DiffusionNFT: Online Diffusion Reinforcement with Forward Process
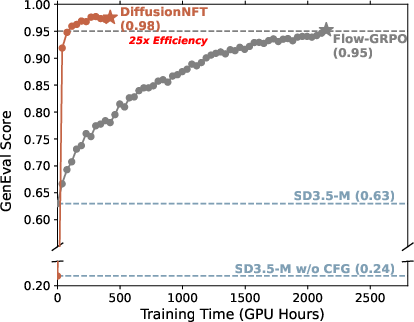
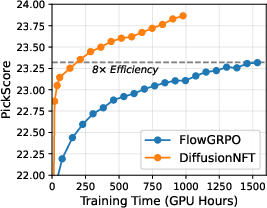
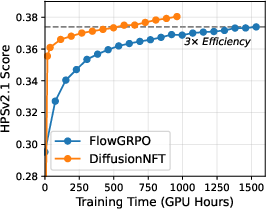
Abstract: Online reinforcement learning (RL) has been central to post-training LLMs, but its extension to diffusion models remains challenging due to intractable likelihoods. Recent works discretize the reverse sampling process to enable GRPO-style training, yet they inherit fundamental drawbacks, including solver restrictions, forward-reverse inconsistency, and complicated integration with classifier-free guidance (CFG). We introduce Diffusion Negative-aware FineTuning (DiffusionNFT), a new online RL paradigm that optimizes diffusion models directly on the forward process via flow matching. DiffusionNFT contrasts positive and negative generations to define an implicit policy improvement direction, naturally incorporating reinforcement signals into the supervised learning objective. This formulation enables training with arbitrary black-box solvers, eliminates the need for likelihood estimation, and requires only clean images rather than sampling trajectories for policy optimization. DiffusionNFT is up to $25\times$ more efficient than FlowGRPO in head-to-head comparisons, while being CFG-free. For instance, DiffusionNFT improves the GenEval score from 0.24 to 0.98 within 1k steps, while FlowGRPO achieves 0.95 with over 5k steps and additional CFG employment. By leveraging multiple reward models, DiffusionNFT significantly boosts the performance of SD3.5-Medium in every benchmark tested.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-Read Summary of “DiffusionNFT: Online Diffusion Reinforcement with Forward Process”
What is this paper about?
This paper introduces a new way to improve image‑generating AI models called diffusion models. The new method is named DiffusionNFT. It helps the model learn from feedback (like a coach giving a score to each image) while it is still being used (“online” learning). The key idea is to train on the simple “forward” part of diffusion (adding noise) instead of the complicated “reverse” part (removing noise). This makes training faster, simpler, and more flexible.
What questions does the paper ask?
The paper focuses on three main questions:
- Can we do reinforcement learning (RL) for diffusion models by training on the forward process (adding noise), not the reverse process (removing noise)?
- Can we use both good and bad generations to guide the model in the right direction?
- Can we avoid tricky math like exact likelihoods and avoid extra tricks like CFG (Classifier-Free Guidance), yet still get better and faster results?
How does the method work? (Using simple analogies)
Think of image generation like sculpting a statue from a noisy block of stone:
- The “forward process” is like covering a clean statue with layers of dust (adding noise).
- The “reverse process” is like carefully brushing away the dust to reveal the statue (denoising).
Most past RL methods tried to teach the model during the reverse process. That is hard, slow, and limits the tools you can use.
DiffusionNFT does something smarter:
- It generates several images for a given text prompt.
- A “judge” (a reward model) scores each image: higher score = better match to the goal.
- It splits the images into “positives” (good) and “negatives” (bad).
- Then it learns a direction to move the model from “what made bad images” toward “what made good images.” You can think of this as a compass pointing from “don’t do this” to “do more of that.”
How is this trained?
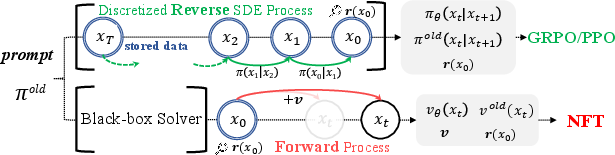
- Instead of adjusting the model during denoising (reverse), DiffusionNFT trains during the forward process using a standard technique called “flow matching.” In simple terms, the model learns how images change as noise is added, which also teaches it how to undo the noise later.
