Learning to Act without Actions
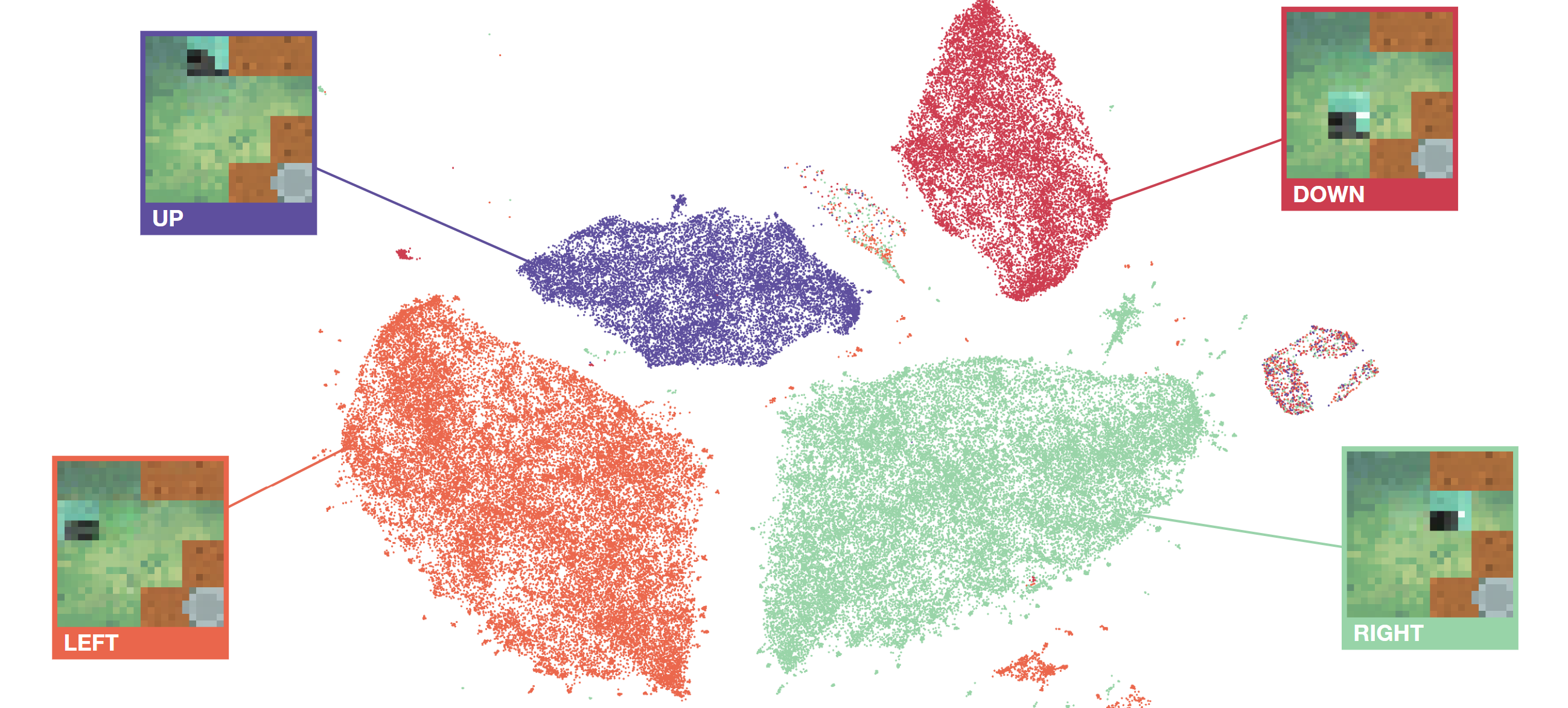
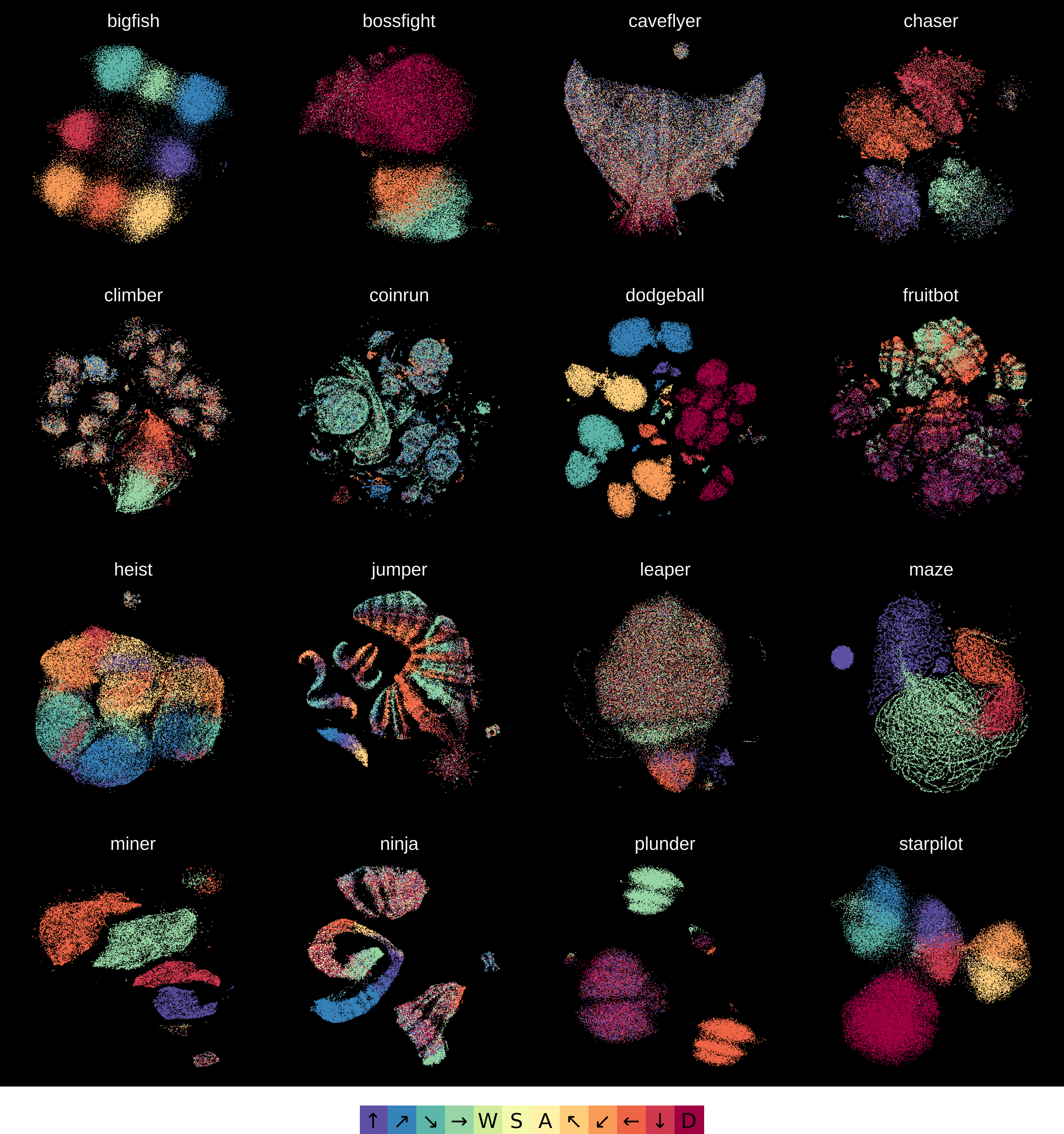
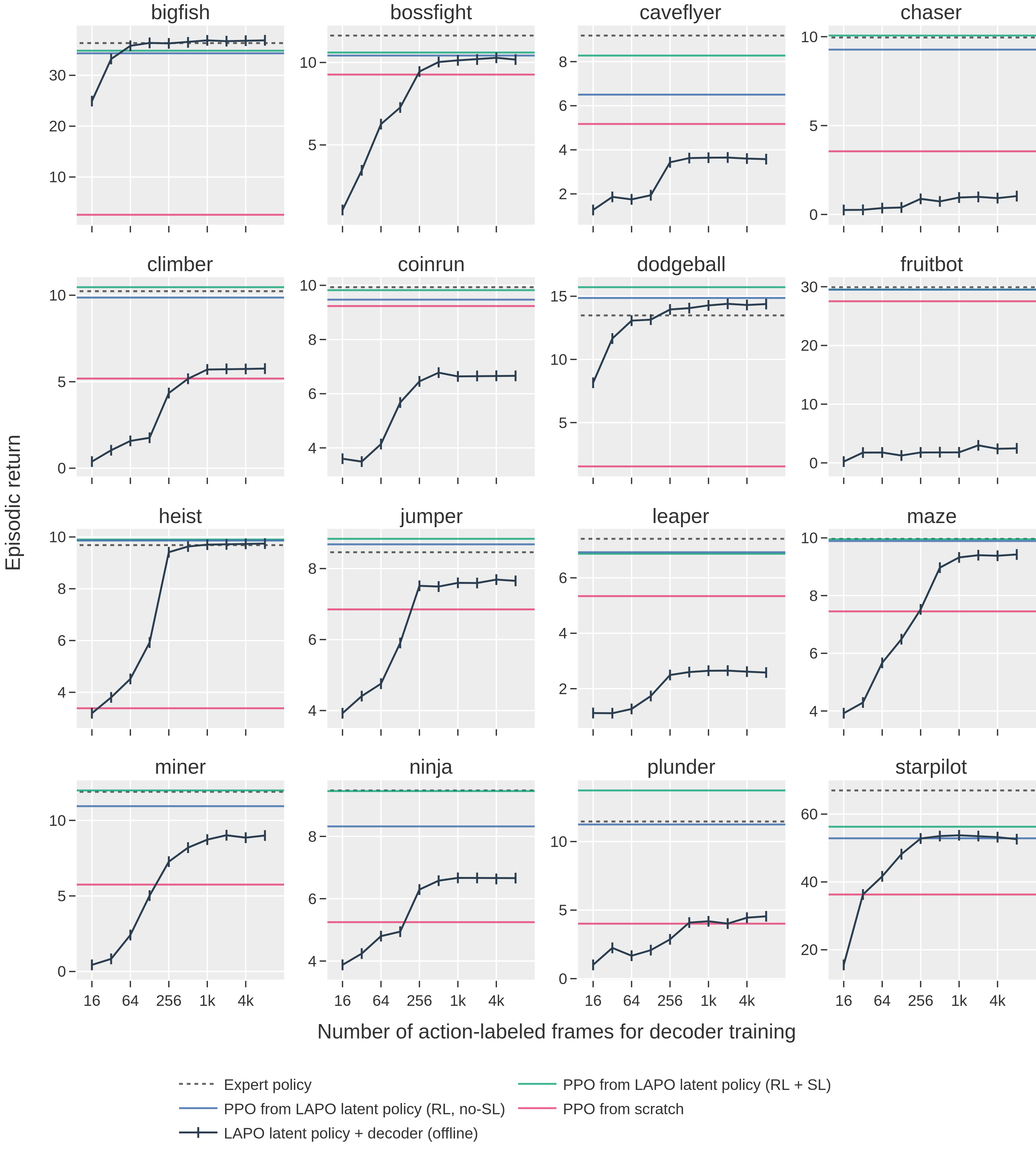
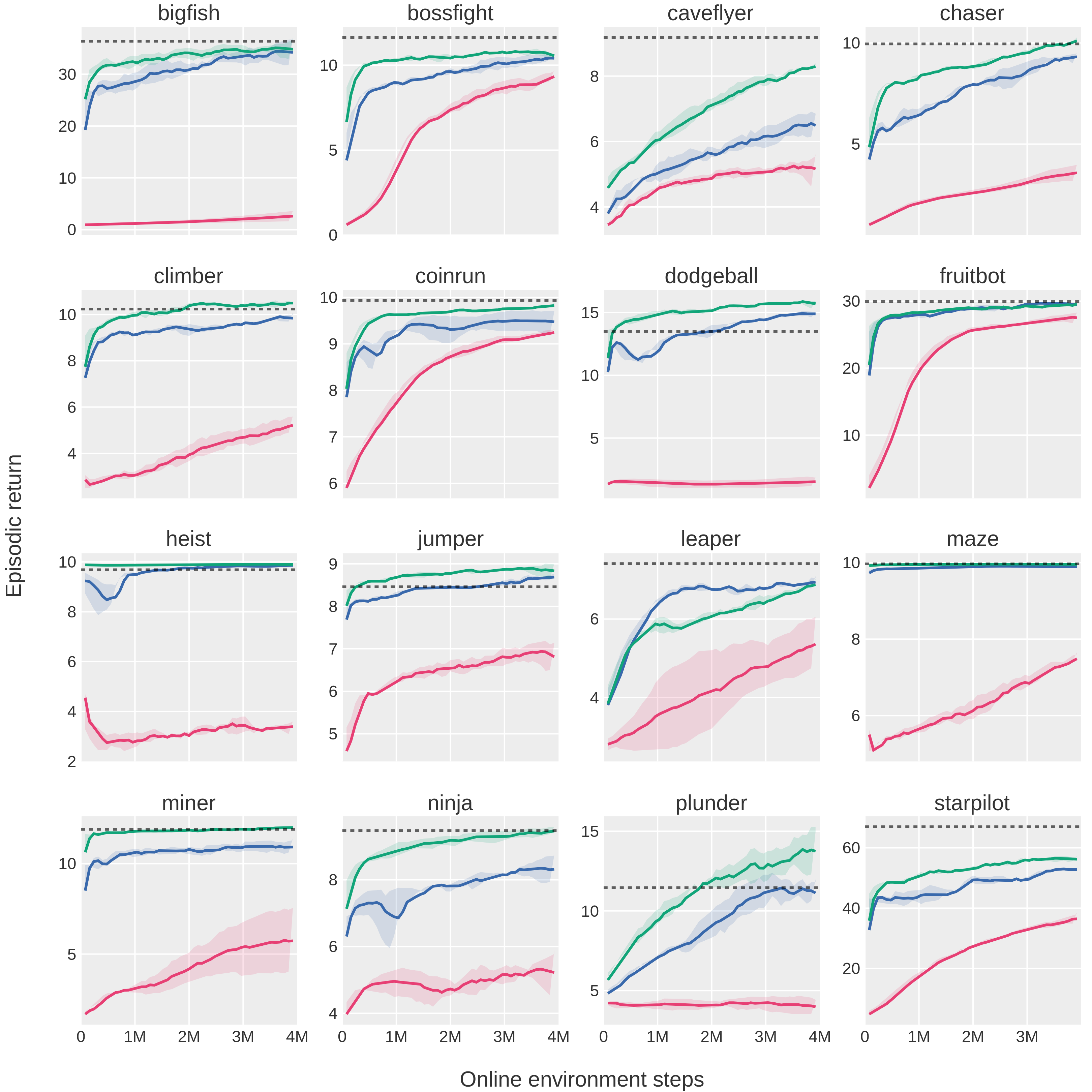
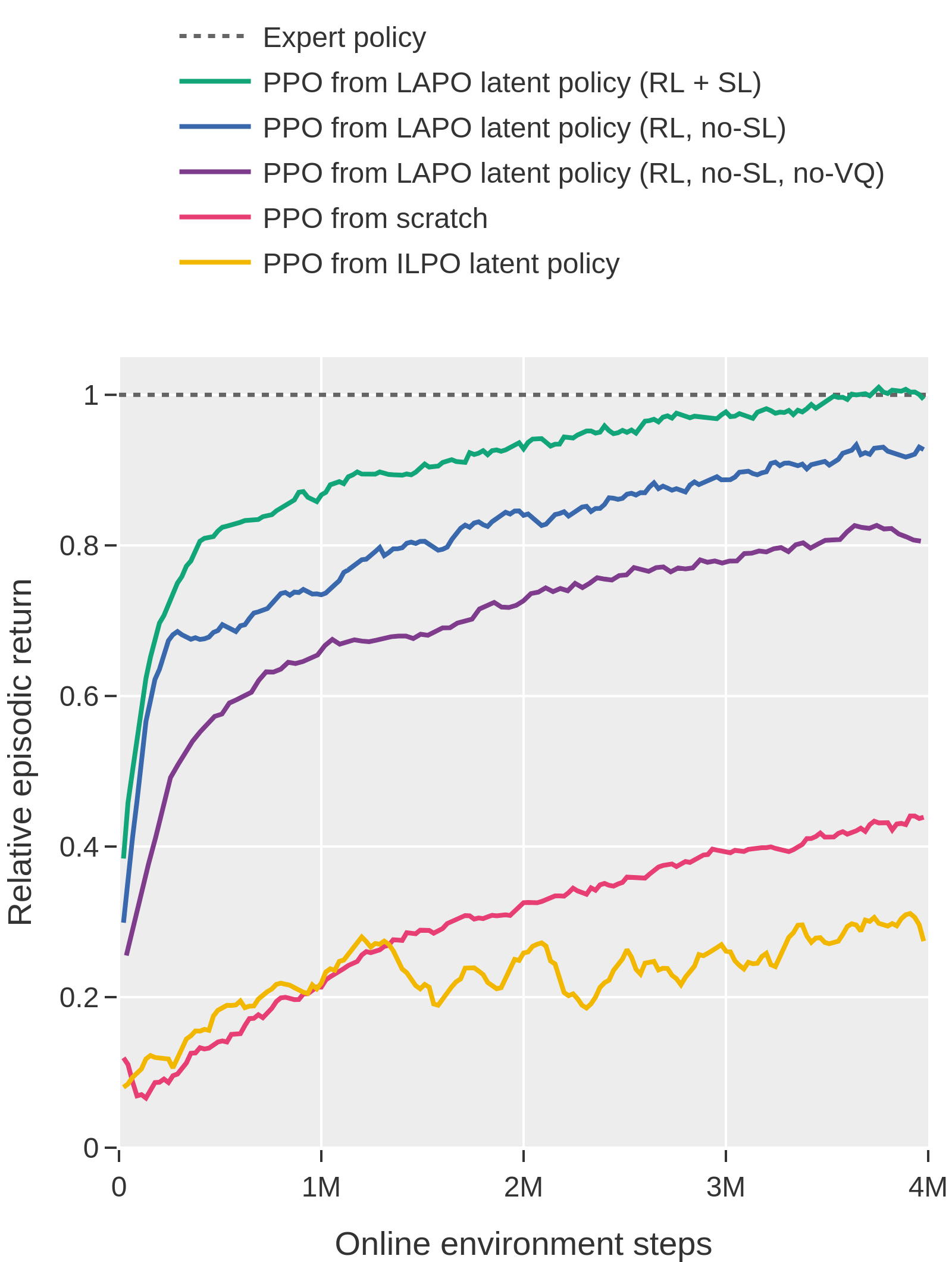
Abstract: Pre-training large models on vast amounts of web data has proven to be an effective approach for obtaining powerful, general models in domains such as language and vision. However, this paradigm has not yet taken hold in reinforcement learning. This is because videos, the most abundant form of embodied behavioral data on the web, lack the action labels required by existing methods for imitating behavior from demonstrations. We introduce Latent Action Policies (LAPO), a method for recovering latent action information, and thereby latent-action policies, world models, and inverse dynamics models, purely from videos. LAPO is the first method able to recover the structure of the true action space just from observed dynamics, even in challenging procedurally-generated environments. LAPO enables training latent-action policies that can be rapidly fine-tuned into expert-level policies, either offline using a small action-labeled dataset, or online with rewards. LAPO takes a first step towards pre-training powerful, generalist policies and world models on the vast amounts of videos readily available on the web.
