DatBench: Discriminative, Faithful, and Efficient VLM Evaluations
Abstract: Empirical evaluation serves as the primary compass guiding research progress in foundation models. Despite a large body of work focused on training frontier vision-LLMs (VLMs), approaches to their evaluation remain nascent. To guide their maturation, we propose three desiderata that evaluations should satisfy: (1) faithfulness to the modality and application, (2) discriminability between models of varying quality, and (3) efficiency in compute. Through this lens, we identify critical failure modes that violate faithfulness and discriminability, misrepresenting model capabilities: (i) multiple-choice formats reward guessing, poorly reflect downstream use cases, and saturate early as models improve; (ii) blindly solvable questions, which can be answered without images, constitute up to 70% of some evaluations; and (iii) mislabeled or ambiguous samples compromise up to 42% of examples in certain datasets. Regarding efficiency, the computational burden of evaluating frontier models has become prohibitive: by some accounts, nearly 20% of development compute is devoted to evaluation alone. Rather than discarding existing benchmarks, we curate them via transformation and filtering to maximize fidelity and discriminability. We find that converting multiple-choice questions to generative tasks reveals sharp capability drops of up to 35%. In addition, filtering blindly solvable and mislabeled samples improves discriminative power while simultaneously reducing computational cost. We release DatBench-Full, a cleaned evaluation suite of 33 datasets spanning nine VLM capabilities, and DatBench, a discriminative subset that achieves 13x average speedup (up to 50x) while closely matching the discriminative power of the original datasets. Our work outlines a path toward evaluation practices that are both rigorous and sustainable as VLMs continue to scale.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about how we test AI systems that can look at pictures and understand language at the same time, called vision–LLMs (VLMs). The authors argue that the way we currently test these models is often unfair, easy to game, or too expensive. They build a new, cleaned-up set of tests called DatBench and DatBench-Full that are more fair, better at telling strong models from weak ones, and much faster to run.
The big questions the authors asked
- How can we make sure tests actually require looking at the image, not just guessing from the words?
- How can we design tests that clearly separate strong models from weak models, instead of letting everyone score roughly the same?
- How can we make testing much faster and cheaper without losing accuracy or usefulness?
How they approached the problem (in everyday language)
Think of testing AI models like making a good school exam. A good exam should:
- Ask questions that match real-life tasks (faithful).
- Clearly separate students by skill (discriminative).
- Take a reasonable amount of time to grade (efficient).
The authors found four common problems in today’s “exams” for VLMs, and they built fixes for each:
- Problem: Multiple-choice questions can be misleading
- Why: With choices A–D, even random guessing gets you about 25%. Some models also learn shortcuts from the options rather than actually understanding the image.
- Fix 1: Turn multiple-choice into “write your own answer.”
- Instead of picking A, the model must produce the answer itself (like a short answer question). A separate strong AI “judge” checks if the meaning matches the correct answer, even if the wording is different.
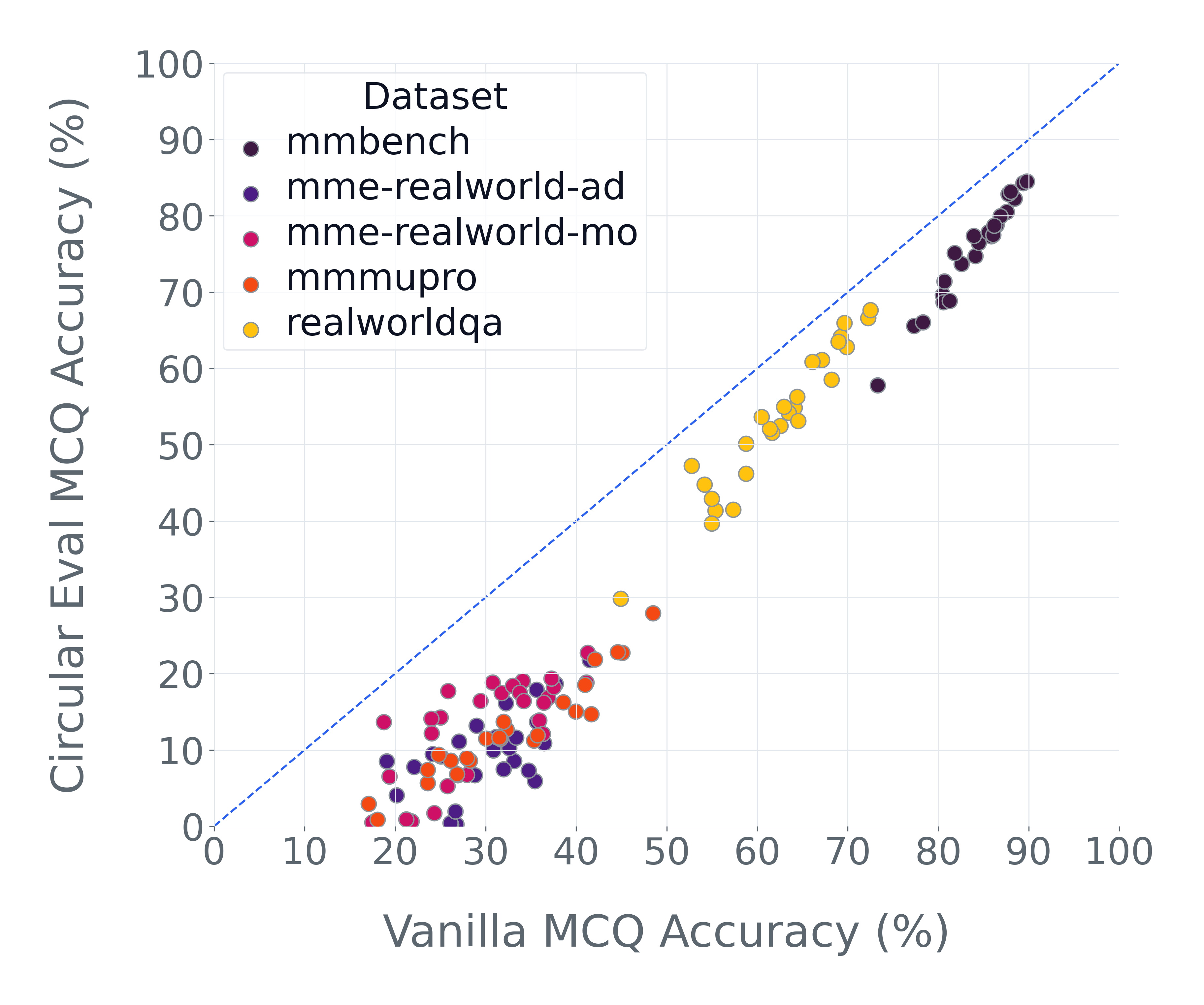
- Fix 2: When multiple-choice is necessary, use “circular evaluation.”
- Shuffle the answer options in different orders and only count it correct if the model picks the right answer every time. This wipes out the guessing advantage.
- Problem: Many questions can be answered without the image
- Why: Sometimes the words alone give the answer (for example, “What color is the toilet?”—most are white). Or the question is just a math puzzle with no real need for the picture.
