Reasoning with Sampling: Your Base Model is Smarter Than You Think
Abstract: Frontier reasoning models have exhibited incredible capabilities across a wide array of disciplines, driven by posttraining LLMs with reinforcement learning (RL). However, despite the widespread success of this paradigm, much of the literature has been devoted to disentangling truly novel behaviors that emerge during RL but are not present in the base models. In our work, we approach this question from a different angle, instead asking whether comparable reasoning capabilites can be elicited from base models at inference time by pure sampling, without any additional training. Inspired by Markov chain Monte Carlo (MCMC) techniques for sampling from sharpened distributions, we propose a simple iterative sampling algorithm leveraging the base models' own likelihoods. Over different base models, we show that our algorithm offers substantial boosts in reasoning that nearly match and even outperform those from RL on a wide variety of single-shot tasks, including MATH500, HumanEval, and GPQA. Moreover, our sampler avoids the collapse in diversity over multiple samples that is characteristic of RL-posttraining. Crucially, our method does not require training, curated datasets, or a verifier, suggesting broad applicability beyond easily verifiable domains.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explores a simple idea: can we get LLMs to reason better just by sampling (picking words) in a smarter way, without any extra training? The authors show that a clever sampling method can make “base” models (the original, untrained versions) perform almost as well as, and sometimes even better than, models that have been improved using reinforcement learning (RL).
Key questions the paper asks
- Can base models already “think” well, and we just aren’t sampling their answers in the best way?
- Is there a way to boost reasoning at test time (when you ask the model a question) without training, special datasets, or external graders/verifiers?
- How does this smarter sampling compare to popular RL techniques like GRPO on math, coding, science, and general helpfulness tasks?
How did the researchers approach it?
The basic idea: “sharpening” the model’s choices
When an LLM generates an answer, it picks the next word based on how likely it thinks each word is. “Sharpening” means adjusting the model’s choices so that it more strongly favors higher-likelihood paths and avoids lower-likelihood ones. Think of it like turning up the contrast on a photo: bright areas get brighter, dark areas get darker. Here, high-quality next steps get more weight, and bad ones get less.
What’s “power sampling”?
Power sampling means sampling from instead of , where:
- is the model’s original distribution over sequences (its usual way of choosing words).
- is a number bigger than 1 that “sharpens” the distribution (higher means stronger sharpening).
Intuition: If the model thinks certain complete answers are much more likely to be correct, power sampling pushes generation toward those answers by amplifying their advantage.
Why not just lower the temperature?
“Low-temperature” sampling (a common trick) makes the next-word choices more confident by flattening out uncertainty at each step. But the paper shows this is not the same as sampling from over whole sequences:
- Low temperature focuses only on the next word, averaging over many possible futures (some good, many so-so).
- Power sampling looks ahead at possible complete continuations and upweights choices that lead to a few very strong future paths.
Analogy: Choosing a turn in a maze.
- Low temperature: pick the turn that seems best now, after averaging many future routes—even if most of those routes are mediocre.
- Power sampling: pick the turn that leads to a smaller number of clearly great routes, even if its immediate score looks slightly worse.
This “look-ahead bias” is valuable for reasoning because it avoids “pivotal” mistakes: early word choices that lock the model into weak solutions later on.
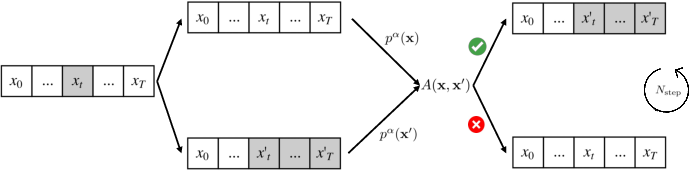
How do you sample from in practice? MCMC explained simply
Directly sampling from is hard because you’d need to consider all possible sequences. The authors use a classic technique called Metropolis–Hastings (a type of Markov chain Monte Carlo, or MCMC), adapted for LLMs:
- Start with a candidate answer.
- Randomly pick a position in the answer and resample the rest from that point using a simple proposal (like low-temperature sampling).
- Decide whether to keep the new candidate based on how much better it fits . If it’s better, you likely accept it; if worse, you often reject it.
- Repeat this “edit-and-check” process several times, growing the answer in chunks (blocks).
Analogy: Editing an essay paragraph by paragraph:
- You occasionally rewrite part of the essay (from a random sentence onward).
- You keep the rewrite only if it scores better according to your rule (favoring clearly strong completions).
