- The paper introduces a modular agent architecture, highlighting integrated perception, reasoning, memory, and execution subsystems to overcome LLM limitations.
- It details innovative methods including sequential and parallel planning, tool-enhanced perception, and reflective reasoning to improve task completion.
- The results reveal a significant performance gap compared to human operators and suggest future work in self-correction and multi-agent collaboration.
Architectural and Implementation Principles for Autonomous LLM Agents
Introduction and Motivation
The paper "Fundamentals of Building Autonomous LLM Agents" (2510.09244) presents a comprehensive review of the architectural foundations and implementation strategies for constructing autonomous agents powered by LLMs. The motivation is rooted in the limitations of traditional LLMs in real-world automation tasks, particularly their lack of persistent memory, tool integration, and robust reasoning capabilities. The work systematically analyzes the design space for agentic LLMs, focusing on perception, reasoning, memory, and execution subsystems, and evaluates integration patterns, failure modes, and generalization across benchmarks.
Core Agent Architecture
The agentic paradigm is defined by four principal subsystems: perception, reasoning, memory, and execution. These components are tightly integrated to enable closed-loop autonomy, allowing agents to interpret environmental signals, formulate and adapt plans, retain and retrieve knowledge, and execute actions in dynamic environments.
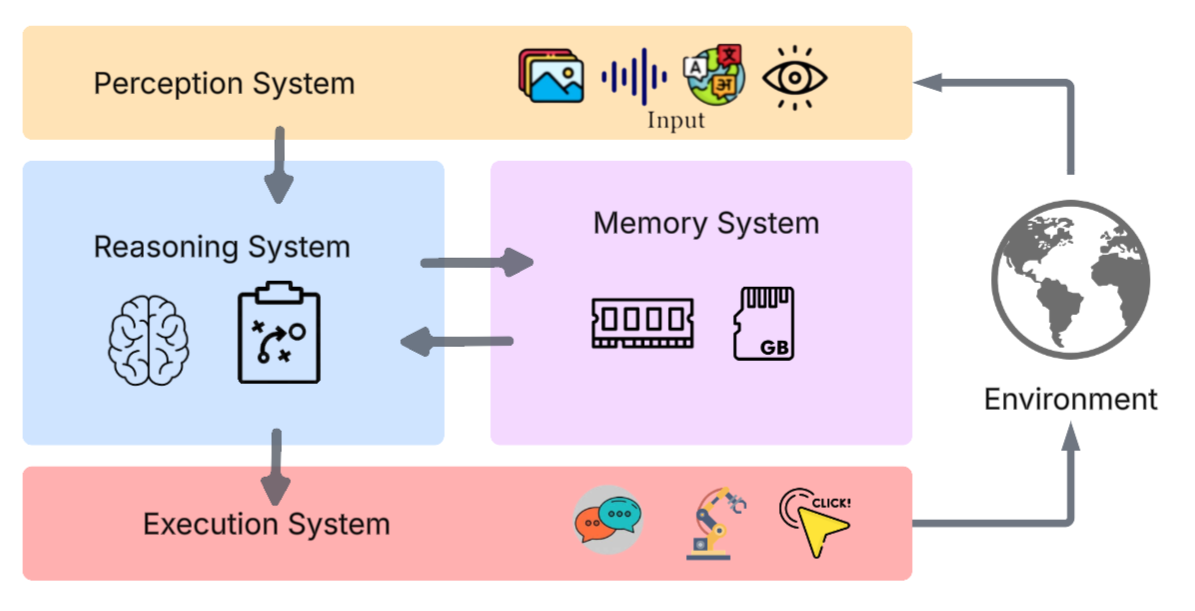
Figure 1: Key Components of an Agent's LLM Architecture, illustrating the modular separation of perception, reasoning, memory, and execution subsystems.
Perception System
The perception system is responsible for converting environmental stimuli into representations suitable for LLM processing. The review categorizes perception approaches into text-based, multimodal, structured data, and tool-augmented modalities.
- Text-based Perception: Direct textual observations, suitable for environments with native text interfaces.
- Multimodal Perception: Integration of visual and textual data via Vision-LLMs (VLMs) and Multimodal LLMs (MM-LLMs). MM-LLMs employ modality encoders, input projectors, and output generators to process and generate across modalities.
