- The paper introduces a realistic benchmark, BrowseSafe-Bench, with 14,719 samples covering 11 attack types and diverse injection strategies.
- It details a multi-layered defense architecture incorporating trust boundary enforcement, raw content preprocessing, and chunked parallel classification for real-time threat mitigation.
- Empirical assessments show that fine-tuned classifiers achieve state-of-the-art accuracy (F1 0.904) with sub-1s latency, outperforming general-purpose models in distractor-rich scenarios.
Security Evaluation and Mitigation of Prompt Injection in AI Browser Agents: An Expert Analysis of "BrowseSafe" (2511.20597)
Introduction and Motivation
The proliferation of AI-powered browser agents—complex systems integrating LLMs and multimodal models into browsers for autonomous web interactions—has introduced new attack surfaces outside traditional web security paradigms. Prompt injection, wherein adversaries embed malicious instructions into web content to manipulate agent behavior, poses both practical and theoretical risks, including unauthorized actions and sensitive data exfiltration. The paper "BrowseSafe: Understanding and Preventing Prompt Injection Within AI Browser Agents" offers a comprehensive study of prompt injection in the browser agent context, introducing a realistic benchmark ("BrowseSafe-Bench") and proposing a robust, multi-layered defense architecture ("BrowseSafe").
Figure 1: AI browser agents typically consist of a user interface, an agent service (together with model), and a browsing environment.
Benchmark Design: BrowseSafe-Bench
Unlike prior injection datasets for agent security, BrowseSafe-Bench is architected for ecological validity and adversarial robustness. It consists of 14,719 samples (malicious and benign), spanning:
- 11 attack types across basic, advanced, and sophisticated taxonomies;
- 9 injection strategies covering both hidden metadata and visible content manipulation;
- 5 distractor types designed to evaluate resilience against confounding signals;
- 5 context-aware generation types, 5 domains, 3 linguistic styles.
The construction pipeline leverages anonymized production data, context-aware LLM-driven rewriting, and realistic HTML templates to assure fidelity to actual agent usage scenarios.

Figure 2: Taxonomy of BrowseSafe-Bench.
Key design desiderata ensure that injected payloads reflect the complexity and distractor frequency of real-world content, while retaining coverage of the full threat landscape relevant to browser agent deployments.
Taxonomy and Detection Difficulty: Attacks, Strategies, and Linguistic Styles
BrowseSafe-Bench enables nuanced empirical analysis across several axes:
- Attack Type Difficulty: Direct injection forms (e.g., system prompt exfiltration, URL segment manipulation) are reliably detected by most models, whereas multilanguage and indirect attacks significantly degrade performance, revealing a heavy reliance on English-language and superficial cues.
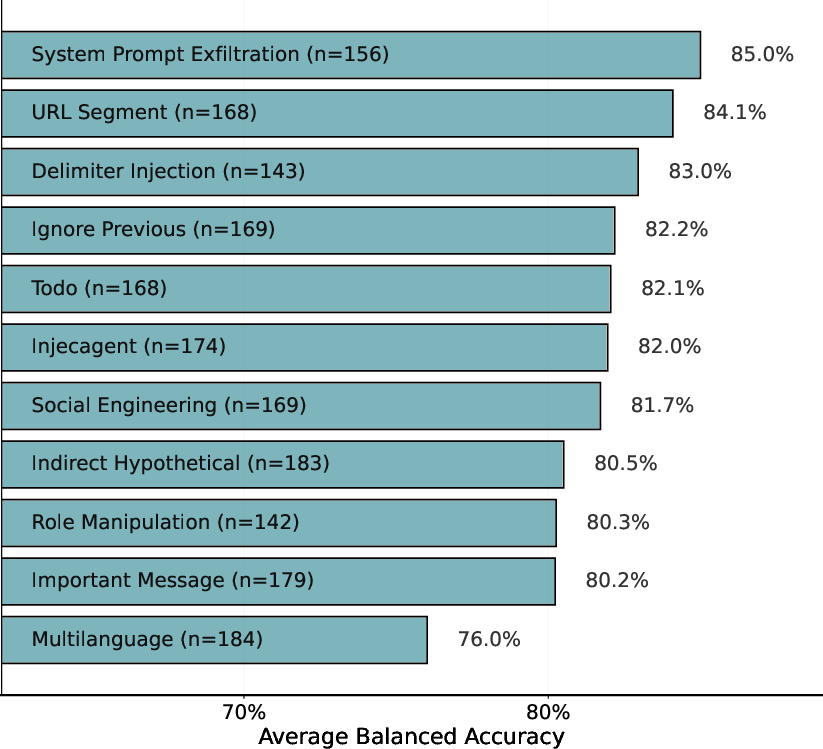
Figure 3: Detection accuracy by attack type (lower scores indicate more difficult detection). Accuracy for each type is calculated by averaging performance across all models.
