Solar Open Technical Report
Abstract: We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts LLM for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper explains how the Upstage Solar team built a very large AI LLM (like a supercharged chatbot) that works well in both Korean and English. The model has 102 billion “knobs” (parameters) and uses a design called a Mixture‑of‑Experts (think: a team of specialists). The main goal is to make strong AI for “underserved” languages—languages that don’t have as much training data as English or Chinese—by focusing on Korean while still being good at general reasoning.
Key goals in simple terms
The paper focuses on three big questions:
- How can we train a great Korean+English AI when there isn’t enough high‑quality Korean text online?
- How can we teach the model step by step—like a good school curriculum—so it learns both languages and many topics well?
- How can we make the model better at reasoning (solving multi‑step problems) in a way that scales to many goals, like safety, helpfulness, and cultural knowledge?
How they did it (methods and ideas, explained simply)
1) Making more (and better) training data
- Problem: There isn’t enough good Korean text online.
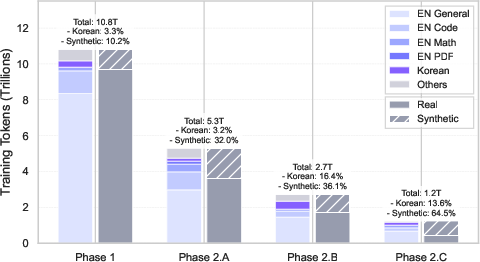
- Solution: They created a huge amount of high-quality synthetic data (4.5 trillion tokens—“tokens” are little pieces of text the model reads). This included:
- Domain-specific texts (like finance, law, medicine)
- Reasoning-focused texts that show multi-step solutions
- Carefully filtered and cleaned data to keep only the good stuff
Think of it like: if the library doesn’t have enough Korean books, they write their own practice books, with clear examples and solutions.
2) A smart, bilingual learning curriculum
- The model trained on about 20 trillion tokens total in a series of phases:
- Early: lots of broad, mixed-quality data to learn general language and facts
- Later: stricter quality filters and more high-quality Korean and advanced topics (math, code)
- They balanced English and Korean and checked topic coverage so the model learns both languages and many subjects.
This is like moving from basic classes to advanced classes with higher standards as the student improves.
3) Teaching reasoning with reinforcement learning (RL)
- Reasoning means solving problems step by step.
- They prepared the model for RL by:
- Mid-training on documents that include multiple solution paths to the same problem (so the model learns different ways to think)
- Supervised Fine‑Tuning (SFT): feeding the model successful, high-quality solution examples
- An RL framework called SnapPO: an “assembly-line” system where generating data, scoring it, and training the model happen as separate stations. This makes it easier to scale and to mix different goals (reasoning, safety, cultural alignment).
4) A better way to read text: the tokenizer
- The tokenizer breaks text into pieces (tokens), like cutting sentences into puzzle pieces the model can understand.
- They built a Korean‑friendly tokenizer with a very large vocabulary (196,608 pieces) and special rules:
- Keep numbers intact for better math (digits are separate tokens)
- Preserve spaces for better code formatting (important in Python)
- They also designed a chat format with a special <|think|> token that separates the model’s “scratch work” reasoning from the final answer—like a hidden thought bubble.
5) The model’s brain: Mixture‑of‑Experts (MoE)
- Instead of one big general brain, the model has many “experts.” For each piece of text, it picks a few experts to process it. This is more efficient and powerful.
- Specs (in simple terms): 102B total parameters, but only about 12B are active per token; very long memory window (up to 131k tokens) for long documents; 129 experts with “top‑8” chosen each time plus a shared general expert.
6) Heavy engineering to make it fast and reliable
- They trained on 480 powerful GPUs and made lots of speedups (like improving how computers talk to each other, fixing precision issues, and loading data smarter).
- Result: almost doubled training speed on their hardware setup.
