- The paper introduces a novel Lookahead routing framework that predicts latent response representations to improve query routing in large language model systems.
- It employs both sequence-level and token-level predictors, using a CLM and an MLM, to balance computational efficiency with contextual accuracy.
- Experiments reveal a 7.7% performance boost over state-of-the-art methods, proving its effectiveness in open-ended tasks and nuanced semantic modeling.
Lookahead Routing for LLMs
The paper introduces the Lookahead routing framework, designed to improve the routing of queries in LLM systems. The framework addresses limitations of existing query-only routing methods by predicting latent representations of potential model outputs.
Introduction
Traditional routing methods direct queries to the most appropriate model based solely on the query itself, treating the task as a classification problem. While this reduces computational overhead, it fails to consider the insights embedded in the responses each model might generate. The Lookahead framework proposes predicting these potential responses' latent representations, enabling more informed routing without running full inference.
Lookahead Framework
The Lookahead framework circumvents the impracticality of generating complete outputs by predicting the latent features of potential responses.
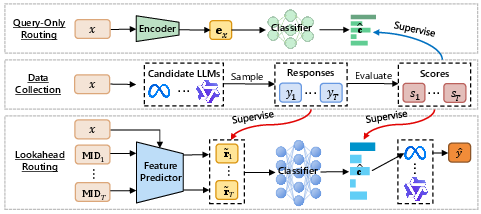
Figure 1: Overview of the Lookahead framework. Middle (Data Collection): For each input prompt x, responses y1:T are sampled from T candidate LLMs.
Response Modeling
The framework employs a response reconstruction objective, where a predictor estimates latent response representations. The predicted representations guide a classifier in estimating model selection scores:
Lresp=T1t=1∑TLrec(x,yt)
This approach enables the router to make contextually aware decisions.
Instantiations
Two variations of the Lookahead framework are implemented:
- Sequence-Level Predictor: Uses a causal LLM (CLM) to autoregressively generate potential responses.
- Token-Level Predictor: Utilizes a masked LLM (MLM) to predict masked responses, encapsulated within a shared semantic space for richer encoding.
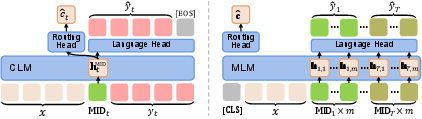
Figure 2: Architectures for response-aware routing in Lookahead. Left: Sequence-level modeling with a CLM. Right: Token-level modeling with an MLM.
Experiments
The Lookahead framework was evaluated across diverse benchmarks, demonstrating a 7.7% performance increase over state-of-the-art methods. It showed particular strength in open-ended tasks, highlighting its ability to capture nuanced semantic distinctions.
Ablation Studies
The efficacy of response modeling was confirmed through ablation studies, showing significant performance degradation when response modeling was removed. Additionally, the MLM variant's curriculum masking strategy was critical to maximizing model performance.
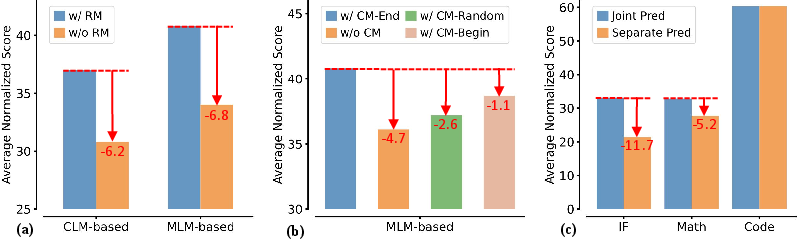
Figure 3: Results of ablation studies for the Lookahead framework. Performance drops when response modeling (RM) is removed.
Analysis
Further analysis indicated that response-aware representations captured richer semantic content than query-only features. Mutual information analysis demonstrated that Lookahead's response modeling encouraged learning latent spaces close to those derived from actual responses.
Conclusion
The Lookahead framework significantly enhances routing in multi-LLM systems by predicting latent response representations, balancing performance with computational efficiency. This advancement enables more precise model selection, particularly benefiting tasks where nuanced, contextual understanding is crucial. Future improvements could consider integrating cost trade-offs and alternative loss functions.