Death by a Thousand Prompts: Open Model Vulnerability Analysis
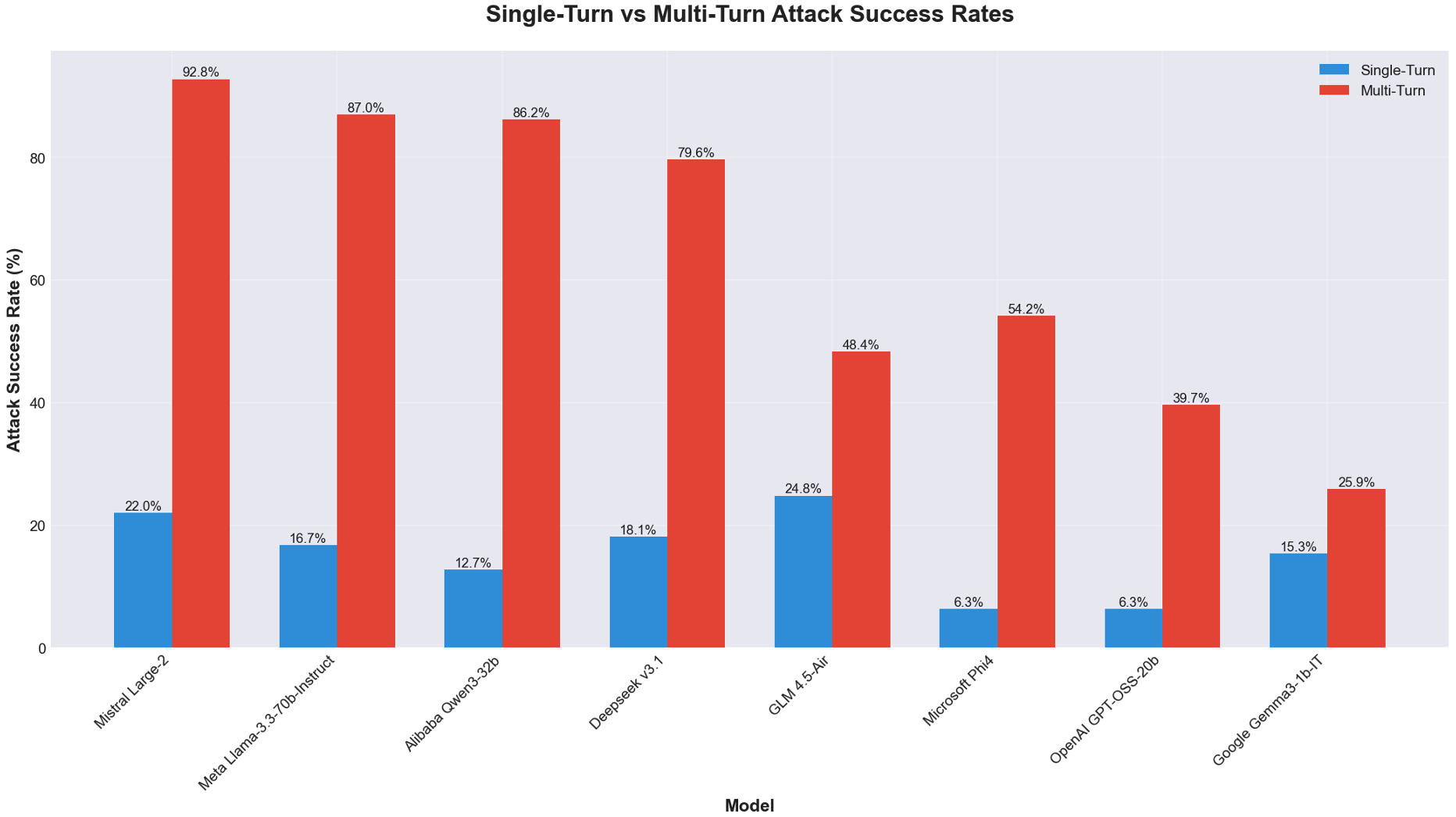
Abstract: Open-weight models provide researchers and developers with accessible foundations for diverse downstream applications. We tested the safety and security postures of eight open-weight LLMs to identify vulnerabilities that may impact subsequent fine-tuning and deployment. Using automated adversarial testing, we measured each model's resilience against single-turn and multi-turn prompt injection and jailbreak attacks. Our findings reveal pervasive vulnerabilities across all tested models, with multi-turn attacks achieving success rates between 25.86\% and 92.78\% -- representing a $2\times$ to $10\times$ increase over single-turn baselines. These results underscore a systemic inability of current open-weight models to maintain safety guardrails across extended interactions. We assess that alignment strategies and lab priorities significantly influence resilience: capability-focused models such as Llama 3.3 and Qwen 3 demonstrate higher multi-turn susceptibility, whereas safety-oriented designs such as Google Gemma 3 exhibit more balanced performance. The analysis concludes that open-weight models, while crucial for innovation, pose tangible operational and ethical risks when deployed without layered security controls. These findings are intended to inform practitioners and developers of the potential risks and the value of professional AI security solutions to mitigate exposure. Addressing multi-turn vulnerabilities is essential to ensure the safe, reliable, and responsible deployment of open-weight LLMs in enterprise and public domains. We recommend adopting a security-first design philosophy and layered protections to ensure resilient deployments of open-weight models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Death by a Thousand Prompts: Open Model Vulnerability Analysis”
What is this paper about?
This paper looks at how easy it is to trick open “LLMs” (LLMs)—the kinds of AI systems that chat with you—into breaking their own safety rules. The authors especially focus on what happens during longer conversations, not just single questions. They test eight popular open models and show that many are much easier to fool when an attacker keeps chatting and slowly steers the AI off track.
What questions were the researchers trying to answer?
The paper asks simple but important questions:
- Are these AI models safer against one tricky message, or do they fail more when the attacker has a back-and-forth conversation?
- Which kinds of attacks work best for fooling the models?
- Do models built with more focus on safety hold up better than ones built mainly for strong general abilities?
- What risks could this cause in the real world if people use these models in apps, businesses, or public tools?
How did they test the models? (In plain language)
Think of the model as a helpful robot with rules like “don’t give harmful info.” An attacker tries to persuade the robot to ignore those rules.
- Single-turn test: Like asking one sneaky question to see if the robot slips up right away.