- The method uses an “implicit” trick so it doesn’t need two separate models (one for positives and one for negatives). It blends them inside one model using a single knob called the guidance strength (β). That keeps training simple and stable.
- It’s “off-policy,” which means it can learn from images made by older versions of the model—no need to tightly sync sampling and training.
- It only needs the final clean images (and their scores) for learning, not the whole step-by-step denoising path. This saves memory and time.
- You can use any sampler (any way of stepping through the process), including fast ODE solvers—no restriction to special noisy samplers.
In everyday language: DiffusionNFT treats feedback like a push from “bad” toward “good” and bakes that push directly into normal diffusion training, on the easier side of the process.
What did they find, and why is it important?
Key results:
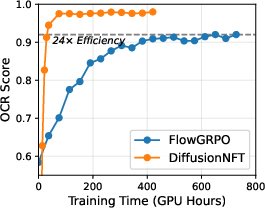
- Much faster learning: DiffusionNFT was 3× to 25× more efficient than a strong baseline called FlowGRPO.
- Big score jumps: On a test called GenEval, the score improved from 0.24 to 0.98 in about 1,000 steps. The baseline took over 5,000 steps to reach 0.95 and needed extra tricks (CFG).
- No CFG needed: DiffusionNFT trains a single model without CFG, yet still beats CFG-based baselines.
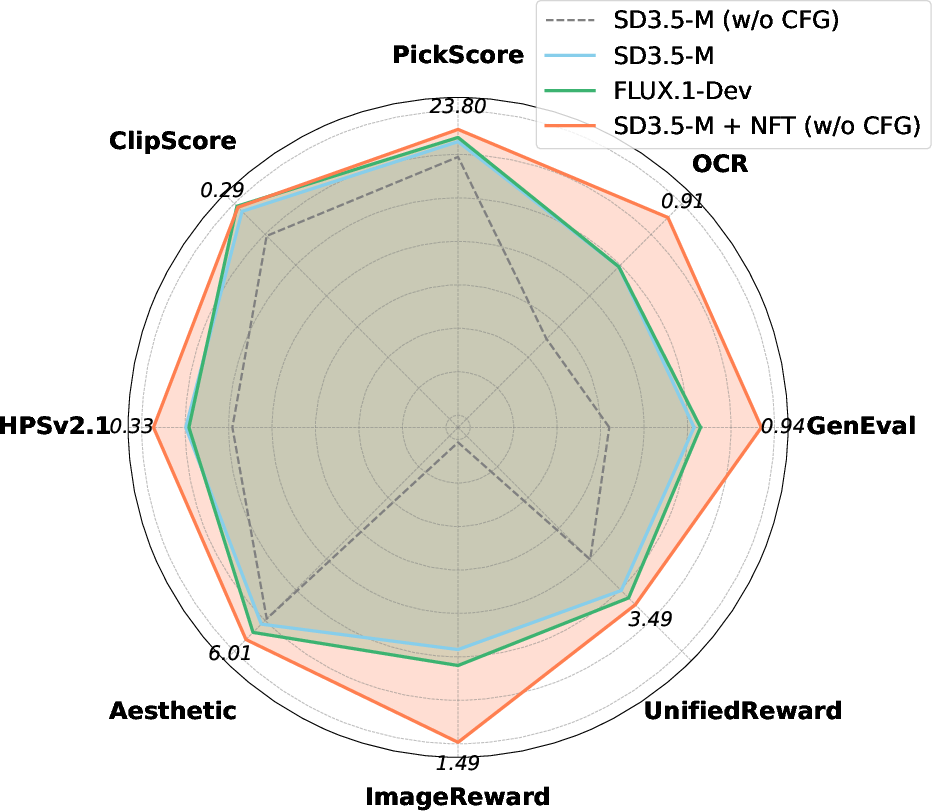
- Works with many goals at once: By combining multiple reward models (different “judges” that check different qualities like text alignment, image quality, readability of text in images, and human preference), the method significantly improved a popular base model (SD3.5-Medium) on all tested benchmarks.
