- The paper introduces a novel file-centric state abstraction that separates persistent memory from immediate reasoning context.
- It employs a hierarchical agent architecture with specialized sub-agents to manage multi-step tasks and reduce error propagation.
- Empirical results on benchmarks show that smaller models achieve competitive performance, validating the design's stability and efficiency.
InfiAgent: Framework and Implications for Long-Horizon LLM Agents
The central challenge addressed in "InfiAgent: An Infinite-Horizon Framework for General-Purpose Autonomous Agents" (2601.03204) is the instability of LLM agents in long-horizon, multi-step tasks. Prevailing LLM agents encode cumulative dialogue history, tool interactions, intermediate plans, and results directly into the context window. As task length increases, this approach suffers from unbounded context growth, necessitating unreliable truncation, summarization, or retrieval-augmented techniques. This design leads to information loss, performance degradation—particularly the “illusion of state”—and instability over extended interaction horizons.
The paper asserts that existing mitigations such as RAG, long-context models, or micro-agent-based extreme task decomposition either conflate persistent state with immediate reasoning context or limit domain generality. The core claim is that robust infinite-horizon reasoning in open, ill-posed research domains is infeasible without a formal separation between persistent long-term state and bounded-context reasoning.
File-Centric State Abstraction and Agent Architecture
InfiAgent defines a novel agent execution formalism: agent state is externalized into a persistent, file-centric abstraction (Ft), distinct from the agent’s bounded reasoning context at each step. The workspace files—containing plans, data, artifacts, logs—are the authoritative memory, not the LLM prompt context. The bounded in-context prompt is reconstructed at each agent step by sampling from the current workspace state plus a small k-step action buffer.