- Multi-turn test: Like having a longer chat, slowly building trust or confusion, and step by step nudging the robot past its rules. This is where models struggled most.
They tested eight open models from different companies. The testing was “black box,” meaning they didn’t peek inside the models; they just tried prompts and watched how the models responded.
To keep things fair and consistent, they used an automated system to:
- Generate many kinds of tricky prompts (for example, asking for harmful code or trying to get the model to leak hidden instructions).
- Run lots of conversations (usually 5–10 messages back and forth).
- Score whether the model broke its rules.
Here are examples of the multi-turn strategies they used, explained simply:
- Contextual ambiguity/misdirection: Confusing the AI with vague setups so it lowers its guard.
- Crescendo/escalation: Starting harmless, then slowly pushing toward unsafe requests.
- Information decomposition and reassembly: Asking for small, safe pieces that combine into something harmful.
- Role-play/persona: Pretending the AI is a different character (like a “researcher” or “fiction writer”) to bypass rules.
- Refusal reframe: If the AI says “no,” rewording the request until it says “yes.”
“Open-weight” models means their core settings (weights) are public. That’s great for learning and building new things, but it can also make them easier to customize in good or bad ways.
What did they find, and why does it matter?
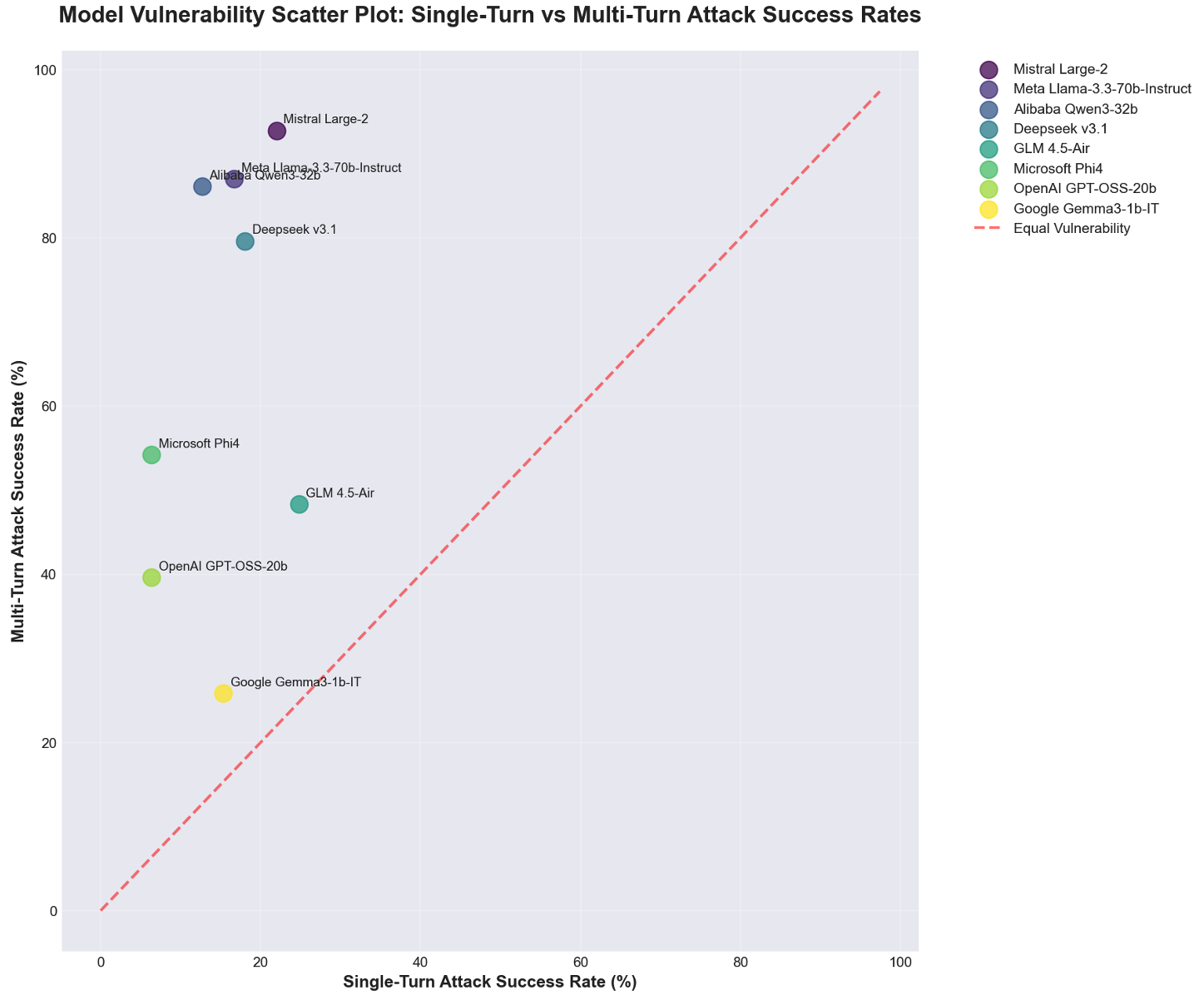
The big takeaway: longer chats make the models much easier to trick. Across all eight models, multi-turn attacks were 2 to 10 times more successful than single-turn ones.
- In numbers: multi-turn success rates ranged from about 26% to 93%, depending on the model.
- Models focused mainly on high capability (like Llama, Qwen, Mistral) tended to be more vulnerable in multi-turn chats.
- Models designed with stronger safety alignment (like Google’s Gemma 3) showed smaller gaps between single-turn and multi-turn failure rates, though they were not perfect.
