Entropy-Adaptive Fine-Tuning: Resolving Confident Conflicts to Mitigate Forgetting
Abstract: Supervised Fine-Tuning (SFT) is the standard paradigm for domain adaptation, yet it frequently incurs the cost of catastrophic forgetting. In sharp contrast, on-policy Reinforcement Learning (RL) effectively preserves general capabilities. We investigate this discrepancy and identify a fundamental distributional gap: while RL aligns with the model's internal belief, SFT forces the model to fit external supervision. This mismatch often manifests as "Confident Conflicts" tokens characterized by low probability but low entropy. In these instances, the model is highly confident in its own prediction but is forced to learn a divergent ground truth, triggering destructive gradient updates. To address this, we propose Entropy-Adaptive Fine-Tuning (EAFT). Unlike methods relying solely on prediction probability, EAFT utilizes token-level entropy as a gating mechanism to distinguish between epistemic uncertainty and knowledge conflict. This allows the model to learn from uncertain samples while suppressing gradients on conflicting data. Extensive experiments on Qwen and GLM series (ranging from 4B to 32B parameters) across mathematical, medical, and agentic domains confirm our hypothesis. EAFT consistently matches the downstream performance of standard SFT while significantly mitigating the degradation of general capabilities.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a common problem when teaching big AI LLMs new skills: they often get better at the new thing but forget how to do general tasks they used to do well. The authors explain why this happens during a common training method called Supervised Fine-Tuning (SFT), and they introduce a new approach, Entropy-Adaptive Fine-Tuning (EAFT), that helps the model learn new skills without losing its overall abilities.
What questions are the researchers trying to answer?
- Why does Supervised Fine-Tuning (SFT) often make models forget general skills, while Reinforcement Learning (RL) tends to keep them?
- Can we change how we train with SFT so the model learns the new domain (like math or medical tasks) but still keeps its general knowledge?
- Will that new training trick work across different kinds of tasks and different model sizes?
How did they approach the problem?
First, a quick guide to key ideas in simple terms:
- Token: Think of a token as a piece of text, like a word or part of a word, that the model predicts next.
- Probability: How sure the model is that a specific token should come next. High probability means “I’m very confident,” low probability means “I’m not very confident.”
- Entropy: A measure of uncertainty. High entropy means the model is unsure and is considering many options; low entropy means it’s very sure and focused on a few options.
The authors compared two training styles:
- Supervised Fine-Tuning (SFT): The model is shown “correct” answers written by humans or stronger models and is forced to match them.
- Reinforcement Learning (RL): The model generates its own answers and learns based on rewards, staying closer to what it already believes.
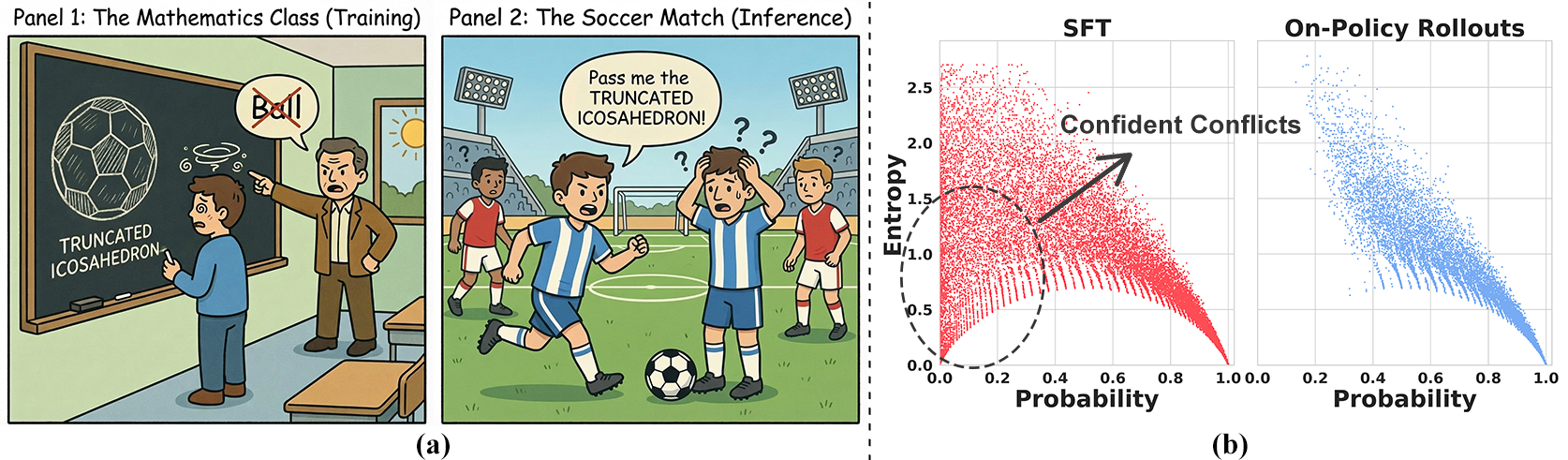
They discovered a special kind of clash in SFT called “Confident Conflicts.” This happens when:
- The model is very sure about its own next word (low entropy),
- But that word disagrees with the training label (low probability for the label). In other words, the model thinks “this is definitely the right word,” but the training data says “no, use a different word.” Forcing the model to change in these cases can cause large, destructive updates—like yanking hard on an already-tight knot—leading the model to forget useful general knowledge.
