JARVIS-1: Open-World Multi-task Agents with Memory-Augmented Multimodal Language Models
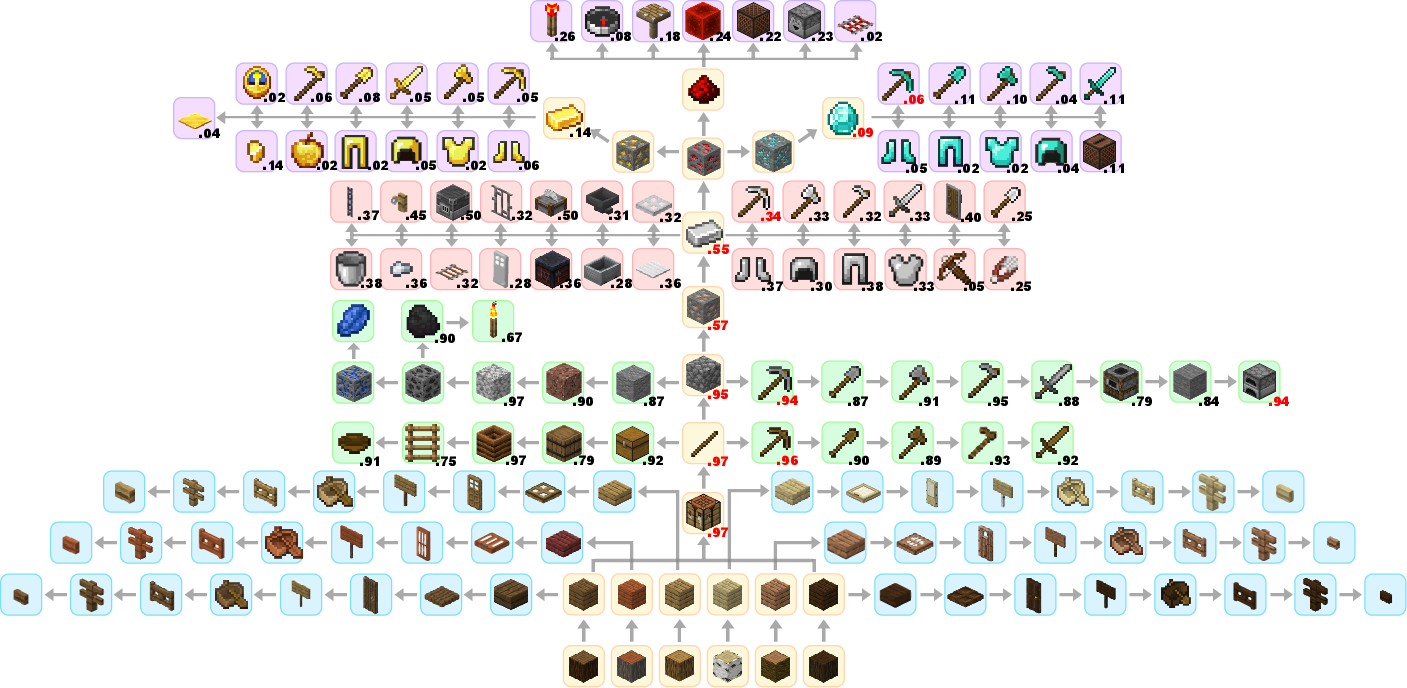
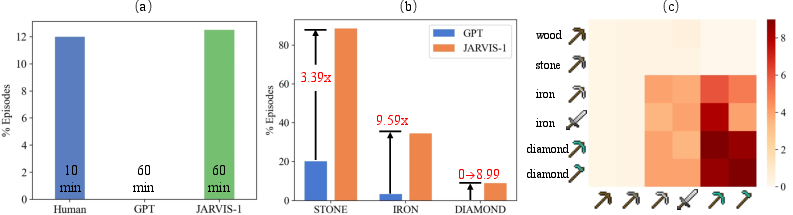
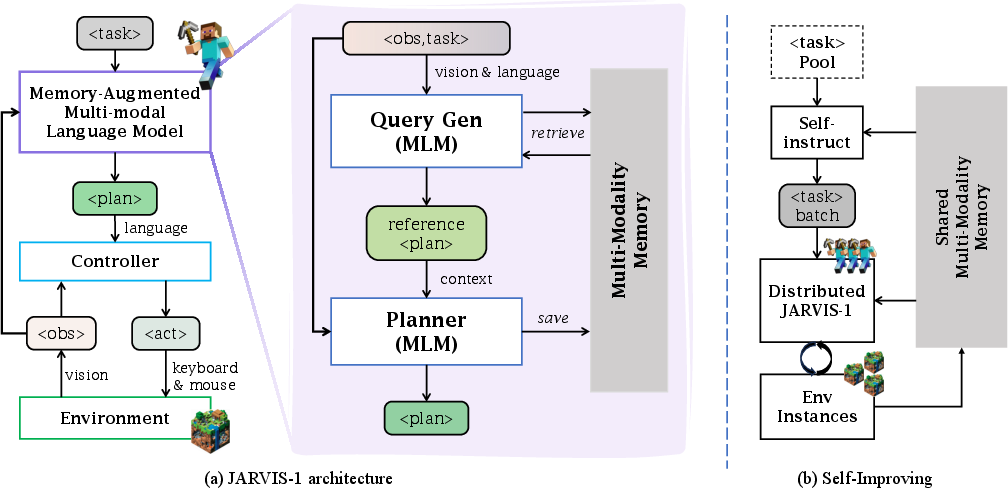
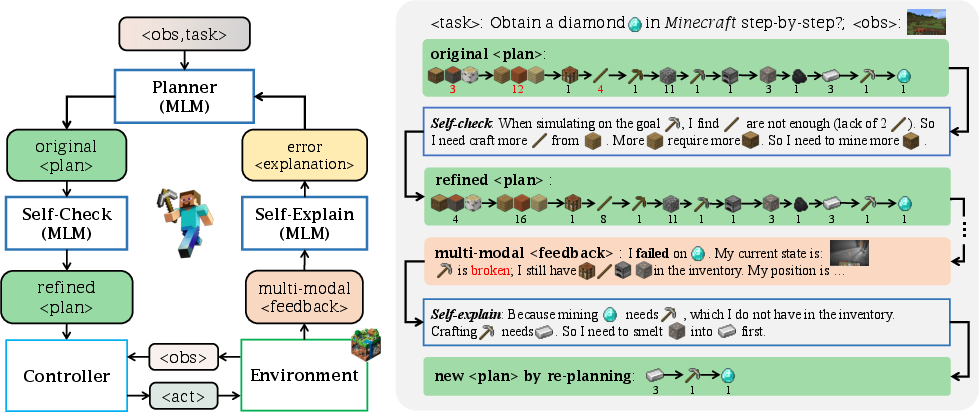
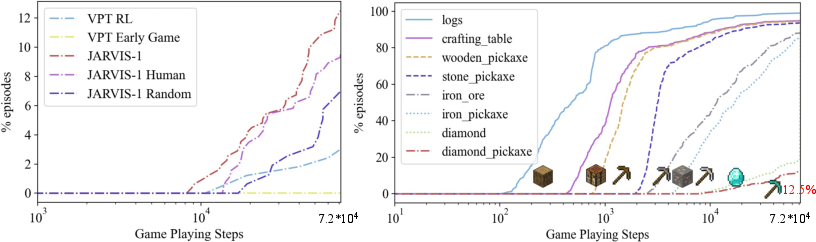
Abstract: Achieving human-like planning and control with multimodal observations in an open world is a key milestone for more functional generalist agents. Existing approaches can handle certain long-horizon tasks in an open world. However, they still struggle when the number of open-world tasks could potentially be infinite and lack the capability to progressively enhance task completion as game time progresses. We introduce JARVIS-1, an open-world agent that can perceive multimodal input (visual observations and human instructions), generate sophisticated plans, and perform embodied control, all within the popular yet challenging open-world Minecraft universe. Specifically, we develop JARVIS-1 on top of pre-trained multimodal LLMs, which map visual observations and textual instructions to plans. The plans will be ultimately dispatched to the goal-conditioned controllers. We outfit JARVIS-1 with a multimodal memory, which facilitates planning using both pre-trained knowledge and its actual game survival experiences. JARVIS-1 is the existing most general agent in Minecraft, capable of completing over 200 different tasks using control and observation space similar to humans. These tasks range from short-horizon