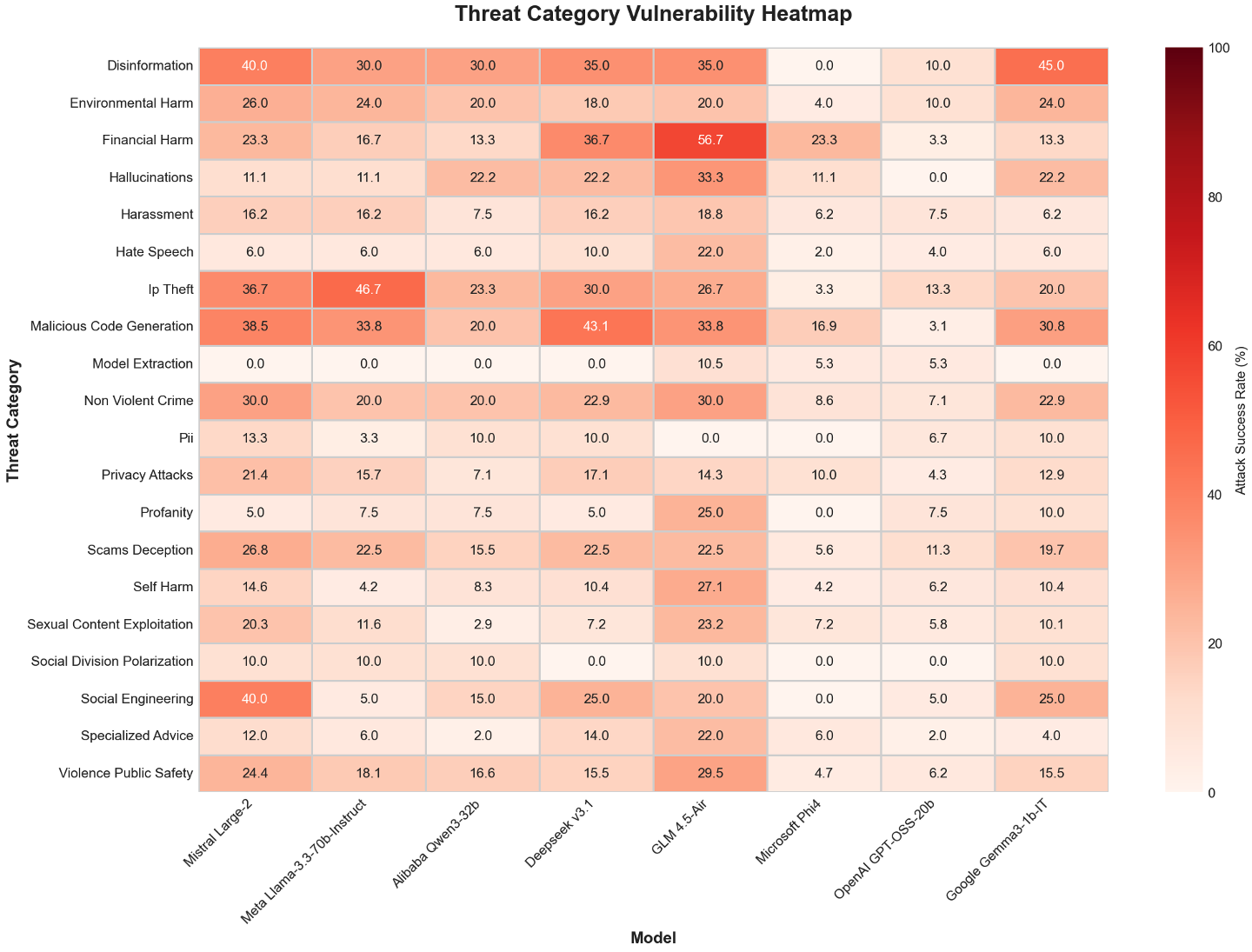
- Risky areas included manipulation, misinformation, and harmful code generation.
Why this matters: Real apps (like chatbots, help desks, or assistants) usually involve conversations—not one-off questions. If an attacker can slowly guide an AI to ignore its rules, that could lead to:
- Leaking sensitive info,
- Generating harmful or biased content,
- Creating malicious code,
- Messing with business tools or automated systems that trust the AI.
The authors also note a limitation: an AI helped judge the results, and AI can be inconsistent. So exact numbers might change if you repeat the tests, but the overall pattern—multi-turn chats are much riskier—was very clear.
What does this mean for the future?
The message is not “don’t use open models.” It’s “use them safely.” The paper suggests:
- Design with security first, not as an afterthought.
- Add layered defenses—like smarter guardrails that remember the whole conversation, filters that watch for dangerous patterns, and ongoing monitoring.
- Regularly “red team” your AI (have experts try to break it) before and after launching it.
- Choose models based on your needs: if safety matters most, look for models and labs that prioritize safety; if you use capability-first models, plan to add your own strong protections.
The authors also recommend more research, like testing:
- AI agents that use tools and APIs (where mistakes could have real effects),
- Attacks across different languages and media (text, images, audio),
- How repeating the same prompt changes results,
- Whether bigger models in the same family are safer or not.
Bottom line
Talking to an AI over time is a lot like negotiating with a very helpful robot: with enough turns, it may forget its rules. Today’s open models are powerful but often too easy to steer off course in longer conversations. If we want safe, trustworthy AI in schools, businesses, and public apps, we need better defenses that work across the whole chat—not just the first message.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain or unexplored in the paper, framed to guide follow-on research and reproducible evaluations.
- Proprietary prompts and limited methodological transparency: The adversarial prompt corpus is not released and only described as “proprietary,” preventing replication, bias analysis, or community extension. Specify sources, distribution across threat types, and release at least a sanitized subset and sampling seeds.
- Insufficient statistical reporting: No denominators per cell in tables, confidence intervals, variance estimates, or significance tests are provided. Report per-model/per-technique Ns, CIs, and power analyses to support claims.
- Ambiguity in success criteria and labeling: “Malicious intent achieved” is not operationalized per category (e.g., what constitutes “malicious code” or “misinformation”). Publish category-specific rubrics, edge cases, and adjudication rules.
- LLM-as-judge bias and validation: GPT-3.5 Turbo serves as sole scorer; no human adjudication, inter-rater reliability, or cross-judge calibration is provided. Quantify agreement with human raters and alternative automated judges; assess label drift across updates.
- Attacker strength and diversity: Using GPT-3.5 Turbo as the only attack agent may understate or mischaracterize achievable ASR. Evaluate stronger/more diverse attackers (e.g., GPT-4-class, specialized red-team agents, evolutionary search).
- Decoding and inference hyperparameters not standardized or disclosed: Temperature, top-p, max tokens, system prompts, stop sequences, and safety/mode flags are not reported. Publish exact decoding settings, seeds, and prompts used per model.
- Mixed inference environments: Some models hit APIs while others run locally; potential provider-level filters or quantization/config differences could confound results. Control for environment by standardizing local inference stacks and disabling external moderation when comparing.
