- The paper introduces EvoTest, a two-agent architecture that evolves policies, memory, hyperparameters, and tool-use routines from transcript analysis.
- The method achieves up to 57% performance improvement over online RL by using a gradient-free, data-efficient evolutionary approach.
- Experimental results on Jericho games demonstrate stable, superior AUC scores enabled by UCB selection and prompt evolution mechanisms.
EvoTest: Evolutionary Test-Time Learning for Self-Improving Agentic Systems
Introduction and Motivation
The EvoTest framework addresses a critical limitation in current agentic AI systems: the inability to perform rapid, holistic learning at test time in novel environments. Most deployed agents operate with static policies, lacking mechanisms for in-session adaptation. This restricts their reliability and utility in dynamic, complex tasks, especially those with sparse reward signals and combinatorial action spaces. To systematically evaluate and drive progress in this area, the authors introduce the Jericho Test-Time Learning (J-TTL) benchmark, which requires agents to play the same text-based adventure game over multiple episodes, aiming to improve performance solely from experience within a single session.
The J-TTL Benchmark
J-TTL is built on the Jericho suite of Interactive Fiction (IF) games, modeling each as a POMDP with a combinatorial natural language action space. The benchmark protocol enforces identical initial states across episodes, ensuring that any improvement is attributable to the agent's internal learning algorithm. Performance is measured via per-episode returns and normalized Area Under the Curve (AUC) scores, facilitating cross-game comparison.
The EvoTest Framework
EvoTest introduces a two-agent architecture: the Actor Agent executes episodes using a fixed configuration, while the Evolver Agent analyzes the full trajectory transcript post-episode to propose a revised agentic configuration. This configuration encompasses:
- Policy Prompt: High-level strategic guidance for the backbone LLM.
- Deployment-Time Memory: Structured, queryable databases of successful and failed state-action pairs.
- Hyperparameters: Controls for inference and decision-making (e.g., temperature, exploration strength).
- Tool-Use Routines: Python functions for state abstraction and memory interaction logic.
The evolution process is gradient-free, relying on semantic analysis of the episode transcript rather than scalar rewards. The Evolver applies evolutionary operators—prompt mutation, memory update, hyperparameter tuning, and tool-use refinement—to generate candidate child configurations. Selection for the next episode is performed via the Upper Confidence Bound (UCB) algorithm, balancing exploitation of proven configurations and exploration of novel mutations.
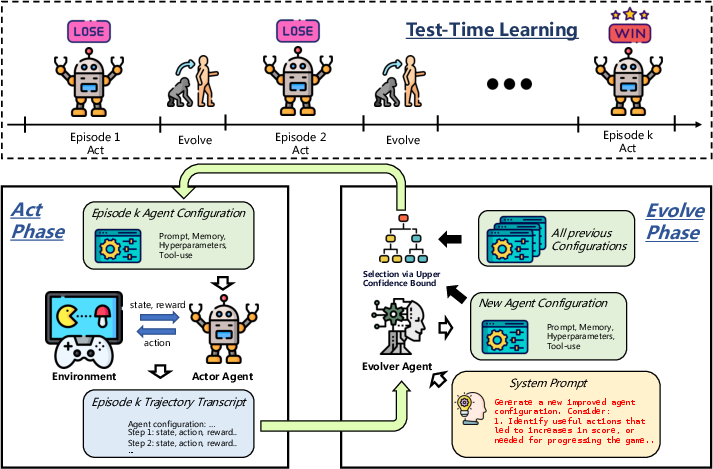
Figure 1: The EvoTest architecture, illustrating the Act-Evolve loop and whole-system evolution via transcript-level analysis.
Experimental Results
EvoTest is evaluated against a comprehensive suite of baselines: static agents, memory-based methods (Memory, RAG), reflection-based methods (Summary, Reflexion), automated prompt optimization (TextGrad, Promptbreeder, EvoPrompt), and weight-update methods (SFT, GRPO). Experiments span six Jericho games and multiple backbone LLMs.
Key findings:
- Test-Time Learning Efficacy: All learning-based methods outperform the static baseline, with upward-trending learning curves across episodes.
- EvoTest Superiority: EvoTest achieves the highest AUC scores on all games and backbones, with an average improvement of 38% over the strongest prompt-evolution baseline and 57% over online RL.
- Data Efficiency: EvoTest's gradient-free, transcript-driven evolution is substantially more data-efficient than gradient-based RL, which struggles with sparse rewards and requires expensive hardware.
