Evaluation design and metrics
- Deterministic validators may reject legitimate alternative solutions, especially under fuzzy prompts; no mechanism for tolerant matching or equivalence classes of correct outcomes.
- No partial-credit metrics for subgoal completion, path optimality (turns/calls), safety violations, or recovery from errors; success/failure lacks granularity.
- Task difficulty is proxied by average turns across models, which is model-dependent; no model-agnostic difficulty indicators (e.g., branching factor, tool entropy, state ambiguity).
- Pass@k is reported from three runs only; no robust confidence intervals, significance testing, or power analysis across models.
- Overlong-output handling is framework-specific; absence of controlled ablations on chunking/streaming/summarization strategies and their effect on success.
- Tooling, interfaces, and maintenance
- Main setup provides only “useful” MCP servers per task; open-world tool discovery under large sets of irrelevant/unknown tools is not evaluated.
- Tool schema quality (naming, descriptions, parameter structures) and versioning are not audited; impact of schema clarity and updates on performance is unmeasured.
- Error taxonomy is narrow (hallucinated tools, execution errors); missing categories include permission/auth errors, idempotency, concurrency/race conditions, latency/timeouts, and rate limits.
- Long-term maintenance (API changes, tool deprecations, container image drift) and versioned leaderboards are unspecified.
- Agent/model configuration and fairness
- System prompts, tool-use instructions, temperatures, and retry policies per model are not fully disclosed; sensitivity to these parameters and fairness across providers is unclear.
- The framework relies on an OpenAI Agents SDK; portability and parity for providers with different tool APIs/runtimes are not validated.
- Cost analysis uses prompt caching and reports output tokens only; input/context tokens, tool I/O bandwidth, and differences in vendor caching semantics are not accounted for.
- Analysis depth and ablations
- Long-context challenges are noted but not dissected via controlled ablations (varying context window, memory/summarization policies, retrieval heuristics).
- No systematic ablations on the number of available tools, degree of cross-app orchestration, tool latency/failure injection, or unrelated-tool distractors.
- Planning and exploration failures (premature stopping, looping, under-exploration) are observed but not categorized or quantified beyond two error types.
- No cross-benchmark correlation (e.g., with SWE-Bench/WebArena/OSWorld) to validate that Toolathlon measures distinct/overlapping capabilities.
- Safety, security, and ethics
- Security posture of the evaluation environment (egress controls, secret handling, SSRF/file exfiltration risks) is not described; impact of security constraints on agent behavior is untested.
- No measurement of safety/compliance behaviors (e.g., avoiding destructive actions, PII handling, policy adherence) or of safe tool-use guardrails.
- Privacy considerations for realistic datasets (e.g., synthetic student records) are not detailed (data generation, masking, sanitization, retention).
- Generalization and robustness
- Robustness to API and schema changes, non-stationarity over time, and cross-version compatibility is not evaluated.
- Zero-shot adaptation to completely unseen applications/tools and schema induction from natural language are not tested.
- Transfer between local clones and real services, and across similar app families (e.g., different LMS/CRM variants), remains unmeasured.
- Scalability and operations
- Parallel evaluation is demonstrated at modest scale (10 concurrent tasks); scalability to hundreds/thousands of tasks, heavy tools (e.g., k8s), and multi-tenant settings is unassessed.
- Resource utilization (CPU/memory/disk/network) vs. performance trade-offs and cost ceilings per task are not characterized.
- Open questions for future work
- How do agents perform in open-world tool ecosystems with many irrelevant/unknown tools and evolving schemas?
- What validator designs can reliably accept multiple correct outcomes under fuzzy instructions without resorting to LLM judges?
- Which strategies most effectively mitigate overlong tool outputs (streaming, selective parsing, tool-internal paging, external retrieval)?
- How robust are results to authentication realisms, intermittent failures, rate limits, and network latencies typical of production SaaS?
- Can we design model-agnostic difficulty metrics and richer progress/safety scores that better reflect real-world agent quality?