Main findings and why they matter
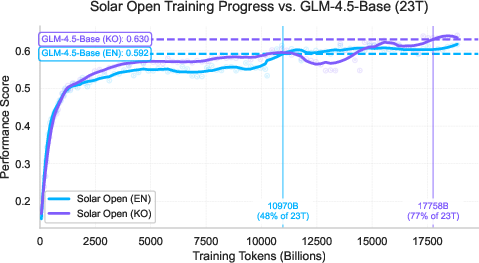
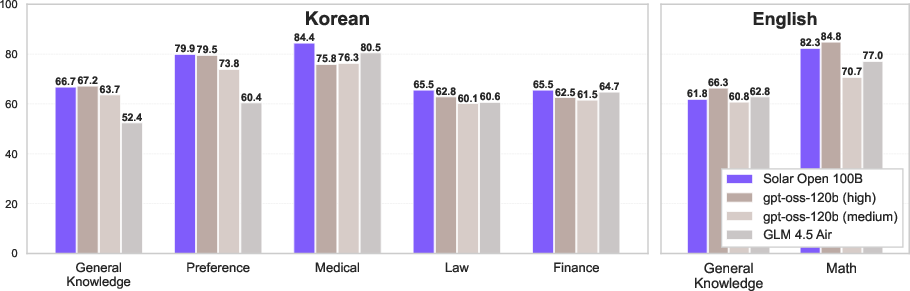
- Competitive performance in both English and Korean: The model reaches similar scores to other top open models (like GLM‑4.5‑Base) but with fewer training tokens—meaning it learned efficiently.
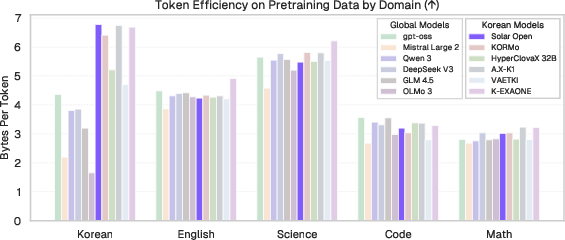
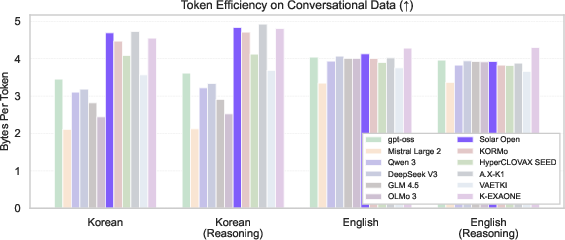
- Strong Korean handling: Thanks to the tokenizer and the carefully balanced curriculum, the model avoids common problems that make Korean text inefficient to process.
- Better reasoning: By creating many diverse solution paths, curating successful examples, and using the SnapPO RL framework, the model becomes better at multi-step problem solving.
- Agent skills: They built realistic tool-use simulations (like planning actions and calling APIs) that helped the model perform well on agent benchmarks even before RL.
Why it matters: This shows a practical way to build strong AI for languages that don’t have tons of data, without needing to copy English-only strategies.
What this could mean going forward
- More inclusive AI: The approach can be applied to other underserved languages, helping more people use AI in their native language with culturally aware knowledge.
- Smarter training pipelines: The curriculum and SnapPO framework make it easier to mix different goals (reasoning, safety, culture) at large scale without rebuilding the system each time.
- Better tools for long, complex tasks: With its long memory and expert system, the model can handle long documents, code, and step-by-step reasoning more effectively.
In short, the team shows how to build a powerful bilingual AI by creating the right data, teaching it with a thoughtful curriculum, and training it with an efficient “assembly line” RL framework—paving the way for high-quality AI in many languages beyond English and Chinese.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to be directly actionable for follow-up research.
Data and curriculum
- Provide a complete data card: exact sources (URLs, datasets, versions), per-language/domain token counts per phase, duplication rates, and preprocessing steps (including PDF parsing heuristics and error rates).
