Routing with Generated Data: Annotation-Free LLM Skill Estimation and Expert Selection
Abstract: LLM routers dynamically select optimal models for given inputs. Existing approaches typically assume access to ground-truth labeled data, which is often unavailable in practice, especially when user request distributions are heterogeneous and unknown. We introduce Routing with Generated Data (RGD), a challenging setting in which routers are trained exclusively on generated queries and answers produced from high-level task descriptions by generator LLMs. We evaluate query-answer routers (using both queries and labels) and query-only routers across four diverse benchmarks and 12 models, finding that query-answer routers degrade faster than query-only routers as generator quality decreases. Our analysis reveals two crucial characteristics of effective generators: they must accurately respond to their own questions, and their questions must produce sufficient performance differentiation among the model pool. We then show how filtering for these characteristics can improve the quality of generated data. We further propose CASCAL, a novel query-only router that estimates model correctness through consensus voting and identifies model-specific skill niches via hierarchical clustering. CASCAL is substantially more robust to generator quality, outperforming the best query-answer router by 4.6% absolute accuracy when trained on weak generator data.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
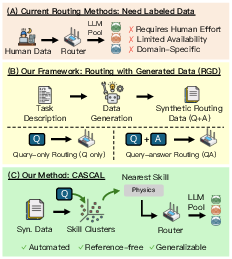
Imagine you have a team of different AI “students” (LLMs). Each one is good at some things and not so great at others. You’re the coach who needs to decide which student should answer each new question to get the best result. That decision-making system is called a “router.”
The big problem: in real life, we often don’t have an answer key (no labeled data) to train this router. So this paper studies how to train a router using practice questions made by an AI (not by humans). The authors call this setting Routing with Generated Data (RGD) and introduce a new method, CASCAL, that chooses experts without needing answer keys.
What questions the paper tries to answer
The authors focus on three simple questions:
- If we train routers on AI-made practice data, how well do popular routing methods work?
- What makes good AI-generated practice data for training a router?
- Can we improve the quality of this generated data (and how)?
How they did it (explained with plain language)
First, they set up a realistic training environment:
- They ask a “generator” AI to create practice questions (and sometimes answers) from short descriptions of tasks (like math, medicine, trivia).
- They gather a pool of different AI models (some big, some small) to act as the “team” the router can choose from.
- They test on real benchmark questions (the test set) but train only on the AI-generated practice questions (the training set).
They compare two kinds of routers:
- Query-answer routers: These assume you have both the question and the correct answer during training (they try to learn “who is correct” using the answer key). With generated data, the “answer key” is written by the generator AI, which might be wrong.
- Query-only routers: These see only the questions and what each model answered (no answer key). They must infer who’s likely correct by patterns of agreement.
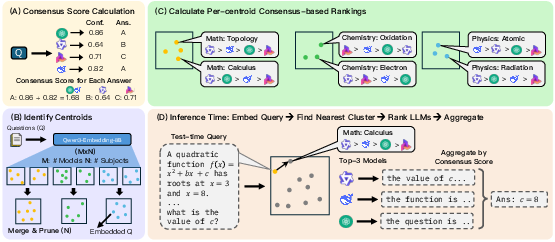
They propose a new query-only router called CASCAL. Here’s how CASCAL works, step by step:
- Consensus (voting with confidence): For each practice question, all models in the pool answer. If many models give the same answer—and especially if they sound confident—that answer probably has a higher chance of being correct. CASCAL turns that idea into a score for each model and question. Think of it like: if most teammates agree and the most confident ones agree, that answer counts more.
- Finding “skill groups”: CASCAL groups similar questions together (like “basic algebra” vs “biology facts”) by looking at the questions’ meanings. Within each group, it figures out which models tend to do best (based on the consensus scores). This helps discover “niches,” the special areas where a model shines.
- Test-time routing: For a new question, CASCAL finds the most similar group and picks the top model(s) for that group. It can either choose one best model or pick a few and let them vote.