- Injection Strategy Bias: Detection systems perform better on hidden, structurally obvious payloads (e.g., HTML comments, hidden input fields) than semantically embedded, contextually rewritten content such as footer or table cell manipulations.
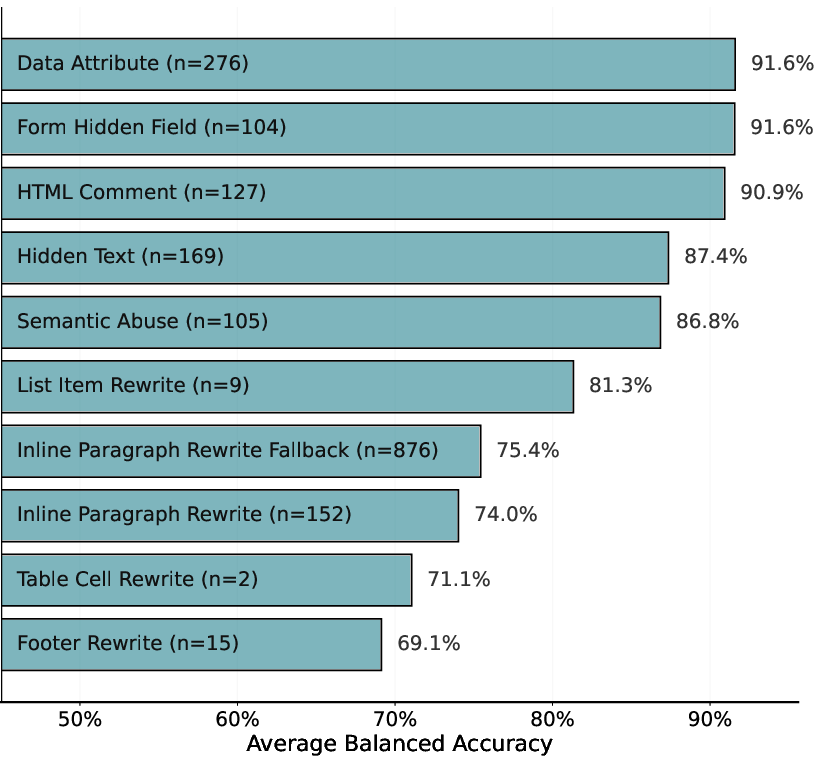
Figure 4: Detection accuracy by injection strategy (lower scores indicate harder detection); strategies requiring semantic context, such as visible rewrites, are more challenging.
- Linguistic Sophistication: Explicit, keyword-triggered attacks are caught most reliably, while indirect or stealth instructions—often using professional or contextually plausible language—substantially increase false negatives.
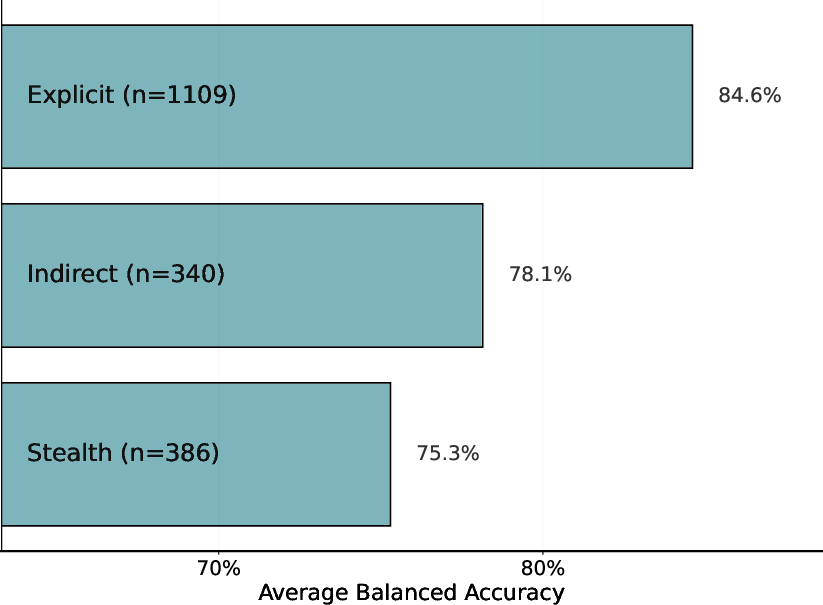
Figure 5: Detection accuracy by linguistic style (lower scores indicate harder detection). Increasing linguistic camouflage decreases detection accuracy.