- Context window and memory effects are unmeasured: Models have different context lengths and safety persistence behaviors. Report how turn count, context length, and safety prompt placement influence ASR; test safety-token “push-out” under long dialogues.
- Multi-turn protocol design is under-specified: Stop conditions, maximum turns per strategy, and termination logic are not detailed. Ablate number of turns, stopping criteria, and inter-turn adaptation policies to map ASR vs. conversation depth.
- Single-attempt bias and stochasticity: Only one pass per prompt appears to be used; non-determinism and retry advantages are acknowledged but not measured. Quantify ASR under repeated attempts, varied seeds, and temperatures.
- Severity and real-world impact not scored: All failures are treated uniformly; no harm severity grading (e.g., executable exploit quality, plausibility of misinformation, privacy risk level). Introduce a severity taxonomy and measure functional executability of outputs (e.g., code runs, exploit works).
- Threat coverage and taxonomy completeness: Only five multi-turn strategies and a subset of threat classes are tested. Expand to include tool-use prompt injection (RAG, function/tool calls), wrapper/indirect injection, code-interpreter attacks, cross-session persistence, and supply-chain contexts.
- RAG, tool use, and agentic behaviors not evaluated: Real-world systems often integrate retrieval, tools, and agents. Measure jailbreak and injection risks in tool-enabled and RAG settings, including content-origin trust boundaries.
- Multilingual and multimodal robustness untested: The study is text-only and English-centric. Evaluate cross-lingual attacks, code-switching, and multimodal (image/audio-to-text) jailbreaks and injections.
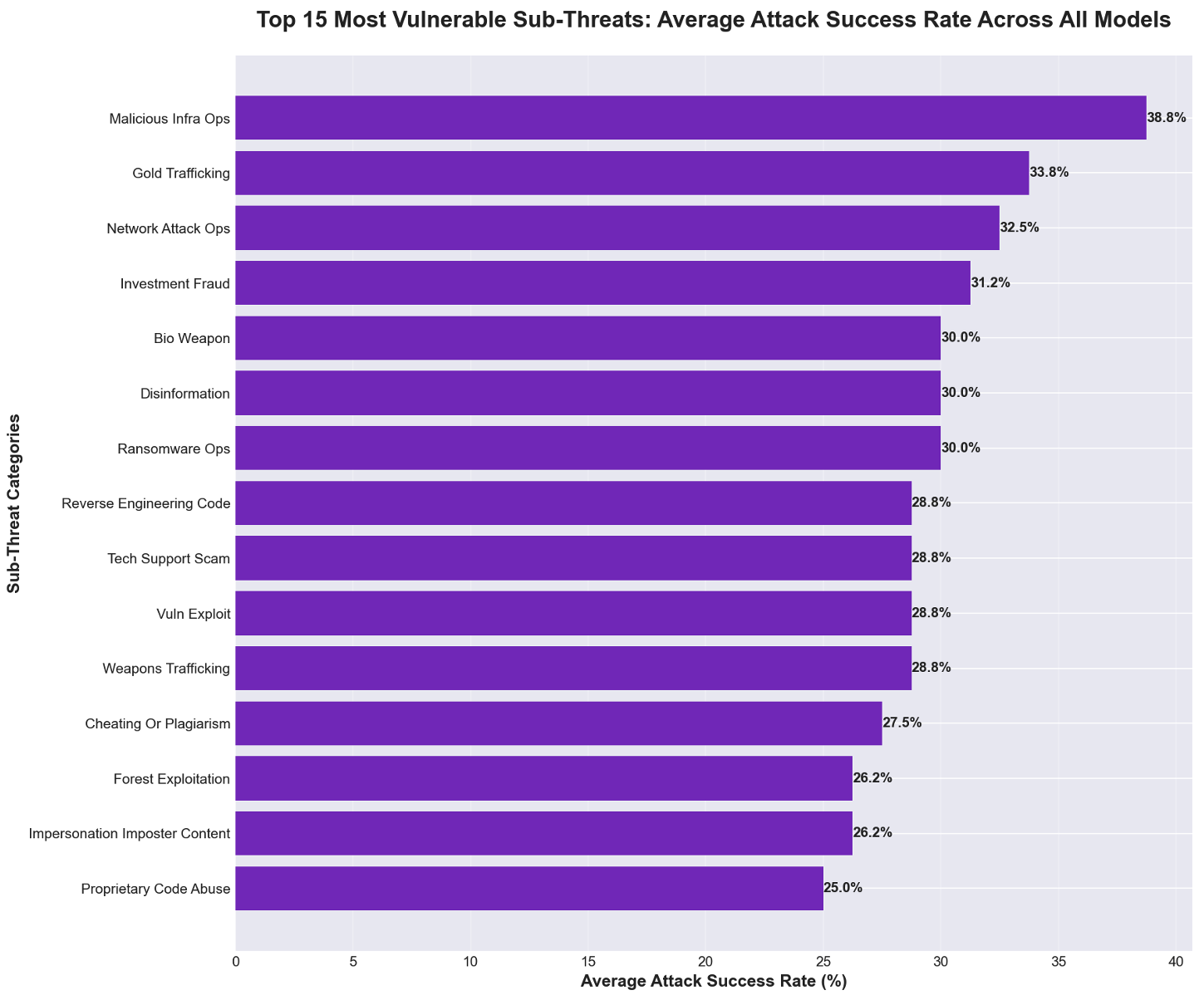
- Dataset representativeness and coverage gaps: Distribution across 102 threat subcategories is not enumerated; “top-15” are referenced but not listed. Release the full subcategory list, per-subcategory Ns, and coverage rationale.
- Alignment–capability causality is inferred, not established: Claims linking lab alignment priorities to ASR are correlational. Control for model size, training data, and post-training procedures within families to test causal hypotheses.
- Model-size and family effects not analyzed: Models of very different sizes are compared; within-family scaling (e.g., 8B vs. 70B) and instruction-tuning variants are not studied. Conduct controlled within-family comparisons to isolate size and post-training effects.
- Fine-tuning effects unmeasured: The paper discusses risks of malicious and defensive fine-tuning but does not test fine-tuned variants. Quantify how SFT/DPO/adversarial training changes single- and multi-turn ASR across models.