- Conduct and report benchmark contamination audits (e.g., MMLU, MMLU-Pro, HellaSwag, Tau², code/math sets) across pre-/mid-/post-training corpora and synthetic data.
- Detail the synthetic data pipeline: prompts, seed selection, models used (and versions), sampling parameters, post-editing/human review protocols, and rejection criteria; quantify quality improvements vs. cost.
- Clarify license compliance and provenance for synthetic outputs (especially when upstream models may have trained on non-permissive content); add auditing protocols and legal risk assessment.
- Quantify PII removal efficacy and privacy risk (PII detection recall/precision, manual red-teaming) for parsed PDFs and synthetic generations; provide a PII-safe pipeline description.
- Report deduplication strategy (document-, paragraph-, and n-gram-level), its impact on effective token count, and ablations on duplication vs. generalization.
- Ablate the curriculum: isolate contributions of (a) increasing synthetic ratios, (b) educational-quality thresholds, and (c) embedding-based topic sampling to downstream performance in each domain and language.
- Calibrate language-aware thresholds: show how quality filters perform differently on Korean vs. English (ROC, calibration curves), and whether thresholds induce domain/language imbalance.
- Measure cross-language interference during curriculum stages (e.g., Korean gains vs. English regressions) and establish sampling/thresholding strategies that preserve both.
Tokenizer and chat template
- Analyze the trade-offs of the 196,608-token vocabulary on memory footprint, cache behavior, and latency at inference (across batch sizes and sequence lengths); provide head-to-head throughput comparisons.
- Validate digit-splitting and whitespace-preservation effects beyond arithmetic/code (e.g., dates, scientific notation, currencies, phone numbers, spacing-sensitive Korean constructs); include ablations on downstream tasks.
- Evaluate tokenization fairness across Korean dialects, mixed-script text, code-switching, and Hangul Jamo vs. syllabic segmentation; release per-case compression and error analyses.
- Demonstrate correlation between BpT gains and downstream performance; show cases where compression improves throughput but harms accuracy (or vice versa).
- Specify and evaluate the <|think|> design: how often CoT leaks to users, controllability under different decoding settings, and the privacy/safety implications of storing or returning hidden reasoning.
Architecture and MoE behavior
- Report MoE routing dynamics: expert specialization by language/domain, capacity factor, token drop rates (if any), entropy of routing logits across layers, and stability over training.
- Ablate Top-k routing (e.g., k=4/6/8/12) and expert counts on quality vs. efficiency; study early-layer imbalance at full scale (not just 10B-A1B prototypes).
- Compare dropless vs. dropped token routing, and the interplay of expert-bias vs. load-balancing losses on stability and generalization.
- Document memory/latency trade-offs for the large vocab with 12B active parameters per token; provide inference-time cost models to guide deployment.
Training and systems engineering
- Release reproducible engineering artifacts: patches for Triton/CUDA compatibility, HSDP configurations, dtype restoration, grouped-GEMM limits, and exact TorchTitan commit hashes.
- Provide end-to-end cost and energy accounting (GPU-hours, power draw, PUE), and the impact of each optimization on energy efficiency.
- Characterize scaling beyond 60 nodes (e.g., sensitivity to network topology, interconnect bandwidth) and failure modes (e.g., stragglers, fault tolerance) during long runs.
- Clarify the “Repeat-KV Optimization” referenced in the throughput table: algorithmic details, applicability scope, and correctness trade-offs.
Mid-training and SFT
- Quantify catastrophic forgetting risk and mitigation efficacy: track perplexity and domain-specific scores before/after mid-training and SFT (especially for English and code/math).
- Validate the difficulty estimator: inter-rater reliability of LLM-based labeling, calibration across domains, bias toward models used to generate labels, and generalization to unseen tasks/languages.
- Release the difficulty-balanced query generator details and evaluate whether raising difficulty improves final performance vs. increased noise; provide failure analyses for over-hard queries.
- Provide data mixture weights for SFT (by language, domain, difficulty), and ablate their effects on instruction-following vs. reasoning vs. tool-use.
