- The paper demonstrates that a single, well-crafted RL sample can outperform traditional methods, achieving up to a 14.5 point gain on non-math benchmarks.
- It introduces the polymath learning paradigm, which synthesizes natural and synthetic samples to infuse multidisciplinary STEM skills into the model.
- The study highlights that optimal sample design, emphasizing algebra and precalculus skill diversity, significantly cuts data needs while enhancing model self-verification.
Extreme Data Efficiency in RL Scaling: A Polymath Learning Paradigm
Introduction and Motivation
The current scaling paradigm for advancing LLM reasoning capabilities emphasizes ever-larger datasets and resource-intensive RL fine-tuning. "One Sample to Rule Them All: Extreme Data Efficiency in RL Scaling" (2601.03111) fundamentally challenges this conventional wisdom by dissecting the influence of data efficiency in RL for LLMs. The study introduces "polymath learning," showing that a single, meticulously designed training example can produce strong, transferable improvements in both mathematical and multidisciplinary reasoning tasks. Central hypotheses address (i) the cross-domain generalizability of one-shot reinforcement learning, (ii) characteristics that determine optimal sample selection, and (iii) the synthesis of meta-samples with maximal multidisciplinary skill coverage.
Experimental Paradigm and Baselines
The work primarily employs Qwen2.5-7B-base, leveraging the GRPO [shao2024deepseekmath] RL algorithm and a fixed batch regime. Evaluation spans extensive benchmarks, including MATH500, AIME, MinervaMath, SuperGPQA, MMLU-Pro, and Scibench. The performance of polymath learning (single-sample RL) is systematically compared to strong baselines: zero-shot inference, in-context learning with 1-shot exemplars, and comprehensive RL with 1k–8k sample subsets (notably, using sophisticated LIMR-based data selection).
Models are exposed to two sample types:
- Natural polymath samples: Selected from mathematics domains (e.g., prealgebra, algebra) by their low LIMR scores, ensuring high RL learnability without over-specialization.
- Synthetic polymath samples: Constructed via LLM-driven instruction-followed generation, emphasizing simultaneous coverage of salient skills from math, physics, chemistry, and biology.
Cross-Domain Generalization Effects
The central empirical result is that RL with a single polymath sample confers outsized, robust improvements not only in math benchmarks but across physics, chemistry, engineering, and other science domains. This effect is particularly pronounced for math-distant domains—fields whose semantic representation (via subject-embedding distance) is far from MATH500—as shown by a 14.5 point average gain over comprehensive RL baselines in such subjects.
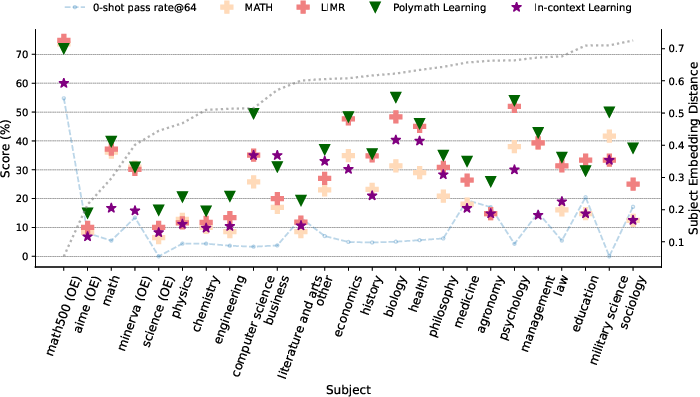
Figure 1: The subject-level performance of different learning strategies. OE denotes open-ended problems, and subjects are sorted by embedding distance from MATH500. Stars/triangles indicate best performances by in-context and polymath learning, respectively.
Notably, the best one-shot polymath RL models consistently outperform strong comprehensive RL models on non-math datasets and perform competitively on mathematics itself. These results are robust across model initializations and are fundamentally non-trivial given the dramatically reduced supervision signal.
Characteristics of Optimal Polymath Samples
Analysis of high-impact samples reveals that rich algebra and precalculus skill coverage is a strong predictor of cross-domain reasoning gains. Data diversity at the intra-sample level, measured by the breadth of salient skills referenced by each example, underpins the sample's transferability.