- After enough edits, you end up with an essay that fits the “sharpened” preference (favoring truly good future paths) without retraining the writer.
The key benefits:
- No training required.
- No special datasets or external graders.
- Just smarter inference-time computation while generating.
What did they find?
Across different base models and tasks, the new sampling method delivers big wins:
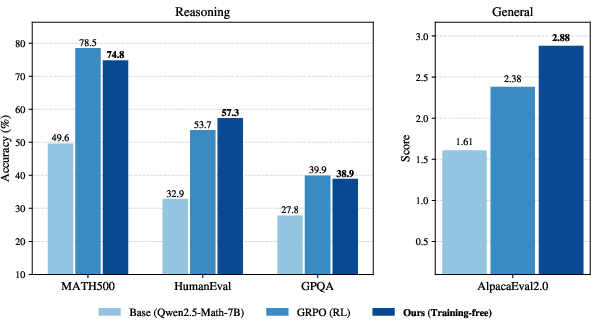
- On math (MATH500), coding (HumanEval), science multiple-choice (GPQA), and general helpfulness (AlpacaEval 2.0), power sampling often matches or beats RL (GRPO).
- It does especially well outside the training domain (e.g., better on HumanEval coding and AlpacaEval helpfulness), showing strong generalization.
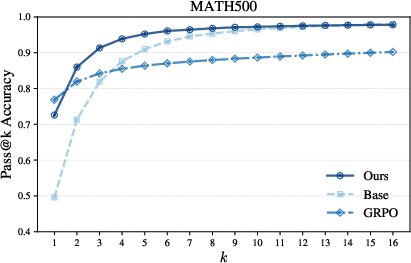
- It avoids “diversity collapse.” RL tends to make models give very similar answers across multiple samples. Power sampling keeps answers varied while still improving single-shot accuracy. That leads to better pass@k performance (solving a problem if any of k samples succeeds).
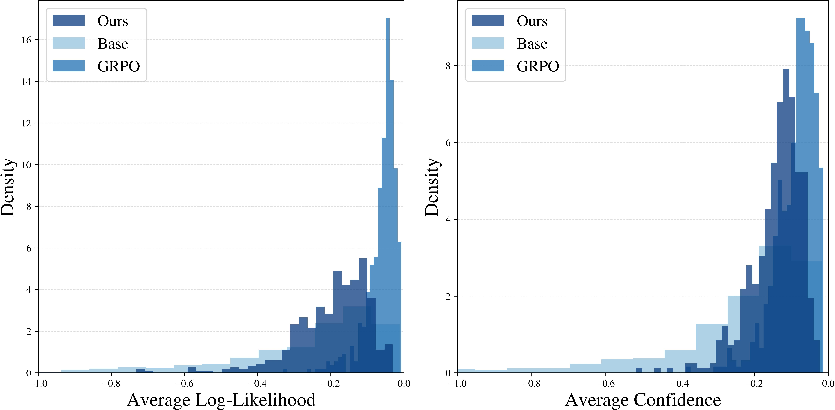
- Generated answers are longer and more confident—similar to RL—without forcing the model to be verbose.
- Answers tend to have higher likelihood under the base model but keep a healthy spread, so the model doesn’t get stuck only producing one style of answer.
Why is this important?
- It shows base models are “smarter than you think.” Much of the benefit of RL can be recovered by better sampling, not new training.
- It reduces cost and complexity. No training runs, no hyperparameter hunts, no need for a ground-truth verifier—just smarter inference.
- It scales with compute at test time. If you can afford a bit more generation effort (a few more “edit-and-check” steps), you get better reasoning without retraining.
- It supports broader applications, including areas where automatic verification is hard (like general Q&A or helpfulness), since the method doesn’t rely on external rewards.
Key takeaway
You can unlock a lot of hidden reasoning ability in base LLMs simply by sampling smarter. By favoring future paths that lead to strong complete answers—using power sampling with an MCMC “edit-and-check” loop—you can get performance close to, or better than, RL-trained models on many tasks. This suggests a powerful, training-free path to better reasoning: spend a little more compute at inference time, and let the base model shine.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of what remains missing, uncertain, or unexplored in the paper. Each item is framed to be concrete and actionable for future research.
- MH correctness and clarity for the staged targets: Provide a formal proof that the staged MH scheme truly samples from the intended target at each stage (i.e., from ), and clarify the apparent inconsistency in Algorithm 1 where the acceptance ratio references instead of .