Key idea in everyday terms: CASCAL is like a coach who watches scrimmage games (practice without refs) to see where each player does well, then assigns players to plays where they’re strongest, and sometimes asks the top three to vote on the final move.
What they found and why it matters
Here are the main takeaways:
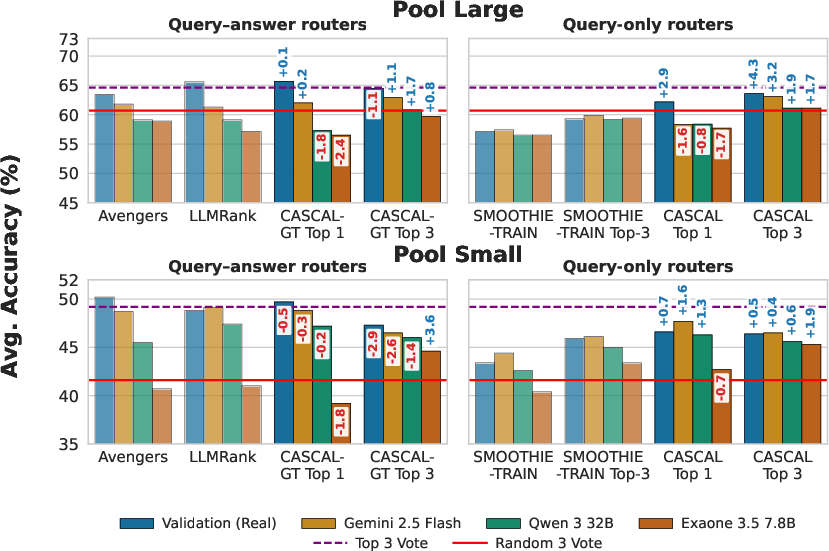
- Query-only wins when answers are unreliable: When the practice answers are written by a weaker AI (and can be wrong), routers that depend on those answers get confused. Query-only methods, like CASCAL, don’t rely on those labels and stay more accurate.
- CASCAL is robust and often better: CASCAL stays strong even when the generator is weak. When trained on data from a weaker generator, CASCAL beat the best answer-based router by about 4.6 percentage points in accuracy on average.
- What makes good generated data?
- The generator should be able to answer its own questions correctly (so labels aren’t misleading).
- The questions should separate the models—meaning some models succeed and others fail—so the router can see differences in skill.
- Smart filtering helps a lot: Even if your generator is small, you can filter the practice questions to keep the ones where:
- The strongest models agree with each other (likely correct), and
- The weaker models disagree (meaning the question actually reveals skill differences).
- This filtering noticeably improved performance, sometimes matching or beating training on real (human) data.
Why this matters: In many real situations, you don’t have time or money to collect lots of human-labeled examples. This paper shows you can still build a good router by generating and filtering smart practice data—and by using a method like CASCAL that relies on model agreement rather than answer keys.
What this could change (implications)
- Cheaper, faster setup: Teams can set up intelligent routing without expensive labeled datasets. That’s useful for startups, internal company tools, or new domains where labeled data doesn’t exist.
- Better use of model “specialties”: By finding niche skills, routers can reliably send questions to the models most likely to nail them, improving accuracy and possibly lowering costs (you don’t always need the biggest model).
- Practical guidance for data generation: If you must use a weaker generator, focus on:
- Writing questions that highlight differences between models.
- Filtering for questions where strong models agree and weak models do not.
- Future directions: Tools could automatically generate and “sharpen” training data (for example, by rewarding questions that maximize useful disagreements), making routing even stronger without human labels.
In short: Even without an answer key, you can still pick the right AI for the job. Let the models “vote,” discover their specialties, and train your router on carefully generated and filtered practice questions. That’s the heart of RGD and CASCAL.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research.
- Generalization beyond discrete, multiple-choice tasks: how to extend CASCAL’s consensus scoring and aggregation to open-ended generation, program synthesis, numeric answers, and free-form reasoning where “agreement” is non-trivial.