RL (SnapPO) specifics
- Specify reward models/functions per objective (reasoning, alignment, safety, culture), their training data, calibration, and anti-gaming safeguards; quantify reward hacking incidents.
- Describe off-policy corrections (e.g., importance sampling, advantage normalization), buffer staleness controls, and policy refresh cadence; include stability/variance analyses.
- Compare SnapPO to standard online PPO/DPO on sample efficiency, wall-clock time, and final performance; include ablations on cyclic decoupling choices.
- Show multi-objective composition strategies (reward scaling, aggregation, scheduling) and trade-offs (e.g., safety vs. helpfulness vs. reasoning); publish Pareto frontiers.
- Detail how <|think|> is handled in RL: whether rewards target hidden reasoning, final answers, or both; impacts on CoT controllability and externalized reasoning quality.
Evaluation coverage and methodology
- Move beyond preliminary curves: report comprehensive benchmark suites covering reasoning (GSM8K, MATH, AIME, BBH), code (HumanEval/MBPP/CRUXEval), knowledge (NaturalQuestions/TriviaQA), multilingual (KMMLU, KoBEST, Ko-ARC), safety/alignment (TruthfulQA, BBQ, AdvBench), and tool-use (ToolBench, SWE-bench, AgentBench, more Tau² breakdowns).
- Provide long-context evaluations up to the claimed 131k window (e.g., RULER, Needle-in-a-Haystack, SCROLLS/L-Eval, LV-Eval), including degradation curves, retrieval sensitivity, and memory robustness.
- Include human evaluations for Korean-specific cultural tasks, politeness/register control, and stylistic fidelity; report inter-annotator agreement and rubric.
- Publish decoding setups (temp/top-p, sampling seeds), prompt formats, and contamination checks for all reported metrics to ensure comparability.
Safety, bias, and ethics
- Conduct bilingual safety audits: jailbreak robustness, toxicity, misinformation, protected-class harms, culturally specific harms, and refusal/right-safety balance; report differential risks across languages.
- Measure factuality and calibration (e.g., truthfulness vs. overconfidence) with and without visible CoT; assess whether CoT increases hallucination or confabulation in Korean vs. English.
- Analyze agent/tool-use safety: prompt injection, tool misuse, data exfiltration, and recovery behaviors; propose and test guardrail strategies compatible with the chat template.
- Document governance: incident reporting, intended-use restrictions, model card with hazard profiling, and policies for misuse mitigation.
Release, reproducibility, and community use
- Clarify release plan: exact model name (currently omitted), checkpoints, tokenizer and chat template artifacts, licenses, and allowed use-cases.
- Provide training logs, seeds, and monitoring dashboards (perplexity, routing stats) to enable replication; share configuration files for pre-/mid-/post-training.
- Release at least a subset of synthetic datasets and filtering models (educational quality scorer, topic clustering) with instructions to reproduce the curriculum at reduced scale.
Generalization and applicability
- Validate the approach on at least one additional underserved language beyond Korean to test portability (tokenizer adaptation, curriculum retuning, RL reward localization).
- Study code-switching and translation quality between Korean and English, and the impact of bilingual training on cross-lingual transfer (including Japanese/multilingual spillover).
- Provide deployment guidance: quantization/LoRA strategies for 12B-active MoE, latency/throughput under realistic serving loads, and effects of large vocabulary on KV-cache and server memory.
Open technical questions
- How do expert specializations evolve for bilingual reasoning, and can routing be steered to mitigate cross-language interference?
- What is the optimal coupling between mid-training trajectory synthesis and RL for compositional reasoning gains without reward hacking?
- Does increased tokenizer compression monotonically improve reasoning throughput at long context lengths, or are there regimes where it harms attention stability?
- Can SnapPO’s off-policy decoupling maintain stability as the number of objectives/scorers grows, and what are the theoretical/empirical limits of buffer staleness?