To fix this, they created EAFT:
- EAFT looks at each token and measures its entropy (uncertainty).
- If the model is very uncertain (high entropy), EAFT lets the training push harder, because the model is still exploring and open to learning.
- If the model is very certain but disagrees (low entropy + low probability), EAFT softens the training signal so it doesn’t aggressively overwrite the model’s existing knowledge.
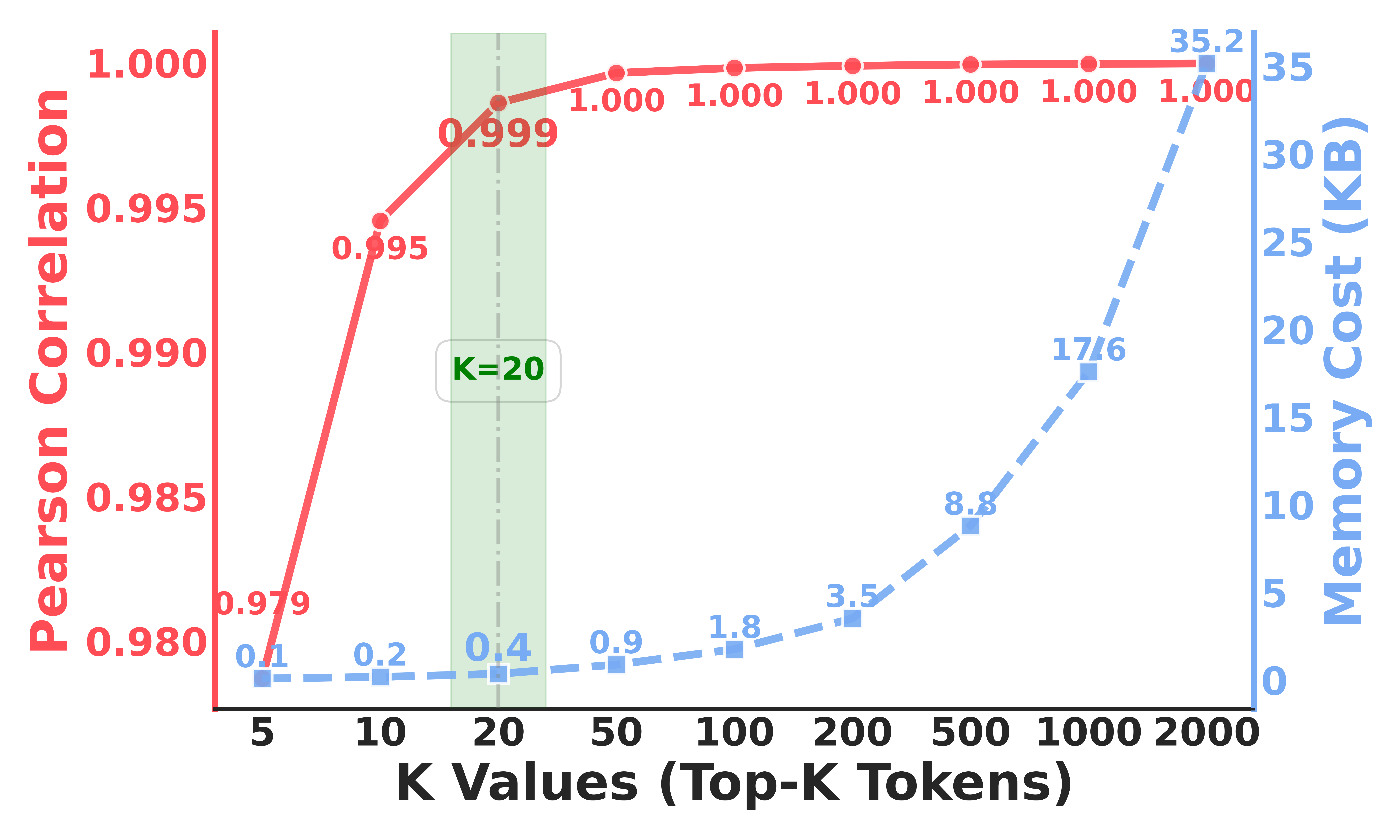
A practical trick: Instead of calculating entropy over all possible words (which is slow), EAFT estimates entropy using just the top 20 most likely tokens. This is fast and, according to their tests, almost as accurate as the full calculation.