- Dependence on token-level log-probabilities: many API models do not expose logprobs or expose incomparable confidences across models; investigate confidence proxies and cross-model calibration so consensus weights are reliable.
- Majority-vote failure modes: analyze and mitigate correlated errors where the majority is wrong (e.g., via truth discovery, Dawid–Skene, robust aggregation), and provide theoretical guarantees or bounds for consensus correctness.
- Clustering sensitivity: quantify how routing depends on the choice of embedding model, k-means/hierarchical parameters, centroid merging thresholds, and distance metrics; provide ablations and stability analyses.
- Task assignment assumptions: the method presumes a known task taxonomy and assigns queries by embedding similarity; design mechanisms for unknown/new tasks, mixed-intent queries, and OOD detection.
- Scalability and training cost: training collects responses from all models over large synthetic sets, which is expensive; develop budget-aware variants (e.g., active sampling, subsampling models, progressive labeling).
- Dynamic model pools: study how to add/remove models or update versions without retraining from scratch, including incremental cluster updates and re-ranking.
- Multilingual and domain generalization: evaluate routing on non-English, domain-specific jargon, and specialized tasks (e.g., legal, finance, programming) to test cross-lingual and cross-domain robustness.
- Real-world validation: test on production logs with heterogeneous, non-stationary user intents rather than curated benchmarks; measure robustness under real traffic distributions.
- Cost/latency trade-offs: quantify economic and latency costs of Top-3 aggregation versus Top-1 routing; design cost-aware routers that adapt k based on budget and difficulty.
- Adversarial robustness: assess resistance to prompt attacks and adversarial queries that intentionally disrupt consensus or cluster assignments; develop defenses.
- Label quality without strong references: for datasets where silver models (e.g., Gemini) are unreliable, create unsupervised or weakly-supervised methods to audit generator answer quality.
- Filtering bias: the proposed filter privileges “top-2” models from the same pool; evaluate fairness and potential bias, and explore pool-agnostic filters that avoid entrenching specific models.
- Generator optimization: formalize and implement RL-style rewards for “self-answerability” and “performance differentiation,” and test whether optimized generators transfer across model pools and tasks.
- Handling abstentions and multi-output responses: specify how consensus scoring treats refusals, non-answers, ties, or multiple plausible choices; design robust extraction and tie-breaking.
- Adaptive ensemble size: study adaptive k (number of experts per query) based on estimated difficulty/uncertainty, and its impact on accuracy, cost, and latency.
- Cross-model calibration: develop methods to calibrate confidence across heterogeneous models (e.g., temperature scaling, ECE/Brier-guided calibration), ensuring Z-score normalization is meaningful across models.
- Error localization: provide per-task and per-cluster error analyses to identify failure hotspots and guide improved cluster construction or targeted query generation.
- Cluster interpretability: add topic labels or explanations for clusters to support debugging and human oversight; evaluate whether interpretable clusters improve routing or trust.
- Embedding drift and versioning: measure how updates to the embedding model (e.g., Qwen3-Embedding) affect cluster stability and routing; design embedding-invariant clustering or re-indexing strategies.
- Adapting CASCAL to continuous/open-ended evaluation: propose automatic agreement metrics (semantic similarity, factuality checks) to recover consensus for non-discrete tasks dropped from BBEH.
- Consensus weight design: compare Z-score weighted consensus to alternatives (entropy/margin-based weights, temperature scaling, Platt scaling) and study robustness under different weighting schemes.
- Leakage and descriptor bias: automate leakage detection when task descriptions are built from seed examples and develop prompts/protocols to minimize overfitting to seeds.
- Transfer to unseen datasets: evaluate whether routers trained on generated data for a domain can transfer to new but related tasks without regeneration, and identify necessary adaptation steps.