Glossary
- Action space: The set of actions an agent can take; in this paper, the available tools for a task. "The action space $is the available tools for the respective task" - **Agent framework**: The scaffolding that runs the agent loop, manages tool calls, and handles context and errors. "We implement a simple agent framework based on the OpenAI Agents SDK (v0.0.15)" - **Agentic**: Relating to autonomous agent behavior in planning and execution. "In agentic scenarios, task difficulty is determined not only by the task instructions but also by the underlying environment states." - **CLI**: Command-line interface; text-based control of applications. "these tasks can also been solved via pure GUI or CLI workflow" - **Cluster orchestration**: Coordinated management of services across a compute cluster (e.g., via Kubernetes). "Kubernetes for cluster orchestration" - **Containers**: Isolated runtime environments used to package and execute software consistently. "Executing and evaluating each task is isolated in separate containers to prevent interference." - **Deterministic rules**: Evaluation criteria that yield the same results given the same state, without subjective judgment. "verifying the final environment states using deterministic rules offers a far more reliable and reproducible evaluation framework" - **Evaluation script**: A programmatic checker that verifies task success by inspecting environment state. "each task in Toolathlon is equipped with a unique, manually crafted evaluation script" - **Execution-based evaluation**: Assessing agents by actually running tools and checking resulting states rather than static predictions. "we think that execution-based evaluation is essential for reliably assessing language agents in realistic scenarios." - **Fuzzy Prompt**: An underspecified or ambiguous instruction that mimics real user input. "``Fuzzy Prompt'' represents that the task instructions are often fuzzy and ambiguous to mimic real user input (\S\ref{sec:task-source})." - **GUI**: Graphical user interface; visual point-and-click control of applications. "these tasks can also been solved via pure GUI or CLI workflow" - **Ground-truth states**: Authoritative target environment states used for validation. "comparing outcomes against either static or dynamically generated ground-truth states" - **Hallucinating non-existing tools**: A model invents tool names or calls tools that do not exist. "hallucinating non-existing tools (e.g., incorrect tool names)" - **LLM judges**: Using a LLM to grade agent trajectories instead of deterministic scripts. "many existing benchmarks rely on LLMs as judges to score agent trajectories" - **Locally containerized environments**: Self-hosted services deployed via containers to simulate realistic systems. "we also incorporate several open-source software deployed locally via containers" - **Long-horizon**: Tasks requiring many steps or turns and sustained context management. "performing real-world, long-horizon tasks" - **MCP (Model Context Protocol)**: A standard protocol for connecting language agents to external applications and tools. "the Model Context Protocol (MCP) has been proposed to establish a standard for connecting language agents to tens of thousands of applications" - **MCP servers**: Server implementations that expose applications via MCP tools. "we obtain a high-quality set of 32 MCP servers in total" - **Observation space**: The information an agent perceives at each step (inputs from the environment/tools). "the observations are the sequential input to the model." - **Open-weights model**: A model whose parameters are publicly available for self-hosting and fine-tuning. "the top open-weights model DeepSeek-V3.2-Exp" - **Overlong tool outputs**: Tool responses that are too large to process easily within context limits. "whether models can successfully complete tasks when encountering overlong tool outputs" - **Parallel evaluation**: Running multiple task evaluations concurrently for efficiency. "supports parallel execution to enable efficient model evaluation." - **Pass@1**: Fraction of tasks solved on the first attempt across repeated runs. "report the average pass@1 success rate" - **Pass@3**: Fraction of tasks with at least one correct trajectory across three runs. "We also include the pass@3 -- the fraction of tasks with at least one correct trajectory" - **Pass^3**: Fraction of tasks where all three trajectories are correct, indicating reliability. "and pass\textasciicircum3 -- the fraction of tasks where all three trajectories are correct" - **POMDP (partially observable Markov decision process)**: A decision process with hidden state where the agent acts based on observations. "Each task in Toolathlon can be formulated as a partially observable Markov decision process (POMDP)" - **Prompt caching**: Reusing cached computations/tokens for repeated prompts to reduce latency and cost. "with prompt caching enabled." - **Reference execution workflow**: A canonical set of steps used to fetch and verify real-time ground truth. "follow a reference execution workflow to dynamically retrieve and match real-time information" - **Reward function**: A mapping that scores outcomes, here representing success via state-based evaluation. "The reward function$ (\S\ref{sec:reliable-eval}) represents our execution-based evaluation"
- State initialization script: A program that sets up realistic starting environment states before evaluation. "each of these tasks is equipped with a state initialization script to set up the states at running time"
- Tool calling turns: The number of tool invocations within a trajectory, used as a proxy for task complexity. "Avg # Turns denotes the number of tool calling turns made by Claude-4-Sonnet"
- Tool execution errors: Runtime failures during tool calls (e.g., bad parameters or missing resources). "errors raised during tool execution."
