DeepCode: Open Agentic Coding
Abstract: Recent advances in LLMs have given rise to powerful coding agents, making it possible for code assistants to evolve into code engineers. However, existing methods still face significant challenges in achieving high-fidelity document-to-codebase synthesis--such as scientific papers to code--primarily due to a fundamental conflict between information overload and the context bottlenecks of LLMs. In this work, we introduce DeepCode, a fully autonomous framework that fundamentally addresses this challenge through principled information-flow management. By treating repository synthesis as a channel optimization problem, DeepCode seamlessly orchestrates four information operations to maximize task-relevant signals under finite context budgets: source compression via blueprint distillation, structured indexing using stateful code memory, conditional knowledge injection via retrieval-augmented generation, and closed-loop error correction. Extensive evaluations on the PaperBench benchmark demonstrate that DeepCode achieves state-of-the-art performance, decisively outperforming leading commercial agents such as Cursor and Claude Code, and crucially, surpassing PhD-level human experts from top institutes on key reproduction metrics. By systematically transforming paper specifications into production-grade implementations comparable to human expert quality, this work establishes new foundations for autonomous scientific reproduction that can accelerate research evaluation and discovery.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “DeepCode: Open Agentic Coding” in Simple Terms
Overview: What is this paper about?
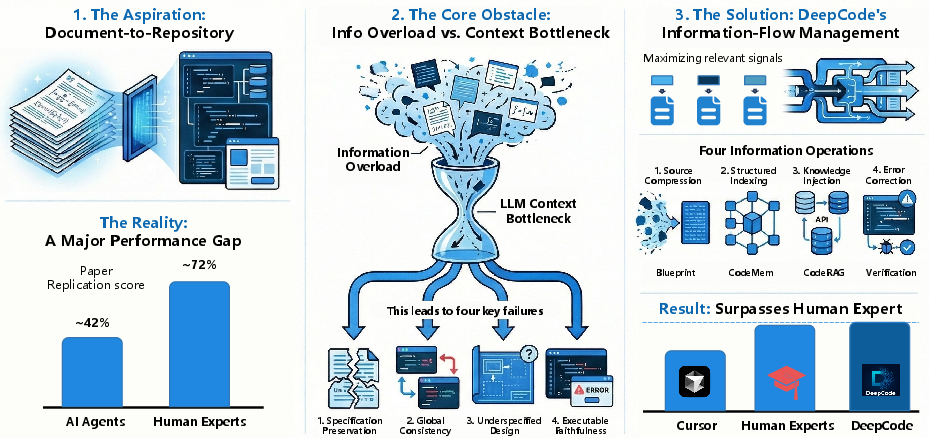
This paper introduces DeepCode, an AI system that can read a scientific paper and automatically write a full, working code project that follows the paper’s instructions. Instead of being just a helpful autocomplete tool, DeepCode acts more like a “junior engineer” that plans, builds, and checks the code on its own. The big idea is to carefully manage information so the AI doesn’t get overwhelmed while turning long, complicated documents into correct software.
Goals: What questions does the paper try to answer?
The paper focuses on a few easy-to-understand goals:
- Can an AI turn a long scientific paper into a complete, runnable code repository?
- How can we handle the “too much information” problem when AI has limited memory?
- Is DeepCode better than other AI coding tools and even human experts at this task?
- Which parts of DeepCode are most important for getting good results?
Methods: How does DeepCode work?