- Practical tips:
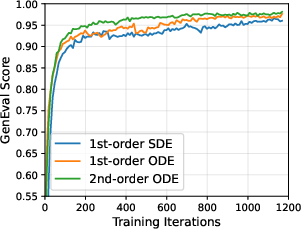
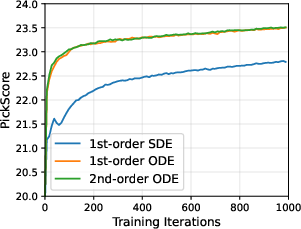
- Using ODE samplers generally gave better data for learning than SDE samplers.
- The “negative-aware” part (penalizing bad generations) was crucial—removing it made training collapse.
- A careful schedule for updating the sampling model (soft EMA updates) and a smart loss weighting made training more stable.
- The guidance strength (β) balances speed and stability; values around 1 worked well.
Why this matters:
- Training on the forward process avoids many headaches (no need for exact likelihoods or storing long denoising chains).
- You can plug in any solver you like when generating images.
- It unifies reinforcement-style feedback with ordinary supervised training, making the system both simple and powerful.
What’s the bigger impact?
- Simpler, faster alignment: DiffusionNFT offers an easy recipe to make image generators follow instructions and human preferences better—without relying on complicated extras like CFG.
- Scales to many goals: Because it supports multiple reward models, it can make models better at a range of skills at the same time (accuracy, aesthetics, text rendering, etc.).
- Broadly useful idea: The “negative-aware” forward-training idea could inspire similar approaches in other kinds of generative models (images, video, maybe even audio).
- Practical for real systems: Being “likelihood-free,” “off-policy,” and “solver-flexible” lowers the cost and complexity of improving models online—useful for companies and labs that want fast iteration.
In short: DiffusionNFT shows that teaching diffusion models using the easy side of the process (adding noise) and learning from both good and bad examples can make training much faster, simpler, and more effective—all while removing the need for complex tricks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper that future work could concretely address:
- Finite-sample and finite-capacity guarantees: Theorems assume unlimited data and model capacity; formal convergence and improvement guarantees under realistic data, capacity, and optimization noise are not established.
- Practical estimation of α(t) and Δ: The key guidance relation depends on intractable densities (πt+/πtold) and idealized rewards; no method is provided to estimate α(t) or Δ from finite samples, nor to adapt the guidance strength β to match α(t).
- Calibration of optimality probability r: The transformation from raw rewards to r∈[0,1] via group normalization and clipping is heuristic; the impact of miscalibration on theory and training stability, and methods to calibrate or learn r, are not analyzed.
- Sensitivity to reward normalization choices: The method relies on per-prompt grouping (K images), Z normalization, clipping bounds; sensitivity studies and principled selection strategies for K and Z are missing.
- Off-policy training without importance sampling: The paper asserts off-policy sufficiency but provides no bias bounds; conditions under which drift between πold and πθ harms learning (and how to detect/mitigate it) are open.
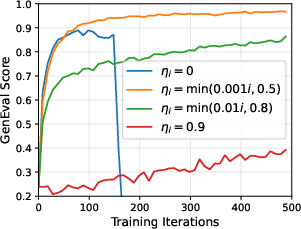
- EMA schedule theory: EMA updates of the sampling policy stabilize training empirically, but no theoretical guidance or adaptive schemes are provided to tune ηi for stability vs. sample-efficiency.
- Negative-aware loss side effects: While necessary to avoid collapse, potential impacts on diversity, coverage, and mode-dropping are not quantified (e.g., no FID/KID/precision-recall diversity metrics).
- Reward hacking and overoptimization: The method optimizes learned/model-based rewards; analyses of reward gaming (e.g., CLIP/PickScore artifacts), robustness to noisy/misaligned reward models, and countermeasures are absent.
- Multi-reward composition: Joint optimization uses a fixed training sequence; there is no framework for resolving conflicting rewards, learning dynamic weights, or exploring Pareto fronts for multi-objective trade-offs.
- Robustness to solver mismatch: Data are collected with arbitrary solvers while training uses the forward objective; the effect of solver choice during rollout vs. inference (including stochastic vs. deterministic, order, step count) on stability and performance is underexplored.
- Forward consistency claim: The paper argues improved adherence to the forward process but lacks formal verification or diagnostics quantifying Fokker–Planck consistency before vs. after finetuning.