Glossary
- AdamW optimizer: A variant of Adam that decouples weight decay from gradient updates to improve generalization during training. "We use AdamW optimizer throughout all training phases with , , , weight decay of 0.1, and gradient clipping of 1.0."
- Activation checkpointing: A memory-saving technique that stores fewer intermediate activations and recomputes them during backpropagation, enabling larger batches. "larger batch sizes enabled by full activation checkpointing outweigh memory savings from selective checkpointing strategies;"
- Agentic workflows: Multi-step, tool-using processes where the model acts as an agent coordinating tools and reasoning over results. "native support for parallel tool calling, essential for agentic workflows."
- All-reduce operations: Distributed training communication primitives that aggregate tensors (e.g., gradients) across devices. "all-reduce operations for gradient synchronization"
- Arrow-formatted datasets: Columnar data format (Apache Arrow) enabling efficient storage and parallel loading of large datasets. "internal structure of Arrow-formatted datasets"
- bfloat16: A 16-bit floating-point format with larger exponent range than FP16, often used for stable mixed-precision training. "a hybrid setup of FP8 and bfloat16"
- Block-masked attention: An attention mechanism that restricts attention to specific blocks to improve efficiency or stability. "our adoption of block-masked attention"
- Byte fallback: Tokenization behavior where text not covered by the vocabulary is encoded as raw bytes, often harming efficiency and semantics. "the byte fallback would subsequently result in sub-optimal semantic segmentation"
- Byte-Pair Encoding (BPE): A subword tokenization algorithm that merges frequent byte pairs to form tokens. "a custom-built byte-level Byte-Pair Encoding (BPE) tokenizer"
- Bytes per Token: A compression efficiency metric indicating average bytes represented by each token. "measured by Bytes per Token"
- CLIMB: A method for embedding-based clustering and filtering to sample topic-aligned data. "Following CLIMB \citep{diao2025climb}"
- Chain-of-thought reasoning: Explicit step-by-step reasoning traces generated before final answers to improve problem solving. "internal chain-of-thought reasoning"
- Context length: The maximum number of tokens the model can process in a single input. "context length extension phases at the end of the pre-training"
- Data curriculum: A staged training data schedule that progresses from noisy/broad to high-quality/specialized content. "The data curriculum for the pre-training phases of ."
- Depth-Up Scaling: A scaling strategy that increases model depth to expand capacity while managing efficiency. "based on Depth-Up Scaling~\citep{kim2024solar107bscalinglarge}"
- Embedding-Based Topic Filtering: Selecting data by clustering text embeddings to ensure coverage of desired domains. "Embedding-Based Topic Filtering"
- Expert bias: A routing adjustment term in MoE that biases selection of experts to improve balance or stability. "expert bias (coefficient: 1e-3)"
- Expert imbalance: Uneven load distribution across experts in MoE, which can destabilize training. "Expert imbalance represents a persistent challenge in MoE architectures"
- Expert parallelism: A distributed training strategy that shards experts across devices to accelerate MoE models. "expert parallelism and tensor parallelism provide no benefit over pure FSDP"
- FP8: An 8-bit floating-point precision format used to accelerate training with acceptable numerical stability. "adding FP8 support"