Think of building a big LEGO set from a long instruction booklet. If the booklet is messy and huge, you need a smart plan to find the right steps fast and avoid mistakes. DeepCode follows three main phases to do that:
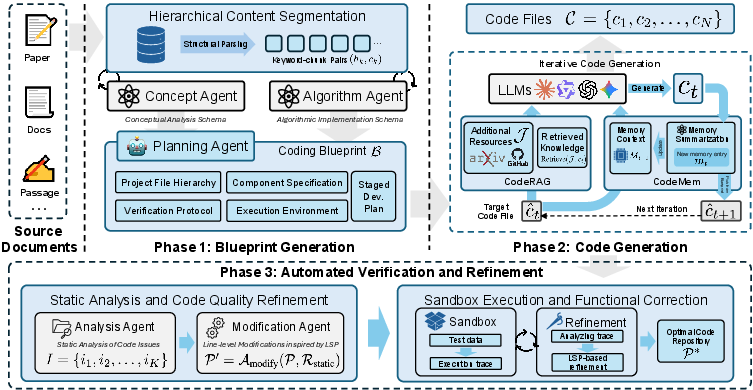
Phase 1: Blueprint Generation (Planning)
Instead of feeding the entire paper to the AI at once (which can overload it), DeepCode first breaks the paper into sections like “Introduction,” “Method,” “Experiments,” and so on. It uses two helper “agents”:
- A Concept Agent that maps the big picture: what the paper is about, the main components, and what success looks like.
- An Algorithm Agent that pulls exact technical details: equations, pseudocode, hyperparameters (the settings for models), and training steps.
These are combined into a clear “implementation blueprint” — a step-by-step plan for the codebase, including:
- What files and folders to create
- What each part (class, function) should do
- What environment and dependencies are needed
- How to test if the implementation is correct
Phase 2: Code Generation (Building with memory and references)
DeepCode then writes the code file by file, but it doesn’t keep dumping all previous code back into the prompt. Instead, it uses two key ideas:
- CodeMem (code memory): Like keeping organized index cards for every file. Each card explains:
- What the file does
- What functions/classes it provides
- What other files it depends on
- Which parts may need to be built next
- This lets DeepCode stay consistent across files without stuffing its short-term memory with tons of text.
- CodeRAG (retrieval-augmented generation): Like looking up examples in a library when needed. If a part of the code is tricky or underspecified, DeepCode searches relevant, high-quality codebases and pulls helpful patterns or snippets. It only does this when needed, to avoid distractions or copying unnecessary stuff.
Phase 3: Automated Verification (Checking and fixing)
Finally, DeepCode tests and fixes its work in two steps:
- Static analysis: Checks structure, quality, and whether the code matches the blueprint. It can make precise edits (like a smart code editor) to improve style or fix missing pieces.
- Sandbox execution: Runs the code in a safe, controlled environment. If it crashes or has errors, DeepCode reads the error messages, figures out what’s wrong, and patches the code. It repeats this until it works or hits a limit.
This closed loop — plan, build, check, fix — helps turn a long paper into a working, faithful implementation.
Results: What did they find, and why does it matter?