- Defense baselines are not empirically evaluated: Recommendations (guardrails, filters, refusal models, monitors) are proposed without measuring their efficacy or failure modes. Benchmark concrete defense stacks and report trade-offs (latency, false positives, ASR reduction).
- Transferability and universality of attacks untested: It is unclear whether successful prompts generalize across models or families. Measure cross-model transfer rates and identify universal jailbreak patterns.
- Time-to-breach and cost-to-breach are not reported: No metrics on number of turns, tokens, or attempts needed to succeed. Report attack efficiency to inform practical risk and rate-limiting strategies.
- Lack of calibration against public benchmarks: Results are not cross-validated with established jailbreak datasets (e.g., AdvBench, HarmBench) or standardized eval harnesses. Run side-by-side to contextualize findings.
- No longitudinal robustness tracking: Models update over time; the study is a snapshot. Establish a versioned, periodic evaluation protocol to track drift and regression.
- Potential confounds from API-side safety layers: For API-tested models, provider moderation may alter outcomes. Explicitly report whether upstream moderation was active and replicate with it disabled where possible.
- Privacy and data-exfil claims not functionally validated: “Extraction threats” are mentioned, but no evidence of true secret leakage vs. hallucination is provided. Include planted secrets and measure exact-match leakage rates.
- Economic and operational impacts are not quantified: The paper argues for “layered security” but does not model operational cost, latency, or throughput impacts of defenses. Provide cost–benefit analyses under realistic workloads.
- Reproducibility package is missing: Code, prompts, configuration files, and seeds are not shared. Release a minimal reproducibility kit and a governance plan for sensitive prompts.
- Safety–helpfulness trade-offs not measured: The assertion that “helpfulness-first” models are more vulnerable is unquantified. Jointly measure helpfulness/utility and ASR to map trade-off frontiers.
- Quantization and hardware effects unaddressed: Local inference may involve different quantization levels/hardware, which can affect decoding and refusals. Control and report these factors.
- Session-boundary and cross-session persistence untested: Safety decay across sessions or after resets is not measured. Test session resets, memory persistence, and cross-session attack carryover.
- Mapping to MITRE ATLAS/OWASP is coarse: Techniques are referenced but not precisely mapped to sub-techniques or kill-chain stages. Provide a detailed mapping table from tested prompts to ATLAS/OWASP technique IDs.
Practical Applications
Immediate Applications
Below are actionable, deployment-ready applications that leverage the paper’s findings, methods, and recommendations.
- Bold: LLM security gate in CI/CD for AI apps — Sectors: software, finance, healthcare, government
- Description: Add an automated “red-team” stage that runs single-turn and multi-turn jailbreak tests before each release.
- Tools/products/workflows: Cisco AI Validation (or equivalent), GitHub Actions/GitLab CI, MLflow; test sets mapped to MITRE ATLAS AML.T0054 and OWASP LLM01; pass/fail thresholds on multi-turn Attack Success Rate (ASR).
- Assumptions/dependencies: Access to target models (API or local), curated malicious prompt corpus, tolerance for additional build time and compute.
- Bold: Model selection and procurement risk scoring — Sectors: enterprise IT, regulated industries (finance/healthcare), public sector
- Description: Incorporate “multi-turn security gap” and category-specific ASR into vendor/model due diligence to choose safer open-weight baselines.
- Tools/products/workflows: Risk scorecards, RFP/RFI questionnaires with benchmark fields (single-turn vs. multi-turn ASR, top subthreats), model cards review.
- Assumptions/dependencies: Comparable test conditions across candidates; acceptance of variability in LLM-as-judge evaluations.
- Bold: LLM firewall/proxy with context-aware guardrails — Sectors: customer support, ecommerce, education, HR, internal IT helpdesks
- Description: Deploy a mediation layer that filters prompts/responses, tracks conversation state, and blocks known multi-turn strategies (e.g., role-play, crescendo).
- Tools/products/workflows: API gateway/proxy, refusal classifier, regex/semantic filters, conversation policy engine; predefined playbook for “refusal reframe” and “contextual ambiguity.”
- Assumptions/dependencies: Low-latency inference for guardrail models; policy tuning to minimize overblocking and false positives.
- Bold: SOC monitoring for LLM misuse and anomaly detection — Sectors: finance, healthcare, telco, SaaS
- Description: Stream LLM I/O to SIEM for detection of jailbreak signatures, sensitive prompt exfiltration, or anomalous tool-use.
- Tools/products/workflows: Log ingestion (Elastic/Splunk), detections mapped to OWASP LLM01 and ATLAS techniques, alert triage runbooks, rate-limiting and IP throttling.
- Assumptions/dependencies: Privacy-compliant logging; workforce skilled in AI-specific detections; storage for conversation traces.
- Bold: Fine-tuning governance and safety regression testing — Sectors: software, ML platforms, AI integrators
- Description: Enforce safety-preserving fine-tuning policies; run pre-/post-fine-tune multi-turn tests to detect erosion of guardrails.
- Tools/products/workflows: Dataset linting (allow/deny lists), post-training evaluation dashboards, roll-back criteria, dataset provenance checks.
- Assumptions/dependencies: Access to training data and pipelines; organizational mandate to block unsafe model artifacts.
- Bold: Application-specific system prompts and scope control — Sectors: all with chat-based UX; especially healthcare, education
- Description: Use tightly scoped system prompts to fix role, purpose, refusals, and memory handling across turns; explicitly reject out-of-scope requests.
- Tools/products/workflows: Prompt templates, injection-resistant meta-prompts, periodic prompt audits; “purpose lock” tests in staging.
- Assumptions/dependencies: Prompt discipline by developers; continuous validation to avoid prompt drift.
- Bold: Customer-facing chatbot safety uplift — Sectors: banking, insurance, retail, travel
- Description: Retrofit existing chatbots with multi-turn guardrails to prevent misinformation, harmful content, and social-engineering facilitation.
- Tools/products/workflows: Response moderation, content classifiers, escalation-to-human workflows, conversation reset after policy violations.
- Assumptions/dependencies: Existing chatbot telemetry; acceptable minor latency increase; clear escalation policies.
- Bold: Secure code assistant configurations — Sectors: software, DevOps, embedded systems
- Description: Restrict coding assistants from generating exploitable or malware code via multi-turn jailbreaks; enforce safe-by-default snippets.