- Bias and ethics: audit whether consensus and filtering amplify demographic or domain biases present in generated data; introduce fairness constraints into routing and data generation.
- Ranking stability theory: formalize conditions under which high top-rank stability yields routing above random despite low Kendall’s τ; derive sample complexity requirements.
- Broader evaluation metrics: move beyond accuracy to include calibration, F1, preference alignment, and partial credit—especially for long-form tasks—and adapt routing objectives accordingly.
- Continual/online learning: design mechanisms for updating clusters and rankings with streaming queries and responses while avoiding catastrophic forgetting and maintaining stability.
- Confidence estimation for black-box/non-deterministic models: develop sampling-based or response-feature-based confidence estimates where logprobs are unavailable or stochasticity is high.
- Interaction with debate/coordinated agents: compare single-round consensus to multi-round debate or coordination frameworks (MAD, Reconcile); identify when debate helps or hurts under RGD.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, leveraging the paper’s findings (RGD) and methods (CASCAL), organized by sector and typical workflows.
- Industry (Software, Customer Support, Knowledge Management): Label-free multi-model routing for discrete QA and classification
- Use case: Route each incoming ticket or FAQ query to the best-performing LLM(s) without needing ground-truth labels; aggregate responses via consensus voting to reduce error rates.
- Tools/products/workflows: CASCAL router integrated into an inference gateway; generator-driven “RGD profiling” pipeline (task descriptions → synthetic queries → model responses → clustering); top-3 consensus aggregator; telemetry dashboards for cluster-level model rankings.
- Assumptions/dependencies: Access to a pool of models/APIs; tasks can be cast as discrete outputs (e.g., multiple choice, categorical labels); reliable text embeddings; generator quality impacts performance but CASCAL is robust to weaker generators; monitoring for domain drift.
- Industry (Finance): Compliance Q&A routing and content classification
- Use case: Automatically route compliance questions (e.g., policy interpretation, disclosure classification) to expert models; ensemble voting reduces hallucinations and improves consistency.
- Tools/products/workflows: CASCAL Top-3 with consensus; filtered RGD queries focusing on high-difficulty, high-consensus samples for compliance domains; model-ranking dashboards to support internal audits and procurement.
- Assumptions/dependencies: Well-scoped compliance categories (discrete labels); careful prompt design for task descriptions; governance over vendor model usage; periodic re-profiling as regulations evolve.
- Industry (Healthcare): Medical MCQ, coding, and decision-support triage
- Use case: Route medical multiple-choice queries (e.g., MedMCQA-like tasks), clinical coding suggestions, or triage classifications to the most reliable model(s); aggregate with consensus to improve robustness.
- Tools/products/workflows: CASCAL router and consensus aggregator; RGD generation for specialty-specific subject clusters; confidence-weighted consensus signals in the audit log.
- Assumptions/dependencies: High-stakes domain—use only for decision support, not autonomous decisions; discrete task framing; privacy-preserving infrastructure; clinical validation and oversight.
- Industry (Content Moderation and Safety): Routing moderation decisions and safety checks
- Use case: Select best moderation/safety model per prompt category (toxicity, self-harm, policy violation) and aggregate outcomes for stronger guardrails.
- Tools/products/workflows: CASCAL clusters aligned to safety policy taxonomies; consensus-based aggregation; periodic RGD filtering to retain variance-inducing queries that differentiate model capabilities.
- Assumptions/dependencies: Clear, discrete policy categories; continual updating as adversarial behaviors evolve; correlation among models can affect consensus reliability.
- Academia (Evaluation/Benchmarking): Label-free model capability profiling and ensemble evaluation
- Use case: Build skill maps of model strengths across subjects without ground-truth labels; compare open-weight models using synthetic routing data when real labels are scarce.
- Tools/products/workflows: CASCAL codebase; RGD data generation and filtering pipeline (top-2 consensus + difficulty filter); Kendall’s τ correlation analysis to assess ranking fidelity; cluster visualizations.
