- The paper introduces SIMECO, the first network achieving full SIM(3) equivariance for robust 3D shape completion.
- It leverages feature canonicalization, similarity-invariant reasoning via VN-transformer, and transform restoration to disentangle intrinsic geometry from extrinsic transformations.
- Experimental evaluations demonstrate improved Chamfer distance and F1 scores across synthetic and real-world benchmarks, highlighting robustness under varying pose and scale.
SIM(3)-Equivariant Shape Completion: Architecture, Analysis, and Implications
Introduction and Motivation
The paper addresses a critical limitation in 3D shape completion: the reliance on pre-aligned, canonicalized input data, which introduces pose and scale biases that undermine generalization to real-world, unaligned scans. Existing methods, including those with SO(3) or SE(3) equivariance, still depend on privileged information such as ground-truth centroids or scales, which is unavailable in practical deployments. The authors argue that robust generalization requires full SIM(3) equivariance—equivariance to rotation, translation, and scaling—so that models are agnostic to extrinsic transforms and focus on intrinsic geometry.
SIM(3)-Equivariant Architecture
The proposed architecture, SIMECO, is the first to achieve full SIM(3) equivariance for shape completion. The network is constructed from modular blocks, each comprising three stages: feature canonicalization, similarity-invariant geometric reasoning, and transform restoration. This design ensures that every layer is SIM(3)-equivariant, and the final output is expressed in the original sensor frame.
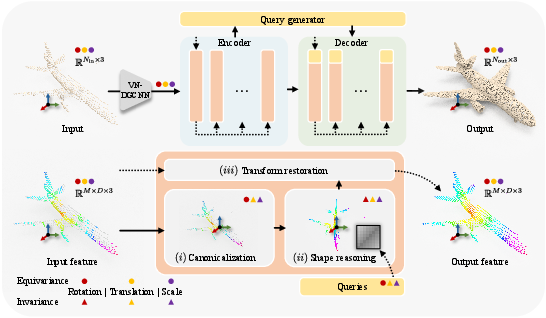
Figure 1: Overview of the SIM(3)-equivariant shape completion pipeline, showing feature extraction, canonicalization, invariant reasoning, and transform restoration.
Feature Canonicalization
Canonicalization removes translation and scale from feature representations using an extended layer normalization. For a set of vector features Vi, the mean is subtracted to eliminate translation, and the result is normalized to remove scale, preserving only the direction (rotation equivariance). This operation is applied channel-wise and is proven to be invariant to translation and scale, and equivariant to rotation.
Similarity-Invariant Shape Reasoning
Shape reasoning is performed in the canonicalized feature space using a VN-Transformer, where attention weights are computed via Frobenius inner products of vector neuron projections. These weights are invariant to SIM(3) transforms, ensuring that the network reasons about intrinsic geometry without being influenced by extrinsic pose or scale.
After each reasoning step, translation and scale are re-injected via a restoration path, using global statistics from the input features. This ensures that the final output is aligned with the sensor frame, a requirement for downstream tasks such as robotic manipulation or autonomous driving.
Implementation Details
The architecture builds on AdaPoinTr, replacing its DGCNN with a VN-DGCNN for local geometric feature extraction and substituting all Transformer layers with the proposed SIM(3)-equivariant modules. The network processes partial point clouds of 2,048 points and predicts completions with 16,384 points. All components, including the query generator and reconstruction head, are implemented to preserve equivariance or invariance as appropriate.
Experimental Evaluation
De-Biased Benchmarking
The authors introduce a rigorous evaluation protocol that eliminates hidden pose and scale cues by applying random SIM(3) transforms at test time. Under this protocol, SIMECO outperforms both data augmentation-based and equivariant baselines on the PCN benchmark, achieving the lowest Chamfer distance (ℓ1) and highest F1 scores across all categories.
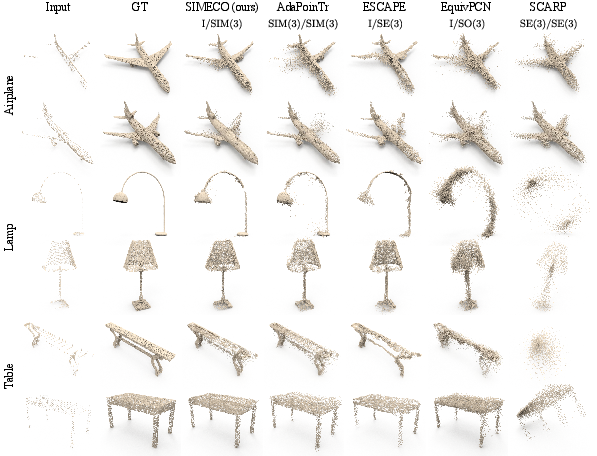
Figure 2: Comparison on PCN. The SIM(3)-equivariant model outperforms other equivariant and non-equivariant baselines under de-biased evaluation.
