- The paper demonstrates that integrating fixed random reservoir layers accelerates convergence while reducing computational overhead.
- The methodology includes various reservoir types—Transformer, FFN, BiGRU, and CNN—evaluated on tasks such as machine translation and language modeling.
- The novel backskipping approach efficiently approximates gradients, maintaining robust performance across diverse NLP benchmarks.
Introduction
The paper "Reservoir Transformers" explores the concept of integrating fixed random layers, also referred to as "reservoir" layers, within transformer models. This approach aims to maintain competitive model performance while achieving faster convergence and greater efficiency by using some layers that are not updated during training. By alternating these reservoir layers with standard transformer layers, the paper investigates their implications on machine translation and language modeling tasks, including masked LLM pre-training. The research is inspired by traditional ideas in machine learning, hinting at the potential benefits of random layer inclusion such as reduced computational overhead.
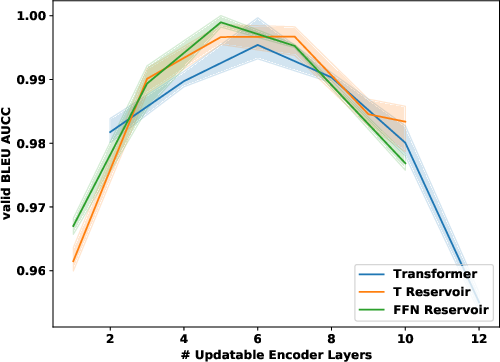
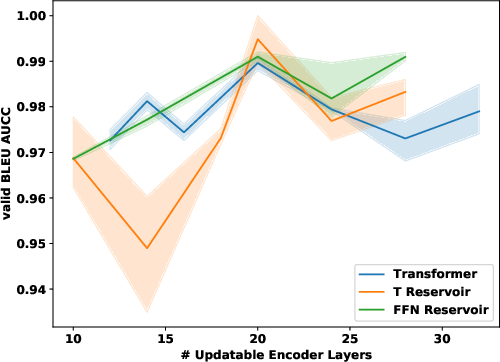
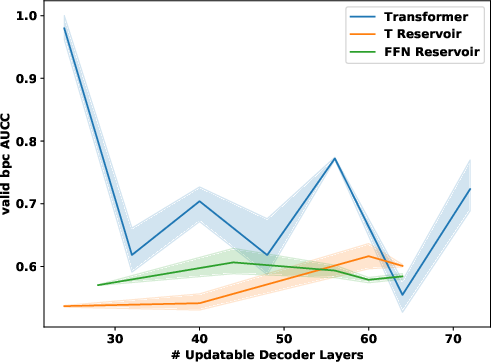
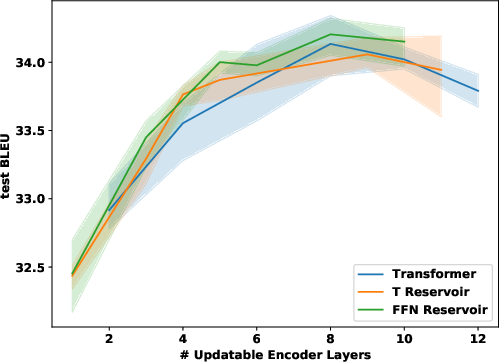
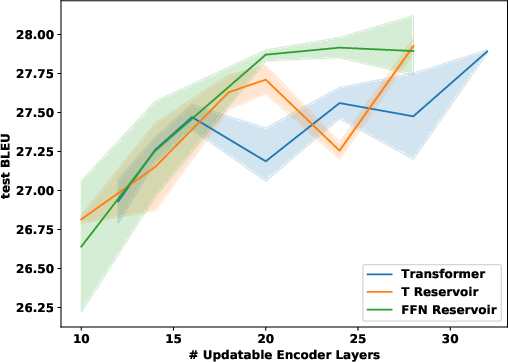
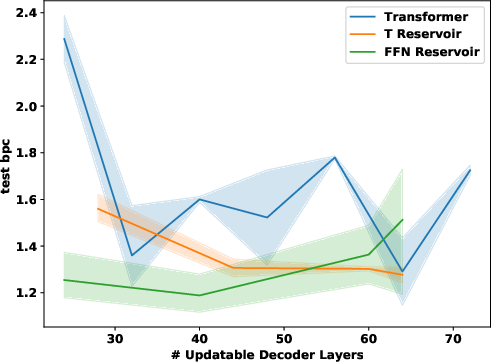
Figure 1: Validation (top) and test (bottom) results for IWSLT (left), WMT (middle) and enwiki8 language modelling (right). IWSLT and WMT are BLEU (high is good); enwiki8 is BPC (low is good). Comparison of regular transformer (blue) and reservoir transformer with FFN (green) or Transformer reservoir (orange) layers added.
