REVNET: Rotation-Equivariant Point Cloud Completion via Vector Neuron Anchor Transformer
Abstract: Incomplete point clouds captured by 3D sensors often result in the loss of both geometric and semantic information. Most existing point cloud completion methods are built on rotation-variant frameworks trained with data in canonical poses, limiting their applicability in real-world scenarios. While data augmentation with random rotations can partially mitigate this issue, it significantly increases the learning burden and still fails to guarantee robust performance under arbitrary poses. To address this challenge, we propose the Rotation-Equivariant Anchor Transformer (REVNET), a novel framework built upon the Vector Neuron (VN) network for robust point cloud completion under arbitrary rotations. To preserve local details, we represent partial point clouds as sets of equivariant anchors and design a VN Missing Anchor Transformer to predict the positions and features of missing anchors. Furthermore, we extend VN networks with a rotation-equivariant bias formulation and a ZCA-based layer normalization to improve feature expressiveness. Leveraging the flexible conversion between equivariant and invariant VN features, our model can generate point coordinates with greater stability. Experimental results show that our method outperforms state-of-the-art approaches on the synthetic MVP dataset in the equivariant setting. On the real-world KITTI dataset, REVNET delivers competitive results compared to non-equivariant networks, without requiring input pose alignment. The source code will be released on GitHub under URL: https://github.com/nizhf/REVNET.


