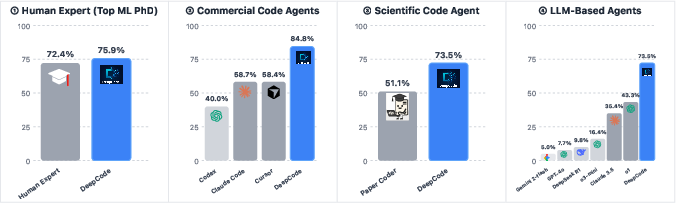
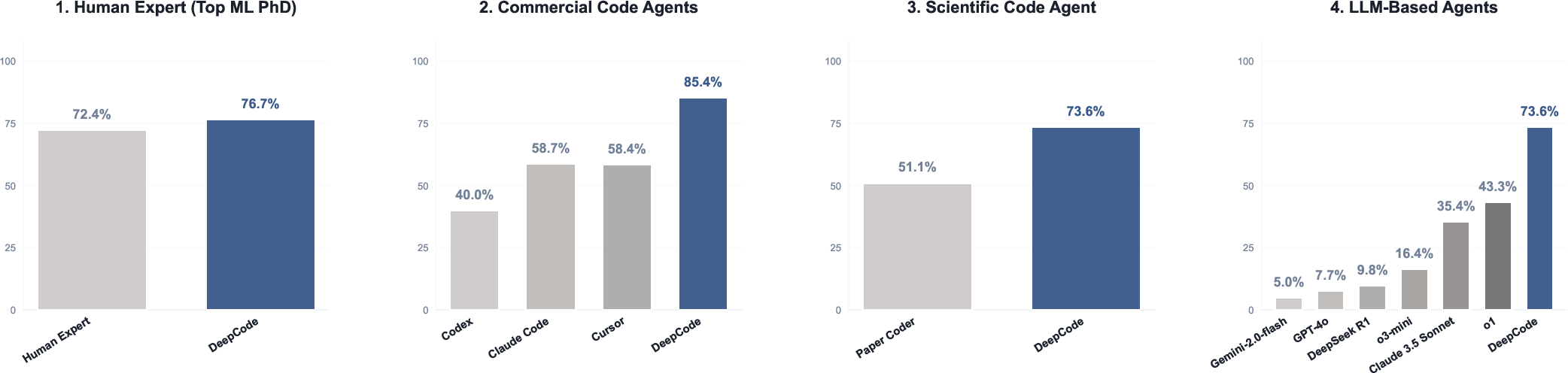
The team tested DeepCode on PaperBench, a benchmark where AI models try to reproduce machine learning papers as code, completely from scratch. Here’s what happened:
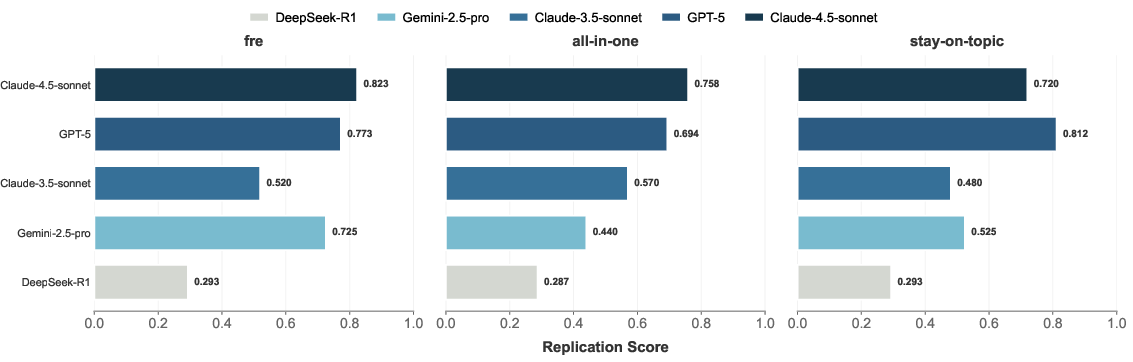
- DeepCode achieved a replication score around 73.5, much higher than the best general-purpose AI agent (about 43.3) and a specialized scientific code agent called PaperCoder (about 51.1).
- On a smaller subset, DeepCode beat popular commercial tools like Cursor, Claude Code, and Codex.
- On key metrics, DeepCode even surpassed PhD-level human experts.
Why this matters:
- It shows that organizing and routing information well (not just using bigger models) makes a huge difference.
- It proves that AI can move beyond “code autocomplete” to “autonomous coding,” handling complex, multi-file projects.
Implications: What could this change in the future?
If AI systems like DeepCode can reliably turn research papers into working code:
- Scientific results can be reproduced more quickly and fairly, speeding up discovery.
- Researchers can spend less time re-implementing existing work and more time inventing new ideas.
- Software building could shift from “writing code line by line” to “writing clear specifications and letting AI build from them.”
- Careful testing and verification will remain essential, and transparency about sources and methods will be important to avoid misuse or errors.
In short, DeepCode suggests a future where AI acts more like a careful, organized engineer — one that reads complex instructions, plans smartly, builds consistently, and checks its own work — helping accelerate science and software development.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
- Lack of precise formalization and measurement of the “information-theoretic” framing: no concrete definitions of channel capacity, compression objectives, or quantitative SNR metrics; no experiments that quantify how blueprint compression or memory indexing changes information density or effective capacity.
- Unspecified algorithms for memory selection and summarization: the functions SelectRelevantMemory and the summarization agent S are not concretely defined (e.g., embedding models, similarity metrics, prompt templates), making reproducibility and optimization unclear.
- No analysis of memory error propagation and recovery: how CodeMem handles stale, inconsistent, or incorrect summaries, and how corrections propagate to restore global consistency, is not described or evaluated.
