- The paper introduces a collaborative memory framework with a two-tier system that enables fine-grained, dynamic access control in multi-user LLM environments.
- It employs immutable provenance and dynamic bipartite graphs to enforce policies, ensure auditability, and reduce resource usage by up to 61%.
- Empirical evaluations across fully collaborative, asymmetric, and dynamic settings demonstrate high accuracy and efficiency under evolving access patterns.
Collaborative Memory: Multi-User Memory Sharing in LLM Agents with Dynamic Access Control
The paper introduces a formal framework for collaborative memory in multi-user, multi-agent LLM systems, addressing the limitations of prior work that assumes monolithic, single-user memory architectures. The authors identify two central challenges in real-world collaborative AI deployments: (1) information asymmetry, where users and agents have heterogeneous, often overlapping access to resources; and (2) dynamic access patterns, where permissions evolve over time due to changing roles, policies, or organizational structure. The proposed solution is a memory substrate that supports fine-grained, time-varying access control, enabling secure and efficient knowledge sharing while maintaining strict privacy and auditability.
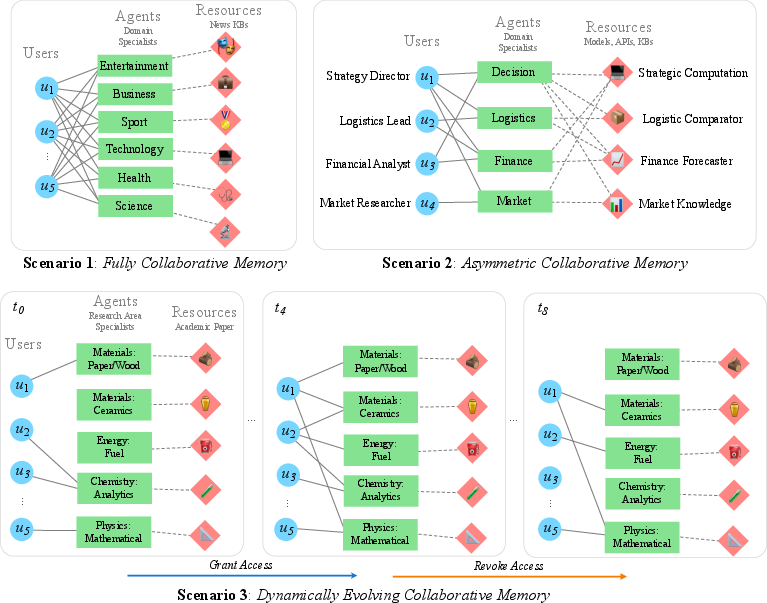
Figure 1: Multi-user, multi-agent collaboration scenarios: fully collaborative (top-left), asymmetric privileges (top-right), and dynamically changing access (bottom).
Framework Architecture
The core of the framework is a two-tier memory system, partitioning memory into private and shared fragments. Each memory fragment is annotated with immutable provenance attributes—contributing agents, accessed resources, and timestamps—enabling retrospective permission checks and auditability. Access control is formalized via two dynamic bipartite graphs: user-to-agent and agent-to-resource, both evolving over time to reflect the current permissions landscape.
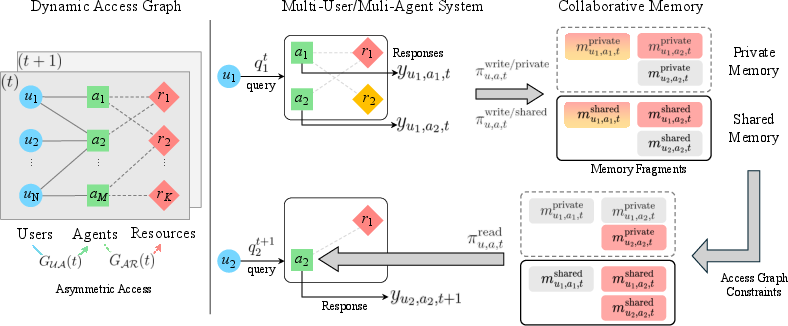
Figure 2: Left: Dynamic multi-user environment with agents and resources. Right: Collaborative Memory workflow, showing query routing, memory updates, and access filtering.