- Transition function: The rule that defines how actions change the environment state. "the tool implementation directly defines the transition function."
- Trajectory: The sequence of observations, actions, and states across an episode. "interaction with them in long trajectories, present substantial challenges for generalization."
- Workspace isolation: Keeping each task’s files and processes separate to prevent interference. "providing strict workspace isolation."
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging Toolathlon’s open-source benchmark, realistic environment initialization, containerized evaluation harness, and deterministic, execution-based scoring.
- Industry (Software/IT/Agent Platforms): Pre-deployment vendor selection and bake-offs for agentic systems
- What: Use Toolathlon’s 108 cross-application, long-horizon tasks to compare agent vendors/models on Pass@1/Pass@3, reliability (Pass3), cost, token usage, and error rates under realistic states.
- Tools/workflows: “Agent QA suite” integrating Toolathlon containers, evaluation scripts, and cost tracking; KPIs wired into dashboards.
- Assumptions/dependencies: Access to Docker/Kubernetes, MCP servers or equivalent APIs, credentials/secrets management, and basic MLOps.
- Industry (Software/DevOps): Agent CI/CD and regression testing
- What: Gate model upgrades or policy changes with Toolathlon test runs; track regressions across tools (e.g., Kubernetes orchestration, BigQuery/Snowflake analytics, WooCommerce ops).
- Tools/workflows: CI jobs that spin up Toolathlon containers in parallel; “fail the build” on KPI drops; per-domain smoke tests.
- Assumptions/dependencies: Compute budget for parallel runs; stable secrets; job isolation for stateful tasks.
- Industry (Security/Safety/Trust): Red-teaming and diagnostics for tool-use agents
- What: Stress-test error handling (parameter/type errors, nonexistent tool hallucination), overlong outputs, and long-context robustness using Toolathlon’s failure analyses.
- Tools/products: “Agent Red Team Pack” that injects tool errors and monitors recovery; automated error taxonomy reports.
- Assumptions/dependencies: Logging/telemetry; ability to tune retries/policies; safe sandboxes for stateful tasks.
- Industry (Software Quality): MCP server QA and hardening
- What: Validate and improve in-house MCP servers against realistic multi-tool tasks; catch schema/permission edge cases and missing tool coverage.
- Tools/workflows: Conformance tests; contract tests per tool; coverage heatmaps.
- Assumptions/dependencies: MCP (or equivalent) adherence; versioned interfaces; fix loop for server/tool bugs.
- Industry (Ops/E-commerce/Finance/IT): Human-in-the-loop SOP-compliant orchestration pilots
- What: Deploy supervised agents for workflows Toolathlon already exercises (e.g., ticket triage via email+Notion, Kubernetes ops playbooks, WooCommerce catalog ops, BigQuery/Snowflake reporting).
- Tools/workflows: Plan–execute–check loops; SOP templates; deterministic checks adapted from Toolathlon evaluators.
- Assumptions/dependencies: Human approval gates; least-privilege credentials; rollback plans; acceptance criteria mirroring evaluation scripts.