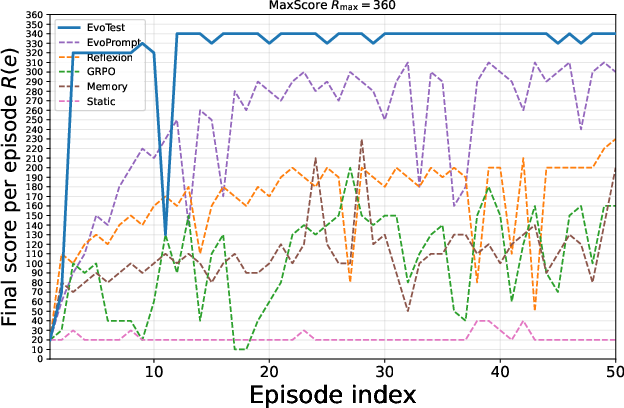
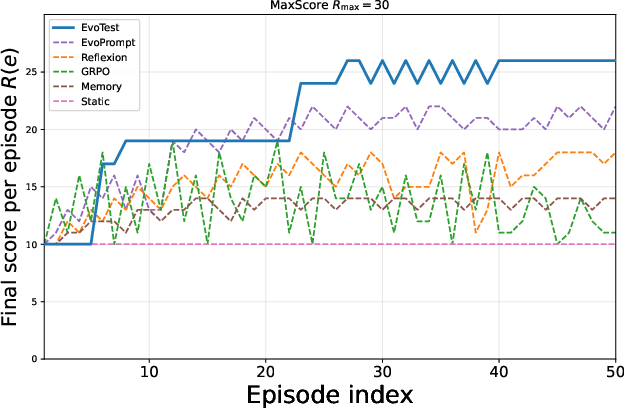
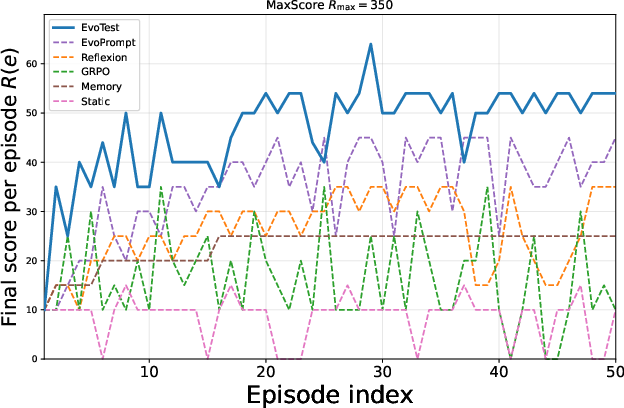
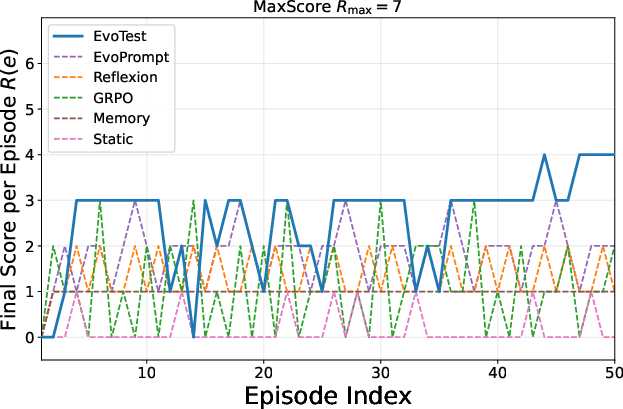
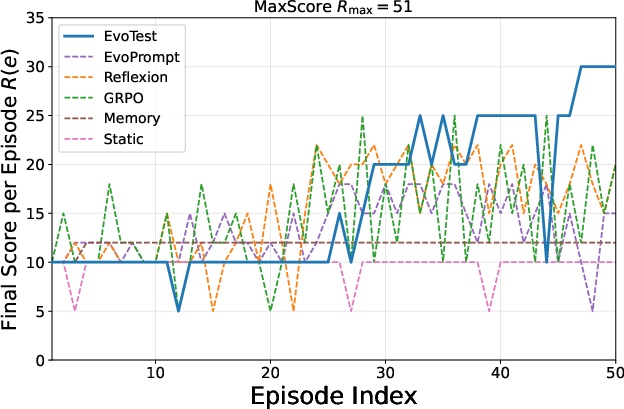
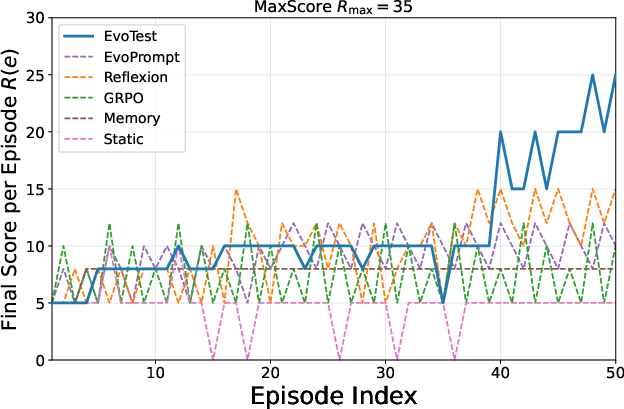
Figure 2: Learning curves for the Detective game, demonstrating EvoTest's steeper and more stable improvement compared to baselines.