What did they find, and why does it matter?
Main findings:
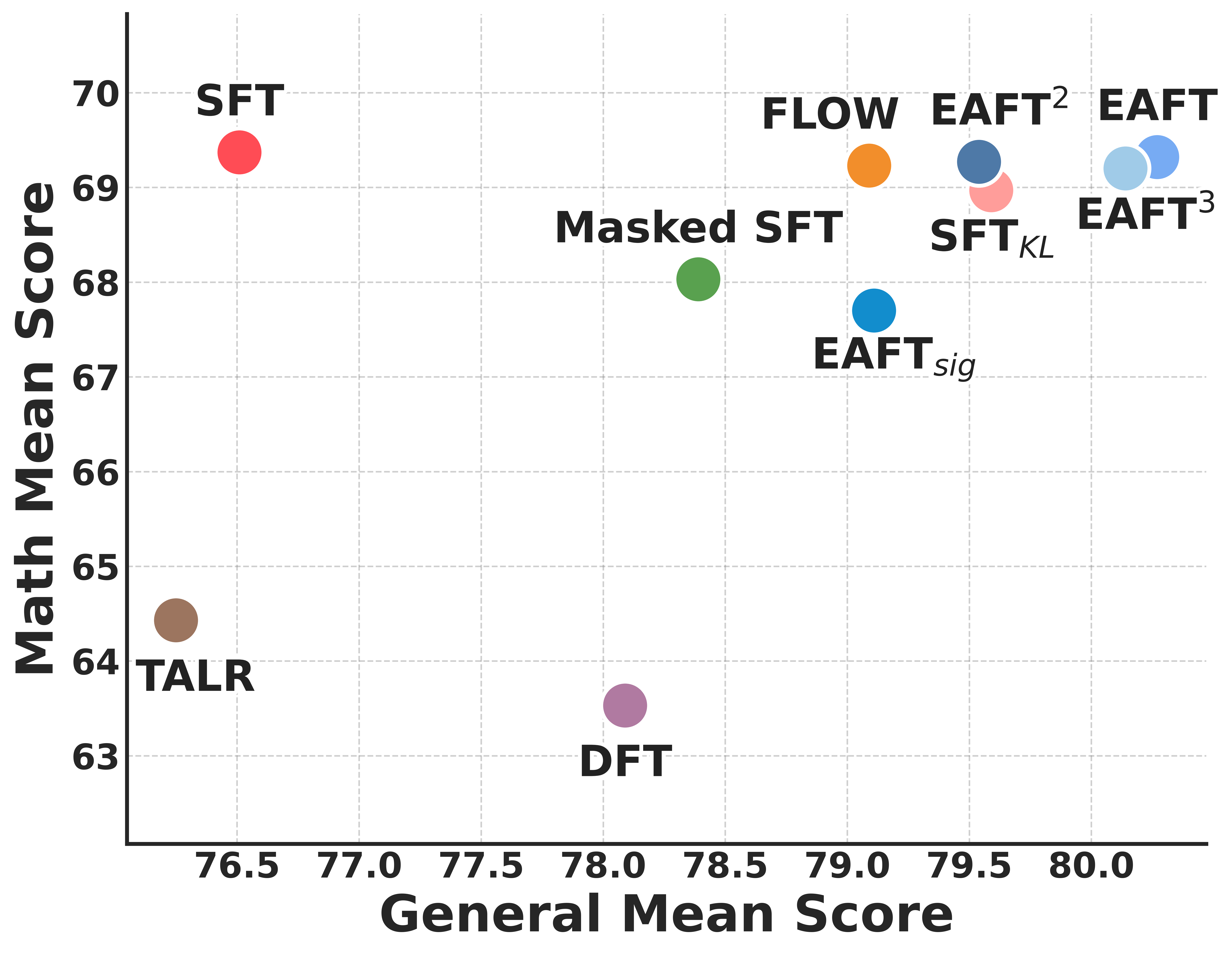
- EAFT keeps general skills strong while still improving performance in the new target domain (like math or medical tasks).
