Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks
Abstract: We introduce enhanced Constitutional Classifiers that deliver production-grade jailbreak robustness with dramatically reduced computational costs and refusal rates compared to previous-generation defenses. Our system combines several key insights. First, we develop exchange classifiers that evaluate model responses in their full conversational context, which addresses vulnerabilities in last-generation systems that examine outputs in isolation. Second, we implement a two-stage classifier cascade where lightweight classifiers screen all traffic and escalate only suspicious exchanges to more expensive classifiers. Third, we train efficient linear probe classifiers and ensemble them with external classifiers to simultaneously improve robustness and reduce computational costs. Together, these techniques yield a production-grade system achieving a 40x computational cost reduction compared to our baseline exchange classifier, while maintaining a 0.05% refusal rate on production traffic. Through extensive red-teaming comprising over 1,700 hours, we demonstrate strong protection against universal jailbreaks -- no attack on this system successfully elicited responses to all eight target queries comparable in detail to an undefended model. Our work establishes Constitutional Classifiers as practical and efficient safeguards for LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making LLMs safer and more reliable by stopping “jailbreaks.” A jailbreak is when someone tricks an AI into giving harmful instructions it should not provide, especially about dangerous topics like chemical, biological, radiological, and nuclear (CBRN) threats. The authors introduce upgraded safety checks, called “Constitutional Classifiers++,” that are both stronger and much cheaper to run. They also keep the number of harmless queries wrongly refused very low.
What questions are the researchers trying to answer?
The paper focuses on four clear questions:
- How can we block clever attacks that hide harmful requests inside long, harmless-looking conversations or code?
- How can we prevent “obfuscated” outputs—answers that look harmless unless you also see the hidden meaning in the prompt?
- Can we keep the defenses strong while making them fast and affordable enough to use in real products?
- Can we use simple, efficient “sensors” inside the AI to detect danger early and route only suspicious cases to heavier checks?
How did they approach the problem?
To make this accessible, think of their system like a good security process at an event.
1) Exchange classifiers: a smart referee watching the whole conversation
- Older systems had two separate checks: one for the user’s prompt and one for the AI’s answer, often in isolation.
- The new “exchange classifier” watches the entire exchange—both the question and the answer—as the answer is being written.
- Analogy: Instead of judging only a single sentence, the referee reads the whole back-and-forth in real time and flags anything that becomes harmful when you see it together.
Why this helps:
- It catches “reconstruction attacks,” where harmful content is split into parts and reassembled during the response.
- It also catches “obfuscation attacks,” where the output uses coded or metaphorical language that only looks safe if you ignore the input.
2) Two-stage cascade: quick screening, then deeper checks when needed
- Stage 1: A fast, lightweight check screens all traffic.
- Stage 2: Only exchanges that look suspicious get escalated to a more careful, more expensive check.
- Analogy: Everyone walks through a quick metal detector first; only the people who trigger it get a thorough bag check.
Why this helps:
- Most conversations are harmless and pass quickly.
- The system saves a lot of compute without sacrificing safety because it spends effort only where it’s needed.
3) Linear probes: tiny “sensors” inside the AI
- A “linear probe” is a very simple detector attached to the AI’s internal signals while it generates text.
- Analogy: It’s like a quick thermometer inside the model that measures if the conversation is trending harmful.
- Two training tricks make these probes reliable:
- Smoothing: Average signals over a short window so one odd word doesn’t cause a false alarm.
- Weighted learning: Focus training on the parts of the sequence that most clearly show harm, instead of punishing harmless beginnings that later turn harmful.
Why this helps:
- Probes are extremely cheap to run and can catch danger early.
- They also notice patterns that bigger external classifiers might miss, so combining them improves accuracy.
4) Testing and measurement: lots of human red-teaming
- The team ran extensive red-teaming: people tried for over 1,700 hours to find strategies that trick the AI into harmful answers.
- They used a consistent way to score if responses were actually dangerous, and they tuned the system to keep false refusals very low on real user traffic.
What did they find?
Here are the main results, explained simply:
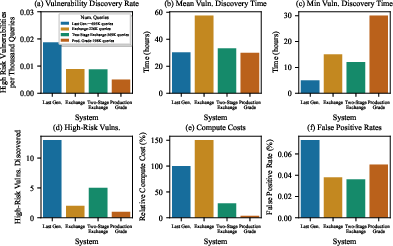
- Exchange classifiers are tougher:
- They found fewer serious vulnerabilities than the older “input + output-only” approach.