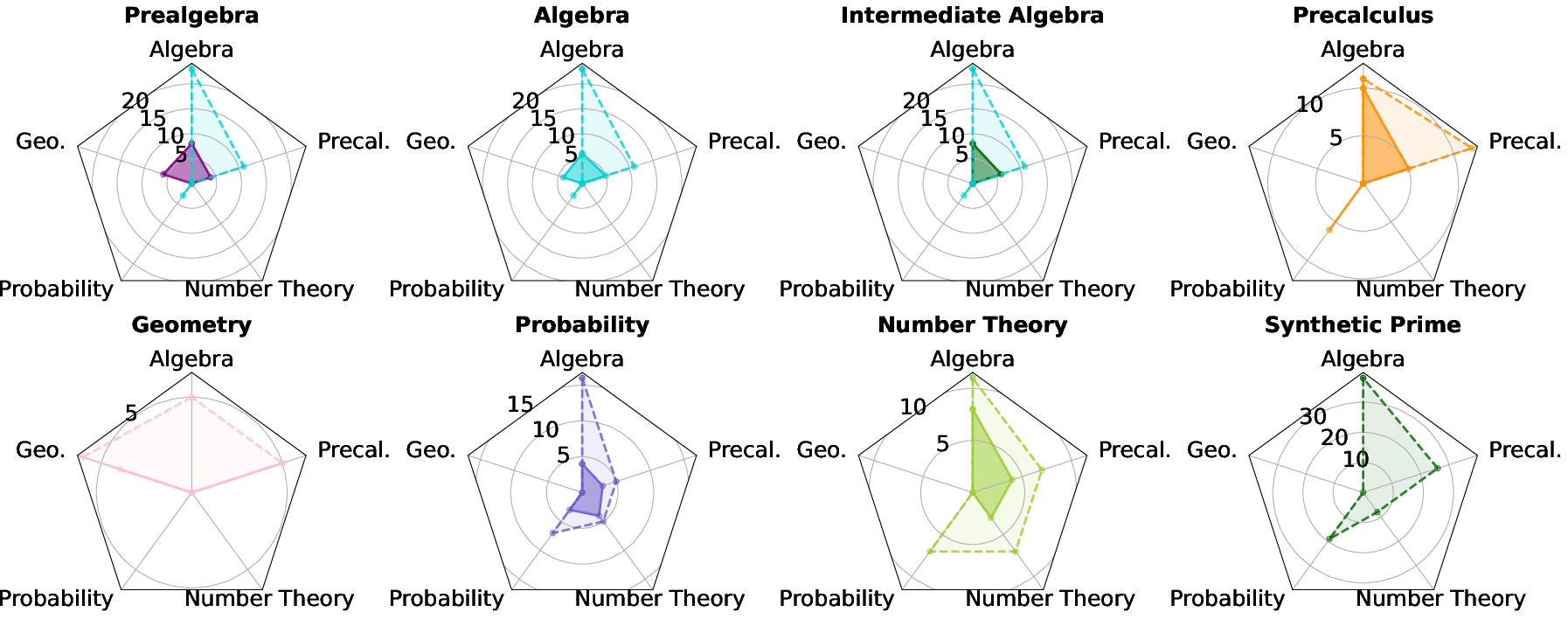
Figure 2: Skill spectrum between natural and synthetic polymath samples; synthetic samples demonstrate markedly broader skill coverage.
Empirically, synthetic polymath samples synthesized to integrate multidisciplinary skills (e.g., the "Synthetic Prime" sample) universally outperform both domain-specific and natural polymath samples. The integration of concepts from diverse STEM domains within one sample strengthens the generalization and reasoning signal, providing superior sample efficiency than simply increasing dataset scale.
Fine-Grained Skill Analysis
Domain-specific skill prevalence further clarifies transfer mechanics. Quantitative fields (science, engineering) heavily rely on algebraic and precalculus skills, and effective samples must encode these foundational operations.