- It works across different model families (such as Qwen and GLM) and sizes (from 4 billion to 32 billion parameters).
- It reduces the sharp “forgetting” drops that standard SFT often causes on general benchmarks (like MMLU or IFEval), while staying competitive on the specialized tasks.
Why it matters:
- Many teams want to specialize big models (for math reasoning, medical Q&A, or tool-use) without turning them into “single-purpose” models that forget everything else. EAFT helps strike that balance.
- It’s simple to add to existing training: you use entropy as a weight to tone down harmful updates and focus on helpful ones.
- It’s efficient: the top-20 entropy trick makes it cheap to compute.
What is the bigger impact of this research?
If widely adopted, EAFT could make fine-tuned models more reliable in real-world use:
- Companies and researchers can build specialized systems that still understand everyday language and tasks.
- Continuous learning (adding new skills over time) becomes safer, with less risk of “catastrophic forgetting.”
- It may reduce the need for heavier methods like RL when SFT is preferred, by making SFT smarter about where to push and where to hold back.
A simple analogy
Imagine a student with strong general knowledge. In SFT, a teacher sometimes insists the student memorize an answer the student strongly believes is wrong. That forceful correction can mess up the student’s broader understanding. EAFT is like a teacher who looks at how unsure the student is: if the student is unsure, the teacher teaches more firmly; if the student is very sure but in conflict, the teacher eases up, avoiding damage to the student’s core knowledge while still helping them adapt over time.
A note on limitations
- EAFT is not ideal when you truly need to overwrite the model’s beliefs (for example, correcting facts or teaching counterfactuals like “the sky is green”). EAFT may resist those changes on purpose.
- If your only goal is to maximize the new task score no matter what, standard SFT might still edge out EAFT in some cases.
- EAFT assumes the model’s high-confidence beliefs are mostly useful. If a model is confidently wrong, EAFT could protect those mistakes unless you also add ways to detect and correct them.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise list of concrete knowledge gaps and open questions the paper leaves unresolved, intended to guide future research.
- Causal verification of “Confident Conflicts” as the driver of forgetting: Design controlled interventions (e.g., synthetic conflicts, counterfactual labels, randomized masking) to establish causality beyond correlational pilot results.
- Entropy as an uncertainty proxy: Disentangle epistemic vs. aleatoric uncertainty and address confidence calibration; compare entropy-gating against calibrated uncertainty estimates (ensembles, MC dropout, temperature scaling, trust-region metrics).
- When to override confident priors: Develop principled criteria or signals (e.g., verified external facts, human labels with provenance) to selectively disable gating for knowledge editing and factual updates without undermining retention.
- Joint probability–entropy gating: Evaluate gating functions that explicitly combine low probability and low entropy to more precisely target conflicts and avoid suppressing useful high-confidence corrections.
- Learning the gating function: Derive or learn an “optimal” gating function f(H) (e.g., meta-learning, bilevel optimization) and adaptive schedules that react to domain shifts, training progress, or downstream validation feedback.
- Top-K entropy approximation validity: Test the Top-K entropy fidelity across languages, tokenizers, vocabularies, temperatures, and model scales; quantify sensitivity to K in regimes with flatter distributions or rare-token updates.
- Domain and benchmark breadth: Extend “general capabilities” beyond MMLU/IFEval/CLUEWSC to reasoning (BBH), coding (HumanEval), summarization, multimodal tasks, safety, robustness, and long-context settings; include multilingual evaluations.
- Long-horizon continual learning: Assess EAFT in multi-stage, multi-domain curricula (e.g., Math→Medical→Code→Safety), measuring retention and interference over extended training horizons and task re-visitation.
- Interaction with on-policy RL: Study EAFT within RL pipelines (e.g., PPO, R1) and hybrid post-training (SFT→RL→SFT), including whether entropy gating complements or conflicts with policy-gradient updates and KL control.
- Confidence calibration impacts: Measure how EAFT affects calibration (ECE, Brier score) and whether gating improves or worsens miscalibrated high-confidence errors; integrate calibration-aware adjustments.
- Error correction capability: Quantify EAFT’s effect on correcting wrong priors and updating outdated facts using targeted datasets (e.g., fact-revision suites, hallucination correction benchmarks).