- But this single exchange classifier cost about 50% more compute than the old system.
- Two-stage cascades keep strength and cut cost:
- The cascade matched the exchange classifier’s robustness.
- It reduced compute cost by about 5.4x compared to the single exchange classifier.
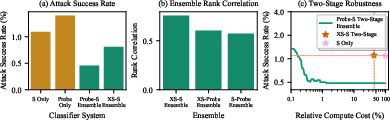
- Linear probes are cheap and surprisingly strong:
- Well-trained probes almost matched small external classifiers at a tiny fraction of the cost.
- Using both together (ensemble) worked best: the probe and the external classifier made different mistakes, so combining them was more robust.
- With smart routing, they could get strong protection while cutting compute massively.
- Production-grade system (the final design):
- First stage: a lightweight linear probe monitors everything.
- Second stage: if the probe is concerned, escalate to a stronger classifier; combine both scores to decide.
- In a real-world shadow deployment:
- Only 0.05% of queries were refused (very low).
- About 5.5% of traffic needed the second-stage check.
- Compute cost dropped by roughly 40x compared to using a single heavy exchange classifier, and about 8x versus the earlier two-stage system.
- In 1,736 hours of red-teaming, no one found a “universal jailbreak” that could consistently get detailed harmful answers to all target questions.
A small summary table of headline metrics
| System | Robustness (fewer is better) | Compute overhead vs old | Refusal rate on production |
|---|---|---|---|
| Old dual-classifier | Higher vulnerabilities | Baseline (100%) | 0.073% |
| Exchange classifier | Lower vulnerabilities | 150% | 0.038% |
| Two-stage cascade | Same as exchange | 27.8% | 0.036% |
| Production-grade (final) | Lowest vulnerabilities | 3.5% | 0.050% |
Note: “Robustness” here refers to how often red-teamers found high-risk jailbreaks; lower is better.
Why is this important?
- Stronger safety against evolving attacks: Attackers are clever and keep inventing new tricks. Watching the full conversation in real time shuts down many strategies at once.
- Practical for real products: Defenses that are too slow or too costly won’t be used. This system keeps costs low and avoids rejecting lots of harmless queries.
- Better protection for high-risk areas: CBRN-related harm is serious. Strong defenses reduce the chance of dangerous misuse.
What could this change in the future?
- Safer LLMs at scale: Companies can deploy strong safeguards widely without slowing everything down or spending too much.
- Smarter, integrated safety: Future models could use these safety signals directly during generation—steering themselves away from harm in real time.
- Better training and data: Using automated red-teaming and more realistic datasets could make classifiers even sharper, further reducing false alarms while keeping protection strong.
Overall, the paper shows how to build a safety system that’s both tough and efficient, making it more likely that advanced AI systems can be used responsibly in the real world.
Knowledge Gaps
Below is a single, concrete list of the paper’s knowledge gaps, limitations, and open questions that future work could address.
- Generalization beyond CBRN: The system’s constitutions, training data, and evaluations target CBRN; robustness to other high-risk domains (e.g., cyber offense, fraud, harassment, misinformation, privacy/copyright, self-harm) is untested.
- Multimodal coverage: The approach is evaluated on text-only exchanges; performance on image, audio, code attachments, file uploads, and tool outputs (e.g., browsing, code execution) is not assessed.
- Cross-lingual robustness: No evaluation across languages, dialects, or code-switching; resilience to non-English obfuscations and multilingual adversarial prompts is unknown.
- Leakage before blocking: The system treats “any flag during streaming” as a defense success; it does not quantify how many harmful tokens can be emitted prior to flagging or the latency to block under EMA/SWiM smoothing.
- Long-context behavior: Static analyses truncate to 20K tokens; robustness and blocking latency under extremely long or multi-session contexts remain unmeasured.
- Automated/adaptive attacker evaluation: Aside from anecdotal expert reports, there is no systematic test against automated, optimization-based jailbreak search or tool-assisted adaptive attacks (e.g., gradient-guided prompt manipulation).
- Formal guarantees: The paper provides empirical robustness but no formal or certified guarantees (e.g., worst-case bounds on harmful token leakage or provable detection for specified attack classes).