Memory read and write operations are governed by configurable policies. The read policy projects the current access graph onto the memory store, filtering fragments to construct a view consistent with the user’s and agent’s permissions. The write policy determines which fragments are retained, redacted, or shared, supporting context-aware transformations such as anonymization or content filtering. Both policies can be instantiated globally, per-user, per-agent, or as a function of time, providing high flexibility for real-world deployments.
Implementation Details
The system is implemented using GPT-4o for all LLM-based components, including the coordinator, domain-specialized agents, memory transformation modules, and the aggregator. Vector embeddings are generated with text-embedding-3-large, and external resources are exposed as Python callables with JSON schemas, invoked via OpenAI’s function-calling interface.
The multi-agent interaction loop is orchestrated by a coordinator LLM, which receives the user query, agent specializations, and conversation history, and outputs a sequence of agent assignments and subqueries. After agent responses are generated, a dedicated aggregator LLM synthesizes the final answer. Memory fragments are encoded as key–value pairs with provenance, and retrieval is performed via cosine similarity between subquery embeddings and memory keys, subject to access constraints.
Two policy instantiations are evaluated: a simple policy (verbatim read/write) and a transformation policy (LLM-mediated redaction/anonymization on write). The experiments use the transformation write policy and simple read policy.
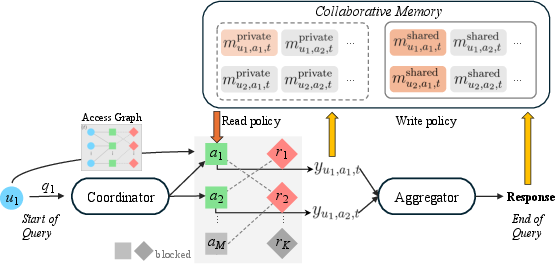
Figure 3: End-to-end pipeline from user query to response, with coordinator and aggregator implemented via GPT-4o.
Experimental Evaluation
Scenario 1: Fully Collaborative Memory
In the fully collaborative setting, all users have unrestricted access to all agents and resources. Using the MultiHop-RAG dataset (2,556 multi-hop questions over six domains), the system demonstrates that collaborative memory reduces resource utilization by up to 61% at 50% query overlap, with accuracy consistently above 0.90. Both isolated and collaborative memory achieve similar accuracy, but collaborative memory yields a more substantial reduction in resource usage as query overlap increases.
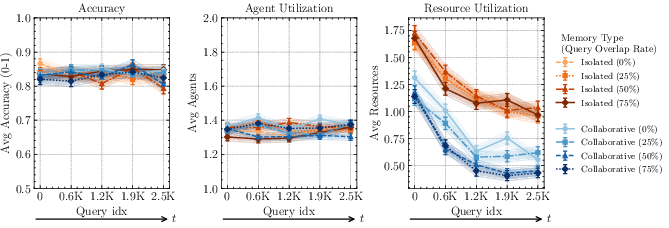
Figure 4: MultiHop-RAG performance under varying query overlap. Collaborative memory achieves lower resource usage across all overlap rates.
Scenario 2: Asymmetric Collaborative Memory
Here, users have heterogeneous privileges, and only partial memory sharing is permitted. In a synthetic business project dataset, asymmetric collaboration reduces redundant resource calls compared to isolated memory, even when only partial cross-user visibility is allowed. The Strategy Director, with maximal privileges, benefits from intermediate insights discovered by other users, further reducing unnecessary tool invocations.
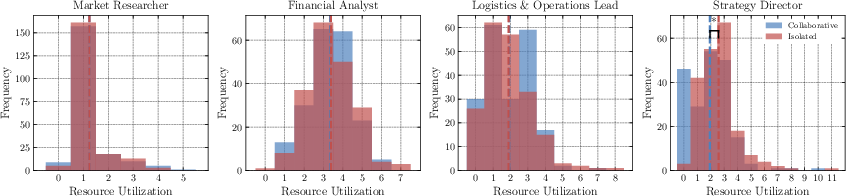
Figure 5: Resource usage with and without asymmetric collaboration. Partial sharing reduces overall resource calls while respecting privilege boundaries.