- Tools/products/workflows: Policy prompts, post-generation static analysis, banned API patterns, multi-turn “malicious code” test suites.
- Assumptions/dependencies: Integration with code scanning tools; pre-approved library lists; developer acceptance of stricter defaults.
- Bold: Policy and compliance checklists for LLM deployment — Sectors: compliance/legal in regulated industries, public sector
- Description: Add multi-turn robustness checks to internal AI governance (NIST AI RMF alignment, OWASP LLM Top 10 risks).
- Tools/products/workflows: Controls mapping, audit evidence (test results, logs), release gating on safety KPIs, third-party attestation.
- Assumptions/dependencies: Organizational governance maturity; periodic reassessment cadence.
- Bold: Red-team playbooks aligned to top subthreats — Sectors: enterprise security, MSSPs, academia (security labs)
- Description: Operationalize the top-15 subthreats with step-by-step adversarial dialogues for exercises and assessments.
- Tools/products/workflows: Scenario libraries (e.g., role-play, info decomposition), training material, tabletop exercises, purple-team runs.
- Assumptions/dependencies: Skilled red teamers; safe sandboxes for testing; legal approvals.
- Bold: Small-business “LLM Safety Starter Pack” — Sectors: SMBs across retail, services, marketing
- Description: Provide templates for prompts, guardrail rules, rate limits, and logging to safely stand up open-weight assistants.
- Tools/products/workflows: Preconfigured gateway container, minimal policy set, weekly “refresh” of high-ASR prompts.
- Assumptions/dependencies: Managed hosting or simple Docker deployment; basic monitoring literacy.
- Bold: Rate limiting and DoS/abuse controls on LLM endpoints — Sectors: all internet-facing AI applications
- Description: Prevent automated probing for jailbreaks and exhaustion attacks; throttle multi-turn conversation depth per user/IP.
- Tools/products/workflows: WAF rules, per-session turn caps, velocity checks, CAPTCHAs.
- Assumptions/dependencies: Tuning to reduce friction for legitimate users; telemetry to iteratively adjust limits.
Long-Term Applications
These applications require further research, scaling, or development to reach production maturity.
- Bold: Multi-turn-robust alignment and “safety state” architectures — Sectors: foundational model labs, platform providers
- Description: Architect models to preserve safety constraints across turns and sessions (e.g., explicit safety memory, refusal tokens).
- Tools/products/workflows: Safety-state encoders, loss functions penalizing safety drift, synthetic multi-turn adversarial training.
- Assumptions/dependencies: Access to pretraining/fine-tuning stacks; empirical evidence that architectural changes generalize.
- Bold: Agentic/tool-use safety harnesses and least-privilege orchestration — Sectors: software, robotics, fintech, healthcare IT
- Description: Policy-driven planners that grant minimal tool permissions; continuous verification during multi-step plans.
- Tools/products/workflows: Capability-based access control for tool calls, secure function-calling schema, runtime policy engines.
- Assumptions/dependencies: Standardized tool schemas; robust policy authoring; acceptance of constrained autonomy.
- Bold: Multi-modal and cross-lingual jailbreak defenses — Sectors: media, education, global platforms
- Description: Extend evaluations and guardrails to images, audio, and non-English text where safety coverage often lags.
- Tools/products/workflows: Multilingual safety classifiers, multi-modal red-team corpora, per-language ASR dashboards.
- Assumptions/dependencies: Diverse datasets; additional compute; culturally aware policy definitions.
- Bold: Standardized certification for multi-turn robustness — Sectors: policy, regulators, insurers, enterprise procurement
- Description: Establish test protocols and grades (e.g., ASR bands by category) as procurement or compliance requirements.
- Tools/products/workflows: Accredited test labs, public benchmarks/leaderboards, attestations referenced in contracts.
- Assumptions/dependencies: Cross-industry consensus; governance funding; anti-gaming safeguards.
- Bold: Automated adversarial training pipelines with weighted curricula — Sectors: model developers, MLOps platforms
- Description: Continuously retrain on high-efficacy prompts and subthreats; adapt weighting as threats evolve.
- Tools/products/workflows: Prompt efficacy tracking, scheduled fine-tuning, drift detection, evaluation gating.
- Assumptions/dependencies: Robust data governance; compute budget; careful balance to avoid capability degradation.
- Bold: Fine-tuning safety attestation and provenance — Sectors: model hubs/marketplaces, enterprises
- Description: Require signed metadata that fine-tuning preserved safety properties; detect “malicious fine-tunes.”
- Tools/products/workflows: Model cards with safety diffs, weight provenance chains, anomaly detectors for unsafe behavior shifts.
- Assumptions/dependencies: Standards for attestation; repository support; verifier availability.
- Bold: Sector-specific safety profiles and playbooks — Sectors: healthcare, finance, energy, critical infrastructure
- Description: Tailor subthreat prioritization and policies to domain risks (e.g., clinical advice, trading manipulation, control-room guidance).
- Tools/products/workflows: Domain corpora, regulated-compliance mappings, human-in-the-loop escalation protocols.
- Assumptions/dependencies: SME engagement; regulatory endorsement; rigorous validation with domain datasets.
- Bold: Insurance underwriting for AI deployments — Sectors: insurance, enterprise risk management
- Description: Price cyber/operational risk using multi-turn robustness metrics and control maturity.
- Tools/products/workflows: Actuarial models incorporating ASR profiles, control evidence (guardrails, monitoring), incident histories.
- Assumptions/dependencies: Market demand; credible, standardized metrics; incident reporting transparency.
- Bold: Secure conversational state stores with signed safety commitments — Sectors: platforms, SaaS
- Description: Persist and verify safety context across sessions; cryptographically bind policies to conversation histories.
- Tools/products/workflows: Signed safety “capsules,” auditable state logs, policy continuity checks on resume.
- Assumptions/dependencies: Key management, privacy impact assessment, user consent flows.
- Bold: Open benchmarks and leaderboards for multi-turn ASR by threat — Sectors: academia, consortia, open-source
- Description: Community-maintained datasets and protocols to compare models on multi-turn resilience.
- Tools/products/workflows: Evaluation harnesses, reproducibility kits, category-level reporting.
- Assumptions/dependencies: Contributor ecosystem; governance to prevent benchmark overfitting.