- Karl Johan Åström. Optimal control of Markov processes with incomplete state information. Journal of Mathematical Analysis and Applications, 10(1):174–205, 1965.
- Playing hard exploration games by watching youtube. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett (eds.), Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pp. 2935–2945, 2018. URL https://proceedings.neurips.cc/paper/2018/hash/35309226eb45ec366ca86a4329a2b7c3-Abstract.html.
- Video pretraining (VPT): learning to act by watching unlabeled online videos. In NeurIPS, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/9c7008aff45b5d8f0973b23e1a22ada0-Abstract-Conference.html.
- The arcade learning environment: An evaluation platform for general agents. Journal of Artificial Intelligence Research, 47:253–279, 2013.
- Estimating or propagating gradients through stochastic neurons for conditional computation. CoRR, abs/1308.3432, 2013. URL http://arxiv.org/abs/1308.3432.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Emerging properties in self-supervised vision transformers. In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pp. 9630–9640. IEEE, 2021. doi: 10.1109/ICCV48922.2021.00951. URL https://doi.org/10.1109/ICCV48922.2021.00951.
- Variational lossy autoencoder. In International Conference on Learning Representations, 2016.
- Quantifying generalization in reinforcement learning. In International Conference on Machine Learning, pp. 1282–1289. PMLR, 2019.
- Leveraging procedural generation to benchmark reinforcement learning. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceedings of Machine Learning Research, pp. 2048–2056. PMLR, 2020. URL http://proceedings.mlr.press/v119/cobbe20a.html.
- Jukebox: A generative model for music. CoRR, abs/2005.00341, 2020. URL https://arxiv.org/abs/2005.00341.
- Imitating latent policies from observation. In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pp. 1755–1763. PMLR, 2019. URL http://proceedings.mlr.press/v97/edwards19a.html.
- IMPALA: scalable distributed deep-rl with importance weighted actor-learner architectures. In Jennifer G. Dy and Andreas Krause (eds.), Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, volume 80 of Proceedings of Machine Learning Research, pp. 1406–1415. PMLR, 2018. URL http://proceedings.mlr.press/v80/espeholt18a.html.
- Reinforcement learning from passive data via latent intentions. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pp. 11321–11339. PMLR, 2023. URL https://proceedings.mlr.press/v202/ghosh23a.html.
- R. Gray. Vector quantization. IEEE ASSP Magazine, 1(2):4–29, 1984. doi: 10.1109/MASSP.1984.1162229.
- Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- Straightening out the straight-through estimator: Overcoming optimization challenges in vector quantized networks. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pp. 14096–14113. PMLR, 2023. URL https://proceedings.mlr.press/v202/huh23a.html.
- Marcus Hutter. On the existence and convergence of computable universal priors. In International Conference on Algorithmic Learning Theory, pp. 298–312. Springer, 2003.
- Planning and acting in partially observable stochastic domains. Artificial intelligence, 101(1-2):99–134, 1998.
- Conservative q-learning for offline reinforcement learning. Advances in Neural Information Processing Systems, 33:1179–1191, 2020.
- Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643, 2020.
- UMAP: uniform manifold approximation and projection for dimension reduction. CoRR, abs/1802.03426, 2018. URL http://arxiv.org/abs/1802.03426.
- Playable video generation. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pp. 10061–10070. Computer Vision Foundation / IEEE, 2021. doi: 10.1109/CVPR46437.2021.00993. URL https://openaccess.thecvf.com/content/CVPR2021/html/Menapace_Playable_Video_Generation_CVPR_2021_paper.html.
- Transformers are sample-efficient world models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/pdf?id=vhFu1Acb0xb.
- Acceleration of stochastic approximation by averaging. SIAM journal on control and optimization, 30(4):838–855, 1992.