- Evaluation dependence on LLM graders: LLM-based rubric grading may be biased or fail under obfuscation; human-grounded evaluations or grader-robustness checks are not provided.
- Representativeness of calibration data: Classifier thresholds are calibrated on WildChat (and one month of production traffic); the representativeness and stability of these sources under domain drift are not demonstrated.
- Helpfulness–safety trade-offs: Beyond refusal rates, impacts on benign helpfulness (precision/recall curves, false positive analyses across benign categories) are not quantified.
- Latency impact: Compute overhead reductions are emphasized, but user-perceived latency from streaming probes/cascades (and escalation) is not measured.
- Robustness to model updates: Probes rely on model-internal activations; stability when the base model is updated (version changes, fine-tuning, quantization) and the need for retraining/recalibration are not analyzed.
- Adversarial activation manipulation: Attacks that aim to steer internal activations to mislead probes (e.g., activation-targeted obfuscation) are not studied; defenses against such attacks are unspecified.
- Sensitivity to probe hyperparameters: The choice of SWiM window size (M=16), EMA configuration, and softmax temperature (τ=1) lacks comprehensive sensitivity analysis across tasks and contexts.
- Exchange-classifier training: The exchange classifier is repurposed from an input classifier without dedicated exchange-specific training; whether tailored exchange training or architectures could materially improve robustness remains open.
- Defense-in-depth layering: Combining exchange classifiers with output-only classifiers for layered defense is mentioned but not evaluated; interactions and gains from multi-monitor ensembles remain unexplored.
- Ensemble generalization risk: Ensemble weights are tuned to minimize attack success on the test set; out-of-sample generalization and overfitting risks (including distribution shift) are not assessed.
- Token-level decision rationale: The system does not provide interpretable evidence or token-level rationales for flags; tooling to support analyst/debug workflows (and reduce false positives) is absent.
- Tool-calling safety: How monitors intercept or evaluate tool outputs (e.g., code run results, retrieved documents) in real time is unspecified; potential harmful content via tools may bypass current classifiers.
- Privacy and policy considerations: Continuous evaluation of full conversational context raises privacy, data retention, and policy transparency questions; user messaging and data governance are not detailed.
- Attacker knowledge of monitors: The paper does not analyze how public knowledge of cascade/probe behavior (e.g., smoothing and thresholds) might enable evasion strategies tuned to the monitors.
- Robustness across obfuscation taxonomies: Beyond reconstruction and metaphor/riddle obfuscation, broader obfuscations (encoding layers, whitespace/noise patterns, templated indirection, role-play indirection) are not systematically covered.
- Cost accounting clarity: Relative compute reductions are reported, but absolute per-token and per-exchange costs (and cost under different escalation rates/traffic mixes) are not disclosed, limiting operational planning.
- Token throttling and partial refusal: The system’s decision semantics (escalation vs. immediate refusal vs. throttling) and their effects on content leakage are not characterized or benchmarked.
- Production horizon and drift: Shadow deployment covers ~1 month; long-term performance under evolving user behavior, seasonal traffic, and emergent attack trends is unknown.
- Data and reproducibility: Training data (synthetic and distilled soft labels), red-teaming datasets, and evaluation pipelines are not released; reproducibility and external validation are limited.
- Robustness under chain-of-thought and tool-enabled reasoning: Attacks that entangle harmful content in intermediate reasoning or tool outputs (e.g., hidden steps, external memory) are not specifically evaluated.
- Transfer to other model families: Generalization of probe/classifier methods to different architectures/scales (open-source LLMs, multilingual/multimodal models) is not demonstrated.
- Calibration under safety-critical operations: Thresholding strategies (fixed 0.55/0.45 logit weights, escalation at 5.5%) are static; adaptive calibration under varying risk levels or per-domain policies is not explored.
- Universal jailbreak claim scope: While no universal jailbreak was found in ~1,700 hours for the production-grade system, the paper acknowledges universal jailbreaks against earlier systems by external experts; whether more automation or time could find one remains open.
- Capability degradation quantification: The GPQA tests show capability drops under two attacks; broader impacts on non-safety benchmarks, user tasks, and scientific queries across diverse domains are not measured.
- Streaming window limitations: SWiM/EMA smoothing can reduce spurious flags but may miss sparse or delayed harms; detection of “slow-ramp” attacks that keep probe scores below thresholds until late-stage harm is not characterized.