This architecture enforces that the agent’s context is strictly O(1) with respect to task horizon, eliminating the unbounded context growth observed in previous systems.
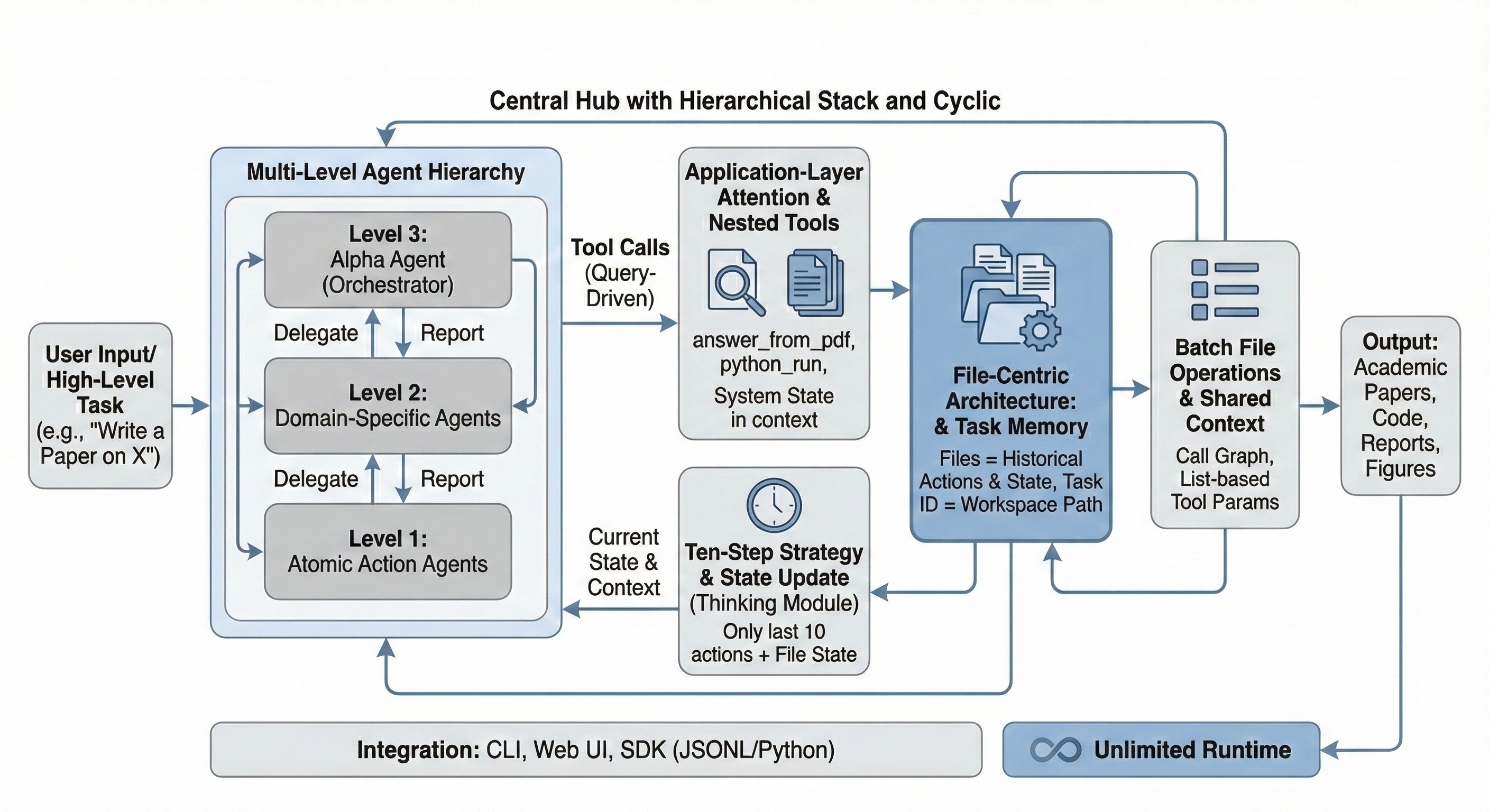
Figure 1: The InfiAgent hierarchical architecture maintains authoritative state in workspace files, periodically consolidating agent progress and leveraging external attention for massive document processing.
InfiAgent further decomposes agent execution into a hierarchical DAG:
- Level 3 (Alpha Agent): Top-level planner decomposing open-ended tasks.
- Level 2 (Domain Agents): Specialists executing domain-specific or workflow steps.
- Level 1 (Atomic/Tool Agents): Fine-grained actors calling tools, web search, file I/O.
This multi-level stack enforces serial invocation and rigid parent-child relationships (Agent-as-a-Tool), suppressing error propagation and tool-calling chaos prevalent in unstructured multi-agent baselines.
A key module is the External Attention Pipeline. Rather than ingesting entire large documents, LLM queries are offloaded to specialized tool subprocesses (e.g., PDF Q&A agents), returning only extracted, relevant information for state integration, thus decoupling external cognition from bounded context.
Empirical Results and Analysis
DeepResearch Benchmark
On the DeepResearch benchmark, InfiAgent (20B model, no task-specific fine-tuning) achieves an overall score of 41.45, competitive with much larger proprietary agents (GPT-4/GPT-5 at 200B-1000B), especially on instruction compliance and structured readability.
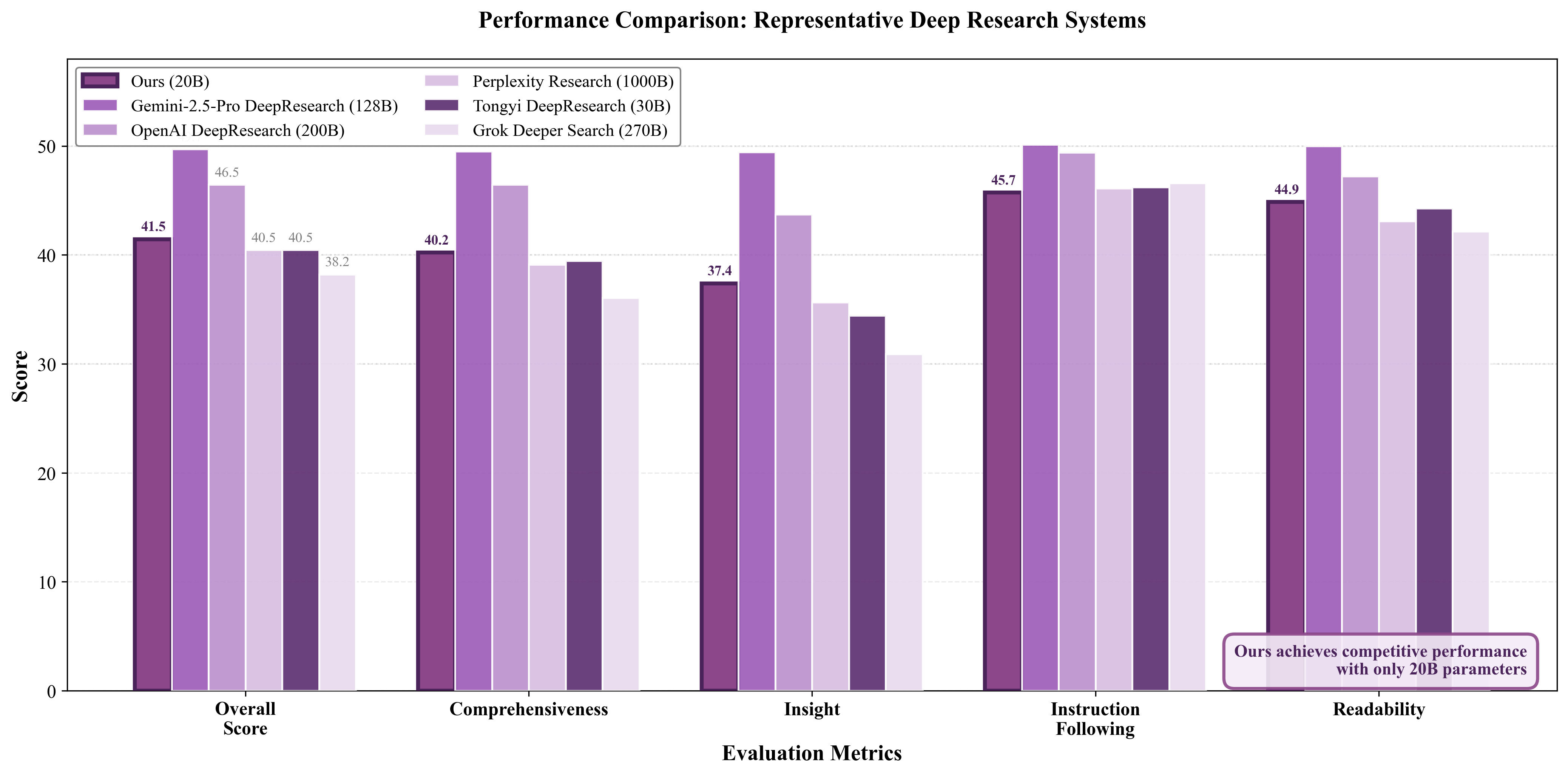
Figure 2: InfiAgent’s component-wise DeepResearch benchmark results emphasize superior instruction-following and output control fidelity.
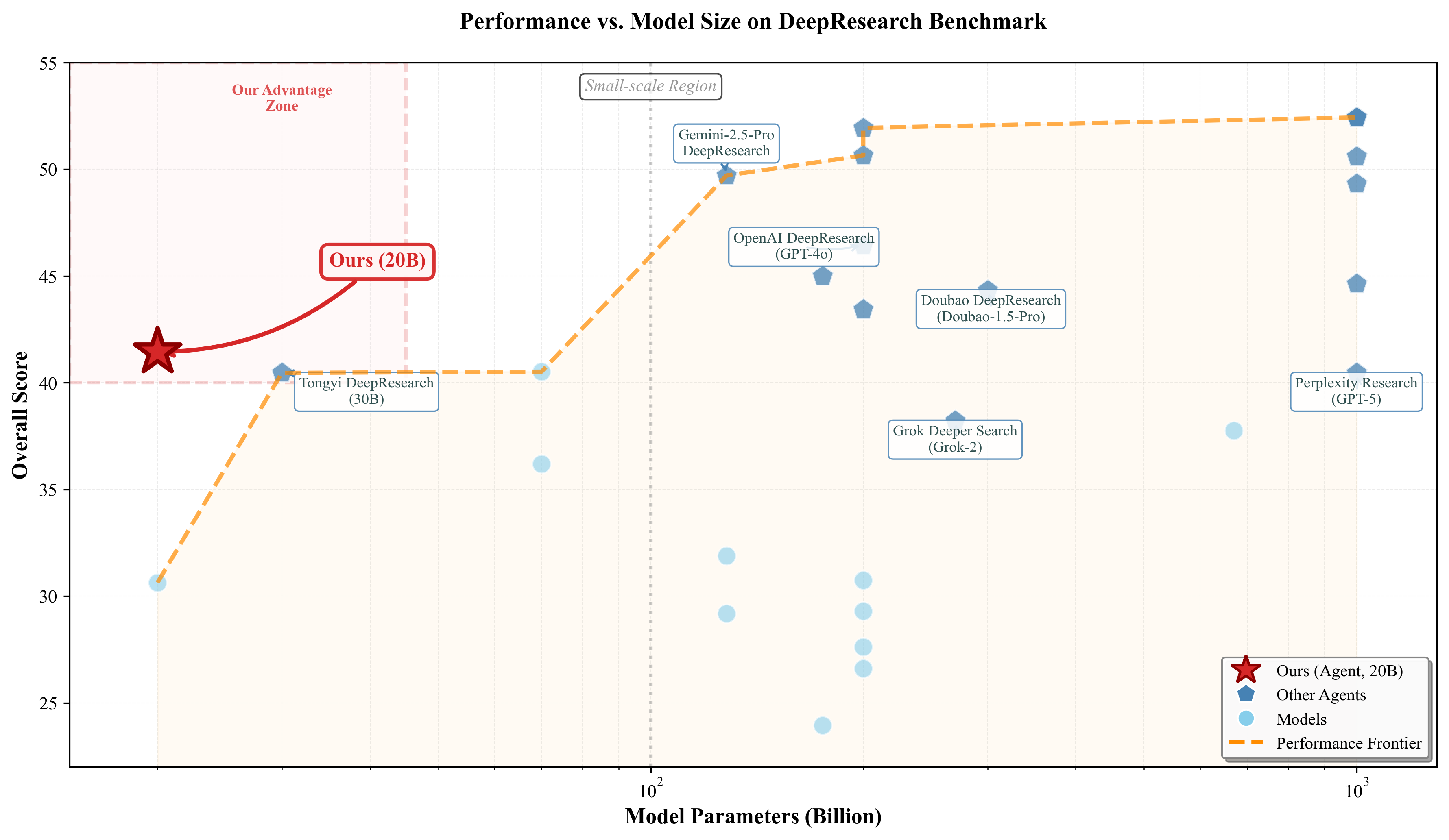