tasks, e.g., "chopping trees" to long-horizon tasks, e.g., "obtaining a diamond pickaxe". JARVIS-1 performs exceptionally well in short-horizon tasks, achieving nearly perfect performance. In the classic long-term task of $\texttt{ObtainDiamondPickaxe}$, JARVIS-1 surpasses the reliability of current state-of-the-art agents by 5 times and can successfully complete longer-horizon and more challenging tasks. The project page is available at https://craftjarvis.org/JARVIS-1
- State abstractions for lifelong reinforcement learning. In International Conference on Machine Learning, pages 10–19. PMLR, 2018a.
- Policy and value transfer in lifelong reinforcement learning. In International Conference on Machine Learning, pages 20–29. PMLR, 2018b.
- Flamingo: a visual language model for few-shot learning. arXiv preprint arXiv:2204.14198, 2022.
- Video pretraining (vpt): Learning to act by watching unlabeled online videos. arXiv preprint arXiv:2206.11795, 2022.
- Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022a.
- Do as i can, not as i say: Grounding language in robotic affordances. In 6th Annual Conference on Robot Learning, 2022b.
- Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Open-world multi-task control through goal-aware representation learning and adaptive horizon prediction. arXiv preprint arXiv:2301.10034, 2023a.
- Groot: Learning to follow instructions by watching gameplay videos. arXiv preprint arXiv:2310.08235, 2023b.
- Teaching large language models to self-debug. arXiv preprint arXiv:2304.05128, 2023.