- Dynamic routing policies: The cascade uses fixed thresholds; learning-based or risk-aware routing (confidence-based deferral, context-aware gating) is not investigated.
- Failure mode taxonomy and coverage: A comprehensive taxonomy linking failure modes to specific mitigations (and measured coverage) is not provided; systematic coverage analysis (e.g., by attack class and obfuscation strategy) is missing.
Practical Applications
Immediate Applications
Below is a concise set of actionable, real-world uses that can be deployed now, grounded in the paper’s findings on exchange classifiers, cascaded monitoring, linear probes with SWiM logit smoothing and softmax-weighted loss, and probe–classifier ensembling.
- Production LLM safety guardrails for consumer and enterprise chat assistants
- Sector: Software platforms, cloud AI providers
- Tools/Workflow: Deploy a two-stage exchange-monitoring cascade (linear probe streams all tokens; escalate suspicious exchanges to an external classifier; combine logits for final decisions) with thresholds calibrated to target refusal rates (e.g., ~0.05–0.1%).
- Dependencies/Assumptions: Access to model activations (for probes), robust calibration data representative of production traffic, and operating SLAs for latency/compute.
- Cost-optimized content moderation for AI APIs
- Sector: Cloud AI, developer tooling
- Tools/Workflow: Integrate a lightweight first-stage probe-router that escalates only flagged traffic to a small classifier; exploit cascade routing to achieve >5x–40x compute savings while holding robustness and low refusal rates.
- Dependencies/Assumptions: Stable telemetry to tune probe thresholds; monitoring to prevent drift; support for streaming token-level evaluation.
- Enterprise AI governance dashboards and safety SLAs
- Sector: Enterprise compliance, risk management
- Tools/Workflow: Track flag/refusal rates, escalation rates, vulnerability discovery rate, and minimum discovery-time metrics; use rubric-based assessments for audits; expose safety SLAs to customers.
- Dependencies/Assumptions: Red-teaming pipeline and evaluation rubrics; access to aggregated logs with privacy controls; buy-in from governance teams.
- Obfuscation-aware filters for education and parental control settings
- Sector: Education technology, consumer safety
- Tools/Workflow: Enable “Safety Mode” that evaluates outputs in-context (exchange classifiers) to catch metaphor-coded or ciphered harmful requests; provide user-facing explanations for flags.
- Dependencies/Assumptions: Constitutions aligned to school/parental policies; appropriate UX to avoid overrefusal; localized content support.
- Biosecurity-aware assistance for scientific and lab workflows
- Sector: Healthcare, biotech, chemical labs
- Tools/Workflow: Guard domain-specific assistant interactions (CBRN constitutions) using exchange classifiers; route sensitive content to an expert review queue when flagged.
- Dependencies/Assumptions: Domain-adapted constitutions and datasets; privacy and compliance (HIPAA, BSL policies); human-in-the-loop escalation.
- Code assistants and repositories with reconstruction attack detection
- Sector: Software development, dev platforms
- Tools/Workflow: Scan code contexts for fragmented harmful instructions (e.g., function-return reconstruction) during generation; refuse or sandbox dangerous outputs.
- Dependencies/Assumptions: Access to full conversational/code context; rules to distinguish legitimate obfuscation (e.g., encoding) from covert harmful reconstruction.
- Agentic task execution guards (tool calling and automation)
- Sector: Robotics, RPA, AI agents
- Tools/Workflow: Gate tool calls when probe-classifier ensembles flag risk; require human approval or safer alternatives; log escalations for audit.
- Dependencies/Assumptions: Integration with agent frameworks; fine-grained tool policy; latency budgets that tolerate escalation.
- Platform moderation and community support desks
- Sector: Social platforms, Q&A sites, customer support
- Tools/Workflow: Exchange-level scoring for posts/replies generated by LLMs; cheap first-stage screening for all traffic, with second-stage review for flagged cases; reviewer assist via rubric scoring.
- Dependencies/Assumptions: Clear policies; annotated datasets; workflows for reviewer override and appeal.
- Financial AI copilots with obfuscation-resistant fraud guards
- Sector: Finance, fintech, compliance
- Tools/Workflow: Detect metaphor-coded or transformed instructions that aim to bypass controls (e.g., “winter’s breath” mapping); escalate to compliance checks; log risk scores.
- Dependencies/Assumptions: Domain-aligned constitutions (AML/KYC); strong thresholds to avoid false positives that block legitimate advice; audit trails.