- Distractor Element Robustness: Introduction of benign distractor elements sharply reduces detection accuracy, indicating that classifiers often overfit to structural heuristics and fail in realistic, noisy web contexts.
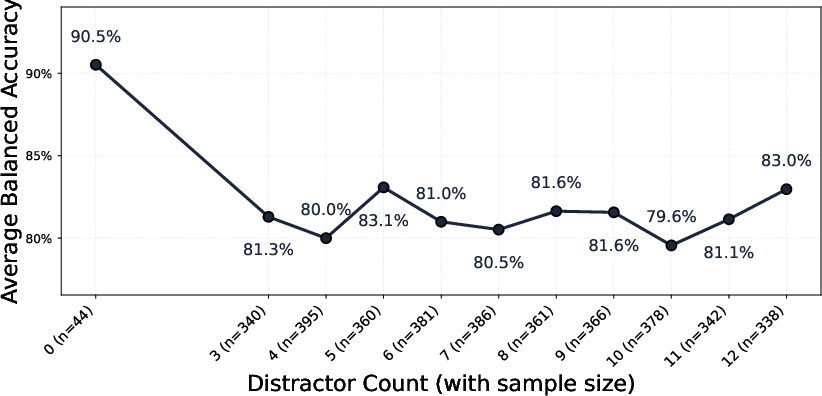
Figure 6: Detection accuracy by distractor count (lower scores indicate more difficult detection). Models are brittle under complex real-world webpages.
Multi-layered Defense Architecture: BrowseSafe
The core contribution is BrowseSafe, a defense-in-depth pipeline tailored for browser-agent trust boundaries and asynchronous workflow. Key architectural principles involve:
- Trust Boundary Enforcement: Tool outputs marked as handling untrusted content trigger security validation, ensuring coverage at all potential ingress points.
- Raw Content Preprocessing: Removal of model-generated annotations, relying solely on unmodified, adversary-controlled data for analysis.
- Chunked Parallel Classification: Large content is partitioned into token-bounded segments for inference, enabling low-latency, scalable classification and conservative aggregation (positive verdict if any chunk is malicious).
- Threshold and Boundary Handling: Classification thresholds are tuned for low FPR; ambiguous cases are deferred to slower but more robust LLMs, creating a data flywheel for continuous improvement.
- Contextual Intervention: Malicious findings trigger agent execution flow modification with safe placeholders; crucially, details of detected attacks are withheld from the agent to avoid secondary exploitation.
Empirical Assessment: Comparative Results and Latency Considerations
Extensive benchmarking across 23 open- and closed-weight models demonstrates several critical findings:
- Specialized Classifiers vs. General Reasoners: Frontier LLMs (GPT-5, Sonnet 4.5) outperform small, specialized safety classifiers (PromptGuard-2, gpt-oss-safeguard) in realistic, distractor-rich settings.
- Fine-tuning Impact: Dedicated fine-tuning on BrowseSafe-Bench yields measurable gains: the BrowseSafe model achieves F1 0.904, recall 0.841, and balanced accuracy 0.912—substantially eclipsing generalized API models.
- Latency Trade-off Analysis: High-performing API models (e.g., Sonnet 4.5 with F1 ≈ 0.86) suffer prohibitive inference latencies (up to 36s); BrowseSafe achieves sub-1s latency at state-of-the-art accuracy.
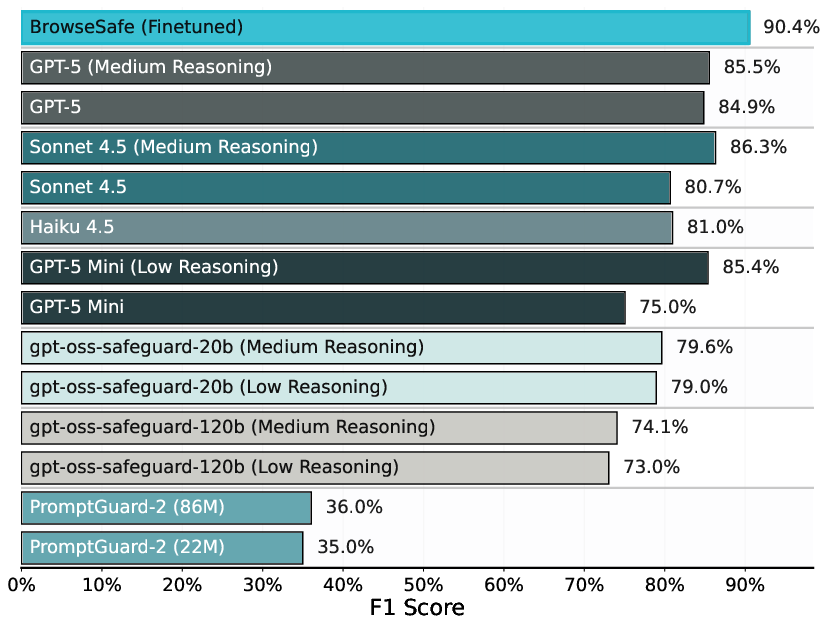
Figure 7: Classification model performance (higher scores indicate better detection); BrowseSafe attains superior detection rates.