- Exact proposal density in acceptance ratio: Precisely derive and implement and for the “random resampling at a uniformly chosen index” proposal, including the mixture over indices and the probability of choosing each index; verify that index-selection probabilities cancel appropriately in .
- Variable-length sequences and EOS handling: Specify how variable-length outputs (early EOS, length changes) are treated in the target and proposal distributions, and how this affects detailed balance, acceptance ratio computation, and potential length bias under .
- Mixing-time and acceptance-rate characterization: Quantify acceptance rates, autocorrelation, effective sample size, and mixing time as functions of , sequence length , block size , proposal temperature, and task/domain.
- Block size sensitivity: Provide a thorough ablation on (beyond a single choice), including its interaction with , acceptance rates, wall-clock cost, and accuracy/diversity trade-offs.
- Proposal distribution design: Explore alternative proposals (e.g., higher-temperature sampling, nucleus/top-k proposals, beam-like proposals, noise-injected logits, speculative decoding, learned proposals) and identify which proposals yield the best mixing and performance per compute.
- Tempering schedules and adaptive : Investigate annealing/tempering schedules (e.g., starting at and increasing), per-prompt adaptive , or position-dependent to balance quality and diversity while controlling mixing difficulty.
- Alternative Monte Carlo methods: Compare against Sequential Monte Carlo, tempered transitions, annealed importance sampling, and parallel tempering to assess whether they mix faster or reach better targets than the proposed MH variant.
- Computational efficiency and deployment cost: Report end-to-end latency, FLOPs, energy, memory footprint, and throughput impacts; quantify cache reuse and batching; compare cost/accuracy trade-offs against RL training amortized over many inferences.
- Length bias and normalization: Analyze how sampling from (a joint probability) interacts with sequence length (e.g., longer sequences often have lower joint probability); assess whether length-normalized targets (e.g., per-token average log-prob) or explicit priors on length improve results.
- Coverage and diversity metrics beyond pass@k: Measure lexical/semantic diversity (e.g., pairwise distance, conditional entropy, type-token ratios) to substantiate claims about avoiding diversity collapse and to characterize quality–diversity trade-offs.
- Failure mode analysis: Identify and categorize cases where power sampling underperforms RL or base sampling; analyze error patterns (e.g., deceptive local likelihood traps, multi-step dependencies) to guide targeted proposal or resampling strategies.
- Critical-window-aware proposals: Test resampling strategies that target “pivotal tokens” or high-influence spans (critical windows), rather than uniform index selection, to more efficiently repair low-likelihood future paths.
- Generalization claims under stronger baselines: Re-evaluate “out-of-domain” advantages against RL models post-trained on broader/matched domains (e.g., coding or science), and against other reasoning-enhancement methods (R1-style, PPO, DPO+CoT, RAP, OPRO).
- Baseline breadth at inference time: Compare to alternative inference-time compute baselines (self-consistency/majority vote, tree-of-thought/graph-of-thought search, verifier-guided reranking, MCTS, best-of-N with reranking) for a fair assessment of test-time search.
- Benchmark scope expansion: Validate on broader and larger benchmarks (e.g., GSM8K, AIME, MMLU(-Pro), MBPP/MBPP+, LiveCodeBench, SWE-bench, BigCodeBench, theorem proving, multilingual reasoning, multi-turn tool-use) to test robustness and scalability.
- Safety, bias, and toxicity: Evaluate whether sharpening amplifies sycophancy, biases, or unsafe content; test on safety/jailbreak benchmarks and assess mitigation strategies (e.g., safety-aware targets or constraints during resampling).
- Hallucination and factuality on unverifiable tasks: Measure factuality (e.g., TruthfulQA, HaluEval) to determine whether higher base-model likelihood under aligns with truthfulness or merely with fluency and confidence.
- Reproducibility details: Provide seeds, hardware specs, caching strategies, exact decoding settings (top-k/p, temperature), acceptance-rate logs, and full training details for RL baselines to enable apples-to-apples replication.
- Theoretical link to “few high-likelihood futures”: Formalize the “sum of exponents vs. exponent of sums” observation; quantify when favors tokens with few high-quality continuations versus many mediocre ones, and relate this to difficulty and problem structure.
- Hybrid verifier-tilting without training: Explore combining with lightweight verifiers or rewards at inference time (e.g., sampling from ) to approximate RLVR benefits without training, and study stability/compute trade-offs.