- Mobile and edge on-device assistants using linear probes
- Sector: Consumer devices, IoT
- Tools/Workflow: Use ultra-low-cost all-layer linear probes for streaming moderation on device; optionally escalate to cloud classifiers only when needed.
- Dependencies/Assumptions: On-device access to activations; privacy constraints; fallback to cloud when local resources are insufficient.
- Red-teaming program adoption (metrics and bounty design)
- Sector: Security, research operations
- Tools/Workflow: Use rubric-based harmfulness grading, vulnerability discovery rate, and minimum discovery time; standardize bounty incentives for universal jailbreak discovery.
- Dependencies/Assumptions: Expert testers, standardized datasets, guidance for reporting and reproducibility.
- Regulatory and audit-ready reporting of defense performance
- Sector: Policy, standards, compliance
- Tools/Workflow: Provide regulator-facing summaries of refusal rates, robustness under red-teaming, and compute overhead; demonstrate adaptive cascades that minimize false positives.
- Dependencies/Assumptions: Accepted benchmarks/rubrics; independent audit capability; legal frameworks recognizing such metrics.
Long-Term Applications
These uses will benefit from further research, scaling, integration into training, broader domain coverage, or standardization.
- Safety-in-the-sampler: integrating classifier signals directly into decoding and training
- Sector: Core AI R&D, model training
- Tools/Workflow: Inject probe/classifier scores into sampling policies (e.g., logit masking), reinforcement learning with safety constraints, or latent adversarial training.
- Dependencies/Assumptions: Joint training access; careful trade-offs between capability and safety; robustness to adversarial adaptation.
- Multi-modal exchange classifiers (text, image, audio, code, video)
- Sector: Media platforms, vision/audio assistants
- Tools/Workflow: Extend probes and cascades to multi-modal activations; detect cross-modal obfuscations and reconstructions.
- Dependencies/Assumptions: Access to multi-modal model internals; large-scale annotated multi-modal safety corpora.
- Black-box-compatible guards via distillation or shadow models
- Sector: Third-party API integrations
- Tools/Workflow: Distill internal probe signals into a small external classifier that operates without activation access; use shadow LLMs to emulate exchange judgments.
- Dependencies/Assumptions: High-quality distillation data; stable model behavior; acceptance of weaker real-time guarantees.
- Standardized jailbreak robustness certifications and benchmarks
- Sector: Policy, accreditation, procurement
- Tools/Workflow: Formalize “universal jailbreak” tests, rubric thresholds, discovery-rate metrics; certify systems that meet specified robustness and refusal targets.
- Dependencies/Assumptions: Multi-stakeholder standard-setting; reference datasets; accredited auditors.
- Automated red-teaming agents and simulation frameworks
- Sector: Safety research, tooling vendors
- Tools/Workflow: Self-play or agent swarms to discover obfuscations/reconstructions; continuous training data generation; adaptive countermeasure testing.
- Dependencies/Assumptions: Safe containment; compute budgets; evaluation fidelity to real-world traffic.
- Domain expansion beyond CBRN: medical misinformation, cybersecurity exploitation, extremist content, financial manipulation
- Sector: Healthcare, cybersecurity, content platforms, finance
- Tools/Workflow: Author new constitutions and datasets per domain; re-calibrate cascades; domain-specific rubrics for harmfulness.
- Dependencies/Assumptions: Expert curation; stakeholder-defined boundaries; continuous update against emerging threats.
- Fleet-wide safety routers and dynamic compute allocation
- Sector: Cloud platforms, model orchestration
- Tools/Workflow: Global routers that adapt thresholds across model fleets; confidence-based deferral; cascading to larger models only when necessary.
- Dependencies/Assumptions: Cross-model compatibility; latency/throughput management; robust routing metrics.
- Privacy-preserving and secure-enclave probes
- Sector: Regulated industries, privacy tech
- Tools/Workflow: Run probes in TEEs or use encrypted computation; minimize exposure of activations while maintaining real-time safety.
- Dependencies/Assumptions: Hardware support; performance overhead acceptable; cryptographic protocol maturity.
- Hardware acceleration for activation probing
- Sector: Semiconductors, edge AI
- Tools/Workflow: Design kernels or co-processors optimized for all-layer probe inference; reduce energy and latency for streaming moderation.
- Dependencies/Assumptions: Hardware–software co-design; market demand; standard probe interfaces.
