- The paper introduces LLM-as-a-judge, detailing its innovative approach to evaluating outputs using metrics like relevance, logic, and safety.
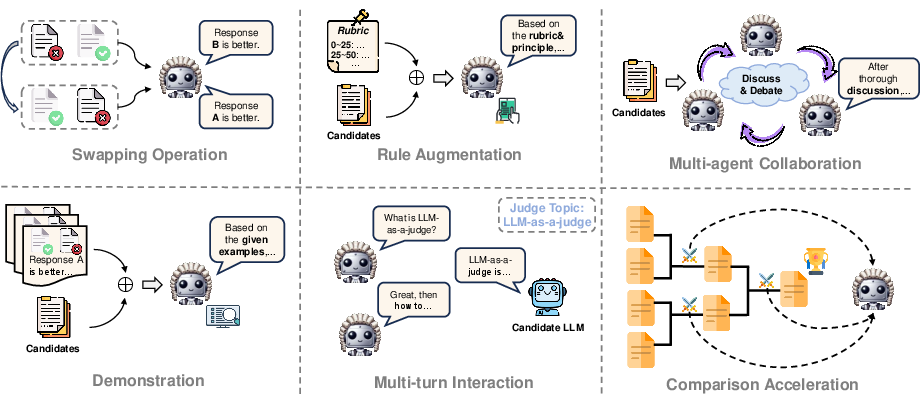
- It outlines tuning and prompting methodologies, including reinforcement learning and multi-turn interactions, to optimize judgment performance.
- The study discusses practical applications in evaluation, alignment, and reasoning while addressing challenges such as bias, scalability, and complexity.
Opportunities and Challenges of LLM-as-a-Judge
The paper "From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge" provides an extensive survey of the emerging paradigm that leverages LLMs for evaluation tasks in artificial intelligence. This approach, termed "LLM-as-a-judge," seeks to utilize the extensive capabilities of LLMs, such as GPT-4, to perform judgmental tasks traditionally handled by smaller models or human evaluations. The paper systematically explores the definitions, methodologies, application scenarios, and future challenges related to this innovative use of LLMs.
Defining LLM-as-a-Judge
LLMs have traditionally been employed to generate content or serve as conversational agents. However, as evaluators, they adopt new roles where they assess candidate outputs by assigning scores, producing rankings, or selecting optimal choices. This is conducted through structured input formats such as point-wise or pair-wise assessments and results in outputs like scoring, ranking, or selection.
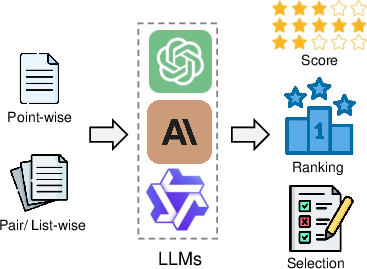
Figure 1: Overview of I/O formats of LLM-as-a-judge.
Attributes of LLM Assessment
A critical section of the paper is dedicated to dissecting the diverse attributes of LLM evaluation. It identifies six key judgments made by LLMs: helpfulness, safety and security, reliability, relevance, logic, and overall quality.
Methodologies for LLM Judgments
The survey outlines several methodologies to enhance LLMs' judgment capabilities, emphasizing the importance of both tuning and prompting strategies.
Applications and Scenarios for LLM-as-a-Judge
The paper explores diverse scenarios where LLM-as-a-judge is applied:
- Evaluation: LLMs evaluate open-ended tasks such as dialogues and creative writing, integrating metrics beyond traditional overlap matching.
- Alignment: Larger LLMs serve as judges to guide smaller models, leveraging self-assessed preference data to improve alignment with human judgments.
- Retrieval: For both traditional and RAG tasks, LLMs are used to rank and select the most pertinent information, enhancing the relevance of retrieved information.
- Reasoning: LLMs help select appropriate reasoning paths and utilization of external tools, effectively allowing models to solve complex, dynamic problems.
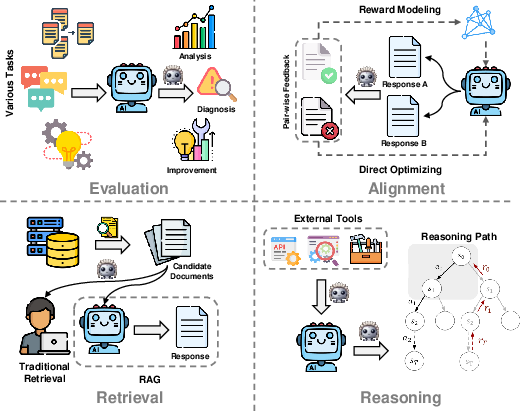
Figure 4: Overview of application and scenario for LLM-as-a-judge.
Challenges and Future Directions
Despite promising applications, the paper highlights several challenges facing LLM-as-a-judge:
- Bias and Vulnerability: Addressing bias is crucial as misalignments can pervasively affect model judgments, necessitating robust mitigation strategies.
- Scalability and Efficiency: Exploring inference-time scaling presents opportunities for optimal resource utilization.
- Complex Judging Strategies: Developing dynamic and adaptive frameworks will enhance judgment accuracy and reliability, laying the groundwork for more intricate evaluation paradigms.
Conclusion
This comprehensive survey posits that while LLM-as-a-judge introduces promising possibilities for enhancing AI evaluation and alignment, it also introduces complex challenges. Addressing these involves meticulous enhancements in methodological frameworks and adaptability to future AI developments. The paper provides valuable insights and guidance for researchers aiming to harness the full potential of LLMs in evaluative contexts.