- Fix: Test models with the picture removed. If a question is answered correctly without seeing the image, it gets filtered out. That keeps only questions where vision truly matters.
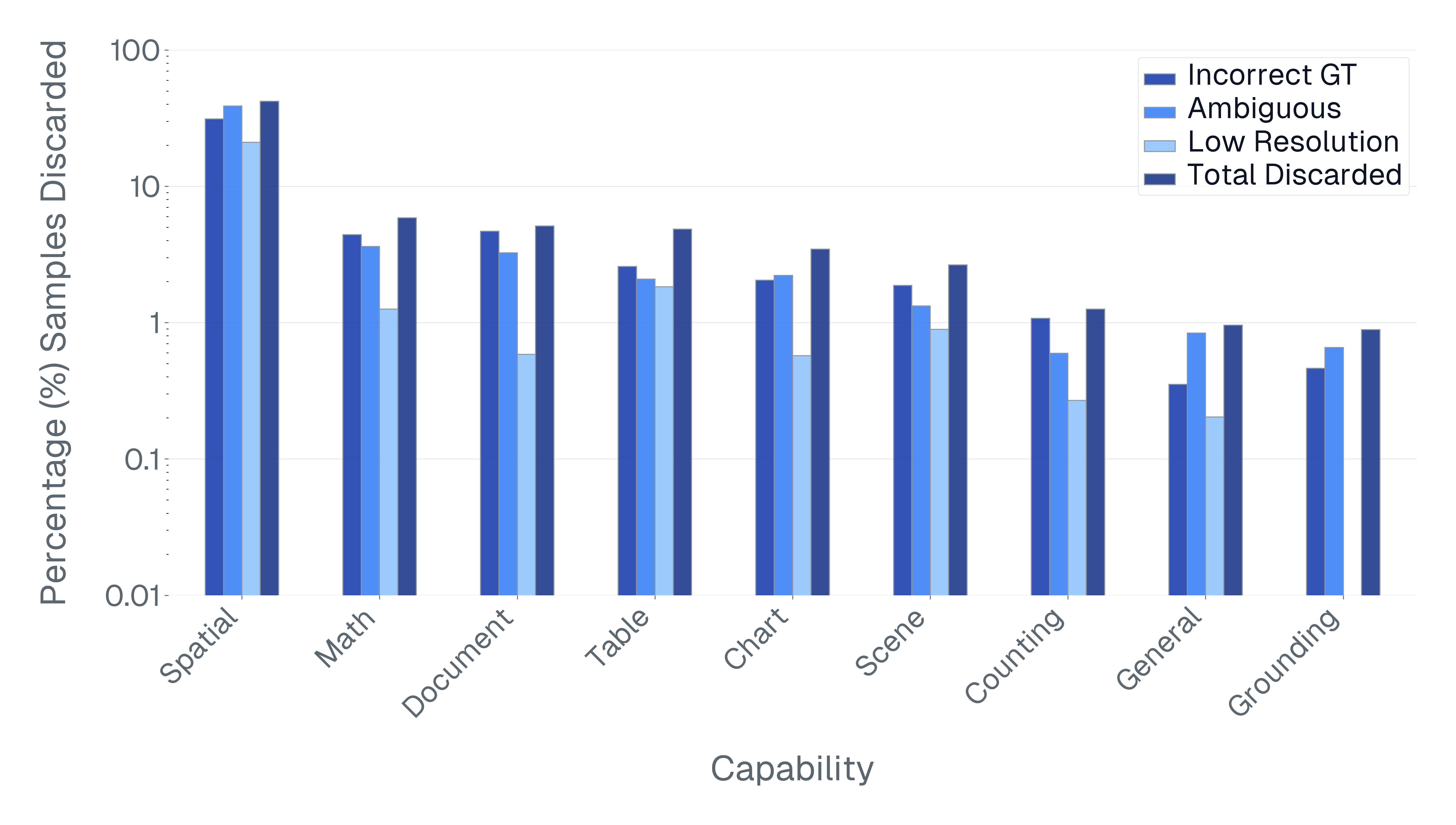
- Problem: Some test questions are wrong, confusing, or too blurry
- Why: Real-world datasets can have mistakes, unclear wording, or tiny/low-resolution images where even a human can’t see the details.
- Fix: Use a two-step cleanup. 1) Flag questions that every model gets wrong (a hint that the question may be bad or mislabeled). 2) Ask a strong AI “judge” to check if the ground-truth answer is correct, the question is clear, and the image is usable. If not, remove it.
- Problem: Testing everything is too slow and costly
- Why: VLMs can produce very long answers and need lots of computation. Running every dataset takes a lot of time and money.
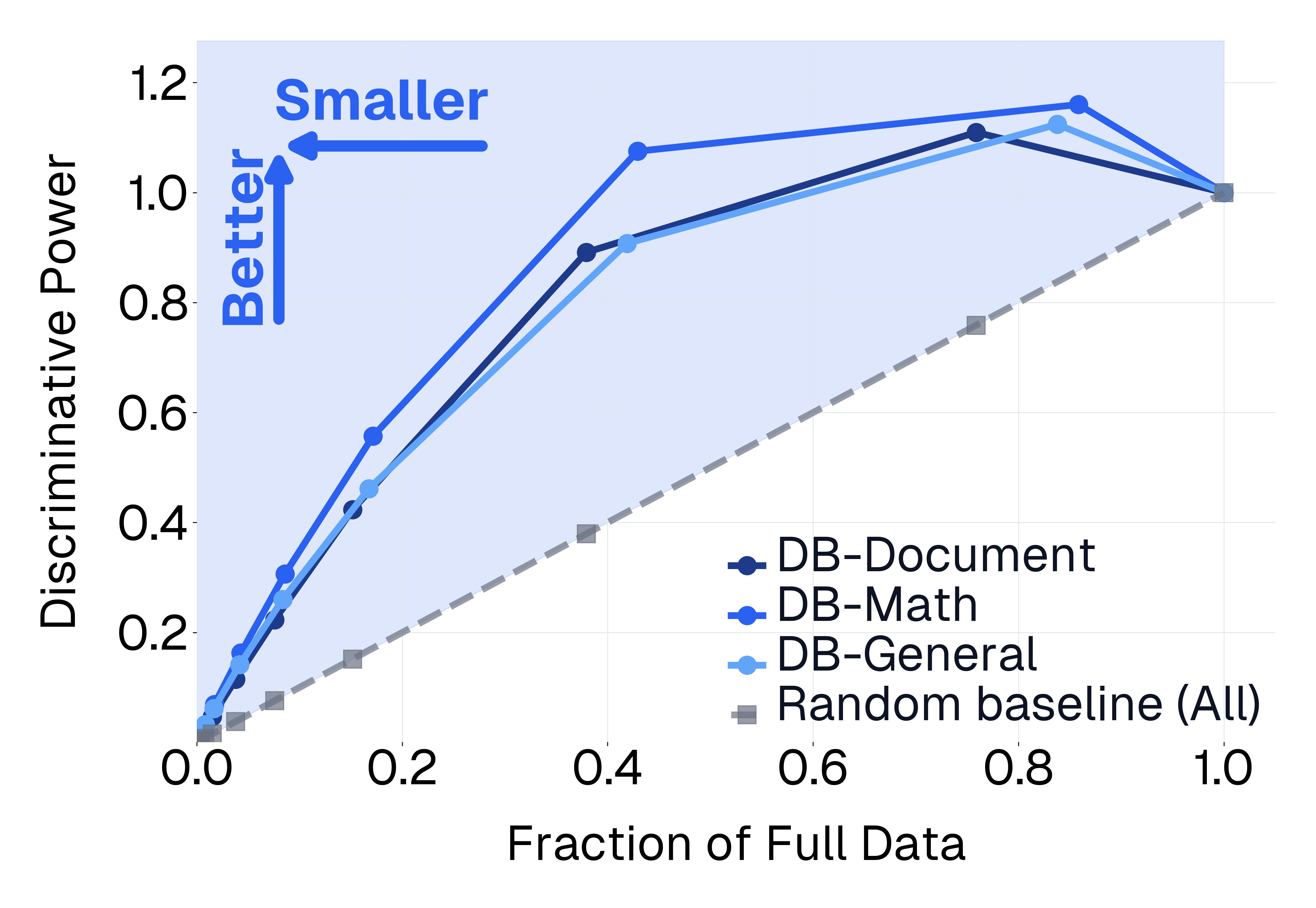
- Fix: Pick the “most informative” questions.