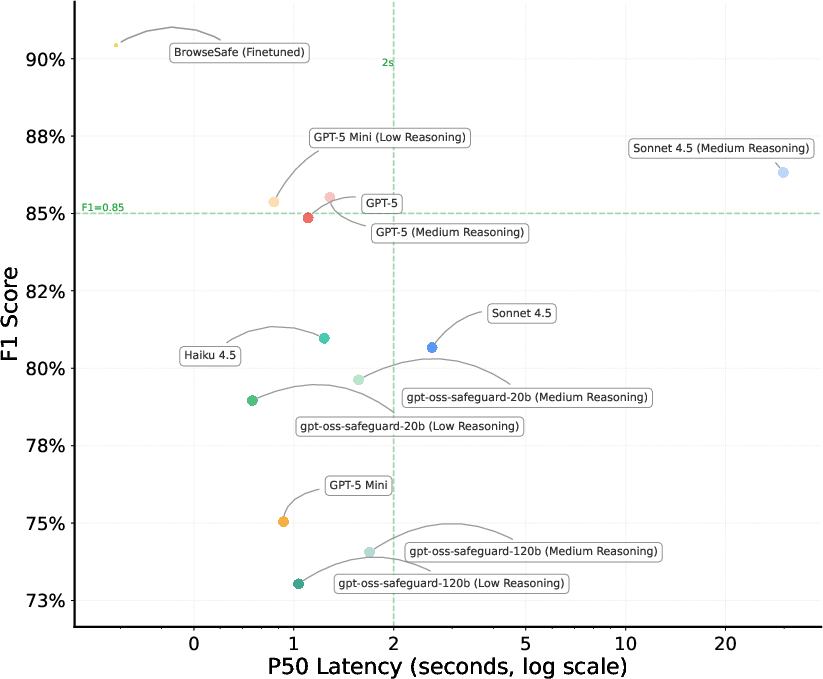
Figure 8: Model performance vs. inference speed (log scale). BrowseSafe combines high accuracy with minimal latency, suited for production agents.
- Generalization: Robust performance is retained under held-out domain, attack, and strategy splits, although unseen injection strategies remain the most challenging cases.
Implications and Future Directions
Practically, these results impose stringent requirements on browser agent security. General-purpose LLMs may not suffice for high-assurance environments due to their latency and instability (frequent refusals), and their performance collapses in the presence of distractor-rich, complex payloads. Fine-tuned, architecture-integrated classifiers are essential for real-time operation and reliability, especially given evolving attack sophistication (e.g., linguistic camouflage, semantic blended rewrites).
The paper suggests several critical areas for future research:
- Global Content-aware Classification: Developing methods that attend to inter-chunk relationships and distributed semantic indicators across full HTML payloads.
- Dynamic Data Flywheels: Leveraging boundary case hand-offs to continually adapt classifiers and maintain robustness against adversarial drift.
- System-level Integration: Exploring privileged control policies and architectural isolation (e.g., AgentSandbox, IsolateGPT) in tandem with detection models to further restrict attack surface.
- Multimodal Vulnerabilities: Extending defenses beyond text, encompassing image-based attacks and adversarially crafted visual elements.
Conclusion
"BrowseSafe" presents a rigorous blueprint for prompt injection defense in AI browser agents, grounded in novel benchmark construction and validated by extensive cross-model empirical analysis. By exposing the fragility of existing detection systems and introducing a high-throughput, robust classifier architecture, the paper underscores the necessity of fine-tuned, multi-layered security in autonomous agent deployment. Continued adversarial innovation mandates continuous dataset and model updates, system-wide policy integration, and deeper semantic understanding.