- Dean Pomerleau. ALVINN: an autonomous land vehicle in a neural network. In David S. Touretzky (ed.), Advances in Neural Information Processing Systems 1, [NIPS Conference, Denver, Colorado, USA, 1988], pp. 305–313. Morgan Kaufmann, 1988.
- Language models are unsupervised multitask learners. 2019.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PMLR, 2021.
- Zero-shot text-to-image generation. In International Conference on Machine Learning, pp. 8821–8831. PMLR, 2021a.
- Zero-shot text-to-image generation. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 of Proceedings of Machine Learning Research, pp. 8821–8831. PMLR, 2021b. URL http://proceedings.mlr.press/v139/ramesh21a.html.
- A generalist agent. Trans. Mach. Learn. Res., 2022, 2022. URL https://openreview.net/forum?id=1ikK0kHjvj.
- U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pp. 234–241. Springer, 2015.
- Efficient reductions for imitation learning. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pp. 661–668. JMLR Workshop and Conference Proceedings, 2010.
- Reinforcement learning with videos: Combining offline observations with interaction. In Jens Kober, Fabio Ramos, and Claire J. Tomlin (eds.), 4th Conference on Robot Learning, CoRL 2020, 16-18 November 2020, Virtual Event / Cambridge, MA, USA, volume 155 of Proceedings of Machine Learning Research, pp. 339–354. PMLR, 2020. URL https://proceedings.mlr.press/v155/schmeckpeper21a.html.
- Jürgen Schmidhuber. Discovering neural nets with low kolmogorov complexity and high generalization capability. Neural Networks, 10(5):857–873, 1997.
- Proximal policy optimization algorithms. CoRR, abs/1707.06347, 2017. URL http://arxiv.org/abs/1707.06347.
- RJ Solmonoff. A formal theory of inductive inference. i. II Information and Control, 7:224–254, 1964.
- Preventing mode collapse when imitating latent policies from observations, 2023. URL https://openreview.net/forum?id=Mf9fQ0OgMzo.
- Reinforcement learning: An introduction. MIT press, 2018.
- The information bottleneck method. arXiv preprint physics/0004057, 2000.
- Behavioral cloning from observation. In Jérôme Lang (ed.), Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, July 13-19, 2018, Stockholm, Sweden, pp. 4950–4957. ijcai.org, 2018. doi: 10.24963/ijcai.2018/687. URL https://doi.org/10.24963/ijcai.2018/687.
- Recent advances in imitation learning from observation. In Sarit Kraus (ed.), Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, August 10-16, 2019, pp. 6325–6331. ijcai.org, 2019a. doi: 10.24963/ijcai.2019/882. URL https://doi.org/10.24963/ijcai.2019/882.
- Generative adversarial imitation from observation. ICML Workshop on Imitation, Intent, and Interaction (I3), 2019b.
- Neural discrete representation learning. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett (eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 6306–6315, 2017. URL https://proceedings.neurips.cc/paper/2017/hash/7a98af17e63a0ac09ce2e96d03992fbc-Abstract.html.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Imitation learning from observations by minimizing inverse dynamics disagreement. Advances in neural information processing systems, 32, 2019.
- Become a proficient player with limited data through watching pure videos. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/pdf?id=Sy-o2N0hF4f.
- Soundstream: An end-to-end neural audio codec. IEEE ACM Trans. Audio Speech Lang. Process., 30:495–507, 2022. doi: 10.1109/TASLP.2021.3129994. URL https://doi.org/10.1109/TASLP.2021.3129994.
- Learning to drive by watching youtube videos: Action-conditioned contrastive policy pretraining. In Shai Avidan, Gabriel J. Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner (eds.), Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXVI, volume 13686 of Lecture Notes in Computer Science, pp. 111–128. Springer, 2022. doi: 10.1007/978-3-031-19809-0_7. URL https://doi.org/10.1007/978-3-031-19809-0_7.
- Semi-supervised offline reinforcement learning with action-free trajectories. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pp. 42339–42362. PMLR, 2023. URL https://proceedings.mlr.press/v202/zheng23b.html.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.