- Ambiguity in the decision policy δ for CodeRAG: the retrieval trigger, confidence calibration, and thresholds are not specified (heuristic vs. learned), nor is the effect of this policy ablated.
- Risk of code contamination and licensing issues in CodeRAG: although author repos are blacklisted, the framework may still retrieve near-duplicate third‑party implementations; there is no policy for license compliance, attribution, or plagiarism detection.
- Limited evaluation scope: the study focuses on PaperBench (ML-paper-to-code) and does not evaluate the second task (multi-component software system generation with UI/backend/DB), leaving generalization to broader software engineering untested.
- No evaluation of multi-language support: experiments appear centered on Python/ML; performance on other ecosystems (e.g., C++, Java, TypeScript, Rust) and cross-language repositories is not assessed.
- Missing multimodal extraction details: how equations, figures, tables, and pseudocode are parsed from PDFs (OCR, math parsing, diagram understanding) is unspecified, and there is no evaluation of robustness to complex or noisy document layouts.
- Faithfulness measured only by static rubric scores: the evaluation excludes post-submission experimental reproduction (e.g., matching reported metrics), leaving scientific fidelity and results replication unverified.
- Reliance on o3‑mini as an automated judge introduces potential bias: no cross‑validation with human assessment or alternate graders, nor analysis of judge sensitivity/robustness to superficial code features.
- Incomplete reporting on resource parity and fairness: runtime budgets, hardware/software parity, and internet/tooling access are not rigorously matched across baselines (e.g., OS versions, agent capabilities), risking confounds.
- Unclear underlying LLM and settings for DeepCode: the core model(s), reasoning modes, temperature, system prompts, and tool-usage parameters are not fully disclosed, impeding reproducibility and comparability.
- Cost and efficiency not reported: compute time per paper, wall-clock breakdown by phase, API/token costs, and retrieval/indexing overhead are not quantified; efficiency trade-offs versus baseline agents remain unknown.
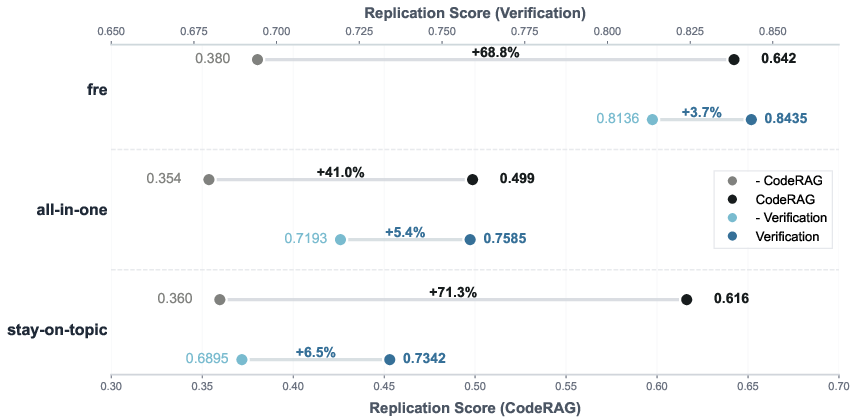
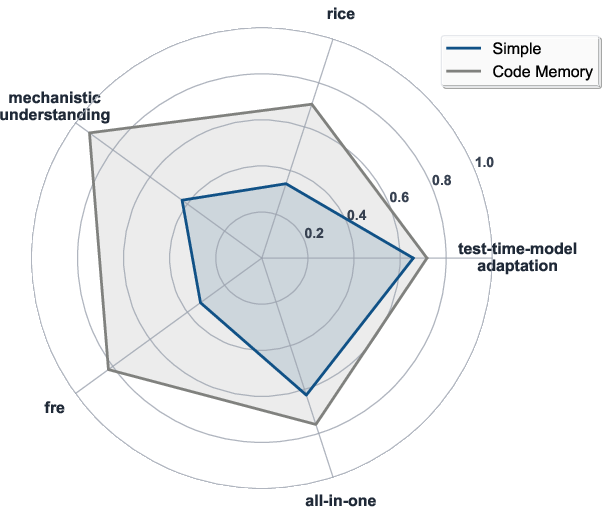
- Missing ablations for RQ2 and RQ3 in the provided text: the effects of different LLMs and module contributions (Blueprint, CodeMem, CodeRAG, Verification) are not documented here; no per-module drop-in/out or sensitivity studies.