- Multi-sample aggregation: Evaluate whether generating multiple samples and aggregating (self-consistency, confidence-based voting, verifier-based reranking) further outperforms both single-shot power sampling and RL.
- Tokenization and multilingual sensitivity: Test robustness across tokenizers and languages, as tokenization changes likelihood geometry and may affect both mixing and the “high-likelihood futures” effect.
- Constraint-preserving decoding: Integrate grammar/constrained decoding with the MH proposal to ensure formats (e.g., JSON, code signatures) are preserved during resampling; evaluate on tasks requiring strict output schemas.
- Memorization and copyright risk: Assess whether sampling from sharper high-likelihood regions increases verbatim memorization or copying from training data relative to base sampling.
Practical Applications
Overview
This paper introduces a training-free, verifier-free inference-time sampling algorithm (“power sampling”) that elicits stronger single-shot reasoning from base LLMs by sampling from a sharpened distribution, specifically the power distribution . The method uses an autoregressive Metropolis–Hastings (MCMC) procedure to iteratively resample token subsequences based on the base model’s own likelihoods. Empirically, it matches or outperforms standard RL posttraining (GRPO) on in-domain and out-of-domain reasoning tasks, preserves diversity (high pass@), and requires no special datasets or reward signals.
Below are practical applications derived from these findings, grouped into immediate and long-term categories. Each application notes relevant sectors, potential tools/workflows, and key assumptions or dependencies.
Immediate Applications
The following applications can be deployed now with engineering integration (e.g., into existing LLM inference stacks). They leverage the paper’s algorithmic insights without requiring model retraining.
- Reasoning boost as a drop-in inference wrapper (Software/AI Platforms)
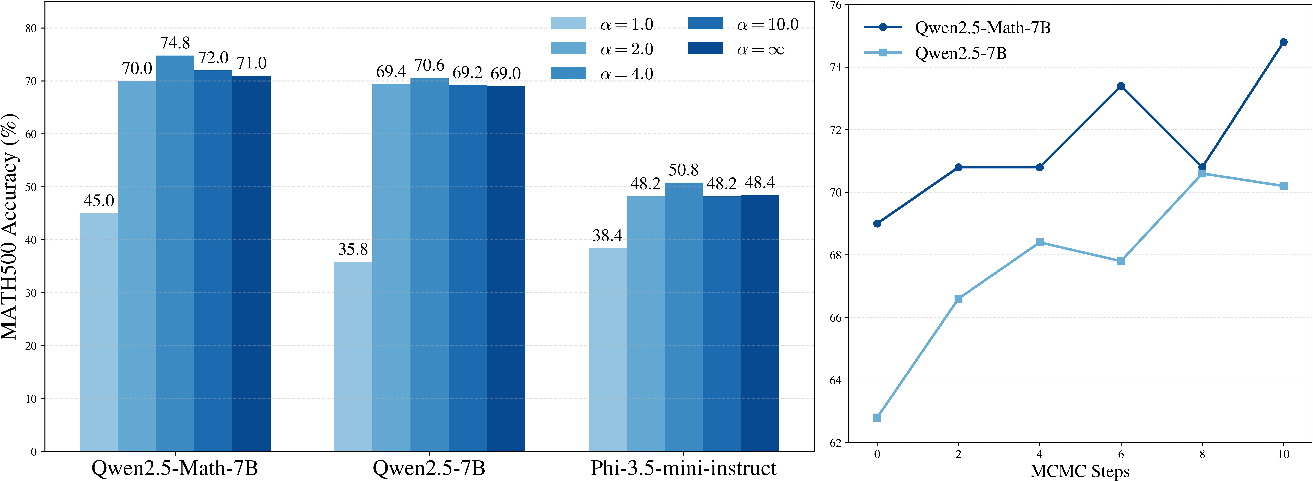
- Implement power sampling around existing LLM APIs (e.g., Hugging Face, vLLM, Triton), exposing a “reasoning quality” knob via , MCMC steps, and block size. Use default settings similar to the paper (e.g., , block size ≈ 128–256, MCMC steps ≈ 2–10).
- Offer per-request profiles: standard sampling vs. “power sampling mode” for tasks that need stronger reasoning (math, code, structured problem solving).
- Tools/Workflows: a middleware library that wraps
logprobscalls, implements MH acceptance, tracks acceptance ratios, and enforces latency/compute budgets. - Assumptions/Dependencies: base model must expose token-level log-likelihoods; increased inference-time compute (often 5–10× tokens vs. standard sampling) must be acceptable; careful engineering for streaming/latency.
