- The paper introduces FinRAGBench-V, a benchmark tailored for integrating visual data into Retrieval-Augmented Generation systems for financial documents.
- The RGenCite baseline model combines retrieval, generation, and visual citation, and it is evaluated using innovative page and block-level metrics.
- Experimental results show that multimodal retrievers outperform text-only models, though challenges remain in complex numerical reasoning and fine-grained citation.
FinRAGBench-V: A Multimodal Retrieval-Augmented Generation Benchmark in Finance
Introduction
"FinRAGBench-V: A Benchmark for Multimodal RAG with Visual Citation in the Financial Domain" introduces a novel benchmark tailored for the financial domain, focusing on integrating visual data into Retrieval-Augmented Generation (RAG) systems. This benchmark addresses the limitations of existing RAG models that predominantly rely on textual data and neglect the rich visual content inherent in financial documents. The paper also proposes RGenCite, a baseline model for this benchmark, combining retrieval, generation, and visual citation.
Benchmark Construction
Retrieval Corpus and QA Dataset
FinRAGBench-V consists of a bilingual retrieval corpus and a meticulously curated question-answering (QA) dataset. The corpus includes 60,780 Chinese and 51,219 English pages sourced from diverse financial documents, such as research reports, financial statements, prospectuses, and financial news.
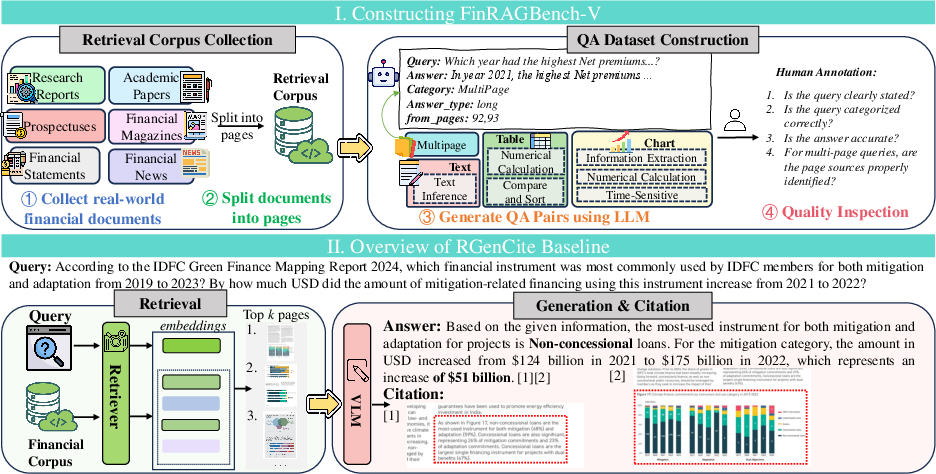
Figure 1: I. Workflow of constructing FinRAGBench-V, including a retrieval corpus and a QA dataset: \ding{172
The QA dataset features 855 Chinese and 539 English pairs and is categorized into seven types based on data heterogeneity and reasoning complexity, including text inference, chart extraction, and multi-page reasoning. This comprehensive dataset allows for a nuanced assessment of multimodal RAG capabilities in the financial sector.
RGenCite Model
Integration of Retrieval, Generation, and Citation
RGenCite serves as a baseline model for FinRAGBench-V. The model is designed to generate answers and provide visual citations by first retrieving relevant content from the corpus and then generating responses while citing specific textual and visual elements. This approach ensures not only accuracy in responses but also traceability, which is crucial in the finance domain.
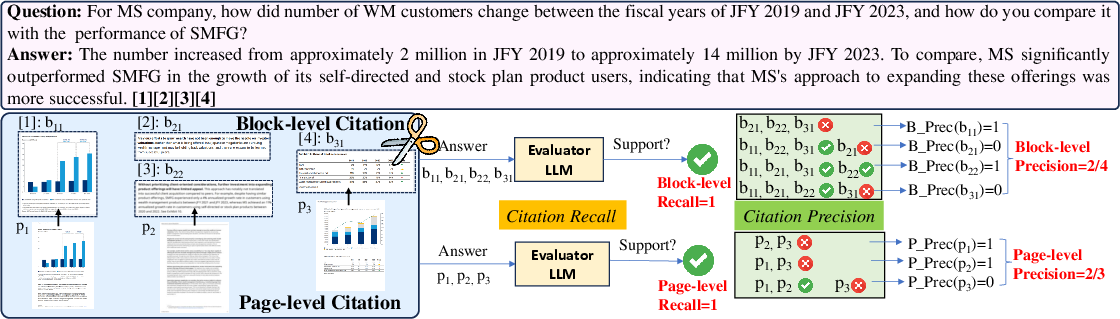
Figure 2: An example of the automatic evaluation of visual citation.