- User-level adaptive safety with fairness constraints
- Sector: Platforms, enterprise AI
- Tools/Workflow: Adaptive thresholds based on contextual risk; fairness-aware calibration to avoid disparate impact; explainable flagging.
- Dependencies/Assumptions: Policy clarity, privacy-preserving personalization, guardrails against misuse.
- Tool-calling governance and action-level verification
- Sector: Agent ecosystems, DevOps, operations
- Tools/Workflow: Combine exchange classifiers with policy engines to gate file writes, code execution, purchases; verify safe plans before tool invocation.
- Dependencies/Assumptions: Standard action schemas; robust plan analysis; human oversight channels.
- Formal robustness analysis and guarantees
- Sector: Academia, high-assurance systems
- Tools/Workflow: Theoretical bounds for streaming classifiers under obfuscation/reconstruction; adversarial training regimes with provable properties.
- Dependencies/Assumptions: New theory; tractable assumptions; testbeds linking formal results to practice.
- Sector-specific certifications (e.g., nuclear/biolab AI assistant safety)
- Sector: Energy, biotech, chemical safety
- Tools/Workflow: Tailored audits and certification protocols using exchange cascades; incident response procedures with escalation logs.
- Dependencies/Assumptions: Regulator partnership; domain rubrics; training and ongoing monitoring programs.
Notes on Assumptions and Dependencies (cross-cutting)
- Access to model internals: Many immediate applications rely on activation probes; black-box models may require distillation or external classifiers.
- Calibration quality: Low refusal rates with robust detection depend on representative benign traffic and high-quality thresholds; drift monitoring is essential.
- Red-teaming coverage: Robustness claims hinge on active discovery programs and rubric consistency; automation helps but needs human oversight.
- Privacy and compliance: Streaming, logging, and escalation must respect data protection laws and platform policies.
- Latency/compute budgets: Cascades and streaming probes must meet product SLAs; savings are realized when routing is tuned and escalation rates stay low.
- Domain constitutions and training data: Extending to new harm areas requires expert-crafted policies and datasets; periodic updates are necessary.
Glossary
- Ablation studies: Targeted experiments that remove or vary components to understand their contribution to performance. "which our ablation studies show is crucial for performance."
- Adaptive computation: A design where the amount of compute used depends on input complexity. "This scheme represents a form of adaptive computation, where classification cost depends on input complexity."
- All-layer probe: A linear probe that concatenates activations from all layers of a model for classification. "Consider an all-layer probe on Gemma 3 27B"
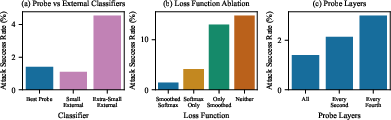
- Attack success rate: The proportion of jailbreak attempts that bypass defenses and produce harmful outputs. "The probe achieves an attack success rate that outperforms the extra-small classifier"
- Base64 encoding: A text-based encoding scheme often used for obfuscation by attackers. "e.g., base64 encoding."
- Binary cross-entropy loss: A standard loss function for binary classification measuring the error between predicted probabilities and true labels. "binary cross-entropy loss"
- CBRN: An acronym for chemical, biological, radiological, and nuclear. "CBRN-related"
- Confidence-based deferral: A cascade strategy that defers inputs to stronger models based on confidence thresholds. "refined cascades through confidence-based deferral"
- Constitutional Classifiers: Safety classifiers guided by a predefined constitution of rules to detect and block harmful content. "Constitutional Classifiers are a promising approach for defending LLMs against jailbreak attempts"
- Compute-robustness tradeoff: The balance between computational cost and defensive effectiveness. "Compute-robustness tradeoff curves for two-stage configurations."
- Defense-in-depth: A strategy that layers multiple defenses to improve robustness against attacks. "complement an output-only classifier for defense-in-depth"
- Distilling with soft-labels: Training a model using probabilistic labels from another model rather than hard labels. "We found either distilling with soft-labels or using hard labels from our synthetic data pipeline leads to similar performance."