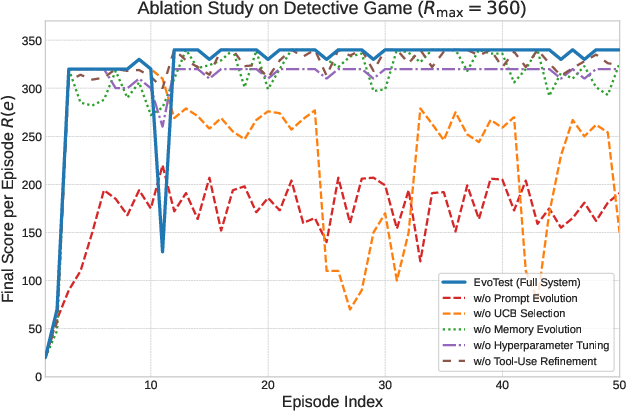
Figure 3: Practical costs for a single learning update and ablation study learning curves, highlighting EvoTest's efficiency and the impact of key components.
Model Analysis and Ablations
Ablation studies reveal that prompt evolution is the primary driver of strategic adaptation, with significant performance drops when removed. UCB selection is critical for stability, preventing catastrophic failures from over-committing to high-risk mutations. Memory and hyperparameter components provide incremental gains, while tool-use routines enhance situational awareness and efficient knowledge operationalization.
Efficiency analysis shows that EvoTest's update step (20–30 seconds via a single LLM API call) is orders of magnitude faster and less resource-intensive than online RL (5–10 minutes on 4 H100 GPUs). The framework is robust to the quality of the Evolver LLM, with performance scaling with model capability but remaining above baseline even with smaller models.
Mechanisms of Whole-System Evolution
EvoTest's memory component is a structured database, programmatically populated with state-action pairs leading to score increases (success memory) and patterns of unproductive actions (failure memory). The Evolver Agent performs semantic credit assignment, identifying causal chains of success and failure, and encodes both positive heuristics and negative guardrails in the evolving policy prompt. This enables the agent to abstract reusable skills and prune the search space, achieving rapid convergence to near-optimal strategies.
Comparative Computational Complexity
EvoTest trades the hardware-intensive backpropagation of online RL for an additional LLM forward pass, making it scalable via API calls and obviating the need for specialized local hardware. The learning cost per cycle is dominated by LLM inference, while RL requires full forward and backward passes through long trajectories, scaling with model size and episode length.
Implications and Future Directions
EvoTest demonstrates that whole-system, gradient-free evolution driven by rich narrative feedback is a viable and superior paradigm for test-time learning in agentic systems. The approach generalizes prompt evolution to encompass memory, hyperparameters, and tool-use routines, enabling multi-faceted adaptation beyond the scope of single-channel methods. This has significant implications for the design of autonomous agents capable of rapid, in-session self-improvement in complex, dynamic environments.
Future research may explore:
- Extension to multi-agent and real-world domains with richer interaction modalities.
- Integration of human-in-the-loop guidance for more nuanced credit assignment.
- Automated discovery of meta-abilities and alignment strategies beyond task-specific adaptation.
- Scaling evolutionary mechanisms to larger populations and more diverse configuration spaces.
Conclusion
EvoTest provides a concrete framework for evolutionary test-time learning, enabling agentic systems to self-improve from experience without fine-tuning or gradients. By leveraging transcript-level analysis and whole-system evolution, it achieves superior data efficiency and performance compared to reflection, memory, prompt optimization, and online RL baselines. This work advances the development of truly autonomous agents capable of learning and adapting in situ, with broad implications for the future of AI agent design and deployment.