- Generalization beyond images: Applicability to video, audio, 3D, or conditional tasks with longer temporal credit assignment is not validated; it is unclear whether reverse-process-free optimization suffices in temporally extended domains.
- Scaling to high resolutions and larger models: Experiments center on SD3.5-Medium at 512×512; compute, memory, and stability at 1024+ resolutions and with 8–12B+ parameter models are untested.
- Fair, apples-to-apples baselines: Head-to-head comparisons mix CFG use, solver choices, and step counts; controlled studies holding these factors constant are needed to isolate algorithmic gains from configuration differences.
- Human evaluation: Improvements are judged via automatic metrics (including in-domain reward models); human preference studies are needed to verify true perceptual and alignment gains and detect regressions.
- Safety and content constraints: Effects on safety (e.g., toxicity, NSFW leakage) and controllability under safety constraints are not examined; integration with safety rewards or constraints is an open direction.
- Hyperparameterization of β: Only global β choices are explored; the benefits of time-dependent β(t), prompt- or reward-adaptive β, and principled selection criteria remain open.
- Time-weighting w(t) design: The adaptive self-normalized weighting is heuristic; its theoretical grounding, stability region, and interactions with solver order and step counts are not characterized.
- Pairwise preference integration: The method uses scalar rewards; extending NFT-style forward training to pairwise preference data (DPO-like objectives) with theoretical backing remains to be developed.
- CFG interplay and controllability: While the approach is CFG-free, many deployments desire controllable guidance; how to reintroduce or emulate CFG-like controls post-RL (without two-model complexity) is not addressed.
- Diversity–quality trade-offs under multi-reward training: Jointly optimizing alignment and aesthetic rewards could reduce diversity; explicit measurement and mitigation strategies (e.g., entropy regularization) are not provided.
- Sample complexity and compute accounting: Absolute sampling/training costs, memory footprints, replay buffer strategies, and cost-to-reward curves versus PPO/GRPO/RWR/DSPO-style baselines are not reported.
- Robustness to reward noise and drift: How the method behaves with noisy, drifting, or adversarial reward models (and how to regularize against them) is unexplored.
- Theoretical consistency under model misspecification: When vθ cannot represent the ideal target v*, the bias induced by implicit positive/negative parameterization and its impact on policy improvement remains unquantified.
- Applicability beyond LoRA: Results rely on LoRA finetuning; whether full-parameter tuning, adapters at different layers, or alternative parameter-efficient schemes affect stability, efficiency, or final performance is unknown.
- Data reuse and replay: The algorithm clears buffers each iteration; the benefits/risks of prioritized replay, longer-horizon off-policy reuse, and distributional coverage control are not studied.
- Long-prompt and compositional generalization: Beyond GenEval/OCR, performance on complex, long, compositional prompts, negative prompts, and fine-grained attribute control is not thoroughly evaluated.
- Inference-time efficiency/quality frontier: The influence of step count, solver order, and guidance strength on the quality–latency Pareto frontier, especially post-RL, is not systematically charted.
Practical Applications
Immediate Applications
Below is a concise set of actionable, real-world use cases that can be deployed now, leveraging DiffusionNFT’s forward-process RL, implicit guidance integration, CFG-free training, and off-policy sampling.
- Brand-aligned, on-spec image generation in production pipelines
- Sector: software, media/advertising, e-commerce
- Use case: Fine-tune existing text-to-image models (e.g., SD3.5-Medium) to adhere to brand guidelines, prompt constraints, and aesthetic preferences using model-based rewards (PickScore, ClipScore, HPSv2.1, Aesthetics).
- Tools/workflows: LoRA-based fine-tuning; multi-reward “alignment studio” that orchestrates reward models; CFG-free inference for simpler deployment; ODE-based solvers for faster sampling.
- Assumptions/dependencies: Availability and calibration of reliable reward models; high-quality prompt data; monitoring for reward hacking (over-optimization to reward proxies).
- Accurate text rendering in images for marketing, documentation, and UI mockups
- Sector: design, marketing, software
- Use case: Apply OCR rewards to improve legibility and correctness of rendered text in posters, social posts, product packaging mockups, and UI screenshots.
- Tools/workflows: Integrate OCR reward evaluators into online fine-tuning loops; adopt forward-process training to avoid storing full trajectories; deploy a “text fidelity” pre-flight check.