Visual Citation Evaluation
A novel evaluation methodology is introduced to systematically assess the visual citation capabilities of MLLMs. The paper proposes precision and recall metrics at both page and block levels, with evaluation strategies including box-bounding and image-cropping.
Experimental Findings
The experimental results reveal several key insights into the performance of multimodal RAG systems:
- Multimodal retrievers outperform text-only retrievers by preserving critical information present in charts and tables.
- While current MLLMs handle text inference adeptly, they struggle with numerical reasoning and multi-document inference.
- Multimodal RAG systems show proficiency in page-level citation but face challenges with block-level citation, highlighting the difficulty in attributing information to specific visual sections accurately.
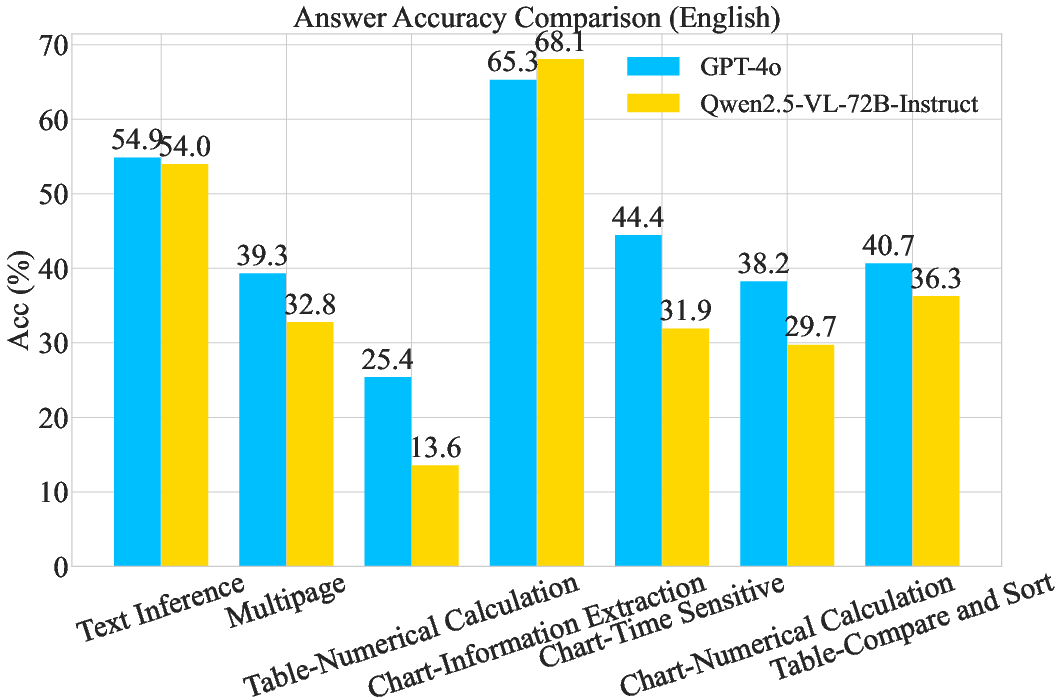
Figure 3: The comparison of answer accuracy between different question categories.
Challenges and Observations
The development of FinRAGBench-V and experiments conducted using RGenCite identify persistent challenges in the field of multimodal RAG in finance:
- Complexity of Financial Data: The sophisticated nature of financial documents, which often require deep understanding and precise extraction, remains a challenge for existing models.
- Visual Complexity: Extracting and reasoning using complex financial charts and multi-page tables present significant hurdles.
- Evaluation Nuances: The absence of established metrics for visual citation evaluation underscores the benchmark's value in driving advancements in this area.
Conclusion
FinRAGBench-V is positioned as a critical resource for advancing multimodal RAG systems' ability to process and produce finance-related insights. However, the benchmark also emphasizes the need for dedicated models optimized for the financial domain's unique characteristics. Future research should continue to refine these evaluation methodologies and address the highlighted challenges, ensuring the reliable and accurate deployment of RAG systems in professional financial applications.