- The authors measure which questions best separate strong models from weak ones (like the best questions on a school exam that really show who understands the topic). This idea is inspired by test theory and uses a simple statistic to find questions where strong models consistently do well and weak models don’t. Keeping these high-signal questions speeds testing up a lot while still giving a clear picture of model skill.
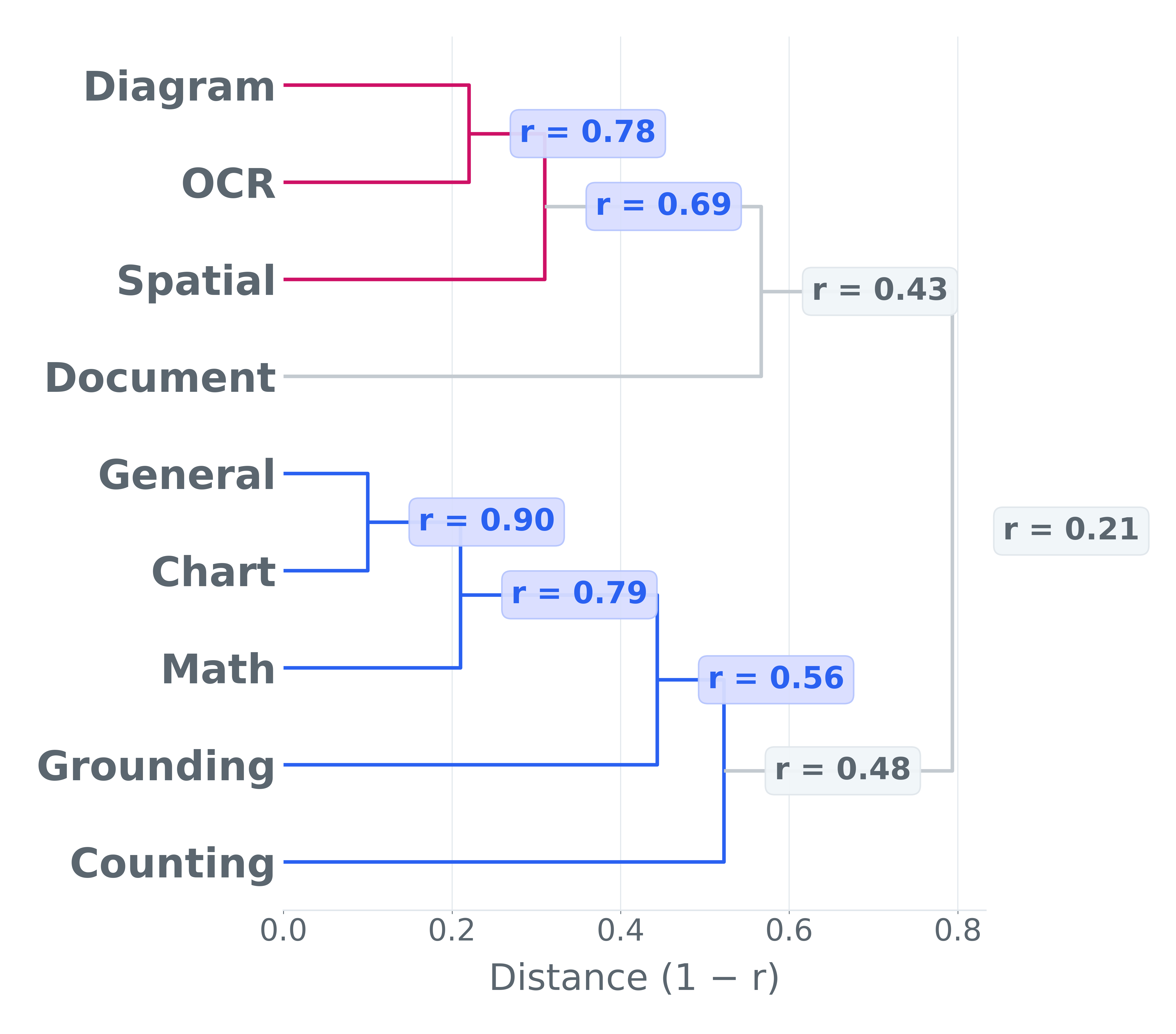
They grouped tasks into nine skills: chart understanding, document understanding, scene text reading (OCR), math/logic, spatial reasoning, grounding (pointing to the right object), counting, diagrams/tables, and general image Q&A.