Figure 3: For a fixed backbone size, InfiAgent (20B) achieves state-of-the-art efficiency–performance trade-offs compared to larger closed-source agents.
These results affirm the thesis that improved state management can partially substitute for model scale in complex multi-step tasks. Notably, performance on insight and comprehensiveness is on par with or exceeds several large proprietary systems, directly attributable to stable externalized memory and execution discipline.
Long-Horizon Literature Review
In a task requiring processing 80 academic papers—each needing summary and relevance scoring—InfiAgent attains maximum coverage (80/80) with Gemini/Claude-4.5 and high average coverage (67.1/80) with a 20B model. Conversely, context-centric agents relying on compressed prompts or extended contexts demonstrate catastrophic drops in completion and output fidelity (min coverage often 0–25).
Ablation studies confirm that removing file-centric state, even with strong LLMs, dramatically degrades task persistence and completion reliability. This data substantiates the bold claim that simple context compression is not an effective substitute for persistent state abstraction; explicit file-centric state is critical for long-horizon robustness.
Practical Applications and Blind Review
The framework’s efficacy is further supported by deployment via InfiHelper, a concrete agent instantiation. InfiHelper demonstrates versatility across dry-lab computational biology, logistics workforce planning, and academic research/multi-paper review. Full-length manuscripts generated by InfiHelper were blindly reviewed by conference-standard experts, who evaluated them as human-level, correct, and logically coherent. This affirms the practical viability of the file-centric paradigm for automated rigorous knowledge work.
Discussion