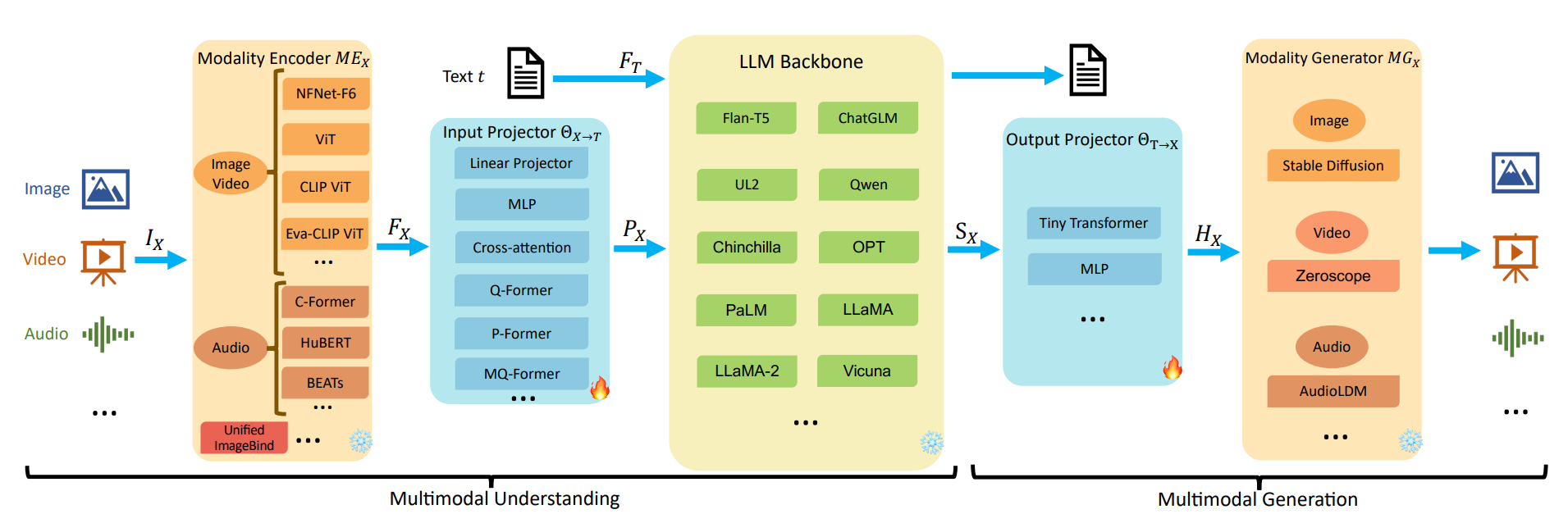
Figure 2: Architecture of Multimodal LLMs (MM-LLMs) for Understanding and Generation, highlighting the flow from modality encoders to LLM backbone and output projectors.
- Enhanced Perception: Techniques such as segmentation and depth maps (VCoder) and Set-of-Mark (SoM) operations improve object-level perception and reduce hallucination.

Figure 3: Usage of segmentation and depth maps for MM-LLM perception, demonstrating improved spatial reasoning and object identification.
Figure 4: Image with Set-of-Mark, showing explicit annotation of interactive regions for improved grounding.
- Structured Data: Accessibility trees and HTML/DOM parsing provide semantic grounding for GUI environments.
- Tool-Augmented Perception: External APIs, code execution, and sensor integration extend perceptual capabilities beyond the agent's native modalities.
The paper identifies persistent challenges in perception, including hallucination, latency, context window limitations, data annotation costs, and computational resource demands.
Reasoning and Planning System
The reasoning subsystem orchestrates task decomposition, multi-plan generation, selection, and reflection. The review distinguishes between sequential and interleaved decomposition strategies.
- Sequential Decomposition: Entire tasks are decomposed into subgoals, with plans generated for each (e.g., HuggingGPT, Plan-and-Solve).
- DPPM (Decompose, Plan in Parallel, Merge): Subtasks are planned concurrently by independent agents, then merged, mitigating error propagation and constraint violations.