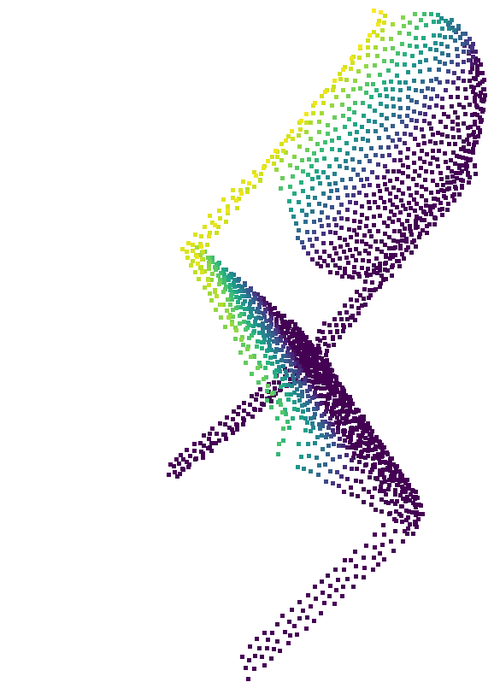





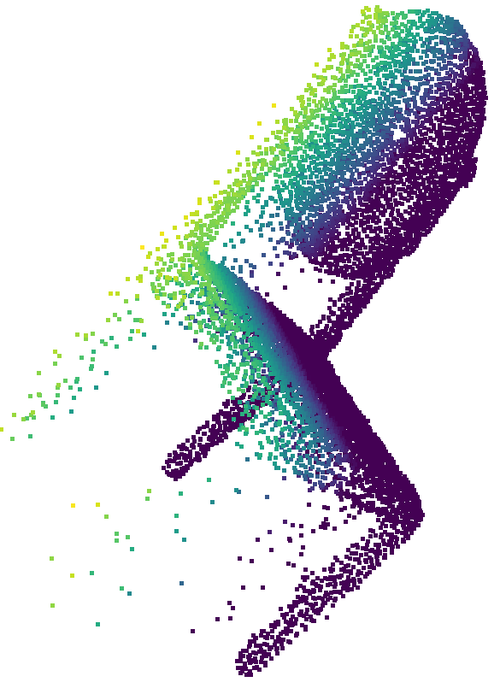























































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Overview
This paper is about helping computers “fill in the blanks” of 3D shapes. When a 3D scanner looks at an object (like a car or a chair), it often can’t see the whole thing, so it produces an incomplete set of dots in space called a point cloud. The authors introduce a new method, called REVNET, that completes these 3D shapes accurately even when the object is turned to any angle. In other words, the method works no matter how the object is rotated.
What Questions Does the Paper Ask?
- How can we complete 3D shapes from partial point clouds without first forcing them into a standard, fixed pose?
- Can we build a model that naturally “understands” rotations, so it works the same whether an object is upright, tilted, or upside down?
- Can we keep fine local details (like thin chair legs or car mirrors) while still being robust to rotations?
How Does the Method Work?
Key ideas explained
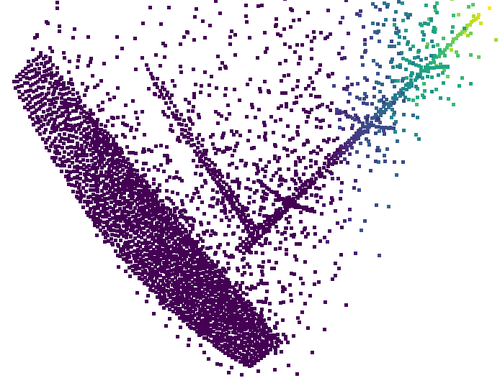
- Point cloud: Imagine you’re looking at a statue in a dark room with only a flashlight. The dots where the light touches form a “cloud” of points that represent the statue’s surface. That’s a point cloud.
- Rotation-equivariant: If you rotate the input shape, the model’s internal features rotate in a matching way, and the output rotates accordingly. Think of it like spinning a toy: if you spin the toy, the model’s “thoughts” about the toy spin with it, so predictions stay consistent.
- Anchors: These are key spots (landmarks) on the object used to organize and rebuild the overall shape. Instead of trying to complete the whole shape at once, the model focuses on these anchors and then fills in details around them.
- Transformer: A type of neural network that uses “attention” to focus on the most relevant information. Here, it looks at relationships among anchors to guess the missing parts.
- Vector Neuron (VN) network: Instead of storing features as plain numbers, the VN network stores them as tiny 3D arrows (vectors). When you rotate the input, these arrows rotate too, which is perfect for 3D tasks.
- Equivariant vs. invariant: Equivariant features change in a predictable way with rotation (they rotate). Invariant features don’t change at all when you rotate the input.
The pipeline in simple steps
The model processes a partial point cloud in four main steps:
- Find and describe landmarks (anchors)
- The model picks important points (anchors) on the visible part of the shape and creates robust “arrow-like” features (using the VN network). These features rotate consistently with the object.
- Predict missing anchor positions
- To guess where the missing anchors should be, the model temporarily switches from rotation-sensitive features to a rotation-free (invariant) space. In that stable space, it predicts where the missing anchors go. Then it converts those positions back to the original space so they rotate correctly with the object.
- Infer features for missing anchors with a VN Transformer
- A special VN Transformer uses attention to combine information from known anchors to estimate the features of the missing anchors. It uses a “channel-wise subtraction” trick: it compares differences between anchors to decide which ones matter most, and it does this separately for each feature channel, which improves detail.
- Generate dense points around each anchor
- Finally, for both the known and the newly predicted anchors, the model produces dense clusters of points to reconstruct the full shape. It again uses the invariant-and-back trick to keep this step stable and rotation-friendly.
Two technical improvements that make it work better
- Equivariant bias: Regular neural networks use a “bias” to make features more flexible. Bias usually breaks rotation behavior, but the authors design a bias that rotates along with the input, keeping everything consistent.
- ZCA-based layer normalization: This is a way to “whiten” or balance the features so different directions (x, y, z) don’t interfere with each other too much. Think of it like straightening and evenly scaling the axes so the model learns more reliably, without losing the rotation-friendly property.
What Did They Find?
- Strong results on a synthetic benchmark (MVP dataset)
- REVNET beats other methods, especially those that are designed to handle rotations, in accuracy. It also produces very consistent outputs when the same object is rotated to many different angles.
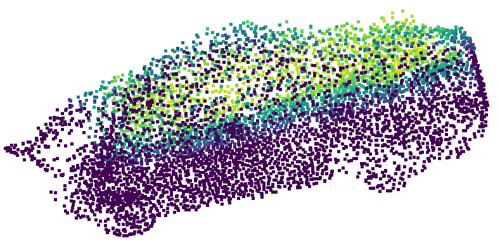
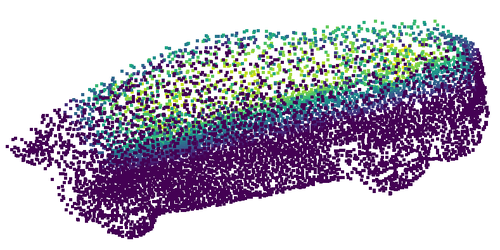
- Competitive on real-world data (KITTI cars)
- On real LiDAR scans of cars, REVNET performs on par with leading methods—even though it doesn’t need the input shapes to be aligned to a standard pose first. This shows it can work “in the wild” without special preprocessing.
Why this matters:
- Rotation robustness: The model stays reliable no matter how the object is oriented.
- Detail preservation: Using anchors and attention helps keep fine details that older, “global-only” methods often miss.
- Less training hassle: Because the network is naturally rotation-friendly, it doesn’t need tons of “randomly rotated” training examples to learn robustness.
Why This Matters and What’s the Impact?
- More reliable 3D understanding: In real life, objects can appear in any orientation. A model that naturally handles rotations is more dependable for robots, self-driving cars, AR/VR, and 3D modeling.
- Better local detail: The anchor-based design helps recreate small, important parts—useful for inspection, design, or navigation tasks.
- Simpler training and deployment: Reducing the need for heavy rotation data augmentation and pose alignment can save time, reduce errors, and make systems easier to maintain.
- A foundation for future 3D methods: The paper’s VN-based tricks (equivariant bias, ZCA normalization, and smart invariant/equivariant switching) can be reused to improve other 3D tasks, like object recognition or registration.
In short, REVNET is a practical and accurate way to complete 3D shapes that works well no matter how the object is rotated, and it keeps the small details that make shapes look realistic.
Collections
Sign up for free to add this paper to one or more collections.