- Token- vs sequence-level gating: Explore span/sequence-level gating (e.g., per reasoning step, per tool-call block) to capture structured conflicts and assess impacts on syntax-heavy tasks and formatting adherence.
- Parameter-space and layer-wise effects: Analyze which parameters and layers EAFT protects/updates (Fisher information, parameter drift, subspace alignment) to explain retention mechanisms and guide targeted regularization.
- Safety and bias preservation: Investigate whether EAFT unintentionally preserves harmful or biased high-confidence priors; integrate safety-aware gating or auxiliary signals to avoid locking in undesirable behaviors.
- Data quality and teacher bias: Evaluate EAFT under label noise, teacher-model bias, and domain mismatches; develop diagnostics to detect spurious “conflicts” originating from imperfect supervision.
- Scaling laws and compute: Characterize how EAFT’s benefits scale with model size, dataset size, and training compute; establish empirical scaling curves and cost–benefit analyses.
- Cross-lingual and multilingual applicability: Test EAFT across non-English languages and mixed-language corpora where entropy distributions and tokenization artifacts differ significantly.
- Hyperparameter robustness and failure modes: Conduct comprehensive sweeps (learning rate, batch size, temperature, KL regularization, K) with confidence intervals; document regimes where EAFT fails or underperforms SFT.
- Theoretical guarantees: Provide formal bounds linking entropy-gated loss to reduced forgetting (e.g., gradient norm control, KL divergence limits to base model, stability under distribution shift) and state required assumptions.
- Deployment considerations: Assess EAFT’s interaction with inference-time decoding (temperature, nucleus sampling), tool-use runtime behavior, and whether training-time entropy gating introduces downstream side effects.
Glossary
- AIME24: A benchmark subset of American Invitational Mathematics Examination problems used to evaluate math reasoning in LLMs. "We evaluate performance on AIME24, AIME25 and GSM8K as the training target"
- AIME25: A follow-up benchmark subset of AIME problems for evaluating math reasoning. "We evaluate performance on AIME24, AIME25 and GSM8K as the training target"
- Agent Tool-Use: A task setting where models must follow strict tool/function-calling formats to solve problems. "Agent Tool-Use. We further evaluate EAFT on agentic tool-use tasks"
- Agentic: Referring to LLM behaviors or tasks involving autonomous tool use or structured actions. "agentic tool-use tasks"
- Alignment Tax: The observed decrease in general capabilities after aligning/fine-tuning models to specific objectives. "this manifests as the 'Alignment Tax'"
- BFCL: The Berkeley Function Calling Leaderboard, a benchmark for evaluating function-calling performance. "Berkeley Function Calling Leaderboard (BFCL)"
- Catastrophic forgetting: The loss of previously learned capabilities when a model is fine-tuned on new data. "catastrophic forgetting"
- CLUEWSC: A Chinese Winograd Schema Challenge benchmark assessing coreference and commonsense reasoning. "CLUEWSC"
- Confident Conflicts: Tokens where the model assigns low probability yet low entropy, indicating confident disagreement with labels. "We term these instances 'Confident Conflicts'."
- Continual learning: Training regimes where a model is adapted sequentially to new domains without forgetting prior knowledge. "domain adaptation and continual learning"
- Counterfactual training: Training that intentionally teaches facts contrary to prior knowledge to edit model beliefs. "counterfactual training (e.g., teaching the model that 'the sky is green')"
- Cross-Entropy (CE) loss: A standard loss function for maximizing likelihood of targets in classification/sequence modeling. "Cross-Entropy (CE) loss"
- DFT: A fine-tuning method that re-weights losses by prediction probabilities to adjust learning focus. "DFT re-weights the SFT loss according to prediction probability."
- Entropy-Adaptive Fine-Tuning (EAFT): A method that scales supervision by token-level entropy to suppress conflicting updates and learn from uncertain tokens. "we propose Entropy-Adaptive Fine-Tuning (EAFT)."
- Epistemic uncertainty: Uncertainty due to lack of knowledge, captured here via higher entropy in token distributions. "distinguish between epistemic uncertainty and knowledge conflict."
- FLOW: An alignment baseline method used for comparison against SFT variants. "FLOW"
- Gradient Magnitude Landscape: A visualization of per-token gradient strengths to diagnose destructive updates. "Gradient Magnitude Landscape."