- Assumptions/dependencies: Tasks with discrete outputs; embedding quality for clustering; stronger generators yield better rankings, but CASCAL remains robust to weaker ones.
- MLOps (Cost/Performance Optimization): Top-1 vs. Top-3 routing policies and ensemble gates
- Use case: Deploy Top-1 routing for latency/cost-sensitive paths and Top-3 with consensus for accuracy-critical paths; fall back to stronger models for queries mapped to “hard” clusters.
- Tools/products/workflows: Routing policies in a serving gateway; dynamic gates driven by consensus score distributions; A/B testing on filtered synthetic queries to estimate ROI.
- Assumptions/dependencies: Multi-model access; cluster assignment stability; compute budget for multiple inferences when using ensembles.
- Procurement and Vendor Selection: Synthetic benchmarks for vendor evaluation without labels
- Use case: Generate domain-specific query sets (via RGD), measure consensus-based correctness proxies, and rank vendors by niche skill clusters.
- Tools/products/workflows: RGD generation tuned by filtering (strong-agreement + differentiation); procurement dashboards with per-cluster ranking; reproducible evaluation harness.
- Assumptions/dependencies: Task descriptions representative of real workloads; access to vendor APIs; acknowledging that synthetic queries may not perfectly mirror production distributions.
- Daily Life (Power-user tooling): Meta-assistant for discrete tasks (e.g., math MCQs, exam prep)
- Use case: A lightweight app routes multiple-choice questions to the best open model(s) and returns consensus answers with confidence, especially for STEM or quiz prep.
- Tools/products/workflows: Local or cloud meta-assistant integrating CASCAL Top-3; on-device embeddings for routing; cached skill clusters for popular subjects.
- Assumptions/dependencies: Discrete format (MCQs); internet/API access for multiple models; cost considerations; suitable for study aid, not authoritative advice.
Long-Term Applications
These opportunities require further research, scaling, validation, or adaptation beyond the current settings (e.g., handling open-ended outputs, multimodality, streaming drift).
- Industry (General): Routing for open-ended generation and semantic consensus
- Use case: Extend CASCAL to free-form tasks (summarization, reasoning) by using semantic equivalence metrics or learned aggregators (e.g., LLM-based evaluators) instead of exact-match voting.
- Tools/products/workflows: Semantic scorers (entailment, factuality), self-consistency and debate-style aggregation, calibration layers for correlated errors.
- Assumptions/dependencies: Reliable automatic equivalence/factuality scoring; robustness to correlated model mistakes; additional compute and latency budgets.
- RL-driven Data Generation (All sectors): Optimized RGD for maximal differentiation and routing quality
- Use case: Train generator agents to produce queries that best separate models by cluster and consensus quality; continuously refine the routing dataset with feedback loops.
- Tools/products/workflows: Reinforcement learning for query generation (rewarding variance and high-confidence consensus); iterative retraining of routers; data curation dashboards.
- Assumptions/dependencies: Safe RL loops; guardrails to prevent generator drift or adversarial prompt leakage; periodic human-in-the-loop checks in high-stakes domains.
- Multimodal Routing (Healthcare imaging, Robotics, Education): Consensus across text+vision+audio models
- Use case: Route multimodal tasks (e.g., radiology classification, instruction following in robotics, lecture comprehension) to specialized expert models with multimodal consensus.
- Tools/products/workflows: Multimodal embeddings and clustering; cross-modal consensus estimators; domain-specific filters for difficult samples.
- Assumptions/dependencies: Strong multimodal embedding backbones; discrete target labels or robust equivalence measures; higher compute requirements.
- Streaming/Online Adaptation (MLOps): Continual clustering and drift-aware routing
- Use case: Update skill clusters and model rankings as data distributions shift; implement exploration/exploitation strategies for newly emerging niches.
- Tools/products/workflows: Online clustering; adaptive gates; drift detectors; telemetry-driven re-profiling; canary routing for unexplored clusters.