- Assumptions/dependencies: OCR model accuracy; domain-specific fonts and layouts may require task-specific reward tuning.
- Compositional, constraint-following visual generation for content automation
- Sector: media production, education
- Use case: Use GenEval-style rule-based rewards to enforce object presence, counts, spatial relations, and attribute constraints—e.g., generating diagrams, educational illustrations, or storyboard panels.
- Tools/workflows: Rule-based reward plug-ins (GenEval) in an online RL loop; prompt templates for constraints; batch-wise reward normalization as in Algorithm 1.
- Assumptions/dependencies: Robust rule parsers for prompts; coverage of rules by available reward functions.
- Cost- and energy-efficient model post-training at scale
- Sector: cloud/AI infrastructure, energy/sustainability
- Use case: Replace reverse-process GRPO-style training with DiffusionNFT’s forward-process RL to cut compute and wall-clock time (3–25× observed efficiency gains), lowering training costs and energy footprint.
- Tools/workflows: ODE solvers; EMA soft updates; adaptive loss weighting; decoupled sampling/training policies for asynchronous MLOps pipelines.
- Assumptions/dependencies: Comparable base-model quality; stable training hyperparameters (β, EMA schedule); reliable reward signal coverage.
- Unified, CFG-free deployment for simplified inference stacks
- Sector: software/AI platforms
- Use case: Deploy single conditional models that learn “implicit guidance” during RL (no separate unconditional model), simplifying inference routing and QA.
- Tools/workflows: CFG-free runners; “guidance-free” inference SDK; reward-driven post-training automation.
- Assumptions/dependencies: Sufficient post-training to match/exceed CFG baselines; reward models strong enough to encode desired preferences.
- Human-in-the-loop preference alignment
- Sector: content moderation, policy compliance, UX research
- Use case: Incorporate human ratings (or unified preference models) into online training loops to steer models toward desired style, safety, and inclusivity.
- Tools/workflows: Preference UIs feeding into normalized optimality probabilities; rolling buffers with EMA updates; dashboards monitoring reward drift.
- Assumptions/dependencies: Quality and representativeness of human feedback; bias auditing; governance for acceptable content.
- Synthetic data generation for vision tasks needing exact composition
- Sector: robotics, autonomous systems, retail analytics
- Use case: Generate curated visual datasets with stringent object relationships for training detectors/segmenters; enforce scene constraints via rule-based rewards.
- Tools/workflows: Sampler choice (ODE > SDE for noise-sensitive rewards); reward suites tailored to detection benchmarks; automatic prompt curriculum.
- Assumptions/dependencies: Transferability of synthetic-to-real distributions; domain-specific reward design; careful validation to avoid spurious correlations.
- Model evaluation and benchmarking in academia
- Sector: academia/research
- Use case: Study forward-process RL as a likelihood-free alternative; compare efficiency/scaling vs GRPO; test multi-reward joint optimization and guidance-free training.
- Tools/workflows: Reproducible pipelines with SD3.5-Medium; open reward models (PickScore, ClipScore, HPSv2.1); ablation on EMA, β, sampler choices.
- Assumptions/dependencies: Access to benchmarking datasets and reward implementations; fair baselines (same sampling steps; comparable LoRA settings).
Long-Term Applications
The following opportunities require further research, scaling, or validation, but are natural extensions of the paper’s methods and findings.
- Cross-modality alignment (video, audio, 3D) via forward-process RL
- Sector: entertainment, social media, AV production
- Use case: Extend DiffusionNFT to video/audio diffusion, aligning outputs with temporal/spatial constraints (e.g., lip sync, scene continuity) and human preferences.
- Potential products/workflows: “Multi-modal Alignment OS” orchestrating heterogeneous reward models; temporal rule engines; guidance-free multi-modal inference.
- Assumptions/dependencies: Well-calibrated reward models for temporal fidelity; computational scaling; memory/stability for longer sequences.
- Enterprise compliance-as-reward for automated safety and policy enforcement
- Sector: policy/compliance, regulated industries (finance, healthcare)
- Use case: Encode legal, branding, and safety policies (e.g., NSFW/bias detectors, HIPAA/GDPR constraints) into reward models; continuously align generators in production.
- Potential products/workflows: Compliance reward marketplaces; policy translators from guidelines to executable reward checks; risk dashboards.