- Exponential moving average (EMA): A streaming method that averages scores over time with exponentially decaying weights. "During inference, we use an exponential moving average (EMA) instead of a sliding window mean"
- Ensemble methods: Combining multiple models or classifiers to improve accuracy and robustness. "Indeed, ensemble methods have a long history in machine learning at improving performance and robustness"
- Exchange classifier: A classifier that evaluates outputs in the context of their corresponding inputs over the full conversation. "we develop exchange classifiers that evaluate model responses in their full conversational context"
- Exchange-level labels: Labels that reflect the harmfulness of the entire conversation exchange rather than individual tokens. "Crucially, these labels are exchange-level labels"
- FLOPs: Floating-point operations, a measure of computational cost. "377K FLOPs per token."
- Forward pass: A single inference step through a model to compute outputs from inputs. "a single forward pass for one token through Gemma 3 4B"
- GPQA Diamond: A challenging benchmark for graduate-level question answering. "We test Claude Opus 4 on GPQA Diamond"
- Internals-based classifiers: Classifiers that operate directly on model internal activations rather than external text. "explore internals-based classifiers, focusing on last-N layer networks"
- Jailbreak attempts: Prompting strategies that try to circumvent safeguards to elicit harmful information. "defending LLMs against jailbreak attempts"
- Latent adversarial training: Training methods that use internal representations to defend against unforeseen failure modes. "latent adversarial training"
- Linear activation probes: Lightweight linear models trained on internal activations to classify harmfulness. "we use linear activation probes"
- LLM-based rubric grading: Using LLMs to generate and apply grading rubrics to evaluate harmfulness of responses. "We evaluate candidate responses using LLM-based rubric grading"
- Logit smoothing: Averaging raw model scores over token windows to reduce spurious spikes in streaming classification. "using logit smoothing and a weighted softmax loss function"
- Model routers: Systems that direct queries to different models or stages based on predicted difficulty or risk. "Other work explores cascades and model routers for efficient LLM deployment."
- Obfuscation attacks: Techniques that make harmful outputs appear benign or unintelligible without context. "Output obfuscation attacks."
- Prompt caching: Reusing computed prompt context during generation to reduce overhead. "Prompt caching during sampling makes this approach computationally feasible without significant overhead."
- Reconstruction attacks: Splitting harmful content across benign segments and instructing the model to reassemble it. "Reconstruction attacks."
- Red-teaming: Systematic adversarial testing by humans to discover vulnerabilities. "Through extensive red-teaming comprising over 1,700 hours"
- Refusal rate: The proportion of queries that are blocked or refused by the system. "a 0.05% refusal rate on production traffic."
- Shadow deployment: Running a system alongside production to collect metrics without affecting users. "We evaluated the system through a shadow deployment on production traffic"
- Short-circuiting: An internals-based fine-tuning method to improve alignment robustness via circuit-level interventions. "including short-circuiting"
- Soft labels: Probabilistic targets used in training, often derived from another model. "exchange-level soft labels"
- Softmax probes: Probes that use softmax-based weighting or aggregation for sequence-level prediction. "softmax probes of \citet{mckenzie2025detectinghighstakesinteractionsactivation}"
- Softmax-weighted loss: A loss that emphasizes positions with higher predicted harmfulness via softmax weighting. "We employ a softmax-weighted loss"
- Spearman rank correlation: A nonparametric measure of monotonic association between two sets of scores. "Spearman rank correlation between classifier predictions on jailbreak attempts."
- Sparse auto-encoder features: Learned sparse latent features used for interpretability or classification. "classifiers using sparse auto-encoder features"
- Streaming classification: Making continuous predictions during token-by-token generation rather than after full completion. "we build streaming classifiers with continuous predictions during generation."
- SWiM (Sliding Window Mean) Logit Smoothing: Averaging logits over a sliding window during training to stabilize streaming decisions. "Sliding Window Mean (SWiM) Logit Smoothing."
- Two-stage classification: A cascade where a lightweight first stage screens inputs and escalates to a stronger second stage. "We evaluate whether two-stage classification maintains robustness"
- Two-stage classifier cascade: A specific cascaded architecture combining a cheap and an expensive classifier. "a two-stage classifier cascade"
- Universal jailbreaks: Strategies that consistently bypass safeguards across many target queries within a domain. "strong protection against universal jailbreaks"
- Vulnerability discovery rate: The number of high-risk vulnerabilities found per unit of red-teaming effort. "yielding a vulnerability discovery rate of 0.00878 per thousand queries."
- WildChat: A large conversational dataset used for calibration of refusal/flag rates. "calibrated to 0.1% refusal rates on WildChat"
Collections
Sign up for free to add this paper to one or more collections.