- No failure mode analysis: lacks qualitative error taxonomy (e.g., interface misalignment, hyperparameter drift, dependency conflicts) and quantitative breakdowns by phase, making it hard to target improvements.
- Weak guarantees on executability coverage: auto-generated tests are used, but their coverage, adequacy criteria, and failure-detection power are not specified; logic errors may evade detection if they pass static checks.
- Unclear handling of underspecified or contradictory papers: the system’s strategy for disambiguation (e.g., preference rules, uncertainty propagation, user queries) and its impact on final outputs are not studied.
- Security and safety risks of agentic execution are not addressed: dependency supply-chain risks, command execution safeguards, network access policies, and sandbox hardening are unspecified.
- No robustness study of CodeRAG retrieval noise: the system’s behavior under irrelevant, low-quality, or conflicting retrieved snippets is untested, and there is no mechanism described for retrieval debiasing or filtering.
- Scalability to large repositories is unquantified: memory growth, index size, retrieval latency, and context load as the number of files increases are not measured; no complexity analysis or scaling limits are presented.
- Absence of comparisons to alternative long-context strategies: claims that information-flow management beats scaling context length are not supported by controlled experiments against strong long-context baselines.
- Generalization to non-ML document genres is untested: performance on standards, RFCs, design docs, or API specs remains an open question, especially where the “paper” structure differs substantially.
- No evaluation of maintainability and software quality beyond rubric: metrics like cyclomatic complexity, modularity, test coverage, documentation completeness, and code smells are not reported.
- Version control and iterative development workflows are not integrated or studied: no experiments on incremental updates, refactoring, or handling evolving specs (e.g., paper revisions).
- Determinism and stability across runs are only partially addressed: while three trials are averaged, variability under different temperatures/seeds, and reproducibility with fixed seeds, are not fully characterized.
- Potential domain leakage through web search remains a threat to validity: safeguards beyond blacklisting the authors’ repo are not detailed; similar code from forks or re-implementations may still bias results.
- Unclear impact of coarse-to-fine planning choices: the staged development plan’s scheduling decisions, their optimization criteria, and their effect on success rate are not quantified.
- Lack of theoretical guarantees: despite the information-theoretic framing, there are no bounds or guarantees on correctness, convergence of the verification loop, or conditions under which the framework succeeds/fails.
- Ethical considerations are not discussed: effects on research attribution, potential misuse (e.g., mass code generation without credit), and compliance with licenses and community norms remain unresolved.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that leverage DeepCode’s blueprint distillation, stateful code memory (CodeMem), retrieval-augmented generation (CodeRAG), and closed-loop verification (static analysis + sandbox execution). Each application lists sectors, potential tools/products/workflows, and key dependencies or assumptions.