The theoretical implication is the establishment of a new agent design principle: treat persistent task state as a first-class entity, completely decoupled from prompt context. This enables unbounded-horizon reasoning without LLM cognitive overload, and allows systematic state inspection, correction, and review that is infeasible in history-centric architectures.
InfiAgent introduces serial execution and periodic state consolidation, which although robust, may induce latency unsuitable for real-time applications or tasks amenable to parallelism. Hallucination or intermediate reasoning errors from the backbone model are not inherently mitigated; persistent state may simply “persist” faults without parallel validation or self-refinement. Efficiency–robustness trade-off is context-dependent; in high-throughput settings, asynchronous or partially parallel designs remain an open research direction.
Broader impact rests on enabling sustained multi-step reasoning for open-ended, ill-structured domains—autonomous research, scientific discovery, deep tool chains, and collaborative multi-agent systems. Future work should explore automated validation, state correction, adaptive parallelism, and formal verification on top of the file-centric substrate.
Conclusion
InfiAgent decisively demonstrates that explicit externalization of persistent agent state via a file-centric abstraction is sufficient to decouple context window limitations from reasoning horizon. Architecturally, this enables smaller open-source LLMs to achieve parity with or outperform larger, proprietary agents in multi-step research and document-intensive tasks. The framework validates that infinite-horizon, stable, and inspectable agent behavior depends more on memory architecture than on context expansion or raw model scale.
The InfiAgent design paradigm is a step toward truly scalable and robust general-purpose autonomous agents, setting a foundation for principled advances in agentic AI.