- FSDP2: A PyTorch variant of Fully Sharded Data Parallel that shards parameters and gradients across devices. "Standard FSDP2~\citep{zhao2023pytorch} performance degrades significantly"
- Grouped GEMM: Batched matrix multiply operations grouped for efficiency, used in MoE expert computations. "TorchTitan's grouped GEMM implementation"
- HellaSwag: A commonsense reasoning benchmark assessing grounded and plausible continuation of scenarios. "MMLU, MMLU-Pro, and HellaSwag benchmarks"
- HSDP (Hybrid Sharding Data Parallel): A hierarchical data-parallel strategy that confines most communication to intra-group operations. "Hybrid Sharding Data Parallel (HSDP)"
- Load balancing loss: An auxiliary loss term encouraging even routing/load across experts in MoE. "employ load balancing loss in conjunction with expert bias"
- Mixture-of-Experts (MoE): An architecture that routes tokens to a subset of specialized expert networks for efficiency and capacity. "Mixture-of-Experts (MoE)"
- MMLU: A benchmark measuring LLM knowledge across multiple academic subjects. "MMLU~\citep{hendrycks2020measuring}"
- MMLU-Pro: A harder variant of MMLU aimed at more challenging reasoning and knowledge tasks. "MMLU-Pro~\citep{wang2024mmlu}"
- Off-policy reinforcement learning: RL where the policy being optimized can differ from the one generating data, enabling cached and decoupled pipelines. "a cyclic off-policy framework"
- Repeat-KV Optimization: An optimization technique related to attention key-value reuse to improve throughput. "Repeat-KV Optimization"
- Reinforcement learning (RL): A training paradigm optimizing actions via rewards, used to teach compositional reasoning and alignment. "Reinforcement learning enables the compositional reasoning"
- Rotary Positional Embedding (RoPE): A positional encoding method that rotates query/key vectors to inject position information. "RoPE (: )"
- Router (MoE): The component that selects which experts process each token in an MoE layer. "Router Dtype Restoration."
- Sequence-wise load balancing loss: A load balancing formulation computed over sequences to stabilize expert routing. "sequence-wise load balancing loss (coefficient: 1e-4)"
- SiLU: The Sigmoid Linear Unit activation function, often used in modern transformers. "SiLU \citep{elfwing2018sigmoid}"
- SnapPO: A decoupled, cyclic off-policy RL framework enabling scalable multi-domain reward composition. "SnapPO"
- Sparse Mixture-of-Experts (MoE) Transformer: A transformer where only a subset of experts are active per token, improving efficiency. "employs a sparse Mixture-of-Experts (MoE) Transformer architecture"
- Supervised fine-tuning (SFT): Post-training with labeled examples to teach instruction following, formatting, and high-quality trajectories. "SFT~\citep{ouyang2022training}"
- Tau2-Bench: A benchmark for tool-use and agentic capabilities across multi-step tasks. "60 points on Tau-Bench"
- Tensor parallelism: Model parallelism that splits tensors (e.g., layers) across devices for distributed computation. "expert parallelism and tensor parallelism provide no benefit"
- Top-k routing: Selecting the k best experts per token in MoE based on router scores. "Num Experts per Token (Top-) & 8"
- TorchTitan: A PyTorch-based large-scale training framework optimized for speed and memory in LLM pretraining. "TorchTitan"
- Triton: A GPU programming language/compiler used to implement efficient kernels for deep learning. "Triton lacks CUDA 13.0 support"
Practical Applications
Immediate Applications
Below are practical applications that can be deployed now, leveraging the paper’s model, data methods, engineering optimizations, and agent/workflow design.