Reservoir Layers and Architecture
Reservoir layers are defined as fixed, randomly initialized layers that do not undergo updates after initialization. The concept of reservoir computing, which forms the basis of this approach, entails using fixed non-linear transformations with a lightweight readout network. The reservoir transformers use this idea by interspersing these layers throughout the transformer network, alternating between reservoir layers and standard trainable layers.
There are multiple types of reservoir layers proposed within the paper:
- Transformer Reservoir: A standard transformer layer with parameters frozen after initialization, including the self-attention module.
- FFN Reservoir: Only the feed-forward neural network part in the transformer layer is frozen, excluding the attention mechanism.
- BiGRU Reservoir: Utilizes bidirectional GRU layers, aligning more closely with traditional reservoir computing methods often based on recurrent architectures.
- CNN Reservoir: Incorporates fixed convolutional layers, such as light dynamical convolution, which have shown competitive performance in sequence tasks.
The application of these reservoir layers can help in understanding the dynamics and capability of transformer models even when parts of their architecture remain unoptimized.
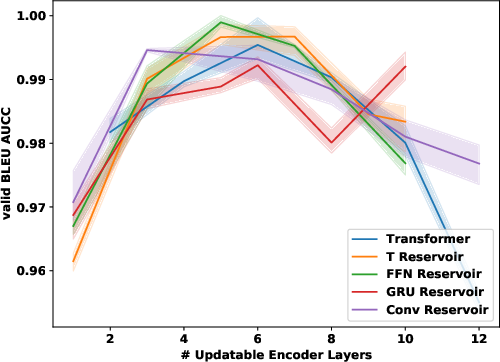
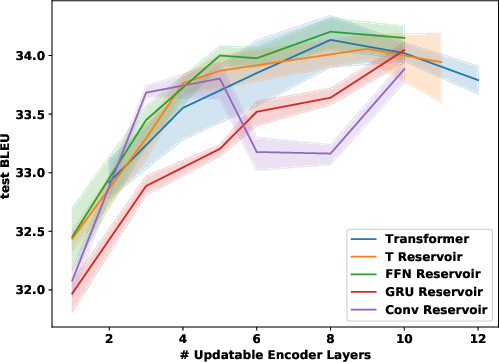
Figure 2: IWSLT comparison of different hybrid architectures with different reservoir layers.
Evaluation
The paper conducts comprehensive evaluations over several NLP tasks such as machine translation (IWSLT and WMT), language modeling (enwiki8), and masked LLM pre-training (using RoBERTa). Performance is gauged in terms of convergence speed and final task performance, providing valuable insight into computational efficiency and generalization capabilities.
Key findings include:
- Faster Convergence: Reservoir transformers consistently show improvements in wall-clock compute time until convergence compared to standard models.
- Efficient Deployment: By not updating certain layers, computational efficiency is enhanced, offering benefits for large-scale pre-training and edge deployment scenarios.
- Robust Performance: Despite the inclusion of non-updated layers, task performance remains comparable, if not superior, to regular transformers.
For machine translation and language modeling, reservoir models performed well across various configurations, reflecting strong adaptability.