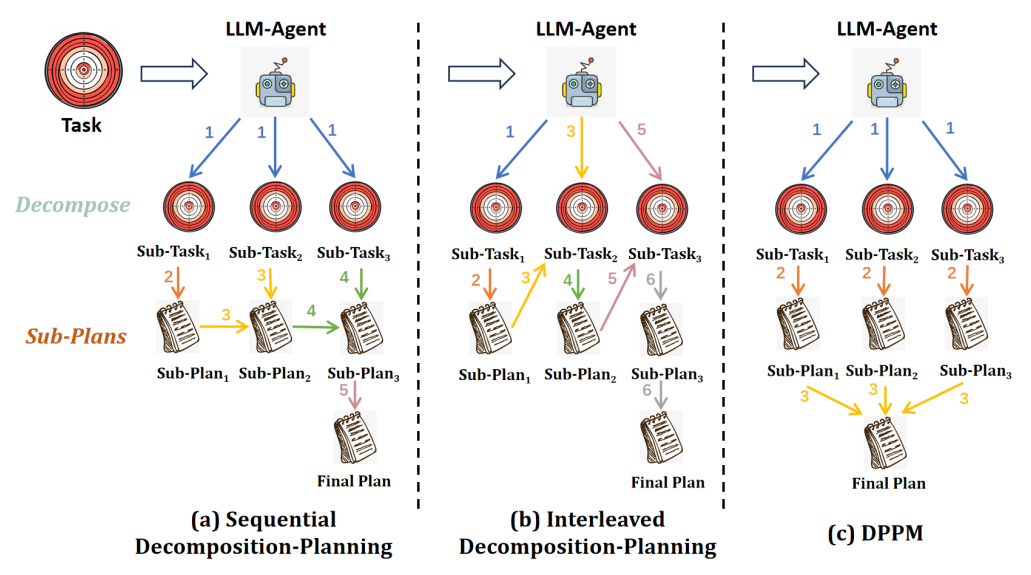
Figure 5: Comparison of different types of planning frameworks, including sequential decomposition-planning, interleaved decomposition-planning, and DPPM.
- Interleaved Decomposition: Chain-of-Thought (CoT), ReAct, and Tree-of-Thought (ToT) approaches interleave decomposition and planning, adapting dynamically to feedback.
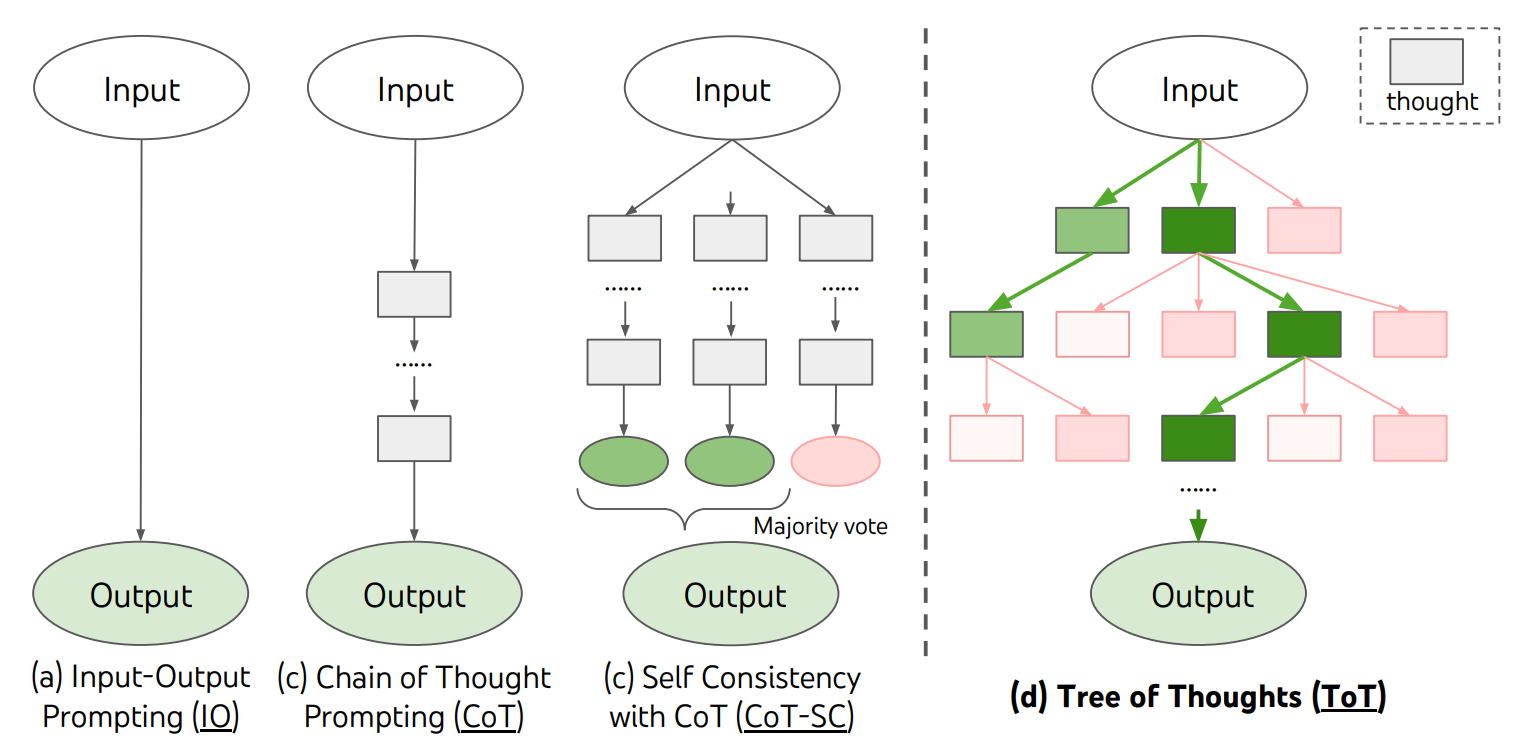
Figure 6: Schematic illustrating various approaches to problem solving with LLMs, including CoT, ToT, and multi-plan selection.
- Multi-Plan Selection: Self-consistent CoT, ToT, Graph-of-Thoughts, and LLM-MCTS generate and evaluate multiple candidate plans, improving robustness but increasing computational cost.
- Reflection: Post-execution self-evaluation and anticipatory reflection (Devil's Advocate) enable agents to learn from errors and proactively mitigate failures.
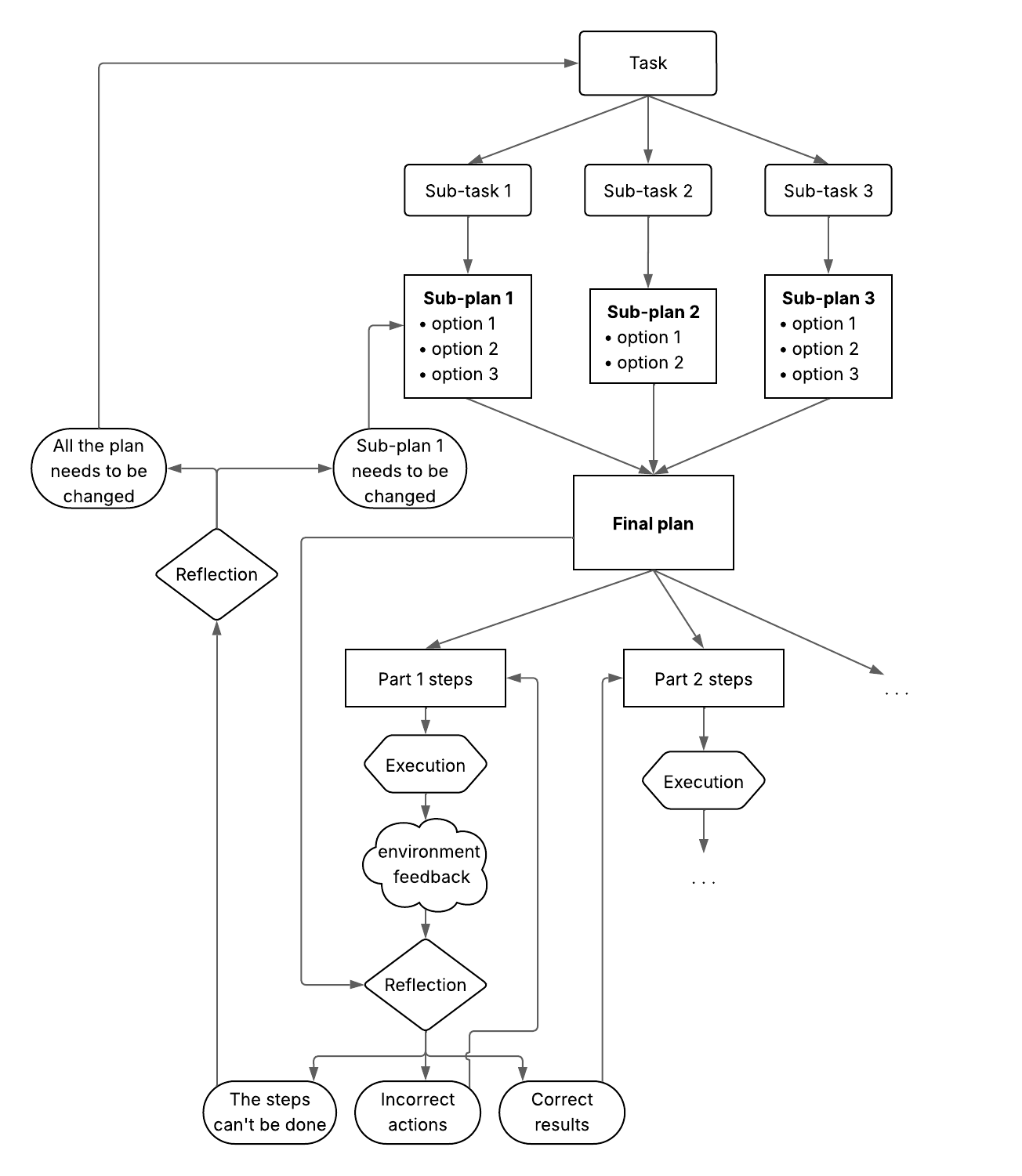
Figure 7: Flowchart of a Reasoning System Using Decompose, Plan, and Merge (DPPM) approach with a reflection system.