What they found and why it matters
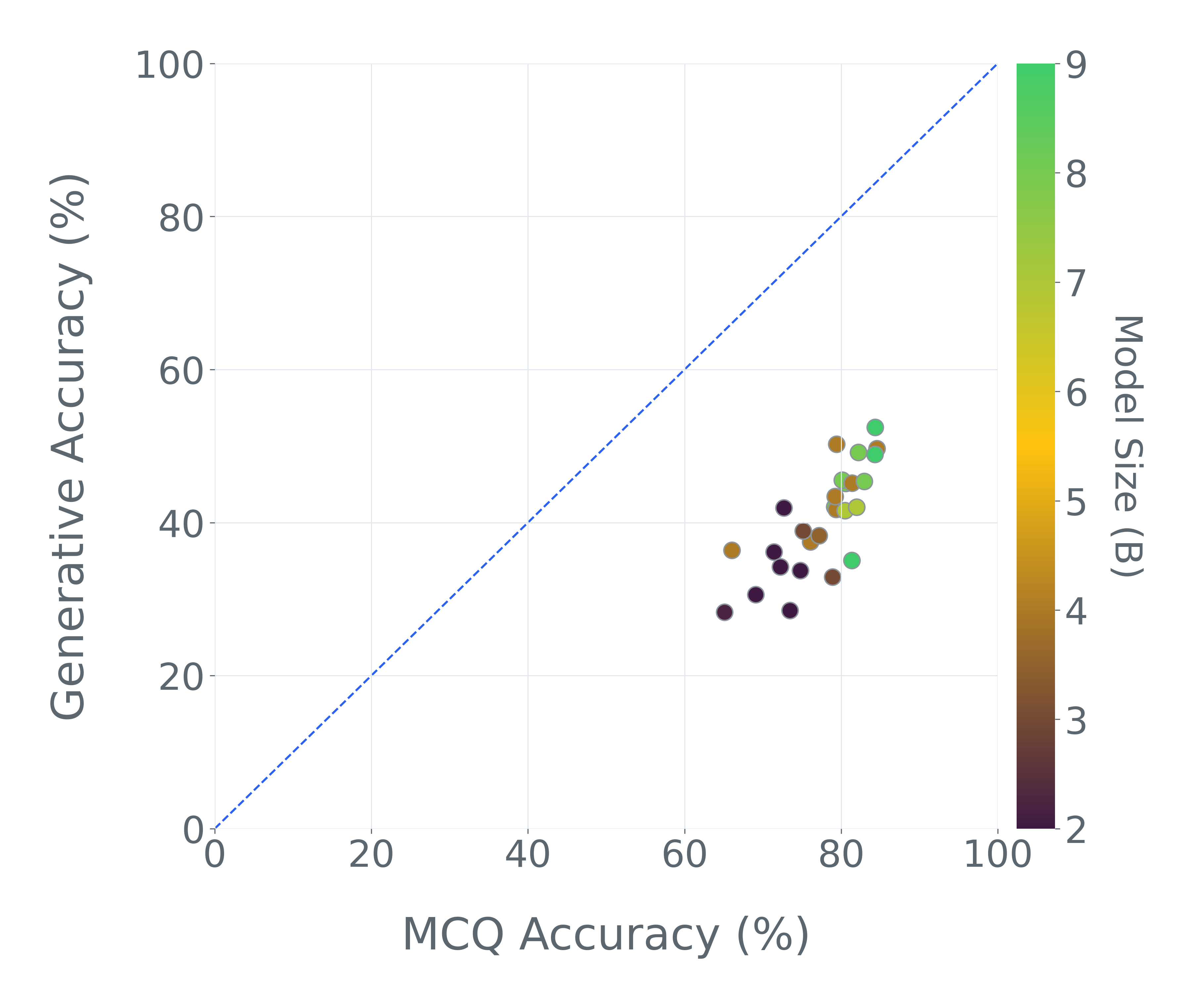
- Multiple-choice can hide real weaknesses:
- When they converted some tests from multiple-choice to “write your own answer,” model scores dropped by as much as 35 percentage points on the same content. That shows the original tests were overestimating what models can do.
- Many questions don’t really need the image:
- In some popular benchmarks, up to about 70% of questions were answerable without seeing the picture. That means scores on those tests don’t reflect true visual understanding.
