- The paper introduces StackPlanner, enhancing centralized LLM systems with hierarchical task-experience memory management.
- StackPlanner employs a modular approach coupling task memory control with structured memory and RL policy optimization.
- Empirically, StackPlanner outperforms existing frameworks, notably achieving state-of-the-art F1 scores on multiple tasks.
StackPlanner: Hierarchical Centralized Multi-Agent System with Explicit Task-Experience Memory Management
Introduction and Motivation
StackPlanner addresses critical deficiencies in current LLM-centric multi-agent systems for complex, knowledge-intensive reasoning, notably the instability of centralized architectures in long-horizon collaboration due to memory bloat, error accumulation, and poor cross-task generalization. The framework recognizes two central challenges: (1) the need for explicit, fine-grained control over task-level memory to prevent LLM agents from being overwhelmed by low-signal, high-volume context, and (2) the lack of practical mechanisms for leveraging reusable, structured coordination experience across tasks in a dynamically extensible way. StackPlanner explicitly decouples high-level coordination from subtask execution, coupling active task memory control with structured experience memory and RL policy optimization.
System Architecture
StackPlanner employs a hierarchical multi-agent system, comprising a central coordinator and several specialized sub-agents, each modularized to encapsulate domain-relevant expertise and procedural autonomy.
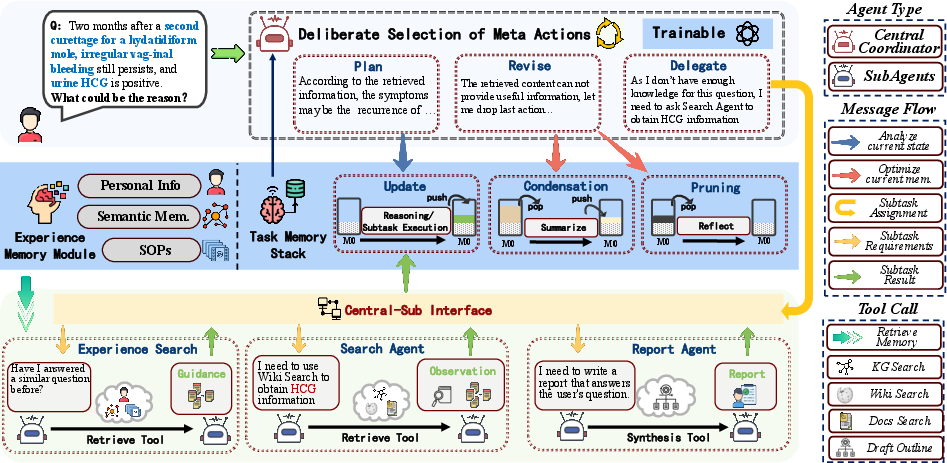
Figure 1: Overview of the StackPlanner framework, illustrating hierarchical coordination, separation of task and experience memory, and multi-agent action flow.
The central coordinator operates in a compact, discrete action space: {Plan, Delegate, Revise}. Planning is oriented towards high-level strategy and decomposition; Delegation spawns targeted subtasks to specialized sub-agents (e.g., Search Agent, Report Agent), and Revise enables memory condensation and pruning. Sub-agents operate autonomously during execution to ensure modularity and to prevent context contamination of the shared task memory.
Active task memory management is realized by maintaining a stack-structured memory M, with operations including sequential update, condensation (summarizing contiguous memory blocks), and pruning (removal of noisy or failed inference steps, with failure causes retained for subsequent reflection). This stack-centric approach enables explicit and dynamic regulation of context available to the coordinator, mitigating the "lost in the middle" phenomenon in LLMs working over extended contexts [liu2023lost].
Cross-task generalization is targeted via a structured "experience memory," supporting three orthogonal axes: user profiles, semantic memory (atomic factual knowledge), and procedural memory (abstract reusable procedures). Experience Search agents enable the retrieval and injection of relevant prior experience into the live task memory during coordination, reducing cold-start failures and improving sample efficiency across tasks [li2025crosstaskexperientiallearningllmbased].
Policy Optimization and Learning
StackPlanner’s coordination policy is formulated as a groupwise, multi-step RL problem operating over the external search engine and the stack-structured memory interface. Policy πθ is trained exclusively via GRPO (Group Relative Policy Optimization), which leverages rollout group statistics to compute normalized, group-relative advantages for token-level policy updates, eliminating the need for an explicit value function [shao2024deepseekmath]. This methodology allows for robust, fine-grained learning signals even in high-variance, long-horizon decision processes.
The RL objective incorporates KL-regularization to constrain policy drift from a frozen reference, and all reward, advantage, and policy update calculations are performed at the action level, yet efficiently propagated at the token level for end-to-end optimization.
StackPlanner thus differentiates itself from parametric-only RLHF pipelines [schulman2017proximal] and coarse-grained RL-augmented search (e.g., Search-R1 [jin2025search]), by integrating retrieval, stepwise reasoning, and explicit memory control in a unified RL framework.
StackPlanner exhibits robust, high-precision performance across a spectrum of multi-hop QA and agentic benchmarks (2WikiMultiHopQA, MuSiQue, GAIA, FRAMES) using Qwen2.5 backbones [Yang2024Qwen25TR]. Notably, it achieves state-of-the-art F1 on challenging out-of-distribution tasks that demand deep reasoning and memory-intensive navigation. For Qwen2.5-7B, StackPlanner attains 38.34% (2Wiki), 22.01% (MuSiQue), 9.45% (GAIA), 19.44% (FRAMES), representing consistent improvements over ReACT, IRCoT, OWL, MacNet, and RL-based baselines such as ReSearch and ARPO.
Rigorous ablation demonstrates that removal of either active task memory or experience memory leads to pronounced drops in performance, with the absence of both resulting in catastrophic degradation (e.g., 32.92%→17.12% F1 on 2Wiki), confirming the necessity and orthogonality of explicit memory and experiential generalization modules.
Qualitative case studies further illustrate StackPlanner’s ability to iteratively prune irrelevant context, focus on actionable knowledge, and generalize procedural strategies to accelerate long-horizon research and synthesis tasks.
Implications, Limitations, and Future Directions
StackPlanner’s explicit memory-centric paradigm for LLM coordination supports improved scalability and robust generalization in multi-agent reasoning and task automation. Its stack-based task memory overcomes context flooding, and experience memory enables RL-driven transfer of compositional strategies—a critical need in open-ended agentic workflows [guo2024largelanguagemodelbased].
The limitations include incomplete support for multi-turn conversational dependencies—sub-agent behaviors are not persistently modeled across long dialogs—and residual cold-start issues in long-term memory when facing new or highly divergent user behaviors. Future work includes designing even more compact yet expressive memory abstractions, extending StackPlanner to open-ended, real-world domains and workflows, and strengthening compositional generalization of procedural knowledge.
Conclusion
StackPlanner establishes a clear framework for hierarchically structured, memory-controlled multi-agent systems, setting a new standard for robust, scalable RL-based orchestration of LLM agents in complex task environments. By formalizing memory as a first-class controllable resource, and combining it with structured experience memory and RL-based learning, StackPlanner demonstrates stable coordination, error correction, and cross-task generalization. The architectural innovations and empirical validation provide a blueprint for next-generation agentic systems tackling information-rich, long-horizon workflows in both research and applied domains.