- Korean-first enterprise assistant for customer support and knowledge management
- Sector: software, customer service, retail
- What emerges: bilingual assistant powered by a Korean-aware tokenizer, long-context RAG over internal FAQs, policy documents, and product catalogs; parallel tool calling for ticketing, CRM updates, and search
- Assumptions/dependencies: access to the model weights and chat template; enterprise connectors; basic safety/preference SFT
- High-fidelity bilingual translation and localization workflows
- Sector: media, gaming, education, government
- What emerges: translation/localization pipelines that exploit better compression for Korean, improved number handling (digit splitting), and code/format fidelity (whitespace preservation)
- Assumptions/dependencies: domain terminology glossaries; evaluation loop for cultural/localization quality; secure handling of sensitive content
- Long-context RAG for regulated document review (up to 131k tokens)
- Sector: legal, finance, compliance
- What emerges: reviewers that ingest large contracts, prospectuses, and policy manuals in Korean/English; structured summaries, risk flags, cross-references; mid-training long-context capability supports extended windows
- Assumptions/dependencies: robust retrieval index; guardrails; audit logging; domain-specific evaluation sets
- Code assistant with tokenizer-level fidelity and multi-tool orchestration
- Sector: software development
- What emerges: code review/generation agents benefiting from whitespace preservation; parallel tool calls to static analyzers, linters, CI, and issue trackers; large-context handling for monorepos
- Assumptions/dependencies: IDE/DevOps integrations; privacy controls; team acceptance and human-in-the-loop review
- STEM tutor and assessment support
- Sector: education
- What emerges: math/science tutoring in Korean with consistent number tokenization (digit splitting), structured problem solving via <|think|>; adaptive difficulty using the paper’s difficulty estimator
- Assumptions/dependencies: curricular alignment; content safety; transparency settings for chain-of-thought exposure
- Task-oriented and user-oriented API agents for business workflows
- Sector: e-commerce, travel, fintech, operations
- What emerges: agents trained via synthesized tool-use trajectories (task-oriented and user-oriented simulators) performing multi-step planning, tool selection, argument generation, and error recovery
- Assumptions/dependencies: accurate API specifications; monitoring; rollback strategies; tool availability and latency
- Synthetic data bootstrapping for underserved-language domains
- Sector: media, healthcare, legal, finance, public sector
- What emerges: internal pipelines replicating the paper’s synthesis + progressive filtering (general quality, educational scoring, embedding topic coverage) to create high-quality domain corpora in Korean
- Assumptions/dependencies: permissive licensing; validation of synthetic quality; domain expert review; storage/I/O capacity
- Difficulty-aware data curation and query generation for SFT
- Sector: academia (ML), applied AI teams
- What emerges: reusable difficulty classifier and cyclic query generator to balance training signal; better SFT datasets for reasoning, code, math in Korean/English
- Assumptions/dependencies: seeding corpora; multi-model response sampling; labeling budget; reproducibility of the estimator
- SnapPO adoption for scalable multi-objective RL
- Sector: applied AI (alignment, safety, reasoning), platform providers
- What emerges: decoupled RL workflow (data generation ↔ reward computation ↔ training) enabling parallel scaling and independent reward modules for reasoning, safety, cultural alignment
- Assumptions/dependencies: availability of SnapPO or equivalent; reward function design; cache stores; orchestration tooling
- GPU training throughput playbook for large MoE models
- Sector: ML engineering, HPC
- What emerges: operationalization of HSDP, dtype restoration for routers, grouped GEMM fast paths, Arrow file-level sharding; quick wins for teams training >50B models
- Assumptions/dependencies: TorchTitan/PyTorch versions with required patches; multi-node (B200/H200) clusters; monitoring for gradient norm issues
- PDF parsing and structured ingestion for technical content
- Sector: finance, legal, academia, healthcare
- What emerges: custom pipeline preserving formatting/semantics; conversion of legacy archives into training/RAG-ready datasets
- Assumptions/dependencies: document access; OCR quality for scans; metadata normalization
- Language-aware tokenizer design kit
- Sector: ML tooling, localization
- What emerges: replicable approach to large-vocab BPE, oversampling target languages/domains, digit/whitespace rules; inference-time efficiency benchmarks for real outputs
- Assumptions/dependencies: tokenizer training compute; domain corpora; acceptance of larger embedding tables
- Public-sector pilots for Korean-language citizen services
- Sector: policy, government services
- What emerges: municipal/state chatbots answering forms/process queries; bilingual support; long-context intake for forms and guidance
- Assumptions/dependencies: procurement, privacy and retention policies; human oversight; accessibility compliance
Long-Term Applications
The following applications require further research, scaling, domain validation, or infrastructure development before broader deployment.