- GSM8K: A benchmark of grade school math word problems to evaluate LLM reasoning. "GSM8K"
- IFEval: A benchmark for instruction-following evaluation of LLMs. "IFEval"
- Kullback–Leibler (KL) divergence: A measure of distributional difference used as a regularization/constraint during fine-tuning. "Kullback-Leibler (KL) divergence"
- Masked SFT: A baseline that discards low-entropy tokens (confident conflicts) during training. "We refer to this baseline as Masked SFT."
- MedMCQA: A medical multiple-choice QA benchmark. "MedMCQA"
- MedQA: A large-scale medical exam QA benchmark. "MedQA"
- MMLU: Massive Multitask Language Understanding benchmark covering diverse knowledge areas. "MMLU"
- Model drift: Unintended deviation of a fine-tuned model from its base distribution or capabilities. "to prevent model drift"
- Off-policy: Training using externally provided data not sampled from the current policy/model. "SFT optimizes the model to maximize the likelihood of ground-truth demonstrations (Off-policy)."
- On-policy: Training on data generated by the current model under its policy. "By contrast, RL optimizes the model based on its own generated responses guided by reward signals (On-policy)."
- Pareto improvement: Gains in one objective without sacrificing another; here, better retention with comparable target performance. "It achieves a Pareto improvement"
- Pareto frontier: The optimal trade-off curve between competing objectives, such as specialization and retention. "occupying the Pareto frontier of learning versus retaining."
- Predictive Entropy: The entropy of the model’s token distribution at a step, measuring uncertainty. "Predictive Entropy."
- Reward models: Learned models that provide scalar feedback signals to guide RL optimization of LLMs. "These signals typically originate from parameterized reward models"
- RL's Razor: A method that uses KL regularization to limit divergence from the base model during training. "RL's Razor employ KL divergence as a regularization term to constrain the model's drift"
- Rollouts (self-rollout): Sequences generated by the model itself during training/evaluation. "training sequences are generated via self-rollout"
- SFT (Supervised Fine-Tuning): Post-training that maximizes likelihood of supervised demonstrations to adapt to domains. "Supervised Fine-Tuning (SFT)"
- SFT_KL: A variant of SFT that adds a KL-divergence constraint to limit drift from the base model. "a regularized variant, denoted as $\text{SFT}_{\text{KL}$"
- TALR: A method that scales learning rates by token confidence to adjust optimization dynamics. "TALR dynamically scales learning rates based on token confidence"
- Top-K approximation: Estimating entropy using only the top-K token probabilities to reduce computation. "the entropy of the Top- tokens"
- Uncertainty calibration: Techniques to align model confidence with true likelihood of correctness. "uncertainty calibration techniques"
- Verifiable signals: Objective, checkable feedback used to reward model outputs during RL. "verifiable signals"
Practical Applications
Overview
Based on the paper’s findings and method (Entropy-Adaptive Fine-Tuning, EAFT), the following applications translate the research into practical, real-world uses. Each item names concrete use cases, sectors, potential tools/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Retention-aware fine-tuning as a drop-in SFT replacement (software, enterprise AI)
- Use case: Swap standard SFT with EAFT in existing training loops to specialize LLMs (e.g., math, legal, customer support) while preserving general abilities.
- Tools/workflows: Add top-k entropy computation (K≈20) and loss gating to CE loss in Hugging Face/DeepSpeed/LoRA trainers; enable a “retention mode” flag in finetune configs.
- Assumptions/dependencies: Base model probabilities reasonably calibrated; minor training-time overhead for top-k; general evaluation set available to track retention.
- Continual learning without catastrophic forgetting (enterprise knowledge management, MLOps)
- Use case: Nightly/weekly model updates on new org data that don’t erase prior knowledge (FAQs, product docs).
- Tools/workflows: EAFT in scheduled fine-tunes; automatic entropy-threshold logging; periodic general benchmark checks in CI/CD for models.
- Assumptions/dependencies: Stable data ingestion pipeline; retention KPIs; careful gating function choice (linear or sigmoid) to avoid under-learning.
- Safety and policy retention during domain specialization (policy, trust & safety, regulated sectors)
- Use case: Fine-tune for tool-use or domain jargon while preserving safety refusal policies and general guardrails.
- Tools/workflows: EAFT-enabled SFT on tool-call or domain datasets; safety eval suite (toxicity, jailbreak resistance) as “retention” gates; optional KL-regularization.
- Assumptions/dependencies: Safety priors are correct; gating will preserve them rather than weaken needed policy edits.