- Code assistants and CI bots with higher pass@1 and preserved pass@ (Software/DevOps)
- Use power sampling for function synthesis, bug fixes, and refactoring. Trigger “power mode” when tests fail or when determinism (low temperature) underperforms.
- Integrate with unit-test-driven workflows (HumanEval-style) and gated merges. Preserve diversity for pass@ by avoiding RL-style collapse.
- Tools/Workflows: CI pipeline plugin that retries candidates using power sampling, logs pass@ curves and acceptance ratios across builds.
- Assumptions/Dependencies: compute budget; logprob access; domain-specific guardrails for unsafe code.
- Math and science tutoring with stronger chain-of-thought (Education)
- Use power sampling for math problem solving and STEM explanations; provide a “reasoning dial” to students and instructors.
- Tools/Products: tutoring apps that switch to power sampling for complex problems, showing answer confidence via base-model likelihood histograms.
- Assumptions/Dependencies: accurate logprob tooling; pedagogy considerations to avoid overconfidence; content safety filters.
- Enterprise assistants with improved helpfulness (General Enterprise)
- The method improves non-verifiable general helpfulness (AlpacaEval 2.0). Expose a toggle for “power sampling mode” in customer support, knowledge management, and drafting tools.
- Tools/Workflows: A/B testing harness to compare default vs. power sampling; length-controlled responses; diversity tracking to reduce repetitive answers.
- Assumptions/Dependencies: acceptable latency increases; content moderation pipelines to mitigate harmful confident outputs.
- Retrieval-augmented generation (RAG) with better reasoning over context (Knowledge Management)
- Apply power sampling after retrieval to synthesize answers requiring multi-step reasoning over documents.
- Tools/Workflows: RAG stack with selective power sampling on “hard” queries (e.g., detected via entropy or uncertainty), confidence dashboards based on base-model metrics.
- Assumptions/Dependencies: reliable retrieval; logprob access; compute budgets for complex documents.
- Low-resource or privacy-first deployments of base models (SMBs, On-prem/Edge)
- Organizations without the budget or data to run RL posttraining can upgrade reasoning using only inference-time compute on local base models (e.g., Phi-3.5-mini-instruct).
- Tools/Products: an on-prem inference server with power sampling; privacy-preserving pipelines without external reward signals.
- Assumptions/Dependencies: hardware capacity at inference; careful latency tuning.
- Safety and QA gating via likelihood/confidence monitoring (Software Quality, Compliance)
- Use base-model likelihood or negative entropy (confidence) histograms to gate responses (reject low-likelihood reasoning traces), log MH acceptance statistics to audit sampling quality.
- Tools/Workflows: observability dashboards that track distribution shift under power sampling; automated rollback to standard sampling when acceptance stalls.
- Assumptions/Dependencies: calibrated confidence metrics; monitoring infrastructure; policy for handling confident but wrong answers.
- Research productivity in academia and data science (Academia/Research)
- Training-free gains in coding, math, and scientific reasoning for prototyping, paper writing, and analysis; preserve diversity for exploration (high pass@).
- Tools/Workflows: Jupyter/VS Code extensions enabling power sampling for “hard reasoning cells,” task-based presets for and MCMC steps.
- Assumptions/Dependencies: local inference setup; compute budget; reproducibility through logging seeds and acceptance paths.
- Productization of a “Reasoning Quality” control (Software/UI/UX)
- Expose “quality vs. speed” slider mapping to power sampling parameters (e.g., alpha, MCMC steps); provide explainable signals (e.g., acceptance ratios, likelihood distributions).
- Tools/Workflows: UI controls; rate-limiters to keep SLOs; adaptive runtime selection based on query difficulty.
- Assumptions/Dependencies: user education, cost controls; latency SLAs.
- Incident response and escalations (Ops)
- For high-stakes tickets or decision trees, escalate to power sampling mode to reduce reasoning errors while preserving diverse suggestions for analysts.
- Tools/Workflows: policy engines that automatically trigger power sampling on high-risk classifications; logging for postmortems.
- Assumptions/Dependencies: risk classification models; human-in-the-loop review.
Long-Term Applications
These opportunities require further research, scaling, domain validation, or integration with other systems.
- Adaptive test-time scaling controllers (Software/AI Platforms)
- Learn policies that choose , proposal temperatures, and MCMC steps per task/query, balancing latency, diversity, and expected accuracy.