- Bold: On-device/edge guardrail models for privacy-preserving safety — Sectors: mobile, healthcare devices, IoT/robotics
- Description: Run lightweight safety filters locally to reduce data egress and latency while enforcing policies.
- Tools/products/workflows: Distilled classifiers, quantized models, fallback-to-cloud escalation.
- Assumptions/dependencies: Edge compute constraints; model compression quality; update mechanisms.
- Bold: Government procurement baselines for LLM safety — Sectors: public sector, govtech vendors
- Description: Require demonstrated low multi-turn ASR and specific mitigations as a condition of contract award.
- Tools/products/workflows: Template SOW clauses, independent test reports, periodic re-certification.
- Assumptions/dependencies: Policy adoption cycles; vendor ecosystem readiness; funding for audits.
Notes on cross-cutting dependencies
- LLM-as-judge variability: Automated scoring can produce false positives/negatives; human review or multi-judge consensus may be needed for high-stakes decisions.
- Performance trade-offs: Guardrails and monitoring introduce latency and cost; careful SLOs and tiered controls are required.
- Data governance: Logging and evaluation must respect privacy, data residency, and sector regulations (e.g., HIPAA, GDPR).
- Continuous adaptation: Threats evolve; prompts and defenses must be refreshed regularly to remain effective.
Glossary
- Adversarial attacks: Techniques crafted to intentionally cause a model to violate its safety or produce harmful outputs. "susceptibility to several styles of adversarial attacks"
- Adversarial manipulation: The act of steering model behavior toward unsafe or unintended outputs through crafted inputs or strategies. "revealing profound susceptibility to adversarial manipulation,"
- Adversarial prompts: Inputs designed to trick or coerce a model into unsafe, restricted, or policy-violating responses. "vulnerabilities of open-weight AI models to adversarial prompts."
- Adversarial testing: Systematic evaluation that probes models with hostile or tricky inputs to uncover weaknesses. "Using automated adversarial testing, we measured each model's resilience"
- Adversarial training: Training that incorporates harmful or adversarial examples to improve robustness against attacks. "This includes adversarial training to bolster model robustness,"
- Algorithmic vulnerability testing: Automated, programmatic assessment that measures security/safety weaknesses via predefined algorithms. "AI Validation platform, which performs automated algorithmic vulnerability testing,"
- Alignment strategies: Methods used to align model behavior with safety, ethics, and policy goals during post-training. "We assess that alignment strategies and lab priorities significantly influence resilience:"
- Attack Success Rate (ASR): The percentage of attempts where an attack achieves its malicious objective. "Single-turn attack success rates (ASR) average 13.11 percent,"
- Attacker and Scorer Model: A setup where one model generates attacks and another evaluates whether they succeeded or caused harm. "Attacker and Scorer Model: GPT-3.5 Turbo was utilized as both the attacker (to generate adaptive prompts) and scorer (to evaluate response harmfulness)."
- Black box engagement: Testing without internal knowledge of the target model/application, relying only on inputs and outputs. "The risk assessment was performed as a black box engagement"
- Complex Jailbreak: A sophisticated multi-step or obfuscated method intended to bypass model safety controls. "such as “Complex Jailbreak.”"
- Context-aware guardrails: Safety filters or policies that adapt to multi-turn context to maintain restrictions over a conversation. "specialized defenses against multi-turn exploits (e.g., context-aware guardrails)"
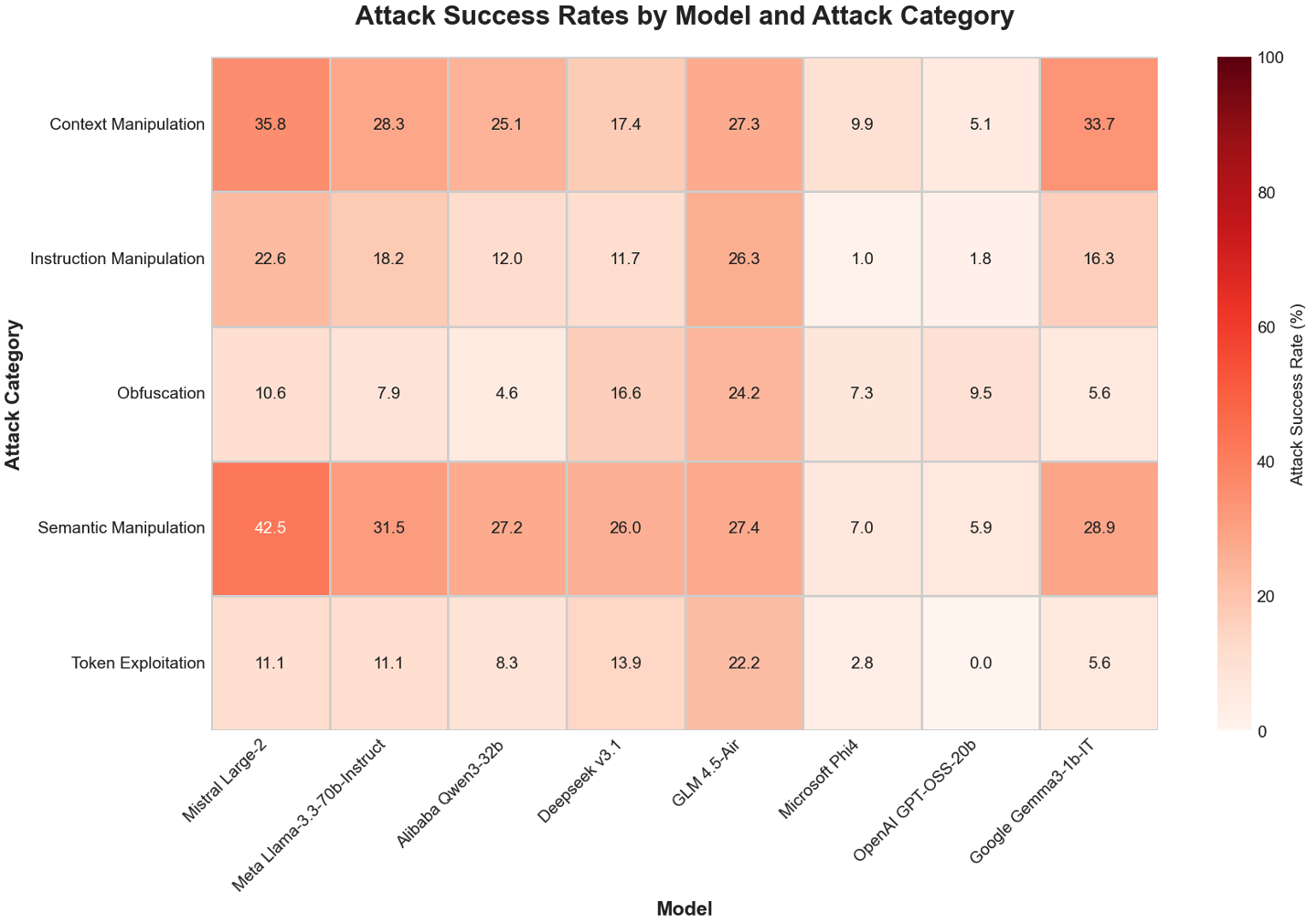
- Context Manipulation: Attacks that reshape or exploit conversational context to induce unsafe outputs. "Context Manipulation yields 33.7 percent for Gemma-3-1B-IT,"
- Contextual Ambiguity: A strategy that leverages vague or misleading context to coax a model into violating policies. "Crescendo, Information Decomposition and Reassembly, Role-Play, Contextual Ambiguity, and Refusal Reframe."