- Dataset quality control via “Confident Conflict” detection (data ops, data labeling)
- Use case: Flag low-entropy/low-probability tokens as likely mismatches (e.g., mislabeled, out-of-distribution phrasing) for relabeling or curation.
- Tools/workflows: “Conflict Auditor” that visualizes entropy–probability clouds, highlights bottom-left cluster; active-learning loop to relabel or filter.
- Assumptions/dependencies: Base model reflects desired priors; some conflicts are legitimate domain deltas and should not be removed—prefer soft down-weighting over hard filtering.
- RL cost reduction pre-stage (AI training ops)
- Use case: Use EAFT as a pre-finetune step to preserve generality before on-policy RL (reducing required RL iterations).
- Tools/workflows: EAFT → short PPO/DPO → eval; reuse EAFT’s entropy logs to set RL curricula.
- Assumptions/dependencies: RL stack available; compatibility with reward models or verifiable signals.
- Healthcare fine-tuning with preserved general capabilities (healthcare)
- Use case: Adapt models to MedQA/MedMCQA-like tasks without degrading broad reasoning and language.
- Tools/workflows: EAFT on domain corpora (clinical Q&A, guidelines); dual-metric gating (medical task score + general MMLU) in training dashboards.
- Assumptions/dependencies: Regulatory validation; alignment with clinical safety; careful monitoring for model overconfidence.
- Agent tool-use specialization without loss of conversational skill (software/agents)
- Use case: Improve function-calling syntax adherence while retaining natural dialogue and general Q&A.
- Tools/workflows: EAFT with tool schemas; BFCL-style evals + general evals; entropy-weighted loss for tool tokens.
- Assumptions/dependencies: Tool format labels are correct; base conversation priors worth preserving.
- Education models: math reasoning without degrading literacy/general knowledge (education)
- Use case: Fine-tune tutoring models on math reasoning while retaining writing, history, and general comprehension.
- Tools/workflows: EAFT on math datasets; class-level dashboards for cross-subject retention; gated loss for factual/terminology conflicts.
- Assumptions/dependencies: Balanced curricula; teachers/admins have retention metrics to enforce.
- Code assistant adaptation to private repos with retention of broad coding knowledge (software engineering)
- Use case: Adapt to an organization’s code style/APIs while keeping knowledge of standard libraries, patterns, and languages.
- Tools/workflows: EAFT LoRA on repo + docstrings; CI evals on general coding benchmarks; entropy gating on identifier-heavy tokens.
- Assumptions/dependencies: Secure data handling; representative general coding eval set.
- On-device or low-resource personalization with LoRA + EAFT (consumer AI, edge)
- Use case: Personalize assistants to user notes/workflows while minimizing drift from base model on-device.
- Tools/workflows: LoRA fine-tune with EAFT; K=20 entropy; lightweight monitoring (token histograms) due to resource limits.
- Assumptions/dependencies: Limited compute; need for simple, low-overhead training loop; privacy constraints.
- MLOps “Retention Monitor” and gating policies (platform/tooling)
- Use case: Operational dashboards that track entropy–probability distributions and general benchmark deltas during fine-tuning.
- Tools/workflows: Metric collectors for token entropy, gradient magnitude in “conflict region”; early warnings for retention risk; auto-tuning gating strength.
- Assumptions/dependencies: Observability integration; agreed retention thresholds/SLOs.
- Open-source trainer plugins (ecosystem enablement)
- Use case: Provide EAFT-ready Trainer callbacks and configs for Transformers/TRL/Lightning.
- Tools/workflows: “EAFT Trainer” package (loss wrapper + top-k entropy + schedulers + logs).
- Assumptions/dependencies: Community adoption; minimal API friction and documentation.
Long-Term Applications
- Industry standard for “no-forgetting fine-tune” in model platforms (software platforms)
- Use case: Major providers expose a “Retention-aware Fine-Tune” API option by default.
- Tools/workflows: Built-in EAFT kernels; standardized retention scorecards and attestations.
- Assumptions/dependencies: Consensus on retention metrics; hardware/library support for efficient per-token entropy.
- Hybrid on-policy/off-policy pipelines (research to production)
- Use case: Integrate EAFT with RL (e.g., PPO/DPO) to emulate on-policy robustness using off-policy data plus entropy gating.
- Tools/workflows: Alternating EAFT and RL phases; gating-guided sampling; reward shaping for conflicts.
- Assumptions/dependencies: Reward model quality; scheduler design; reproducibility.
- Regulatory and procurement guidelines around retention (policy, governance)
- Use case: Require vendors to demonstrate that domain adaptation does not erode general capabilities beyond thresholds.