- Collaborating with language models for embodied reasoning. In NeurIPS Foundation Models for Decision Making Workshop, 2022.
- Clip4mc: An rl-friendly vision-language model for minecraft. arXiv preprint arXiv:2303.10571, 2023.
- Minedojo: Building open-ended embodied agents with internet-scale knowledge. Advances in Neural Information Processing Systems Datasets and Benchmarks, 2022.
- Mindagent: Emergent gaming interaction. arXiv preprint arXiv:2309.09971, 2023a.
- Mindagent: Emergent gaming interaction. arXiv preprint arXiv:2309.09971, 2023b.
- Neurips 2019 competition: the minerl competition on sample efficient reinforcement learning using human priors. arXiv preprint arXiv:1904.10079, 2019a.
- Minerl: A large-scale dataset of minecraft demonstrations. arXiv preprint arXiv:1907.13440, 2019b.
- The minerl 2020 competition on sample efficient reinforcement learning using human priors. arXiv: Learning, 2021.
- An embodied generalist agent in 3d world. arXiv preprint arXiv:2311.xxxx, 2023.
- Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. ICML, 2022a.
- Inner monologue: Embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608, 2022b.
- Minerl diamond 2021 competition: Overview, results, and lessons learned. neural information processing systems, 2022.
- Continual training of language models for few-shot learning. arXiv preprint arXiv:2210.05549, 2022a.
- Continual pre-training of language models. In The Eleventh International Conference on Learning Representations, 2022b.
- Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, pages 19274–19286. PMLR, 2023.
- Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- Code as policies: Language model programs for embodied control. arXiv preprint arXiv:2209.07753, 2022.
- Steve-1: A generative model for text-to-behavior in minecraft. arXiv preprint arXiv:2306.00937, 2023.
- Mcu: A task-centric framework for open-ended agent evaluation in minecraft. arXiv preprint arXiv:2310.08367, 2023a.
- Text2motion: From natural language instructions to feasible plans. arXiv preprint arXiv:2303.12153, 2023b.
- Juewu-mc: Playing minecraft with sample-efficient hierarchical reinforcement learning. arXiv preprint arXiv:2112.04907, 2021.
- Llm+ p: Empowering large language models with optimal planning proficiency. arXiv preprint arXiv:2304.11477, 2023.
- Llm as a robotic brain: Unifying egocentric memory and control. arXiv preprint arXiv:2304.09349, 2023.
- Seihai: A sample-efficient hierarchical ai for the minerl competition. In Distributed Artificial Intelligence: Third International Conference, DAI 2021, Shanghai, China, December 17–18, 2021, Proceedings 3, pages 38–51. Springer, 2022.
- Generation-augmented retrieval for open-domain question answering. arXiv preprint arXiv:2009.08553, 2020.
- Augmented language models: a survey. arXiv preprint arXiv:2302.07842, 2023.
- Zero-shot task generalization with multi-task deep reinforcement learning. In International Conference on Machine Learning, pages 2661–2670. PMLR, 2017.
- OpenAI. Gpt-4 technical report, 2023.
- Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155, 2022.
- Generative agents: Interactive simulacra of human behavior. arXiv preprint arXiv:2304.03442, 2023.
- A generalist agent. arXiv preprint arXiv:2205.06175, 2022.
- Reflexion: an autonomous agent with dynamic memory and self-reflection. arXiv preprint arXiv:2303.11366, 2023.
- Progprompt: Generating situated robot task plans using large language models. arXiv preprint arXiv:2209.11302, 2022.
- Adaplanner: Adaptive planning from feedback with language models. arXiv preprint arXiv:2305.16653, 2023.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023a.
- Self-instruct: Aligning language models with self-generated instructions, 2022.
- Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents. arXiv preprint arXiv:2302.01560, 2023b.
- Chain of thought prompting elicits reasoning in large language models. 36th Conference on Neural Information Processing Systems (NeurIPS 2022), 2022.
- Spring: Gpt-4 out-performs rl algorithms by studying papers and reasoning. arXiv preprint arXiv:2305.15486, 2023.
- React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Tree of thoughts: Deliberate problem solving with large language models, 2023.
- Plan4mc: Skill reinforcement learning and planning for open-world minecraft tasks. arXiv preprint arXiv:2303.16563, 2023.
- Socratic models: Composing zero-shot multimodal reasoning with language. arXiv preprint arXiv:2204.00598, 2022.
- Proagent: Building proactive cooperative ai with large language models. arXiv preprint arXiv:2308.11339, 2023.
- W. Zhang and Z. Lu. Rladapter: Bridging large language models to reinforcement learning in open worlds. arXiv preprint arXiv:2309.17176, 2023.
- Mmicl: Empowering vision-language model with multi-modal in-context learning. arXiv preprint arXiv:2309.07915, 2023.
- Ghost in the minecraft: Generally capable agents for open-world enviroments via large language models with text-based knowledge and memory. arXiv preprint arXiv:2305.17144, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.