- Industry (FinOps/Program Mgmt): Cost–performance sizing and policy setting
- What: Use benchmark cost and token telemetry to select models/settings that meet budget and reliability targets; set max-turns, chunking, and streaming summarization policies for overlong outputs.
- Tools/workflows: Cost simulators; token budgets; adaptive truncation/chunking strategies.
- Assumptions/dependencies: Accurate pricing; observability; rate-limit management.
- Academia (AI/ML/SE): Reproducible research on long-horizon, tool-using agents
- What: Use Toolathlon to study planning vs exploration, error recovery, memory, and the impact of overlong outputs; compare prompting vs policy learning.
- Tools/workflows: Offline analysis of trajectories; ablation suites; shared leaderboards.
- Assumptions/dependencies: Compute and storage for logs; consistent seeds; IRB/ethics review if using human raters.
- Academia (Education/EdTech): LMS agent prototyping and evaluation
- What: With Canvas container environments and realistic state init, test agents for roster/gradebook management, announcements, and scheduling.
- Tools/workflows: Course ops SOPs; deterministic checks for assignment/setup correctness.
- Assumptions/dependencies: Institutional IT policies; FERPA/privacy constraints for real data.
- Academia/Industry: Training material and coursework
- What: Build assignments and labs on agent evaluation, MCP server design, and state initialization scripts.
- Tools/workflows: Prebuilt Toolathlon tasks; rubrics from deterministic evaluators.
- Assumptions/dependencies: Instructional compute; container access for students.
- Industry/Policy: Procurement readiness and model governance
- What: Require Toolathlon performance thresholds in RFPs for agent vendors; track Pass@K and safety diagnostics as governance KPIs.
- Tools/workflows: Evidence packets with reproducible runs; model/cards with Toolathlon scores.
- Assumptions/dependencies: Legal/contract terms; reproducibility policy; periodic re-validation.
- Industry (AgentOps/Observability): Production monitoring mapped to benchmark metrics
- What: Mirror Pass@K and error presence ratios in production; alert on deviations from benchmark baselines.
- Tools/workflows: “AgentOps” dashboards correlating tool failures, overlong outputs, early termination; canary runs on Toolathlon.
- Assumptions/dependencies: Telemetry hooks; privacy-safe logging.
- Daily life (Power users/SMBs): Choosing practical personal/SMB agents and guardrails
- What: Use public Toolathlon scores to pick models for Notion, Calendar, email triage, and basic e-commerce operations, with human approval before execution.
- Tools/workflows: Checklists and reversible changes; simple “dry-run then apply” patterns.
- Assumptions/dependencies: Risk tolerance; backup/restore; API quotas and costs.
Long-Term Applications
The following concepts require further research, domain adaptation, scaling, or regulatory frameworks before broad deployment.
- Policy/Standards: Agent certification and compliance benchmarks
- What: Create ISO-like certifications for tool-using agents tied to deterministic, execution-based suites (e.g., domain variants of Toolathlon).
- Sectors: Finance, healthcare, public sector, critical infrastructure.
- Assumptions/dependencies: Multi-stakeholder standards bodies; auditable runs; secure sandboxes; incident reporting.
- Policy/Procurement: Agent SLAs and contractual guarantees
- What: Standardize SLAs (e.g., Pass@1 thresholds, max error incidence) backed by reproducible benchmark evidence and periodic audits.
- Sectors: Government procurement, regulated industries.
- Assumptions/dependencies: Legal enforceability; fair test access; version pinning of tools/states.
- Healthcare: Benchmarking and safe deployment for clinical ops agents
- What: A healthcare Toolathlon variant with EHR sandboxes, scheduling, secure messaging, billing/coding, and SOP adherence.
- Products/workflows: “ClinOps Agent QA,” HIPAA-compliant evaluation enclaves.
- Assumptions/dependencies: Synthetic-yet-realistic patient data; vendor EHR sandboxes; strong privacy/security posture; clinical oversight.
- Energy/Utilities: Grid and asset management assistants
- What: Agents coordinating work orders, SCADA-like dashboards, asset logs, and compliance reporting via tool interfaces.