- Tools/workflows: Third-party audits using “confident conflict” metrics and general benchmarks; model cards include retention curves.
- Assumptions/dependencies: Benchmark standardization; accepted audit protocols.
- Personalization-at-scale with retention SLAs (consumer, enterprise)
- Use case: Managed services that fine-tune per team/user but guarantee a minimum general capability baseline.
- Tools/workflows: EAFT with auto-calibrated gating per cohort; fleet-level retention monitoring; rollback triggers.
- Assumptions/dependencies: Reliable per-tenant evals; cost-effective monitoring.
- Active learning driven by conflict maps (data ops, labeling)
- Use case: Prioritize human review for tokens/samples in the “confident conflict” region to resolve label–prior mismatches.
- Tools/workflows: Annotator UI highlighting conflict spans; batch triage and relabel; retrain with EAFT + cleaned data.
- Assumptions/dependencies: Annotation budget; agreement on which conflicts reflect data errors vs desired domain shifts.
- Curriculum and scheduling based on entropy (training strategy)
- Use case: Start training on high-entropy tokens/samples (uncertain knowledge) and gradually include harder conflicts with moderate weighting.
- Tools/workflows: Entropy-driven curricula; adaptive annealing of gating function.
- Assumptions/dependencies: Stable entropy estimates; avoiding underfitting important low-entropy but correct targets.
- Knowledge editing with override-aware gating (knowledge management)
- Use case: When the goal is to intentionally change a prior (e.g., fix an outdated fact), temporarily invert gating or set high weights for targeted conflicts.
- Tools/workflows: “Edit mode” that detects local conflicts and boosts them; post-edit calibration.
- Assumptions/dependencies: Precise scope of edits; safeguards against unintended drift.
- Uncertainty calibration integration (research/engineering)
- Use case: Improve EAFT’s decision quality by calibrating predictive entropy (temperature scaling, ensembles, MC dropout).
- Tools/workflows: Calibration phase before fine-tune; plug-in uncertainty modules; per-domain temperature.
- Assumptions/dependencies: Added compute; dataset for calibration; diminishing returns beyond certain scales.
- Multi-domain, multi-objective training with reduced interference (cross-sector)
- Use case: Train unified models for healthcare, finance, and general chat with domain-balanced retention.
- Tools/workflows: Domain-aware gating schedules; per-domain entropy statistics; jointly optimized Pareto frontier.
- Assumptions/dependencies: Conflict resolution policies across domains; comprehensive eval matrices.
- Safe skill acquisition in robotics and embodied agents (robotics)
- Use case: Teach domain-specific instructions (manipulation scripts, tool-use language) without losing general instruction-following and safety priors.
- Tools/workflows: EAFT on grounded instruction datasets; safety evals in-the-loop; simulator-to-real transfer with retention checks.
- Assumptions/dependencies: High-stakes validation; mapping language conflicts to behavior-level risks.
- Provider-grade products: EAFT SDK and ConflictScope analyzer (vendor ecosystem)
- Use case: Offer turnkey SDKs that implement EAFT and companion analyzers that visualize/confidence-conflict hot spots before/after training.
- Tools/workflows: GUI dashboards; dataset diffing; model card generators with retention plots.
- Assumptions/dependencies: Market demand; integration with common data lakes and labeling tools.
- Cross-model distillation guided by conflict regions (research)
- Use case: During teacher→student distillation, use teacher’s conflict map to emphasize uncertain knowledge and soften conflicts.
- Tools/workflows: Entropy-aligned temperature schedules; per-token weighting in KD loss.
- Assumptions/dependencies: Teacher reliability; alignment between vocabularies/tokenizers.
Common assumptions and dependencies across applications
- Calibration: EAFT assumes low-entropy tokens reflect strong priors worth preserving; if the base model is confidently wrong, EAFT may protect errors unless combined with calibration or targeted override modes.
- Compute and engineering: Requires per-token top-k probabilities and entropy; with K≈20, the overhead is minimal but still needs implementation in training loops.
- Evaluation culture: Organizations need retention metrics and general benchmark suites to realize the benefits; otherwise improvements may go unnoticed.
- Task intent: EAFT is not ideal for counterfactual instruction or deliberate knowledge overwriting unless adapted (e.g., “edit mode”).
- Data quality: Some “conflicts” are true domain deltas; soft gating (not hard masking) is preferred to avoid losing necessary supervision.
Collections
Sign up for free to add this paper to one or more collections.