- Tools/Workflows: meta-controllers with cost-aware scheduling; difficulty estimators (entropy, uncertainty, length).
- Assumptions/Dependencies: robust difficulty prediction; reinforcement or bandit-style learning to tune sampling policies.
- Hybrid training that leverages power sampling traces (ML Engineering)
- Use MH logs to curate high-quality reasoning traces, seeding supervised fine-tuning or RL without expensive reward models; support “feedback-free” or weakly-supervised posttraining.
- Tools/Workflows: data curation pipelines extracting accepted/rejected candidate pairs; synthetic dataset generation for future training.
- Assumptions/Dependencies: data governance; label quality checks; risk of overfitting to high-likelihood regions.
- Multimodal and embodied planning (Robotics/Autonomy)
- Extend power sampling to language-driven planners for robots or agents (vision-language-action sequences), resampling pivotal tokens to avoid low-likelihood failure paths.
- Tools/Workflows: LLM-based task planners that use block-wise resampling on action sequences; integration with MDP/trajectory proposals.
- Assumptions/Dependencies: reliable multimodal likelihoods; careful latency management; safety validation in controlled environments.
- Domain-specific decision support (Healthcare, Legal, Finance)
- Use power sampling to produce stronger reasoning drafts for clinicians, lawyers, and analysts, paired with external validators (guidelines, calculators, checklists).
- Tools/Workflows: “second-look” assistants that generate multiple high-quality candidates; human review workflows; provenance tracking.
- Assumptions/Dependencies: strict compliance and safety; domain verifiers; rejection mechanisms for overconfident errors; regulatory approvals.
- Safety, bias, and calibration research for sharpened distributions (AI Safety/Policy)
- Investigate how sampling from concentrates on high-likelihood regions that may encode biases; develop countermeasures (calibration, fairness constraints, ensemble proposals).
- Tools/Workflows: fairness-aware acceptance criteria; risk-weighted alpha selection; audits of likelihood-concentration effects across demographics.
- Assumptions/Dependencies: access to sensitive evaluation datasets; governance and compliance frameworks.
- Hardware and systems optimization for inference-time MCMC (Systems/Cloud)
- Develop GPU/TPU kernels and micro-batching schemes that amortize the 5–10× token generation overhead; asynchronous proposal generation; speculative decoding for MH candidates.
- Tools/Workflows: systems libraries with efficient logprob computation and caching; acceptance-aware speculative execution.
- Assumptions/Dependencies: engineering effort; cost-benefit vs. RL training; coordination with model vendors.
- Standardization of “test-time reasoning” metrics and policies (Policy/Standards)
- Define industry norms for reporting test-time compute (tokens × steps), diversity (pass@), and likelihood/confidence histograms; inform energy usage disclosures and carbon accounting.
- Tools/Workflows: benchmarking suites with pass@ and calibration metrics; procurement and compliance checklists specifying test-time scaling constraints.
- Assumptions/Dependencies: multi-stakeholder coordination; alignment with regulatory bodies.
- Adaptive proposal distributions and search (ML Research)
- Go beyond low-temperature proposals: learn proposal LLMs or use external heuristic search to propose candidates that mix fast and thorough exploration; reduce mixing times.
- Tools/Workflows: proposal-learning pipelines; annealing schedules over blocks; hybrid beam/MCMC search.
- Assumptions/Dependencies: training resources; convergence studies; task-specific tuning.
- Program synthesis and formal verification synergy (Software Engineering)
- Combine power sampling with formal methods (SMT solvers, type systems) to generate high-likelihood candidate programs and prune via verification; improve correctness in safety-critical code.
- Tools/Workflows: LLM+solver co-pilots; MH acceptance modified with verifier scores; step-wise resampling around proof obligations.
- Assumptions/Dependencies: integration complexity; solver performance; domain constraints.
- Curriculum and pedagogy at scale (Education Policy)
- Deploy power-sampling-enabled tutors to large student populations, studying effects on learning outcomes, misconceptions, and trust calibration.
- Tools/Workflows: controlled trials; dashboards tracking confidence vs. correctness; adaptive “alpha” that responds to student proficiency.
- Assumptions/Dependencies: IRB approvals; teacher training; safeguards against overreliance.
- Cross-model interoperability and democratization (Open Source/Community)
- Package power sampling as an open standard across model families (Qwen, Phi, Llama, Mistral) with consistent APIs, logs, and monitoring; reduce dependence on proprietary RL pipelines.