- Assumptions/dependencies: Policy formalization into reward functions; false positive/negative trade-offs; third-party audits; regulation updates.
- Sustainable AI deployments through standardized forward-process RL recipes
- Sector: cloud providers, sustainability initiatives
- Use case: Institutionalize forward-process RL as a green alternative to reverse-process GRPO for diffusion; define energy/carbon accounting baselines and reporting.
- Potential products/workflows: Green training SLAs; energy-aware scheduler integrating solver choice and step budgets; shared benchmarking standards.
- Assumptions/dependencies: Consensus on measurement protocols; broad adoption across vendors; verification of efficiency gains at larger scales.
- Personalized, on-device alignment using local preference signals
- Sector: consumer devices, AR/VR
- Use case: Adapt models to personal aesthetic, cultural, or accessibility needs via lightweight online RL (LoRA) and local reward proxies.
- Potential products/workflows: Edge alignment kits; privacy-preserving preference learning; on-device ODE sampling with dynamic β tuning.
- Assumptions/dependencies: Efficient on-device fine-tuning; privacy/security of preference data; stability with small batch sizes.
- Dynamic multi-objective orchestration with reward arbitration
- Sector: enterprise generative platforms
- Use case: Real-time trade-offs among aesthetics, factuality, safety, and text fidelity; adaptive β scheduling; reward weighting policies that reflect business goals.
- Potential products/workflows: Reward routers; arbitration policies (Pareto/frontier tracking); “alignment SRE” roles monitoring reward balance and drift.
- Assumptions/dependencies: Transparent reward aggregation; conflict-resolution strategies; monitoring to prevent mode collapse.
- Healthcare and scientific imaging augmentation with domain-specific rewards
- Sector: healthcare, scientific research
- Use case: Generate synthetic medical/scientific images aligned to protocol constraints (e.g., lesion visibility, modality characteristics) to aid training or hypothesis generation.
- Potential products/workflows: Domain reward curation with expert input; bias/fidelity audits; controlled trials comparing diagnostic utility.
- Assumptions/dependencies: Clinical validation; regulatory approval; careful management of synthetic data biases and traceability.
- Safety-critical simulation content generation (e.g., autonomous driving)
- Sector: automotive, robotics
- Use case: Produce richly constrained synthetic scenes for simulators, aligning with rare/edge-case distributions via reward shaping.
- Potential products/workflows: Scenario grammars mapped to rule-based rewards; simulator bridges; continuous alignment with incident-derived objectives.
- Assumptions/dependencies: Validated correlation between reward-optimized visuals and downstream model robustness; rigorous safety validation.
- Open reward model ecosystems and standards
- Sector: open-source, consortia
- Use case: Community-driven libraries of reward models (quality, alignment, safety, bias) with standardized interfaces and calibration tools for diffusion RL.
- Potential products/workflows: Reward model registries; evaluation leaderboards; documentation of known failure modes and bias probes.
- Assumptions/dependencies: Governance and quality control; licensing; diverse representation in reward curation.
- Theoretical unification of supervised and reinforcement learning for generative modeling
- Sector: academia
- Use case: Formalize negative-aware fine-tuning and implicit parameterization as a general policy improvement operator across modalities; develop new efficiency bounds and stability criteria.
- Potential products/workflows: Algorithmic toolkits extending NFT beyond vision; benchmark suites testing forward consistency and off-policy performance.
- Assumptions/dependencies: Continued theoretical progress; generalized proofs under varied schedules/solvers; robust cross-domain validation.
In all cases, feasibility hinges on the quality, coverage, and calibration of reward models; stable hyperparameter schedules (β, EMA); sampler choice (ODE generally preferred); ethical use (bias/safety auditing); and careful monitoring to avoid reward hacking or collapse.
Glossary
- Adaptive Loss Weighting: A training strategy that adjusts the loss weight over diffusion time to stabilize or emphasize certain timesteps. "Adaptive Loss Weighting. Typical diffusion loss includes a time-dependent weighting w(t) (Eq.~\eqref{eq:diffusion_loss})."
- Black-box solvers: Sampling or integration methods treated as opaque procedures without needing internal gradients or structure. "First, DiffusionNFT allows data collection with arbitrary black-box solvers, rather than just first-order SDE samplers."