- Paper-to-code reproduction service for research labs and journals
- Sectors: academia, scientific publishing
- Tools/workflows: “PDF/Markdown → Implementation Blueprint → Repository synthesis → Static+Dynamic verification → reproduce.sh + README”
- Dependencies/assumptions: Access to high-quality LLMs; clear reproduction rubrics; compute for sandbox runs; permission to reproduce/redistribute artifacts
- Spec-to-repo prototyping for software teams
- Sectors: software, product engineering
- Tools/workflows: Intake design docs (PRDs, architecture notes) → Blueprint → Code generation with CodeMem for cross-file consistency → CI sandbox run → PR opening
- Dependencies/assumptions: Structured design inputs; integration with VCS/CI; organizational code standards; model access
- CI “autofix runner” for static/dynamic code quality
- Sectors: DevOps, software tooling
- Tools/products: LSP-inspired agent that applies targeted patches from static analysis reports and sandbox error traces; pipeline step in CI/CD
- Dependencies/assumptions: Repository access, permissioned automated edits, safe rollback, test harness availability
- Documentation-driven development (DDD) with automatic blueprints
- Sectors: software, education
- Tools/workflows: Blueprint generator produces architecture maps, component specs, environment config, verification protocol; synchronized docs/code via CodeMem summaries
- Dependencies/assumptions: Source docs or specs; organizational buy-in for blueprint artifacts as “source of truth”
- Codebase onboarding and refactoring assistant
- Sectors: enterprise software
- Tools/workflows: CodeMem acts as a compressed global index of interfaces/dependencies; aids newcomers, refactor planning, and interface consistency checks
- Dependencies/assumptions: Read permission to repos; consistent language servers; adequate summarization fidelity
- Enterprise code pattern grounding via CodeRAG
- Sectors: software (internal platforms)
- Tools/workflows: Index internal libraries/components; map relationship tuples to target modules; reuse proven implementation patterns in new services
- Dependencies/assumptions: Legal/IP clearance; private repo indexing; governance on snippet reuse
- Environment provisioning and reproducible pipeline generation
- Sectors: DevOps, data science
- Tools/workflows: Sandbox agent validates environment instructions, resolves dependencies, and emits reproduce.sh/test datasets
- Dependencies/assumptions: Deterministic environment setup; access to required packages/hardware; dependency mirrors
- Open-source maintenance bot (issue triage and targeted PRs)
- Sectors: open-source ecosystems
- Tools/workflows: Read issues/design discussions → Blueprint deltas → Targeted edits via LSP patches → CI verification
- Dependencies/assumptions: Maintainer guidelines; contributor license agreement (CLA); project governance
- Security-oriented structural triage (non-exploit-focused)
- Sectors: security, reliability engineering
- Tools/workflows: Static analysis flags structural/dependency anomalies; sandbox traces expose runtime misconfigurations; agent proposes hardening patches
- Dependencies/assumptions: Not a full vulnerability scanner; requires test inputs; careful handling of production secrets and infra
- Data-science workflow synthesis from experiment descriptions
- Sectors: finance analytics, healthcare analytics, research ops
- Tools/workflows: Transform methodological text into pipeline repos (ETL/feature engineering/model training/evaluation), with verification scripts
- Dependencies/assumptions: Access to data schemas; domain libraries; privacy/compliance constraints
Long-Term Applications
These use cases require further research, scaling, validation, or productization—especially around safety, governance, and domain-specific compliance.
- Autonomous software engineer for end-to-end product development
- Sectors: software, platform engineering
- Tools/products: Agentic IDE with native Blueprint/CodeMem/CodeRAG/Verifier; spec-to-production orchestrator
- Dependencies/assumptions: Stronger long-horizon reasoning; robust guardrails; human-in-the-loop governance; liability frameworks
- National-scale reproducibility infrastructure for science policy
- Sectors: policy, funding agencies, scholarly comms
- Tools/workflows: Standardized blueprint schemas and rubrics; automated replication pipelines; registry of verified artifacts
- Dependencies/assumptions: Legal/publisher permissions; sustained compute funding; community standards; auditability requirements
- Regulated spec-to-software generation in safety-critical domains
- Sectors: healthcare (medical devices), aerospace, automotive, energy
- Tools/products: Verified generation augmented with formal methods, model checking, compliance traceability from standards to code
- Dependencies/assumptions: Certification pathways (e.g., FDA, DO-178C/ISO 26262); formal verification integration; stringent reliability guarantees
- Enterprise SpecOps: business requirement documents to production services
- Sectors: finance, e-commerce, telecom
- Tools/workflows: Requirements → Blueprint → Microservice repos with consistent interfaces (CodeMem) and internal pattern reuse (CodeRAG) → staged verification
- Dependencies/assumptions: Secure access to APIs and internal catalogs; organizational guardrails; change-management processes