- A lot of items are low quality:
- In some datasets, up to about 42% of questions were ambiguous, mislabeled, or too low-resolution to judge fairly.
- Huge speedups with little loss of signal:
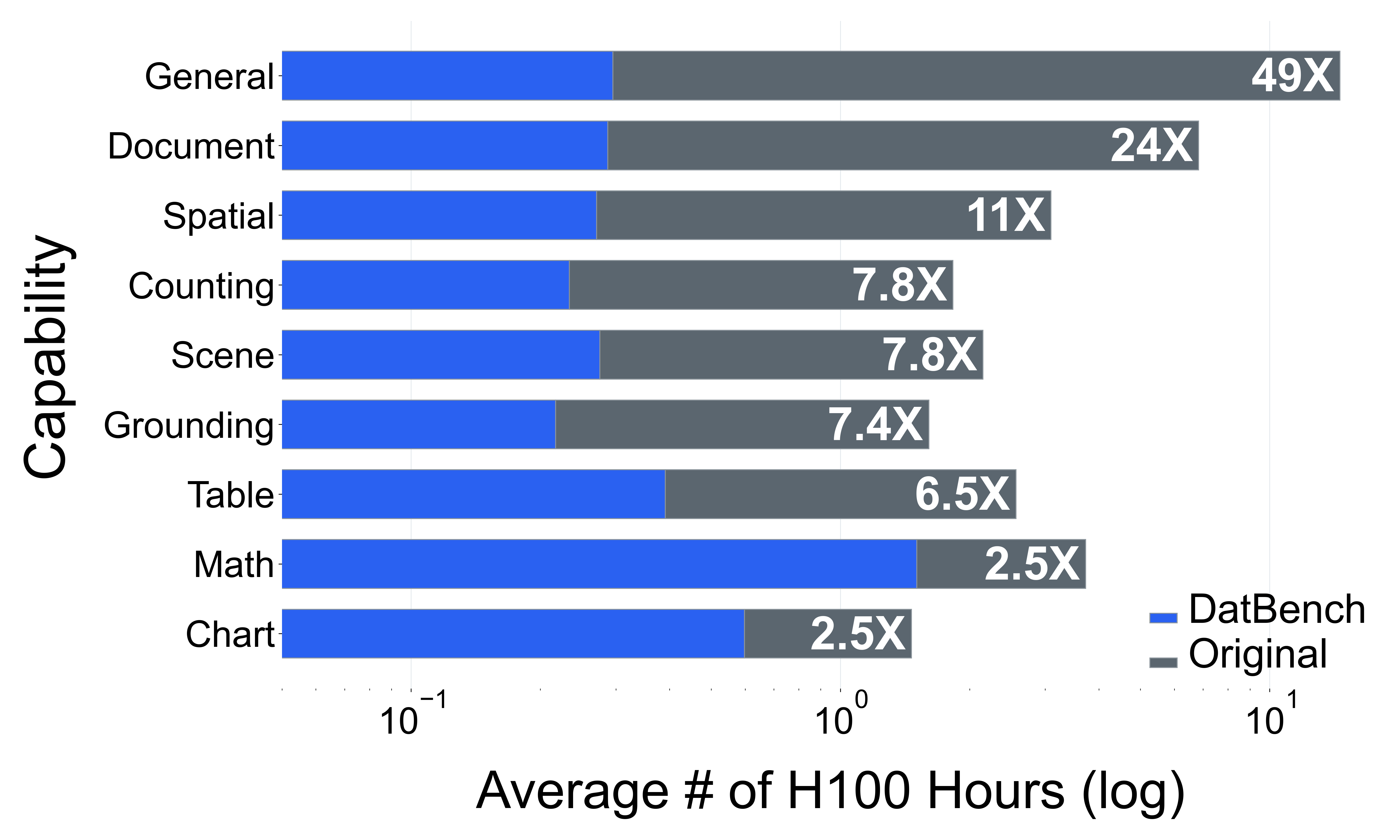
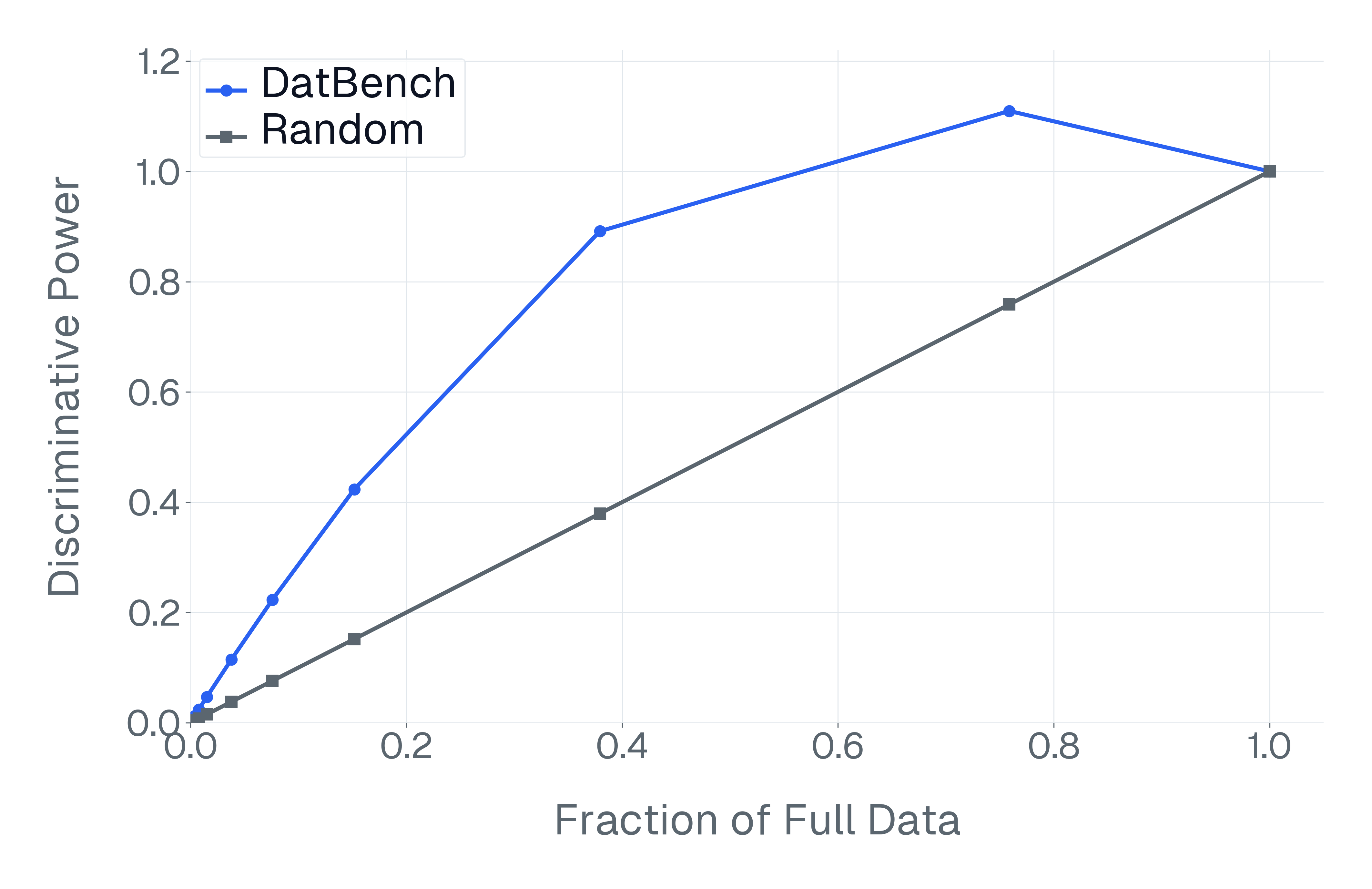
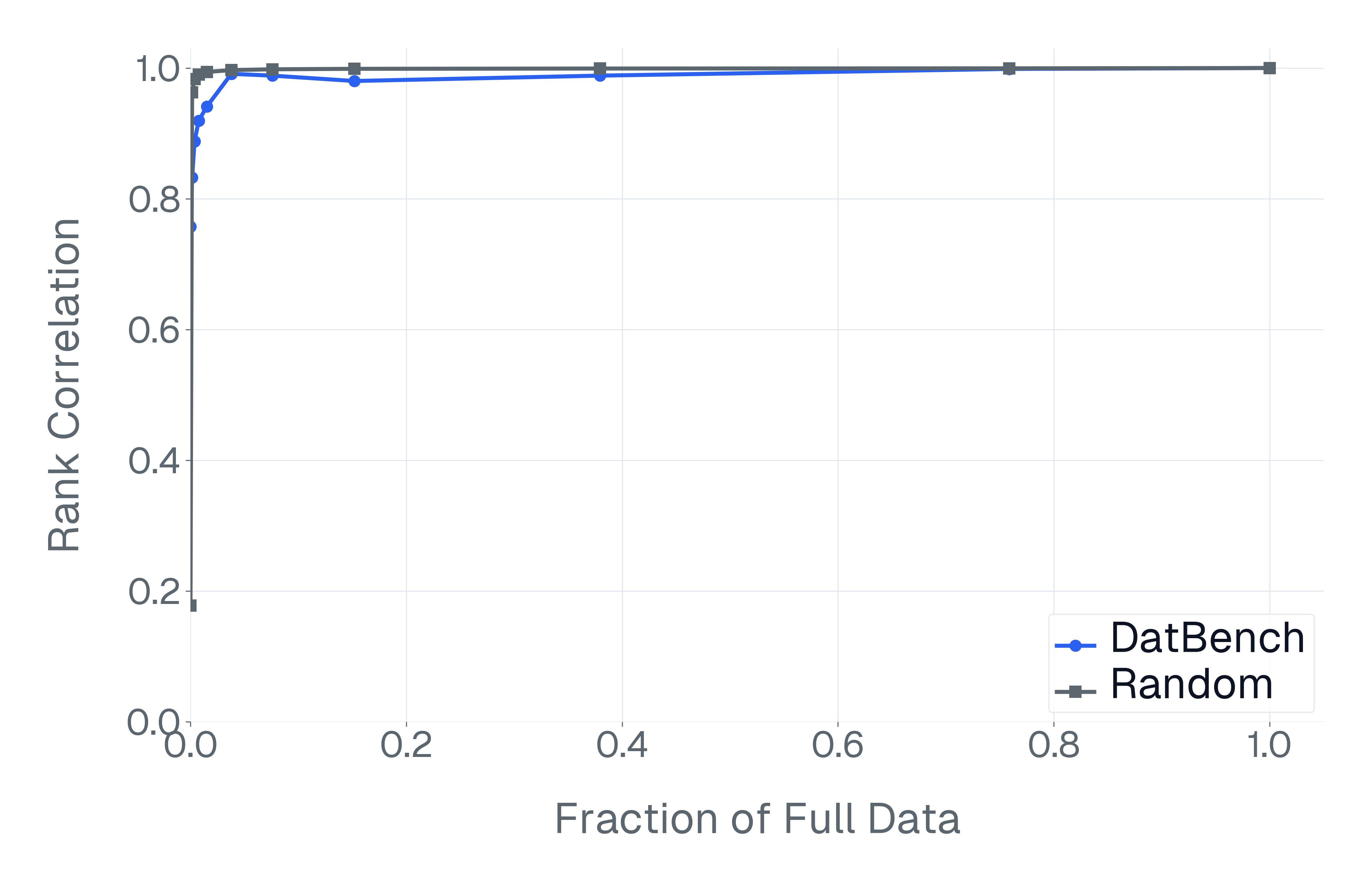
- By keeping only the most informative questions, they got testing to run on average 13× faster (and up to 50× faster) while still separating strong models from weak ones just as well as the full, slower tests.