- Products/workflows: “UtilityOps Agent Bench” with deterministic compliance checks.
- Assumptions/dependencies: Secure ICS emulation; safety constraints; NERC/CIP compliance.
- Finance: Front/middle/back-office orchestration with auditability
- What: Agents that reconcile transactions, generate regulatory reports, and triage anomalies across data warehouses and ticketing systems.
- Products/workflows: “RegOps Agent Suite” with immutable audit logs, deterministic verification.
- Assumptions/dependencies: Access to synthetic but realistic ledgers; strong controls; regulator-approved sandboxes.
- Education: Autonomous course management at scale
- What: Agents handling course setup, grading pipelines, proctoring logistics, and student communications across LMS and email/calendar.
- Products/workflows: “LMS Agent Copilot” with policy-aware templates and auto-evaluation.
- Assumptions/dependencies: Institutional governance; accommodation policies; human escalation.
- Industry (Enterprise SaaS): Robust, cross-app enterprise copilots with auto-remediation
- What: Agents that reliably orchestrate tasks across CRM, ERP, ITSM, data warehouses, and cluster managers with policy-checked outcomes.
- Products/workflows: Memory-augmented planning, error-aware retries, overlong-output chunking, and state diffs pre/post execution.
- Assumptions/dependencies: Advances in long-context modeling, exploration strategies, and tool-error-aware learning; end-to-end audit trails.
- Research/ML: New training paradigms for reliable tool-use
- What: RL/IL on execution traces; exploration-aware reward design; curriculum over realistic initial states; retrieval-augmented planning.
- Products/workflows: Open logs and evaluators; “plan-conditioned” policies; auto-curriculum generators.
- Assumptions/dependencies: High-quality trajectories; safety filters; compute for RL.
- Ecosystem: Registry/marketplace of validated MCP servers and tools
- What: A public catalog with conformance reports, domain tags, failure modes, and versioned evaluation artifacts.
- Products/workflows: “MCPConform” badges; SBOM-like manifests for tooling stacks.
- Assumptions/dependencies: Community governance; CI-backed validation; security vetting.
- Risk/Insurance: Underwriting for agent-driven operations
- What: Use benchmarked reliability and safety metrics to price risk and define coverage terms for agentic workflows.
- Products/workflows: “Agent Risk Score” derived from deterministic evaluations and production telemetry.
- Assumptions/dependencies: Accepted metrics; access to loss data; regulatory acceptance.
- Privacy/Security: Confidential evaluation enclaves and data governance
- What: Secure, privacy-preserving evaluation environments with realistic data distributions and reproducible scoring.
- Products/workflows: TEEs/VPC sandboxes; data synthesis pipelines; secure artifact registries.
- Assumptions/dependencies: Trusted hardware or equivalent; synthetic data quality; governance frameworks.
- Human–Agent Teaming: Adaptive escalation and reliability-first UX
- What: UX patterns that route complex/ambiguous steps to humans, with the agent resuming after verification; measurable uplift over full autonomy.
- Sectors: Healthcare, finance, IT ops, customer support.
- Assumptions/dependencies: Effective handoff APIs; role-based permissions; change management.
Notes on feasibility and assumptions (cross-cutting)
- Tool access and credentials: Many applications assume MCP or equivalent API connectivity, with least-privilege credentials and secret rotation.
- State realism: Deterministic evaluation depends on realistic initial states; domain variants (e.g., healthcare, finance) require high-quality synthetic data and legal review.
- Safety and governance: Given current Pass@1 ceilings (~38.6% best-in-class on Toolathlon), critical workflows require human-in-the-loop, guardrails, reversible changes, and strong auditability.
- Cost and rate limits: Budgeting and throttling policies must be set, as long-horizon tasks can be token- and cost-intensive.
- Compute and isolation: Containerized, parallel evaluation requires adequate compute and strict isolation to avoid state leakage.
Collections
Sign up for free to add this paper to one or more collections.