- Legacy system modernization via blueprint extraction and guided migration
- Sectors: government IT, banking, manufacturing
- Tools/workflows: Distill legacy docs/code into blueprints and dependency graphs; propose modernization paths; generate target repos
- Dependencies/assumptions: Access to legacy artifacts; compat layers; licensing; phased rollout plans
- AutoR&D platforms: continuous paper reproduction, variant exploration, and benchmarking
- Sectors: academia, industrial research labs
- Tools/workflows: Ingest new publications → reproducible implementations → parameter sweeps/ablation studies → leaderboards
- Dependencies/assumptions: Dataset availability; compute budgets; ethical review for sensitive domains; result provenance
- Next-gen IDEs with native memory/RAG/verifier baked in
- Sectors: developer tools
- Tools/products: IDE extensions that maintain project “state memory,” retrieve internal/external patterns, and auto-verify edits
- Dependencies/assumptions: Vendor support for LSP augmentation; privacy-preserving indexing; seamless developer UX
- Domain code knowledge bases aligned to canonical blueprints
- Sectors: education, open-source, standards bodies
- Tools/workflows: Curated indices mapping reference implementations to typical blueprint components; pedagogical kits
- Dependencies/assumptions: Community curation; licensing compliance; evolving standards
- Automated grant/procurement compliance (RFP/SOW-to-prototype)
- Sectors: government, enterprise procurement
- Tools/workflows: Translate requirements into testable prototypes and verification protocols; traceability from spec to code
- Dependencies/assumptions: Handling of confidential materials; audit trails; contractual/legal oversight
- Continuous scientific replication networks and marketplaces
- Sectors: academia, open science platforms
- Tools/workflows: Distributed pipelines that replicate, verify, and archive artifacts for new papers; incentive mechanisms for contributors
- Dependencies/assumptions: Publisher APIs; storage/compute funding; credit/citation mechanisms; governance models
Notes on Feasibility Across Applications
- Model capabilities: Reliability depends on access to high-quality LLMs with sufficient context and reasoning. Gains here do not substitute for guardrails and verification.
- Data/IP governance: CodeRAG benefits from curated repositories; IP compliance and licensing policies are critical.
- Integration: Real-world utility improves with tight hooks into VCS, CI/CD, package registries, secret management, and observability.
- Safety and assurance: Safety-critical deployments require formal methods, certification workflows, and rigorous human oversight.
- Compute and cost: Sandbox verification, indexing, and multiple replication trials incur compute costs; budgets and scheduling must be managed.
- Organizational adoption: Success hinges on process changes—treating the blueprint as a canonical artifact and integrating agents into development lifecycles.
Glossary
- Adaptive Retrieval: A dynamic decision process to fetch external knowledge during code generation when needed. "Adaptive Retrieval."
- afferent couplings: Incoming dependencies a module has on other internal components. "afferent couplings (internal dependencies)"
- agentic coding: A paradigm where AI agents autonomously plan and implement software projects from specifications. "an open agentic coding framework"
- agentic software engineering: The approach of using LLM-based agents to plan and build entire software projects from high-level specs. "what we term agentic software engineering"
- Algorithm Agent: A specialized agent that extracts low-level technical details (algorithms, equations, hyperparameters) from documents. "Algorithm Agent: Low-Level Technical Detail Extraction."
- Automated Verification: The phase that uses structured checks and execution feedback to ensure correctness of the synthesized repository. "Automated Verification"
- Blueprint Generation: The phase that compresses and organizes raw document content into a structured implementation plan. "Blueprint Generation"
- blueprint distillation: The compression of unstructured specifications into a precise, high-signal implementation blueprint. "source compression via blueprint distillation"
- channel optimization problem: Framing repository synthesis as optimizing information flow through constrained contexts. "repository synthesis as a channel optimization problem"
- channel saturation: Overloading the model’s context with redundant tokens, obscuring critical information. "induce channel saturation"
- Code Memory (CodeMem): A stateful, structured memory of the evolving repository used to maintain cross-file consistency without large prompts. "a stateful Code Memory (CodeMem)"
- CodeRAG: A retrieval-augmented generation system that grounds code synthesis in external code repositories. "a CodeRAG system that performs conditional knowledge injection"
- closed-loop error correction: Iteratively fixing issues using feedback from verification or execution results. "closed-loop error correction"
- closed-loop feedback system: A verification mechanism that uses execution outcomes to guide code refinement. "closed-loop feedback system"
- Concept Agent: A specialized agent that maps high-level structure, contributions, and reproduction goals from the source document. "Concept Agent: High-Level Structural and Conceptual Mapping."