- In some cases, they matched the “discriminative power” of the full benchmark using only about 40% of the questions.
Why this matters: If tests reward guessing, allow answering without images, or include bad items, we can’t trust the results. Researchers might think they’re making progress when they’re really just getting better at test quirks. These fixes give the community a more honest view of what VLMs can actually do.
What this means going forward
- Better benchmarks, better models: Clear, fair, and efficient tests will help researchers focus on real improvements, not shortcuts.
- Saves time and energy: Faster evaluations mean teams can iterate more quickly and spend less money and power on testing.
- More trustworthy comparisons: The cleaned-up tests make it easier to know which models are truly stronger at visual reasoning.
- A shared resource: The authors release two cleaned-up evaluation suites:
- DatBench: a smaller, high-impact subset for quick, frequent testing.
- DatBench-Full: a larger, high-quality collection after removing bad or “blindly solvable” items.
In short, this paper shows how to turn messy, misleading tests into fair, sharp, and affordable ones—so we can measure what really matters as vision–language AI keeps improving.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies what remains missing, uncertain, or unexplored in the paper, framed to guide future research:
- Quantify and validate the reliability of LLM/VLM-as-judge scoring across domains and formats (math, OCR, multilingual, grounding), including inter-judge agreement, calibration curves, and error modes.
- Provide reproducibility protocols for LLM-as-judge decisions (e.g., public adjudication sets, annotated rationales, and alternate judges) to assess judge bias and sensitivity to prompt phrasing.
- Establish principled, dataset-specific procedures for setting blind-solvability rejection thresholds (τ), including statistical estimation based on answer-space entropy and empirical guessing baselines.
- Develop causal tests for visual necessity (e.g., counterfactual or masked-image probes) beyond simple image removal to isolate cases where visual grounding is actually required.
- Analyze the impact of MCQ-to-generative transformation on task semantics and validity—when removing options fundamentally changes the problem, induces ambiguity, or shifts the required reasoning.
- Systematically compare circular MCQ evaluation against generative conversion on the same items to quantify trade-offs in fidelity, discriminability, and compute.
- Address dependence of discriminative subset selection on the specific suite of 27 models (1B–10B); quantify generalization to unseen architectures, larger models (e.g., 30B–70B+), and different training paradigms.
- Extend item-level discrimination beyond point-biserial correlation to multi-dimensional latent traits (e.g., vision, language, OCR, spatial, math) to avoid conflating heterogeneous capabilities in a single scalar.
- Incorporate graded/partial credit for complex generative tasks (e.g., multi-step math or multi-attribute reasoning) rather than binary correctness to better reflect nuanced capability differences.
- Measure stability of discriminative selection under inference variance (temperature, decoding strategy, max tokens), especially for “thinking” models with long chains-of-thought.
- Provide uncertainty estimates (confidence intervals, bootstrap) on discriminative scores, rank correlations, and speedup metrics to separate true signal from sampling noise.
- Study adversarial vulnerability of LLM-as-judge scoring (e.g., targeted phrasing, hallucinated self-justifications) and propose robust judging protocols resilient to strategic responses.
- Evaluate multilingual coverage and judge competency on bilingual/multilingual OCR tasks; quantify errors from judge language limitations and propose language-specific judges or ensembles.
- Investigate prompt-sensitivity effects in both model generation and judge scoring; design standardized multi-prompt evaluation to mitigate single-prompt bias.
- Clarify and audit the criteria for “frontier” item inclusion (up to 20% in DatBench): how this proportion is chosen, how it affects difficulty distribution, and whether it varies by capability.
- Develop mechanisms to fix and retain mislabeled or ambiguous items (label correction pipelines, expert re-annotation, confidence-weighted inclusion) rather than discarding them outright.
- Explore super-resolution, intelligent cropping, or multi-view augmentation to rescue low-resolution or visually indeterminable samples instead of removing them.
- Provide rigorous guidance on when MCQ is the correct evaluation format (e.g., credentialing, compliance audits) and how to design faithful MCQ that minimizes guessing and positional biases.
- Examine potential overfitting of discriminative selection to superficial artifacts (e.g., language priors, test leakage), including detecting negative or spurious item discrimination at scale.
- Systematically address test-set leakage risks (near-duplicates or stylistic overlap with web-scale training corpora) via multimodal deduplication and leakage audits.
- Extend the evaluation beyond image-centric tasks to richer modalities (video, audio, temporal reasoning) and compositional multi-turn interactions to reflect real deployment contexts.
- Benchmark grounding metrics beyond localization (e.g., IoU) to include referential consistency, relational grounding, and multi-object disambiguation under complex language.
- Study fairness and safety implications of filtering out “ambiguous” real-world cases (e.g., autonomous driving): how to evaluate models on inherently uncertain scenarios without penalizing risk-aware behavior.
- Provide transparent compute accounting: sensitivity of reported speedups to batching, hardware, kv-cache configurations, and output-length distribution, especially for long CoT models.
- Design adaptive evaluation that refreshes difficulty over time (dynamic item pools, online item calibration) to prevent saturation as models improve.
- Quantify cross-capability interference (e.g., tension between high-level reasoning and low-level perception) with controlled experiments and item families that isolate specific skills.
- Investigate whether discriminative subsets preserve fine-grained ordering among near-frontier models (small deltas), not just coarse tiers (1B vs. 8B).
- Define principled policies for τ in constrained-answer domains (counting, small-integer outputs) using empirical answer distributions rather than fixed heuristics.
- Report per-capability score distributions and effect sizes before/after filtering to show how signal-to-noise changes and where discrimination gains originate.
- Evaluate judge consistency on diagram-heavy scientific domains (e.g., CharXiv, AI2D) where domain expertise and precise terminology can challenge semantic matching.
- Provide open protocols for community contributions (e.g., appeals, re-judging, item fixes) and versioning that maintains longitudinal comparability while improving data quality.
- Assess how DatBench selection affects downstream optimization (model training or alignment), avoiding “train-on-benchmark” feedback loops that distort evaluation integrity.
- Explore ensemble judging or hybrid scoring (LLM-as-judge plus symbolically grounded checks) to reduce reliance on a single model and capture formal correctness (math, units, coordinates).
- Calibrate the trade-off between circular evaluation’s compute cost (multiple passes) and the overall efficiency goals; provide thresholds where circular evaluation becomes preferable.