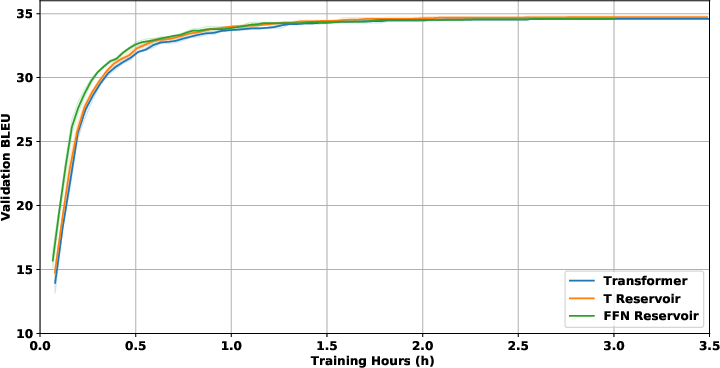
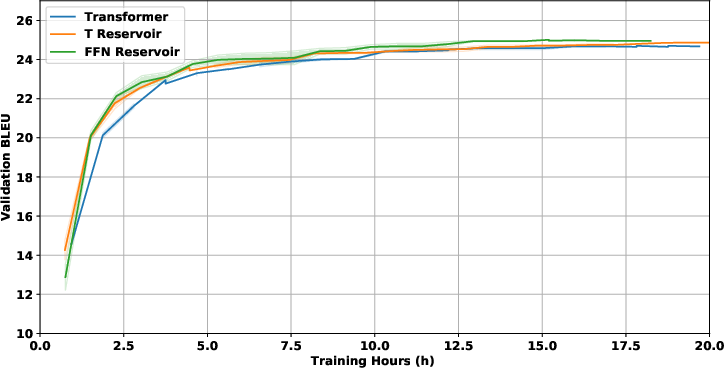
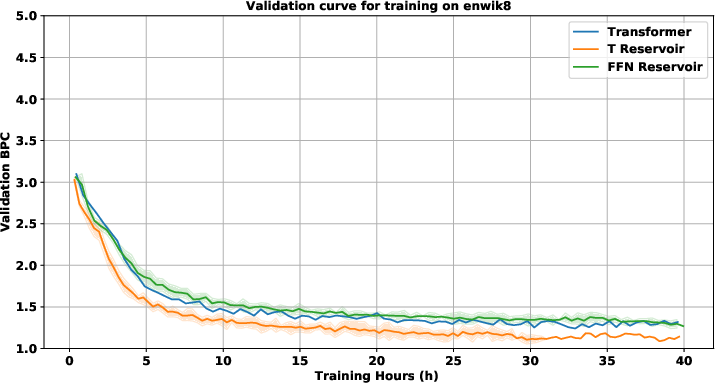
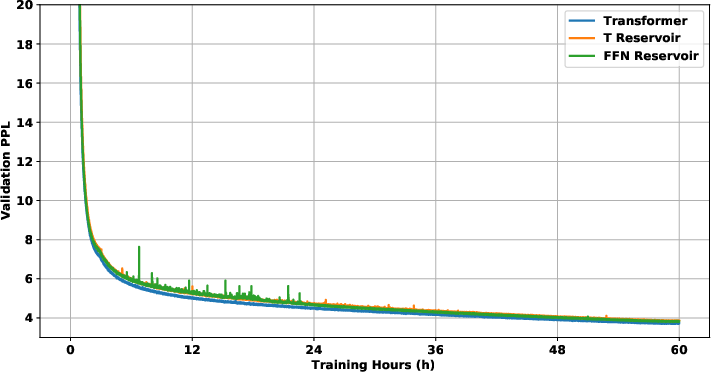
Figure 3: IWSLT with 2-layer decoder validation plot (upper left). WMT with 24-layer decoder validation plot (upper right). Enwik8 with 48-layer decoder validation plot (lower left). RoBERTa with 12-layer decoder validation plot (lower right).
Backskipping Concept
The paper introduces the novel backskipping approach, which further enhances efficiency by skipping backpropagation through reservoir layers, akin to bypassing backward calculation with gradient approximations. This concept leverages policy gradients to estimate the upstream gradients without performing conventional backward passes.
This demonstrates potential for reducing computational complexity while retaining model performance, leading to greater efficiency, particularly in large-scale neural network training scenarios.
Conclusion
The "Reservoir Transformers" paper successfully challenges the conventional wisdom that model layers must be trained to achieve optimal performance. By leveraging fixed random layers, it underlines several profound implications for transformer architecture design, engaging both theoretical and practical considerations. The research opens avenues for further exploration into hybrid and backskipping strategies, potentially catalyzing innovations in model efficiency and scalable neural network training.