- National/regional LLM programs for underserved languages beyond Korean
- Sector: policy, public sector, academia
- What emerges: replicating the paper’s synthetic data + curriculum + SnapPO RL stack for Arabic, Japanese, regional languages; open-weight ecosystems fostering local innovation
- Assumptions/dependencies: sustained funding; language-specific tokenizers; community governance; benchmark development
- Clinical decision support and longitudinal EHR reasoning in Korean
- Sector: healthcare
- What emerges: long-context assistants synthesizing multi-visit EHRs; structured outputs, guideline checks, triage; culturally aligned patient communication
- Assumptions/dependencies: rigorous clinical validation; regulatory clearance; robust safety/reward models; integration with hospital systems
- Legal research and case analytics across bilingual corpora
- Sector: legal
- What emerges: cross-lingual case law synthesis; precedents tracking; risk analysis over decades-long filings using extended context
- Assumptions/dependencies: court-approved QA; confidentiality; domain-aligned RL rewards; updated legal corpora
- Cross-lingual financial risk, compliance, and audit agents
- Sector: finance
- What emerges: agents scanning mixed-language disclosures, contracts, and communications; tool-graph workflows for checks; explainable flags and trails
- Assumptions/dependencies: extensive internal tool coverage; human-in-the-loop review; model auditability; regulator acceptance
- Adaptive curriculum tutors with difficulty-aware lesson planning
- Sector: education
- What emerges: per-grade, subject-specific tutors that adjust content difficulty using the paper’s classifier; compositional reasoning via RL; culturally aligned materials
- Assumptions/dependencies: educational standards mapping; longitudinal assessment; safety and bias audits; parental/teacher controls
- Autonomous multi-tool enterprise agents
- Sector: software, operations
- What emerges: end-to-end agents executing complex branching workflows (planning, tool selection, error handling, memory management) built on the paper’s agent simulators and parallel tool calling
- Assumptions/dependencies: hardened tool APIs; transactional safeguards; provenance tracking; robust failure recovery
- Standardized multi-objective RL pipelines integrated into MLOps
- Sector: ML platforms
- What emerges: productized SnapPO-like frameworks with domain-specific reward registries (reasoning, safety, culture, tools); scalable caching and evaluation harnesses
- Assumptions/dependencies: community standards; shared reward libraries; compute budgets; monitoring and rollback frameworks
- Scaling to 200B+ models via Depth-Up strategies
- Sector: applied AI
- What emerges: higher-capability bilingual models with improved reasoning and coverage; downstream performance gains in complex domains
- Assumptions/dependencies: GPU capacity; training stability at scale; data curation extensions; inference cost management
- Tokenizer benchmarking and standards for inference-time efficiency
- Sector: ML tooling
- What emerges: formalized metrics and suites (e.g., IF-bilingual-sft-style outputs) to guide tokenizer design for real deployments; shared best practices
- Assumptions/dependencies: community adoption; cross-model comparability; downstream acceptance of larger vocabularies
- Government language equity policies and data commons
- Sector: policy
- What emerges: grants and procurement templates for synthetic data generation; safe-data governance; public-domain corpora in underserved languages; evaluation infrastructure
- Assumptions/dependencies: legal frameworks for synthetic data; privacy norms; community participation; sustainability
- Language-to-action planning for robotics via tool-graph reasoning
- Sector: robotics, manufacturing
- What emerges: adapting API graph construction and multi-step reasoning to embodied toolkits; task decomposition, error recovery, and memory handling for robot workflows
- Assumptions/dependencies: grounding to sensors/actuators; simulator-to-reality transfer; safety certification; latency constraints
- Industrial operations and energy documentation assistants
- Sector: energy, industrial maintenance
- What emerges: long-context synthesis of manuals, logs, and SOPs; agentic workflows for maintenance scheduling and incident analysis
- Assumptions/dependencies: data integration; domain-specific evaluation; operator training; reliability guarantees
- Multilingual scientific research assistants for math/code-heavy tasks
- Sector: academia, R&D
- What emerges: assistants that draft, verify, and translate technical content; code+math reasoning over large contexts; lab tool integration
- Assumptions/dependencies: reproducibility checks; citation/attribution policies; domain-specific reward shaping; community vetting
Collections
Sign up for free to add this paper to one or more collections.