- Multi-Agent Systems: Modular experts (planning, reflection, error handling, memory, action) collaborate to distribute reasoning tasks, enhancing scalability and specialization.
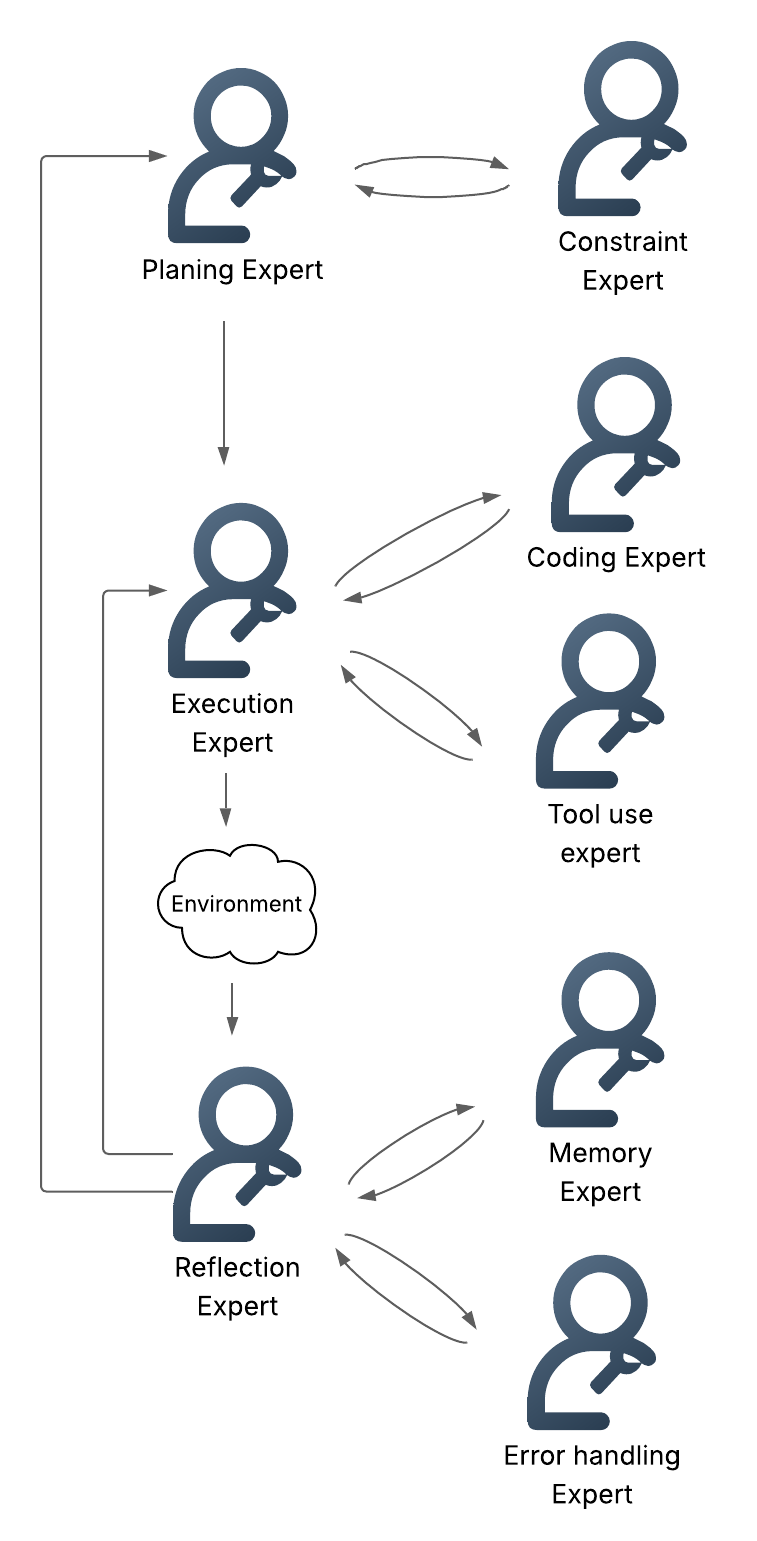
Figure 8: Example of the communication between agents in a multi-agent system, illustrating expert specialization and inter-agent coordination.
Memory System
The memory subsystem is bifurcated into long-term and short-term mechanisms:
- Long-term Memory: Embodied memory via fine-tuning, Retrieval-Augmented Generation (RAG) for external document retrieval, and SQL/database integration for structured knowledge.
- Short-term Memory: Context window management, chunking, and summarization to maintain immediate task context.
- Data Storage: Experiences (including failed attempts), reusable workflows (AWM), external knowledge, and user information are retained for future retrieval and adaptation.