- Tools/Workflows: OSS libraries; task-specific presets; community benchmarks for pass@ diversity vs. single-shot accuracy.
- Assumptions/Dependencies: broad maintainer engagement; API support for logprobs; sustainable funding.
Notes on Feasibility
- Compute trade-offs: Power sampling often increases generated tokens substantially (e.g., ~8–9× in the paper’s MATH500 setup). Latency/throughput budgets must be managed via adaptive knobs (alpha, steps, block size), difficulty estimation, and selective activation.
- Logprob access: The method requires reliable next-token log-likelihoods from the base model. Some commercial APIs may restrict or quantize these; open-source models are preferable for full control.
- Robustness and safety: Sharpening toward high-likelihood regions can increase confidence (and potential overconfidence). Pair with calibration, human oversight, and task-specific verifiers, especially in regulated domains.
- Generalization: Results are shown on specific models (Qwen2.5, Phi-3.5) and benchmarks (MATH500, HumanEval, GPQA, AlpacaEval). Expect variation across models and tasks; perform A/B testing and tune parameters per domain.
- Diversity: A key advantage over RL posttraining is preserved diversity (strong pass@). Ensure product workflows exploit this (e.g., multi-candidate generation for review) rather than collapse to single determinism.
In summary, power sampling offers a practical, immediately deployable path to stronger reasoning from base models, with broad applicability across software development, education, enterprise assistance, and research—while setting up fertile ground for long-term innovation in adaptive test-time scaling, multimodal planning, domain-specific decision support, and AI safety.
Glossary
- Acceptance probability: In Metropolis-Hastings, the probability of accepting a proposed sample based on the target and proposal densities. "With probability A(\mathbf{x}, \mathbf{x}i) = \text{min} \left\lbrace 1, \frac{p{\alpha}(\mathbf{x}) \cdot q(\mathbf{x}i | \mathbf{x})}{p{\alpha}(\mathbf{x}i) \cdot q(\mathbf{x}|\mathbf{x}i)}\right\rbrace, candidate is accepted as ; otherwise, MH sets ."
- AlpacaEval 2.0: A length-controlled LLM helpfulness benchmark where responses are judged by GPT-4-turbo against a baseline. "AlpacaEval 2.0: The AlpacaEval dataset is a collection of 805 prompts \citep{dubois2024lengthcontrolledalpacaeval} that gauge general helpfulness with questions asking e.g., for movie reviews, recommendations, and reading emails."
- Annealing: A technique that sharpens or tempers a distribution, often by exponentiating it, to bias sampling toward high-likelihood regions. "In the statistical physics and Monte Carlo literature, sampling from is known as sampling from an annealed, or tempered, distribution"
- Aperiodic: A Markov chain property meaning the chain does not return to the same state at fixed periodic intervals. "The proposal is aperiodic if the induced chain of samples does not return to the same sample after a fixed interval number of steps."
- Autoregressive MCMC sampling: Integrating MCMC with sequential token generation in LLMs to sample structured sequences. "Prior works have explored integrating classic MCMC techniques with autoregressive sampling."
- Automated verifier: A program that automatically checks correctness and provides a reward signal for RL. "an automated verifier could substantially enhance performance on difficult reasoning tasks in mathematics and coding."
- Confidence (entropy-based): A measure of certainty derived from the average negative entropy of next-token distributions. "We also plot the base model confidence of MATH500 responses, defined to be the average negative entropy (uncertainty) of the next-token distributions"
- Critical windows (pivotal tokens): Small sets of highly influential tokens that determine the eventual correctness of model outputs. "choosing “wrong” tokens that have high average likelihoods but trap outputs in low likelihood individual futures are examples of critical windows or pivotal tokens"
- Diffusion model: A generative model framework where sampling procedures can be steered or tempered at inference time. "as a means of generating higher quality samples from the base diffusion model"
- Distribution sharpening: Reweighting a base distribution to upweight high-likelihood regions and downweight low-likelihood regions. "This is the question of distribution sharpening \citep{he2025rewarding,shao2025spuriousrewards,yue2025doesrlincentivizereasoning}: that is, whether the posttrained distribution is simply a “sharper” version of the base model distribution"
- GPQA: A graduate-level, Google-proof multiple-choice STEM benchmark assessing advanced reasoning. "GPQA: GPQA \citep{rein2024gpqa} is a dataset of multiple-choice science questions (physics, chemistry, and biology) which require advanced reasoning skills to solve."