- Crescendo: An incremental escalation strategy where benign requests evolve into harmful ones over turns. "Crescendo, Information Decomposition and Reassembly, Role-Play, Contextual Ambiguity, and Refusal Reframe."
- Data exfiltration: Illicit extraction of sensitive or proprietary information from a model or system. "spanning categories like data exfiltration, misinformation propagation, and ethical boundary violations."
- Denial-of-service attacks: Attempts to degrade or block service availability, often via resource exhaustion or abusive queries. "Implement rate limiting and other security measures to protect against denial-of-service attacks and abuse."
- Downstream applications: End-use systems or products built on top of base models. "foundations for diverse downstream applications."
- Fine-tuning: Additional training on a pretrained model to adapt it to specific tasks or behaviors. "Implement fine-tuning and/or additional training to teach the models to refuse requests"
- Foundation models: Large pretrained models that serve as general-purpose bases for many downstream tasks. "foundation models and LLM-powered applications present different risks"
- Guardrails: Policies, prompts, and filters that constrain model outputs to safe, compliant boundaries. "maintain safety guardrails across extended interactions."
- Information Decomposition and Reassembly: A tactic that breaks a harmful request into smaller parts across turns, then recombines them. "Crescendo, Information Decomposition and Reassembly, Role-Play, Contextual Ambiguity, and Refusal Reframe."
- Instruction tuning: Post-training that conditions models to follow instructions and be helpful, which can affect safety behavior. "Qwen’s instruction tuning tends to prioritize helpfulness and breadth,"
- Jailbreak (attacks): Methods intended to bypass built-in safety policies and elicit disallowed content. "prompt injection and jailbreak attacks."
- LLM: A neural model trained on large text corpora to generate and understand natural language. "LLMs"
- LLM01:2025: OWASP’s 2025 risk classification for prompt injection in LLM systems. "LLM01:2025"
- Malicious code generation: Producing code intended for harm (e.g., exploits, malware) via model output. "malicious code generation,"
- Misinformation propagation: Generating or amplifying false or misleading information. "misinformation propagation,"
- Model alignment: Ensuring a model adheres to desired ethical, safety, and policy constraints. "to improve model alignment."
- Model provenance: The origin and development history of a model, affecting trust and security posture. "model provenance may factor into models’ resilience"
- Model-agnostic: Applicable across different models without requiring model-specific customization. "third-party model-agnostic guardrails"
- Multi-turn attacks: Adversarial strategies carried out over several conversational turns to erode defenses. "multi-turn attacks achieving success rates between 25.86 % and 92.78 %"
- Open-weight models: Models whose weights are available for use and fine-tuning by external parties. "Open-weight models provide researchers and developers with accessible foundations"
- Post-training: Processes applied after pretraining (e.g., alignment, instruction tuning) to shape model behavior. "developers are “in the driver seat to tailor safety for their use case” in post-training."
- Prompt injection: Inputs that insert or override instructions to subvert intended model behavior. "prompt injection and jailbreak attacks."
- Red teaming: Systematic adversarial evaluation by specialized testers to uncover security weaknesses. "regular red-teaming exercises."
- Refusal models: Auxiliary models or mechanisms that detect and block unsafe requests or outputs. "tool-based moderation such as filtering, refusal models"
- Refusal Reframe: A strategy that reframes a refusal into a different context to bypass safety constraints. "Crescendo, Information Decomposition and Reassembly, Role-Play, Contextual Ambiguity, and Refusal Reframe."
- Role-Play: An attack method that assigns personas or roles to elicit disallowed content. "Crescendo, Information Decomposition and Reassembly, Role-Play, Contextual Ambiguity, and Refusal Reframe."
- Runtime guardrails: Safety controls operating during model inference to monitor and filter inputs/outputs. "third-party model-agnostic runtime guardrails"
- Security gap: The difference in vulnerability between conditions (e.g., single-turn vs multi-turn) indicating risk exposure. "Security gaps were predominantly positive,"
- Semantic Manipulation: Techniques that exploit meaning and phrasing to coax unsafe outputs without overtly harmful keywords. "Semantic Manipulation shows Mistral Large 2,"
- Single-turn attacks: One-shot adversarial inputs without iterative interaction. "2x to 10x higher than single-turn attacks."
- Subthreats: Fine-grained threat types within broader categories used for detailed vulnerability analysis. "The top 15 subthreats demonstrated extremely high success rates"
- System prompts (meta-prompts): Special high-priority instructions that condition a model’s behavior and scope. "use case-specific meta-prompts (system prompts)"
- Threat modeling: Analyzing systems to identify assets, risks, and trust boundaries for security planning. "Perform threat modeling of application/architecture to identify and analyze trust boundaries."
- Tool-based moderation: External tools that filter or block unsafe inputs/outputs to enforce safety policies. "tool-based moderation such as filtering, refusal models"
- Trust boundaries: Interfaces where data or control crosses between components with different trust levels. "trust boundaries"
Collections
Sign up for free to add this paper to one or more collections.