Robustness to Pose and Scale Perturbations
SIMECO maintains completion quality under large pose and scale changes, whereas competing methods degrade significantly.

Figure 3: Robustness to pose and scale perturbations. The SIM(3)-equivariant model is stable under large extrinsic variations.
Cross-Domain Generalization
When trained on synthetic data and evaluated on real-world scans from KITTI and OmniObject3D, SIMECO sets new records, reducing minimal matching distance on KITTI by 17% and Chamfer distance on OmniObject3D by 14% compared to the best non-equivariant baselines.


Figure 4: Cross-domain generalization to real scans. The model trained on PCN generalizes to KITTI and OmniObject3D, recovering more details than augmented baselines.
Equivariance Group Ablation
Ablation studies show that each added symmetry group (rotation, translation, scale) improves performance, with full SIM(3) equivariance yielding the best results in real-world operational design domains.
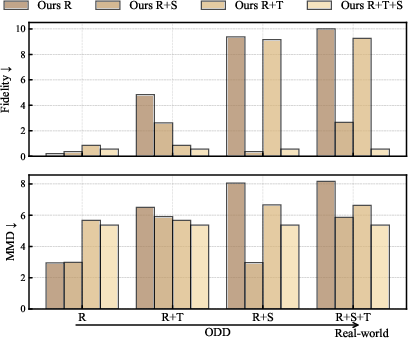
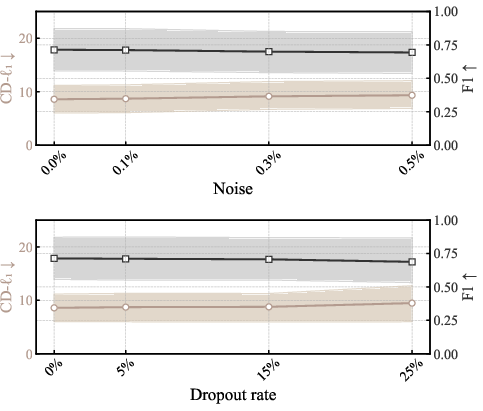
Figure 5: Equivariance group ablation. Each added symmetry group improves cross-domain performance, with full SIM(3) performing best.
Failure Cases
The model occasionally fails on ambiguous partial scans or when input quality is poor, disrupting the transform restoration module.
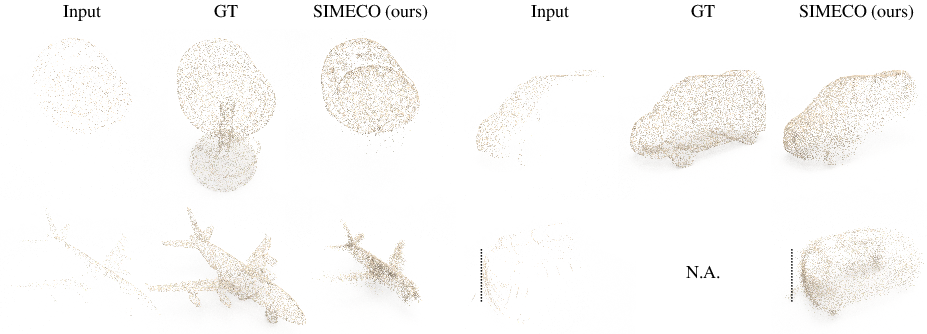
Figure 6: Failure cases. Ambiguous geometry or poor input quality can lead to incorrect completions or misalignment.
Theoretical and Practical Implications
The paper provides formal proofs that all network modules are SIM(3)-equivariant, and demonstrates that architectural equivariance is superior to data augmentation or explicit pose estimation. The approach is robust to input noise and point dropout, and does not require canonicalization of training data. Computationally, SIMECO is more efficient than other equivariant baselines, with a per-scan latency of 76 ms, and its performance advantage persists after controlling for parameter count.
Limitations and Future Directions
While SIMECO removes dependence on absolute pose and scale, this can discard helpful cues in settings where canonical frames are available. The method does not explicitly handle articulated or multi-object scenes, and the computational overhead of vector-valued features is higher than scalar baselines. Extending the framework to multi-object and large-scale scene modeling is a promising direction.
Conclusion
This work establishes full SIM(3) equivariance as a necessary and effective principle for generalizable 3D shape completion. By disentangling intrinsic geometry from extrinsic transforms at the architectural level, the proposed method achieves state-of-the-art results on both synthetic and real-world data under strict, unbiased evaluation. The findings have significant implications for deploying shape completion in robotics, autonomous vehicles, and digital heritage, and open avenues for further research in equivariant modeling for complex 3D environments.