- Classifier-Free Guidance (CFG): An inference-time method that improves conditional generation by combining conditional and unconditional predictions. "Recent works discretize the reverse sampling process to enable GRPO-style training, yet they inherit fundamental drawbacks, including solver restrictions, forwardâreverse inconsistency, and complicated integration with classifier-free guidance (CFG)."
- DDIM: Denoising Diffusion Implicit Models; a non-stochastic sampling method for diffusion models derived from an ODE formulation. "This formulation is known as flow matching~\citep{lipman2022flow}, where simple Euler discretization serves as an effective ODE solver, equivalent to DDIM~\citep{song2020denoising}."
- Diffusion Negative-aware FineTuning (DiffusionNFT): An online RL approach for diffusion models that contrasts positive and negative samples on the forward process via flow matching. "We propose a new online RL paradigm: Diffusion Negative-aware FineTuning (DiffusionNFT)."
- Direct Preference Optimization (DPO): A preference-learning method that optimizes models from pairwise comparisons without explicit reward models. "Diffusion-DPO~\citep{wallace2024diffusion,yang2024using,liang2024step,yuan2024self, li2025divergence} adapts DPO to diffusion for paired human preference data but requires additional likelihood and loss approximations compared to AR."
- Energy guidance: A sampling-time guidance approach that uses an energy (score) function to steer diffusion generation. "Policy Guidance. This includes energy guidance \citep{diffuser, cep} and CFG-style guidance \citep{frans2025diffusion, jin2025inference}."
- Euler discretization: A first-order numerical method to integrate ODEs during reverse diffusion sampling. "This formulation is known as flow matching~\citep{lipman2022flow}, where simple Euler discretization serves as an effective ODE solver, equivalent to DDIM~\citep{song2020denoising}."
- Exponential Moving Average (EMA): A smoothing update rule that blends parameters over time for stability. "Instead, we leverage this property to employ a ``soft" EMA update:"
- Flow matching: Training via matching a model’s velocity field to the target data transport field along the diffusion time. "This formulation is known as flow matching~\citep{lipman2022flow}"
- Flow models: Generative models formulated as deterministic flows (ODEs) transporting noise to data. "While flow models naturally admit simple and efficient sampling through ODE, the lack of stochasticity hinders the application of GRPO."
- FlowGRPO: A GRPO-based RL method adapted for flow/diffusion models using an SDE formulation to reintroduce stochasticity. "FlowGRPO~\citep{liu2025flow} addresses this by using the SDE form~\citep{song2020score} under the velocity parameterization (see Appendix~\ref{appendix:flowsde}):"
- Fokker–Planck equation: A PDE describing the time evolution of probability densities under stochastic processes. "This preserves what we term forward consistencyâthe adherence of the diffusion model's underlying probability density to the Fokker-Planck equation \citep{oksendal2003stochastic,song2020score}"
- Forward consistency: Ensuring the learned model’s density evolution matches the forward diffusion process (not just reverse-time sampling). "This preserves what we term forward consistencyâthe adherence of the diffusion model's underlying probability density to the Fokker-Planck equation"
- GRPO: Group Relative Policy Optimization; a policy-gradient-style RL algorithm variant used for post-training. "This makes transitions between adjacent steps tractable Gaussians, enabling direct application of existing RL algorithms like GRPO to the diffusion domain~\citep{xue2025dancegrpo, liu2025flow}."
- Guidance strength: A scalar that scales the added guidance direction applied to the base policy’s velocity. "We term reinforcement guidance, and guidance strength."
- Guidance-free training: Training the model to internalize guidance so no external guidance is needed at inference. "This technique, inspired by recent advances in guidance-free training \citep{gft}, allows us to perform RL continuously on a single policy model, which is crucial to online reinforcement."
- Implicit parameterization: A technique where target positive/negative policies are defined as linear functions of the old and current models, avoiding training separate models. "it adopts an implicit parameterization technique that allows integrating reinforcement guidance directly into the optimized policy."
- Importance sampling: A weighting method for off-policy corrections; here explicitly avoided. "Finally, it is a native off-policy algorithm, naturally allowing decoupled training and sampling policies without importance sampling."