- GRPO: Group Relative Policy Optimization, a reinforcement learning algorithm widely used to enhance LLM reasoning. "The Group Relative Policy Optimization (GRPO) algorithm was at the center of these advances \citep{shao2024deepseekmath}."
- HumanEval: A code-generation benchmark of handwritten problems, evaluated via unit tests. "HumanEval: HumanEval is a set of 164 handwritten programming problems covering algorihtms, reasoning, mathematics, and language comprehension \citep{chen2021evaluatingllmcode}."
- Irreducible: A proposal/Markov chain property ensuring nonzero probability to eventually reach any set with positive mass. "The proposal distribution is irreducible if for any set with nonzero mass under the target distribution , has nonzero probability of eventually sampling from ."
- Low-temperature sampling: Exponentiating next-token distributions to reduce temperature and make sampling more deterministic. "A related but well-known sharpening strategy is low-temperature sampling \citep{wang2020contextualtemperature}"
- Markov chain: A sequence of random states where the next state depends only on the current state; used to construct MCMC samplers. "The MH algorithm constructs a Markov chain of sample sequences "
- Markov chain Monte Carlo (MCMC): A class of methods for sampling from complex or unnormalized distributions via Markov chains. "we invoke a Markov Chain Monte Carlo (MCMC) algorithm known as Metropolis-Hastings (MH) \citep{metropolis1953equation}, which targets exactly what we want"
- Metropolis-Hastings (MH): A specific MCMC algorithm that accepts or rejects proposals based on an acceptance ratio. "we invoke a Markov Chain Monte Carlo (MCMC) algorithm known as Metropolis-Hastings (MH) \citep{metropolis1953equation}"
- Mixing time: The number of steps needed for an MCMC chain to approximate the target distribution well. "the potential for an exponential mixing time \citep{gheissari2017exponentially}"
- Mode collapse: Loss of diversity where samples concentrate in a few modes, often undesirable in generative modeling. "annealing is used as a way to avoid mode-collapse during sampling"
- Multimodal distribution: A distribution with multiple distinct high-probability regions (modes). "and more accurately sample from complex multimodal distributions \citep{latuszynski2025mcmcmultimodal}"
- Negative entropy: The negative of entropy; here used as a confidence proxy for next-token distributions. "defined to be the average negative entropy (uncertainty) of the next-token distributions"
- Out-of-domain tasks: Evaluation tasks different from a model’s posttraining domain, useful to test generalization. "out-of-domain tasks such as HumanEval and AlpacaEval."
- Pass@: A metric where a problem is considered solved if at least one of k generated samples is correct. "pass@ (multi-shot) scores"
- Power distribution: The distribution obtained by raising a base distribution to a power α, sharpening it toward high-likelihood sequences. "One natural way to sharpen a distribution is to sample from the power distribution ."
- Proposal distribution: The distribution used to generate candidate samples in MCMC methods. "using an arbitrary proposal distribution "
- RL-posttraining: Applying reinforcement learning after pretraining to improve specific capabilities like reasoning. "are the capabilities that emerge during RL-posttraining fundamentally novel behaviors that are not present in the base models?"
- RL with human feedback (RLHF): Reinforcement learning guided by a reward model trained on human preference data. "RL with human feedback (RLHF) \citep{ouyang2022traininglfh} was developed as a technique to align LLMs with human preferences using a trained reward model."
- RL with verifiable rewards (RLVR): Reinforcement learning driven by automatically verifiable reward signals. "RL with verifiable rewards (RLVR) has emerged as a powerful new posttraining technique"
- Sequential Monte Carlo (SMC): A particle-based sampling approach maintaining multiple candidates updated by importance weights and resampling. "used in a Sequential Monte Carlo (SMC) framework \citep{chopin2004cltsmc}"
- Tempered distribution: Synonym for annealed distribution; samples from pα that temper the base distribution. "sampling from is known as sampling from an annealed, or tempered, distribution"
- Temperature (sampling): A parameter controlling distribution sharpness in token sampling; lower temperature favors high-probability tokens. "where the temperature is ."
- Tilted distribution: A distribution modified or steered (e.g., by rewards or powers) away from the base model’s original distribution. "tilted distributions"
- Verifier-free: An approach that does not require access to an external correctness verifier during sampling or training. "our algorithm is training-free, dataset-free, and verifier-free, avoiding some of the inherent weaknesses of RL methods"
Collections
Sign up for free to add this paper to one or more collections.