Scenario 3: Dynamically Evolving Collaborative Memory
This scenario evaluates the system under real-time changes in access permissions using the SciQAG scientific QA dataset. As access is granted, accuracy and agent/resource usage increase; as privileges are revoked, these metrics decrease accordingly. The system strictly adheres to the current access graph, and memory reuse further reduces external resource calls over time.
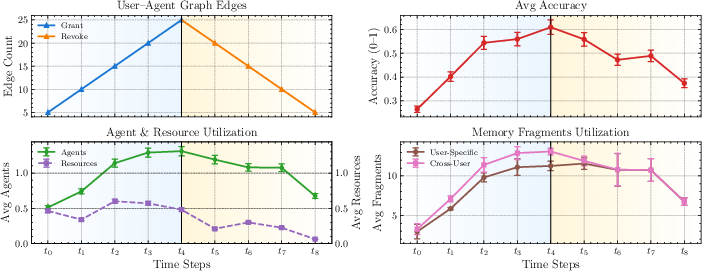
Figure 6: System performance over eight time blocks with dynamic privilege changes. Accuracy and resource usage track the available access.
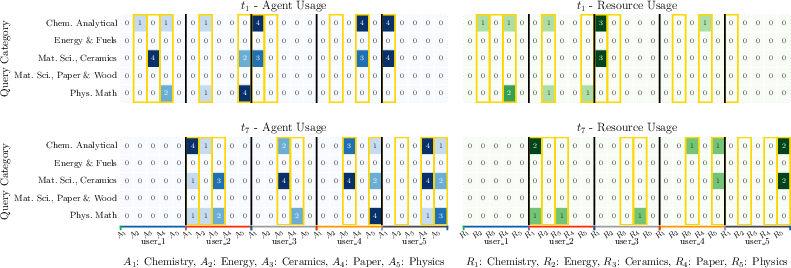
Figure 7: Agent and resource usage across user queries, with yellow rectangles indicating granted access and usage counts.
Policy Enforcement, Auditability, and Security
A key property of the framework is provable adherence to asymmetric, time-varying access policies. The use of immutable provenance and dynamic access graphs ensures that memory fragments are only surfaced to agents and users with the requisite permissions, even as those permissions change. This design supports full auditability of memory operations and enables retrospective compliance checks, which are critical for enterprise and regulated environments.
Limitations
The evaluation is constrained by the lack of large-scale, real-world multi-user datasets, necessitating the use of synthetic or benchmarked environments. The current implementation is validated on moderate numbers of users and agents; scaling to large enterprise deployments with high concurrency and rapidly evolving roles remains an open challenge. Additionally, reliance on LLMs introduces the risk of hallucinations or policy breaches, though the framework’s enforcement mechanisms mitigate these risks to some extent.
Implications and Future Directions
The collaborative memory framework provides a principled foundation for secure, efficient, and interpretable knowledge sharing in multi-agent, multi-user LLM systems. Its modular design allows integration with alternative memory architectures (e.g., hierarchical or graph-based memory) and supports fine-grained, adaptive policy specification. The approach is directly applicable to enterprise assistants, productivity platforms, and distributed workflow systems where privacy, compliance, and efficiency are paramount.
Future research directions include: (1) developing large-scale, realistic multi-user benchmarks; (2) extending the framework to support concurrent, low-latency operations at enterprise scale; (3) integrating more sophisticated policy languages (e.g., ABAC) and automated policy synthesis; and (4) exploring formal verification of policy compliance in the presence of probabilistic LLM outputs.
Conclusion
This work formalizes the problem of collaborative memory in multi-user, multi-agent LLM systems, introducing a two-tier memory architecture with dynamic, provenance-aware access control. The framework enables safe, efficient, and auditable knowledge sharing under asymmetric, time-varying permissions, and demonstrates substantial reductions in resource utilization without compromising accuracy or privacy. The approach lays the groundwork for scalable, trustworthy multi-agent AI systems in complex, real-world environments.