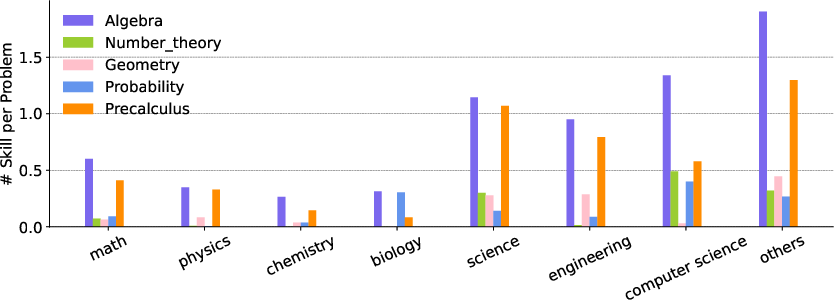
Figure 3: Average number of mathematical skills per problem in subject domains. Algebra and Precalculus dominate.
Synthetic specialist samples with targeted, multidisciplinary backgrounds excel in certain areas (e.g., the "Synthetic Prime" in physics/chemistry, geometry in engineering). This granularity opens the possibility of targeted skill injection via sample engineering to address identified weaknesses.
Self-Verification Mechanisms
Self-verification—models' emergent ability to internally check or revise outputs—appears more frequently and robustly after polymath learning than with comprehensive RL, particularly for samples rich in number theory or intermediate algebra skills. Patterns such as "re-evaluate," "recheck," and code-based validation are subject- and sample-dependent, revealing a complex interaction between learned verification routines and reinforcement supervision signals.
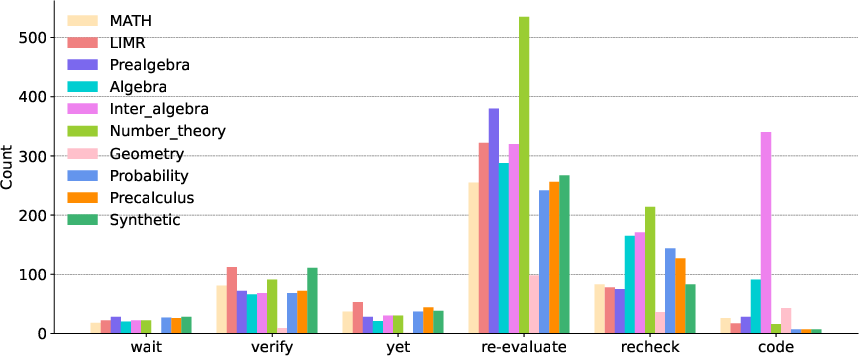
Figure 4: Self-verification patterns under different comprehensive and polymath samples across all subjects. Distinct samples elicit different verification types.
Implications and Future Outlook
This work has several impactful implications:
- Sample engineering is more effective than dataset scaling: Meticulous construction and skill balancing in even a single sample can outperform RL on thousands of examples. This finding contradicts the default to brute-force data scaling and calls for a more nuanced approach to dataset curation in RL for LM reasoning.
- Enabling practical RL efficiency: The results dramatically reduce RL time and data costs for achieving competitive or superior generalization, opening pathways for RL alignment and reasoning enhancement with minimal computational resources.
- AI curriculum design: The approach provides concrete direction for designing compact, high-signal synthetic "curriculums," enabling targeted improvement on weak domains or skills by altering the internal composition of a single sample.
- Limits and future questions: Despite encouraging robustness, further expansion is needed to (a) automate skill-based meta-sample synthesis on broader domains, (b) anchor sample construction strategies to formal measures of skill diversity, (c) understand observed limitations (e.g., format overfitting), and (d) adapt rewards and selection for non-math domains with unreliable automatic supervision.
Conclusion
"One Sample to Rule Them All" (2601.03111) definitively demonstrates that the data efficiency of RL for LLM reasoning can be improved by two orders of magnitude—down to a single well-crafted sample—if sample construction is treated as a problem of skill and diversity optimization. These results necessitate a shift from dataset scaling to high-precision sample engineering as the lingua franca for RL-based reasoning enhancement in LLMs. Future research should systematize and automate the design of these meta-samples, generalize the methodology outside math-heavy reasoning, and link sample structure to theoretical bounds on generalization and transfer.