- Jensen's inequality: A convexity inequality used here to derive tractable bounds for likelihood-related objectives. "Whether approximating the marginal data likelihood with variational bounds and applying Jensen's inequality to reduce loss computation cost~\citep{wallace2024diffusion}"
- Likelihood-free: An approach that does not rely on explicit or approximate likelihood computation. "In contrast, DiffusionNFT is inherently likelihood-free, bypassing such compromises."
- LoRA: Low-Rank Adaptation; a parameter-efficient finetuning method adding low-rank adapters to large models. "We finetune with LoRA (, )."
- Marginal data likelihood: The probability of observed data under a model, marginalized over latent variables; hard to compute in diffusion. "Whether approximating the marginal data likelihood with variational bounds and applying Jensen's inequality to reduce loss computation cost"
- Markov Decision Process (MDP): A formalism defining states, actions, transitions, and rewards for sequential decision-making. "recent works~\citep{black2023training,fan2023dpok, liu2025flow,xue2025dancegrpo} formulate the diffusion sampling as a multi-step Markov Decision Process (MDP)."
- Off-policy: RL training where the behavior (data-collecting) policy differs from the optimized policy. "Finally, it is a native off-policy algorithm, naturally allowing decoupled training and sampling policies without importance sampling."
- On-policy: RL training where data is collected from the current policy being optimized. "Fully on-policy () accelerates early progress but destabilizes training"
- Ordinary Differential Equation (ODE): A deterministic time-evolution equation used to model reverse diffusion flows. "Reverse sampling typically follows the ODE form~\citep{song2020score} of the diffusion model"
- Policy Gradient: A family of RL methods that optimize policies by ascending gradients of expected returns. "Policy Gradient algorithms assume that model likelihoods are exactly computable."
- Proximal Policy Optimization (PPO): A popular policy-gradient RL algorithm using clipped objectives for stability. "In order to apply Policy Gradient algorithms such as PPO \citep{schulman2017proximal} or GRPO \citep{shao2024deepseekmath} to diffusion models"
- Rectified flow: A specific flow schedule with linear paths simplifying the velocity target. "Rectified flow~\citep{liu2022flow} can be considered as a simplified special case of the above-discussed diffusion models, where "
- Rejection FineTuning (RFT): Training only on high-reward (positive) samples by rejecting low-reward ones. "previous work \citep{lee2023aligning} performs diffusion training solely on , known as Rejection FineTuning (RFT)."
- Reparameterization: Expressing a random variable as a deterministic function of parameters and noise for tractable gradients or sampling. "enabling reparameterization as \begin{equation*} _t=\alpha_t_0+\sigma_t,\sim(\bm 0,). \end{equation*}"
- Reward-Weighted Regression (RWR): An offline RL method that fits a policy to data weighted by rewards. "Reward-Weighted Regression (RWR)~\citep{lee2023aligning} is an offline finetuning method but lacks a negative policy objective to penalize low-reward generations."
- Score-based RL: Approaches that optimize directly over the score (gradient of log-density) rather than likelihoods. "Score-based RL. These methods try to perform RL directly on the score rather than the likelihood field \citep{zhu2025dspo}."
- Soft Update: Gradual parameter update of a target/behavior policy toward the online policy for stability. "Soft Update of Sampling Policy."
- Stochastic Differential Equation (SDE): A stochastic time-evolution equation modeling noisy diffusion dynamics. "FlowGRPO~\citep{liu2025flow} addresses this by using the SDE form~\citep{song2020score}"
- Stop-gradient operator: An operation that prevents gradients from flowing through a term during backpropagation. "where sg is the stop-gradient operator."
- Transition kernel: The conditional distribution specifying how states evolve over diffusion time. "The forward noising process admits a closed-form transition kernel $\pi_{t|0}(_t|_0)=(\alpha_t_0,\sigma_t^2)$"
- Variational bounds: Lower bounds (e.g., ELBO) used to approximate intractable likelihoods. "Whether approximating the marginal data likelihood with variational bounds and applying Jensen's inequality to reduce loss computation cost"
- Velocity parameterization: Modeling diffusion dynamics by predicting velocity (the tangent of the transport trajectory) instead of noise or data directly. "One way to learn diffusion models is to adopt the velocity parameterization ~\citep{zheng2023improved}, which predicts the tangent of the trajectory"
Collections
Sign up for free to add this paper to one or more collections.