- Limitations: Context window constraints, memory duplication, and privacy concerns are highlighted as ongoing challenges.
Execution System
The execution subsystem translates internal decisions into concrete actions:
- Tool and API Integration: Structured function calling enables interaction with external systems.
- Multimodal Action Spaces: Agents automate GUIs via vision-LLMs, generate and execute code, and control robotic systems through sensor-actuator loops.
- Integration Challenges: Latency, error propagation, and state synchronization across modalities require careful architectural design.
Limitations and Implications
The review identifies a substantial performance gap between LLM agents and human operators, with leading models achieving only ~42.9% task completion on OSWorld versus >72% for humans. Key limitations include insufficient experience, high fine-tuning costs, closed-source model restrictions, and incomplete visual perception. The modular agentic architecture, however, offers a pathway to more robust, adaptable, and context-aware AI systems.
Future Directions
Potential extensions include advanced self-correction mechanisms, one-shot learning from human demonstrations, and human-in-the-loop architectures to accelerate agent training and productivity. The integration of richer memory systems and more sophisticated multi-agent collaboration is expected to further close the gap with human-level performance.
Conclusion
This paper provides a rigorous analysis of the architectural and implementation principles underlying autonomous LLM agents. By dissecting the perception, reasoning, memory, and execution subsystems, and evaluating integration strategies and failure mitigation techniques, the work establishes a foundation for building more capable, generalizable, and intelligent agentic systems. The findings underscore the necessity of modular design, robust memory, and advanced reasoning for achieving reliable autonomy in complex environments.