- Assumptions/dependencies: Stable embedding space over time; robust drift monitoring; careful budget management for continual re-profiling.
- Routing-as-a-Service (Industry/Cloud): Brokered marketplaces for expert selection
- Use case: Cloud services expose routing endpoints that select among third-party models, with cluster-resolved skill maps and consensus-based SLAs.
- Tools/products/workflows: SaaS routers; standardized APIs for model pools; transparent reporting of cluster-wise performance; cost/latency-aware selection policies.
- Assumptions/dependencies: Vendor cooperation and standardized telemetry; governance over data usage; commercial agreements and compliance.
- Policy and Governance: Standards for transparent routing, bias monitoring, and auditability
- Use case: Develop guidance for using label-free routing in regulated settings, including reporting model consensus, disagreement, and cluster-level error analysis.
- Tools/products/workflows: Audit trails capturing consensus scores and cluster assignment; fairness and bias checks per cluster; procurement best practices using synthetic evaluations.
- Assumptions/dependencies: Policy-maker buy-in; standardized evaluation protocols; safeguards against systemic bias and correlated errors in consensus.
- Education: Adaptive multi-expert tutoring and assessment generation
- Use case: Route subject-specific queries to the most capable tutor models; generate calibrated assessments using filtered synthetic data that targets student weaknesses.
- Tools/products/workflows: Learner model + router for expert selection; RL-tuned generator for differentiated question creation; teacher oversight and pedagogical alignment.
- Assumptions/dependencies: Reliable estimation of correctness without labels; safety and age-appropriate content constraints; human-in-the-loop validation.
- Healthcare (High-stakes deployments): Ensemble decision support with regulatory validation
- Use case: Clinically validated routing and aggregation for diagnostic support, coding, and triage—using multimodal signals and strict guardrails.
- Tools/products/workflows: Regulated audit pipelines; clinical trials for validation; multimodal consensus; domain-specific safety filters and escalation protocols.
- Assumptions/dependencies: Regulatory approval (e.g., FDA), HIPAA-compliant infrastructure, extensive validation on real patient data, strong monitoring and human oversight.
- Security and Red Teaming: Generator-driven adversarial prompt creation for robustness testing
- Use case: Use RGD to synthesize hard, differentiating prompts that expose model failure modes; improve routers and ensembles against adversarial attacks.
- Tools/products/workflows: Red-team generators tuned for variance and consensus gaps; failure-mode dashboards; countermeasure development.
- Assumptions/dependencies: Safe adversarial generation; careful control to avoid data leakage or model exploitation; ongoing maintenance.
- Edge/On-device Meta-Assistants: Local routing among small models for privacy-sensitive tasks
- Use case: Run CASCAL-like routing across lightweight models on-device (e.g., MCQ help, categorization) with privacy-preserving consensus.
- Tools/products/workflows: Efficient embeddings; compact model pools; local consensus voting; offline RGD profiling.
- Assumptions/dependencies: Device compute limits; memory footprint constraints; periodic synchronization for cluster updates; limited to discrete tasks.
Overall, CASCAL and RGD unlock practical label-free routing today for discrete tasks, and set the stage for rich, scalable ecosystem advances—semantic consensus for open-ended generation, multimodal routing, RL-optimized query generation, and regulated, audit-ready deployments in high-stakes domains.
Glossary
- Aggregator model: A component that combines outputs from selected models into a final decision. "where the chosen models may be used alone () or aggregated via ensemble methods such as majority voting or via a separate aggregator model."
- BigBench-Extra-Hard (BBEH): A challenging subset of BIG-bench focused on difficult tasks used for evaluation. "BigBench-Extra-Hard \citep[BBEH;] []{bbeh}"
- CASCAL: A query-only routing method that uses consensus and clustering to estimate model skills without labels. "We further propose CASCAL, a novel query-only router that estimates model correctness through consensus voting and identifies model-specific skill niches via hierarchical clustering."