- conditional knowledge injection: Injecting external patterns or libraries only when the current context lacks sufficient detail. "conditional knowledge injection"
- context bottlenecks: Limitations imposed by the finite context window of LLMs that restrict how much information can be processed. "context bottlenecks of LLMs"
- context windows: The finite token capacity that bounds the information an LLM can consider at once. "finite context windows"
- dependency graph: A structured representation of how files and modules depend on each other within a project. "dependency graph"
- dependency manifest: A specification of external libraries and resources required to run the codebase. "dependency manifest (e requirements.txt, package.json, README.md file)"
- document-grounded program synthesis: Generating executable code directly from a complex document as the sole specification. "document-grounded program synthesis"
- efferent couplings: Outgoing dependencies from a module to other components that will consume its interface. "predicted efferent couplings (external dependencies)"
- execution trace: The collected outputs and error messages from program runs used for diagnosing and fixing issues. "execution trace"
- Functional Executability: Ensuring the final repository is runnable and robust, not just plausible code. "Functional Executability"
- Global Structural Consistency: Maintaining strict compatibility and coherence across interfaces and types in all modules. "Global Structural Consistency"
- Hierarchical Content Segmentation: Parsing documents into a structured index of sections and subsections for targeted retrieval. "Hierarchical Content Segmentation"
- hierarchical weighting scheme: A rubric design where sub-tasks have predefined importance weights in score aggregation. "hierarchical weighting scheme"
- high-entropy specification: A rich, information-dense source document that must be compressed for effective synthesis. "high-entropy specification—the scientific paper"
- Implementation Blueprint: A consolidated, unambiguous plan detailing file hierarchy, components, environment, and verification. "Implementation Blueprint"
- information-flow management: Strategically structuring, routing, and compressing information to maximize relevant signal. "principled information-flow management"
- information-theoretic lens: Viewing the synthesis task through concepts like entropy, signal, and channel capacity. "information-theoretic lens"
- IterativeAgent: An agent scaffolding that forces models to use full time and make incremental progress. "IterativeAgent"
- Knowledge Grounding: Aligning implementation with external, proven code patterns to reduce hallucinations. "Knowledge Grounding with CodeRAG"
- Language Server Protocol (LSP): A standardized interface enabling precise, programmatic code edits and diagnostics. "Language Server Protocol (LSP)"
- multi-agent system: A coordinated set of specialized agents that together analyze and plan complex tasks. "specialized multi-agent system"
- PaperBench: A benchmark evaluating LLM agents on reproducing machine learning papers into code repositories. "PaperBench"
- PaperBench Code-Dev: A benchmark variant focused on code development from research papers in sandboxed VMs. "PaperBench Code-Dev"
- program synthesis: Automatically generating executable code that fulfills a given specification. "high-fidelity program synthesis"
- Replication Score: The primary metric quantifying how well the generated repository reflects the source specification. "Replication Score"
- retrieval-augmented generation: Enhancing generation by retrieving relevant external knowledge to inform outputs. "retrieval-augmented generation"
- sandboxed environment: An isolated setup for safely executing and testing generated code. "sandboxed environment"
- Signal-to-Noise Ratio: The relative density of relevant information versus irrelevant tokens within the context. "Signal-to-Noise Ratio"
- source compression: Reducing unstructured inputs to succinct, high-signal representations. "source compression"
- structured indexing: Creating compact, queryable summaries of code or documents to manage context efficiently. "structured indexing"
- Stateful Generation: Maintaining and using evolving repository summaries to guide file-by-file synthesis. "Stateful Generation with CodeMem"
- Static Analysis: Non-executing inspection to detect structural issues and code quality problems. "Static Analysis"
- SimpleJudge: An automated grader that scores repositories against a hierarchical rubric. "SimpleJudge"
- transmission errors: Defects introduced during generation that must be corrected via feedback loops. "transmission errors (bugs)"
- Verification Protocol: A formal plan specifying metrics, setups, and success criteria for validating implementations. "Verification Protocol"
Collections
Sign up for free to add this paper to one or more collections.