Practical Applications
Immediate Applications
- Boldly reduce evaluation compute with DatBench (AI/ML industry, cloud, MLOps)
- What to do: Replace large, noisy VLM eval suites with DatBench for routine regression testing and model selection; expect ~13× average and up to 50× speedups while maintaining discriminative power.
- Tools/workflows: DatBench/DatBench-Full from Hugging Face; GitHub code; integrate a “DatBench Runner” step in CI/CD to gate merges by per-capability deltas.
- Assumptions/dependencies: Your target tasks map to DatBench’s nine capabilities; licensing/redistribution terms of the underlying datasets; reproducible inference settings across runs.
- Build capability scorecards for procurement and deployment decisions (enterprise IT, healthcare, finance, retail)
- What to do: Use DatBench’s nine-capability breakdown (e.g., Document Understanding, Scene OCR, Counting, Spatial Reasoning) to produce model scorecards matched to application requirements (e.g., invoice KIE, storefront OCR, shelf counting, spatial awareness).
- Tools/workflows: Capability dashboards; thresholds/SLOs per capability; side-by-side comparisons of candidate models on discriminative subsets.
- Assumptions/dependencies: Task-to-capability alignment; standardized prompts; controlled prompting to avoid confounding instruction-following differences.
- Add a “no-image baseline” gate to catch blind-solvable tests (safety teams, QA, academia)
- What to do: Run each evaluation twice—once with and once without the image—and reject or downweight items that pass without vision (per-paper τ thresholds) to ensure true multimodal measurement.
- Tools/workflows: Automated no-image ablation; dataset-level histograms of blind-solvability; per-capability pass/fail gates.
- Assumptions/dependencies: Additional inference passes for ablation; chosen τ thresholds tuned by task format (generative vs constrained-answer).
- Convert MCQs to generative or adopt circular MCQ evaluation (benchmark maintainers, academic labs, online leaderboards)
- What to do: Transform MCQ items into open-ended prompts with LLM-as-judge scoring; where MCQ is essential, use circular evaluation (option permutations) to collapse chance baselines and reduce inflation.
- Tools/workflows: MCQ-to-Gen converter; circular evaluation harness; semantic answer matching via a cost-effective judge (e.g., Qwen3-30B).
- Assumptions/dependencies: Reliable LLM-as-judge configuration and prompt templates; accepted answer normalization policies in your community/organization.
- Automate dataset QC with VLM-as-judge filters (data vendors, research orgs, internal eval teams)
- What to do: Run a two-stage pipeline: flag unanimous model failures, then have a strong VLM/LLM judge verify ambiguous labels, incorrect ground truth, or low-resolution images; remove or fix flagged items.
- Tools/workflows: Judge-backed QC scripts; reviewer queues for edge cases; integration with annotation tooling.
- Assumptions/dependencies: Access to a strong judge (frontier LLM/VLM); governance to audit judge mistakes; domain exceptions (specialized tasks may require human experts).
- Fast, compute-aware iteration for small/edge models (mobile/embedded ML, automotive, robotics)
- What to do: Use discriminative subsets to compare 1B–10B variants frequently during training; shorten feedback loops without losing signal on true capability differences.
- Tools/workflows: Lightweight nightly evals; capability-targeted smoke tests (e.g., OCR, spatial) before full-suite runs.
- Assumptions/dependencies: Stable inference parameters; careful sampling to avoid overfitting to the discriminative subset.
- Construct custom, domain-specific benchmarks with the four-step recipe (regulated industries, public sector, legal tech)
- What to do: Apply the paper’s pipeline—MCQ transformation, blind-solve filtering, judge-based QC, discriminative selection—to your domain (e.g., medical charts, legal forms) to create faithful and efficient evaluation sets.
- Tools/workflows: Domain-appropriate scoring rubrics; curated “frontier item bank” to preserve headroom; documented τ thresholds and QC criteria.
- Assumptions/dependencies: Availability of domain-competent judges/humans; data privacy; agreement on acceptable generative scoring in the domain.
- Lower cost and carbon of evaluation (R&D leadership, sustainability teams, cloud FinOps)
- What to do: Swap full benchmarks for DatBench to cut evaluation tokens; incorporate evaluation compute into cost/CO₂ reporting; schedule evals during lower-carbon time windows.
- Tools/workflows: H100-hour tracking; token accounting; carbon-intensity-aware job scheduling.
- Assumptions/dependencies: Accurate measurement of compute and emissions; enterprise reporting policies.
- Create red-team triage lists from retained frontier items (AI safety, reliability engineering)
- What to do: Focus stress-testing on verified, currently-unsolved items to monitor failure modes (e.g., perception vs reasoning tension, overthinking penalty); track emergence over model updates.
- Tools/workflows: Frontier item dashboards; regression alerts keyed to capability domains; postmortems linking failures to model changes.
- Assumptions/dependencies: Consistent evaluation seeds; logging and traceability for chain-of-thought length and perception regressions.
- Improve reproducibility in publications and courses (academia, open-source communities)
- What to do: Standardize on DatBench-Full for paper comparisons and course labs; cite per-capability performance with generative scoring and blind-solve checks to avoid inflated claims.
- Tools/workflows: Shared eval configs; public leaderboards showing both vanilla and corrected (generative/circular) metrics.
- Assumptions/dependencies: Community adoption; willingness to report both inflated and corrected scores for transparency.
Long-Term Applications
- Certification-grade, faithful VLM evaluations for regulated domains (policy, healthcare, automotive)
- What could emerge: Regulatory standards that mandate blind-solve analysis, generative scoring, and judge-backed QC for claims on document understanding (e.g., EHR OCR), diagnostic diagrams, or spatial reasoning in ADAS.
- Dependencies: Consensus on generative scoring validity; sector-specific ground truthing; legal frameworks for AI audits.
- Evaluation-as-a-Service platforms with discrimination-aware workflows (cloud, MLOps vendors)
- What could emerge: Managed services that host curated item banks per capability, run circular/generative protocols, track frontier items, and expose APIs/dashboards for procurement decisions.
- Dependencies: Dataset licensing; privacy/security for proprietary test images; standardized metadata schemas.
- Community-maintained item banks with IRT-scale stability (benchmarking consortia, standards bodies)
- What could emerge: Large response matrices across many models enabling robust IRT parameterization; continuous refresh with automated blind-solve and QC checks; stratified capability ladders.
- Dependencies: Broad model participation; contributor agreements; governance to mitigate test-set leakage and gaming.
- Carbon- and cost-aware evaluation standards (sustainability, finance, cloud infrastructure)
- What could emerge: Industry-wide benchmarks that report “signal-per-token” and emissions for evaluation; procurement SLAs requiring efficient evaluation practices.
- Dependencies: Accepted carbon accounting methods for inference; alignment between vendors and customers on efficiency metrics.
- Automated benchmark maintenance with hybrid (human + VLM) judging (annotation ecosystem, marketplaces)
- What could emerge: Continuous pipelines that flag ambiguous/low-res items at ingestion, propose label fixes, and route edge cases to domain experts—keeping benchmarks fresh as models evolve.