- Consensus-based correctness estimation: Estimating correctness by weighting agreement among models rather than using ground-truth labels. "CASCAL is characterized by two core ideas: (1) Consensus-based correctness estimation: Given that majority vote is often a strong signal for correctness"
- Consensus score: A metric that sums the confidence-weighted agreement supporting a model’s answer for a query. "The consensus score for model on query is:"
- Consensus voting: An aggregation method that selects answers based on agreement across multiple models. "and aggregate responses via consensus voting."
- Descriptor model: An LLM used to generate concise natural-language summaries of tasks to guide data generation. "by prompting a descriptor model to summarize a given task using a small number of seed examples"
- Distribution sharpening: Filtering generated data to keep only highly informative, differentiating samples. "This raises the question of distribution sharpening: can we recover routing performance by filtering generated data to retain only high-quality queries?"
- Domain shift: A mismatch between the distributions of training and test data that can affect model performance. "Since we evaluate routing under domain shift, we use Smoothie-Train variant of the algorithm."
- Embedding space: The vector space in which text is represented for similarity and clustering. "clustering-based approaches that identify skills in the embedding space"
- Hierarchical clustering: A clustering method that builds a hierarchy of clusters to capture niche specializations. "we propose a hierarchical clustering approach that groups queries into skill clusters and identifies niche skills for each model"
- k-means: A clustering algorithm that partitions data into k groups based on distance to centroids. "clusters them via -means ()"
- Kendall's tau: A rank correlation coefficient measuring the agreement between two orderings. "using Kendall's correlation coefficient."
- Majority vote: Selecting the answer supported by the most models or samples. "Given that majority vote is often a strong signal for correctness"
- MedMCQA: A multiple-choice medical QA benchmark used to assess model reasoning in medicine. "MedMCQA \cite{medmcqa}"
- MMLU-Pro: A professional-level multi-task language understanding benchmark covering many subjects. "MMLU-Pro \cite{mmlupro}"
- Multi-Agent Debate (MAD): A framework where multiple LLMs argue over several rounds to reach a better consensus. "A prominent example is Multi-Agent Debate (MAD), where agents generate arguments over multiple rounds to arrive at a superior consensus-based solution"
- Query-answer router: A router trained using both inputs and labels to estimate model correctness and route accordingly. "We evaluate query-answer routers (using both queries and labels) and query-only routers across four diverse benchmarks and 12 models"
- Query-only router: A router trained without labels that relies on agreement or proxy metrics to route queries. "a novel query-only router"
- Routing with Generated Data (RGD): A setting where routers are trained on synthetic queries (and sometimes answers) produced from task descriptions by LLMs. "We introduce Routing with Generated Data (RGD), a challenging setting in which routers are trained exclusively on generated queries and answers produced from high-level task descriptions by generator LLMs."
- Self-consistency: A technique that leverages multiple samples or models to arrive at a consistent answer. "This metric can also be understood as a form of self-consistency across multiple models."
- Silver reference: A strong but non-gold standard label used as an approximate reference for evaluation. "against an answer obtained using Gemini-3-Flash as a ``silver'' reference."
- Skill centroid: The representative embedding center of a cluster that characterizes a niche capability. "to obtain skill centroids"
- Skill cluster: A group of queries representing a coherent niche or capability region for routing. "groups queries into skill clusters"
- Stratified split: A train/test division that preserves the distribution of categories (e.g., tasks) across splits. "stratified by tasks."
- SuperGPQA: A high-difficulty graduate-level QA benchmark assessing deep reasoning. "SuperGPQA \cite{supergpqa}"
- Variance-inducing questions: Queries designed to elicit performance differences among models for better differentiation. "filtering for variance-inducing questions with high consensus by stronger models produces more informative routing samples"
- Weak supervision: Learning from noisy or indirect signals instead of ground-truth labels. "a weak supervision-inspired approach"
Collections
Sign up for free to add this paper to one or more collections.