- Dependencies: Reliable judge models; human-in-the-loop budgets; provenance tracking for labels and revisions.
- Hardware–software co-design for evaluation workloads (semiconductors, systems)
- What could emerge: Runtime primitives for evaluation-specific sampling, early stopping on low-discrimination items, and batch scheduling optimized for multi-pass (circular) MCQ runs.
- Dependencies: Vendor support; interface standards in serving stacks; evidence that hardware-level optimizations generalize.
- Training data selection informed by discriminative metrics (model training, data engineering)
- What could emerge: Active learning or curriculum systems borrowing point-biserial/IRT-like signals to maximize training signal per token, complementing evaluation-side gains.
- Dependencies: Empirical validation that discriminative selection transfers to training; safeguards against distributional bias.
- Domain- and subgroup-aware capability scorecards for fairness (compliance, risk)
- What could emerge: Audits that require demonstrating a gap between with-image and no-image performance across subgroups/domains, mitigating spurious language-prior advantages.
- Dependencies: Representative subgroup datasets; approved fairness metrics for multimodal settings; careful τ calibration per subgroup.
- Generalization of the pipeline to video, audio, and 3D modalities (robotics, media, AR/VR)
- What could emerge: Faithful, discriminative, efficient benchmarks for temporal and spatial reasoning in video (e.g., surveillance, sports), audio-visual grounding, and 3D perception.
- Dependencies: Multimodal judges; scalable generative scoring across time; storage and privacy constraints.
- Education assessments moving from MCQ to generative with AI-as-judge (edtech, testing)
- What could emerge: Exams and MOOCs that adopt circular/generative scoring and automated QC to reduce guessing and better measure reasoning on diagrams, charts, and math problems.
- Dependencies: Stakeholder acceptance; robust anti-cheating/proctoring; transparent rubrics for AI-judged grading.
Notes on cross-cutting assumptions:
- LLM/VLM-as-judge reliability: Judging models can mis-score edge cases; high-stakes settings require human oversight and documented adjudication policies.
- Thresholds and transformations: τ thresholds and MCQ-to-generative conversions must be tuned per task to avoid changing problem semantics.
- Representativeness: Discriminative subsets should be periodically re-estimated as model families and capabilities evolve to prevent overfitting to historical tiers.
Glossary
- Blind solvability: The phenomenon where a model answers correctly using only textual cues, without needing the image. Example: "A significant challenge in VLM evaluation is ``blind solvability''"
- Chain-of-thought: A generated step-by-step reasoning trace used by models during inference. Example: "generating chains-of-thought exceeding 32K tokens"
- Chance baseline: The expected accuracy a model can achieve by random guessing in a multiple-choice setting. Example: "chance baseline ($1/N$ for options)"
- Circular evaluation: An MCQ protocol that permutes options and requires consistent correct answers across permutations to collapse chance performance. Example: "circular evaluation \citep{liu2024mmbench} collapses chance baselines"
- Cross-modal connector: The component linking visual and language representations within a VLM. Example: "the vision encoder or cross-modal connector"
- Embedding-based clustering: Selecting or grouping items using vector embeddings to capture semantic similarity. Example: "\citet{vivek2024anchor} employ embedding-based clustering to select representative subsets"
- Grounding: Linking text to specific image regions via localization (e.g., boxes or masks). Example: "Grounding: identifying and localizing specific regions or objects referred to in text through bounding boxes or segmentation-style tasks;"
- Inference-time compute scaling: Increasing computation during inference (e.g., longer reasoning) to boost performance. Example: "utilize inference-time compute scaling, often generating chains-of-thought exceeding 32K tokens"
- Item discrimination: How well an item separates high-ability from low-ability models. Example: "item difficulty and discrimination"
- Item Response Theory (IRT): A psychometric framework modeling item difficulty and discrimination to analyze responses. Example: "Item Response Theory (IRT) motivated weighting"
- Key Information Extraction (KIE): Extracting structured fields from documents (e.g., forms, receipts). Example: "Key Information Extraction (KIE) from structured forms and receipts."
- Kendall’s τ: A nonparametric statistic measuring rank correlation between orderings. Example: "Kendallâs "
- Language priors: Statistical regularities in text that models exploit to answer without visual evidence. Example: "language priors alone."
- LLM-as-judge: Using a LLM to grade or semantically match model outputs. Example: "we employ an LLM-as-judge (specifically Qwen3-30B ... ) to perform semantic answer matching"
- MCQ-to-Generative Transformation: Reformulating multiple-choice questions as open-ended generation tasks. Example: "MCQ-to-Generative Transformation and Circular MCQ Evaluation"
- Multimodal embeddings: Joint vector representations spanning text and images. Example: "the lack of unified multimodal embeddings"
- Multiple Choice Question (MCQ): A format where the model selects an answer from provided options. Example: "Multiple Choice Questions (MCQs)"
- Option-robust MCQ protocols: MCQ methods designed to reduce option-specific biases and spurious effects. Example: "option-robust MCQ protocols"
- Overthinking penalty: Performance degradation from excessive reasoning during inference. Example: "inference-time scaling can actively degrade perceptual performance through an overthinking penalty"
- Pareto frontier: The set of models that are not dominated on multiple performance dimensions. Example: "distinguish models along the Pareto frontier"
- Plackett-Luce models: Probabilistic models for ranking data used to aggregate ordinal preferences. Example: "aggregating heterogeneous evaluations via Plackett-Luce models"
- Point-biserial correlation (r_pb): A statistic measuring association between a binary outcome and continuous ability, used to score item discrimination. Example: "point-biserial correlation ()"
- Psychometric modeling: Statistical methods from measurement theory (e.g., IRT) used to analyze test items and abilities. Example: "psychometric modeling"
- Rank correlation: Measures of agreement between model orderings produced by different evaluations or subsets. Example: "rank correlation measures such as Spearmanâs or Kendallâs "
- Referring expression segmentation: Segmenting the region specified by a natural-language expression. Example: "referring expression segmentation"
- Referring expressions: Natural-language phrases that identify specific objects or regions in an image. Example: "General referring expressions (allows both appearance and location words)."
- Semantic answer matching: Grading generated answers by semantic equivalence rather than exact string match. Example: "to perform semantic answer matching"
- Signal-to-noise ratio: The proportion of meaningful evaluative signal relative to noise or artifacts. Example: "reduce the signal-to-noise ratio of the evaluations"
- Spearman’s ρ: A nonparametric statistic measuring monotonic rank correlation. Example: "Spearmanâs "
- Visual Question Answering (VQA): Answering natural-language questions about images. Example: "performing high-level Visual Question Answering (VQA)"
- Visual token sequences: Long sequences of tokens representing image content for transformer models. Example: "the dense visual token sequences required to represent high-resolution images"
- Vision-LLM (VLM): A model that processes and reasons over both images and text. Example: "vision-LLMs (VLMs)"
- VLM-as-judge: Using a vision-LLM to verify data quality or evaluate answers. Example: "VLM-as-Judge Quality Filtering."
Collections
Sign up for free to add this paper to one or more collections.