- The paper introduces a modular framework that probes behavioral consistency by pairing agents with varied biases and measuring dialogue agreement.
- It reveals that agents systematically suppress disagreement and display sentiment asymmetries, even when internal preferences diverge strongly.
- The study demonstrates that LLM agents fail in in-depth behavioral tests, questioning their reliability for accurate social simulation.
Behavioral Coherence in LLM Agents: A Latent Profile Evaluation for Social Simulation
Introduction and Motivation
The paper addresses a critical question in the use of LLMs as synthetic agents for social simulation: do LLM agents exhibit internal behavioral coherence, or do they merely produce plausible but ultimately inconsistent responses? While prior work has focused on external validity—how well LLMs mimic human survey responses or demographic priors—this study shifts the focus to internal consistency, specifically whether an agent’s conversational behavior aligns with its own revealed internal state (e.g., preferences and openness to persuasion).
The authors propose a modular framework for probing behavioral consistency in LLM agents, emphasizing the need to move beyond surface-level plausibility. The framework is designed to systematically test whether LLM agents’ internal states, as elicited through direct questioning, predict their downstream conversational behavior in multi-agent dialogue settings.
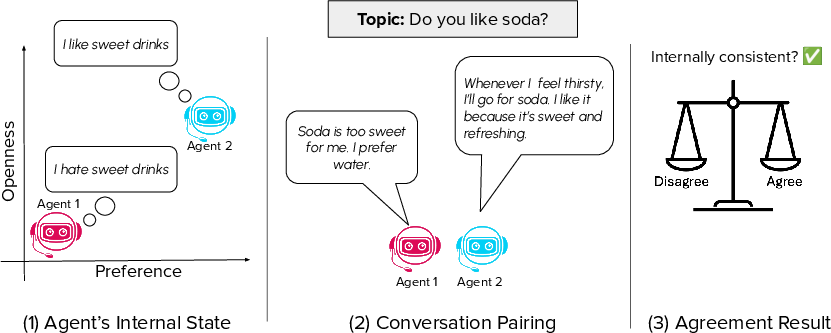
Figure 1: A framework for probing behavioral consistency in LLM agents by comparing predicted latent profiles against each other, focusing on whether conversational outcomes align with agents' internal states.
Framework for Probing Behavioral Coherence
The experimental framework consists of five sequential stages:
- Topic Selection: Topics are chosen with varying levels of contentiousness, allowing for controlled manipulation of conversational context.
- Agent Generation: Agents are instantiated with explicit demographic profiles and topic-specific biases, systematically varying age, gender, region, urbanicity, education, and stance.
- Internal State Elicitation: Each agent’s preference (Pi) and openness (Oi) are measured via direct prompts. Preferences are rated on a 1–5 scale, and openness is assessed through a battery of yes/no questions adapted from the Big Five personality framework.
- Pairing for Dialogue: Agents are paired to maximize diversity in preference and openness, enabling controlled tests of behavioral predictions.
- Outcome Measurement: Conversations are scored for agreement using an LLM-as-judge protocol, with agreement measured on a 1–5 scale.
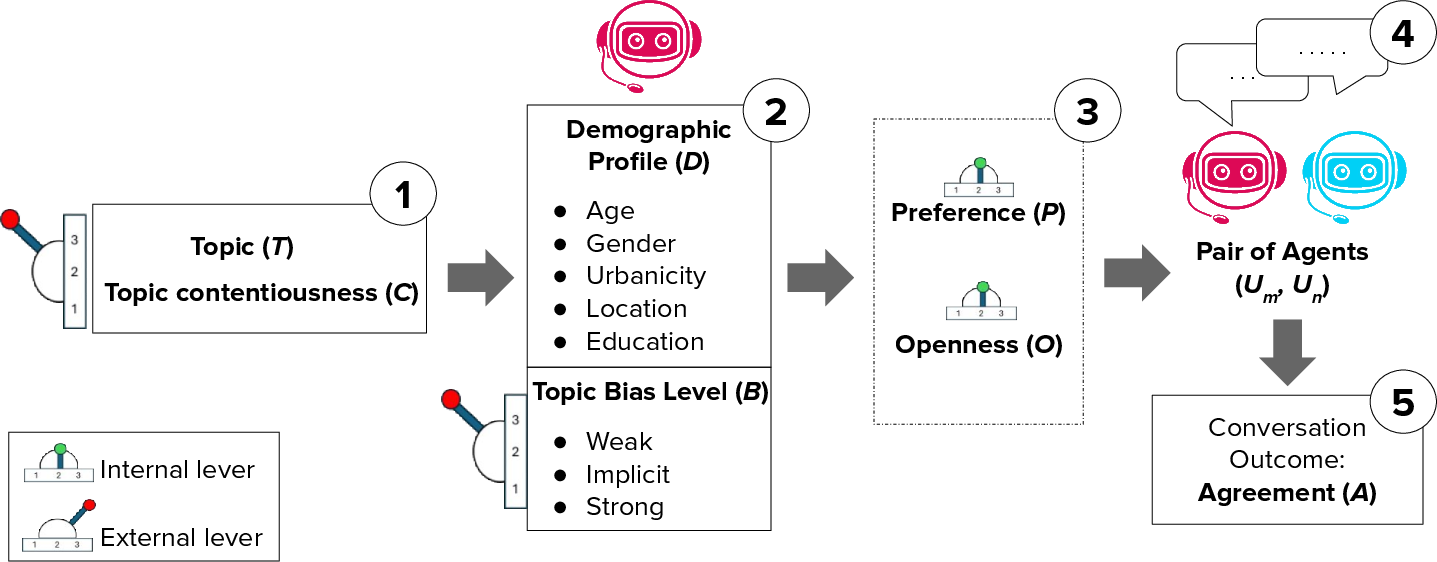
Figure 2: The framework operationalizes behavioral coherence by systematically varying topic, agent profile, internal state, and pairing, then measuring agreement in dialogue.
A non-parametric bootstrap approach is used to estimate group-level agreement distributions, providing robust statistical comparisons across experimental conditions.
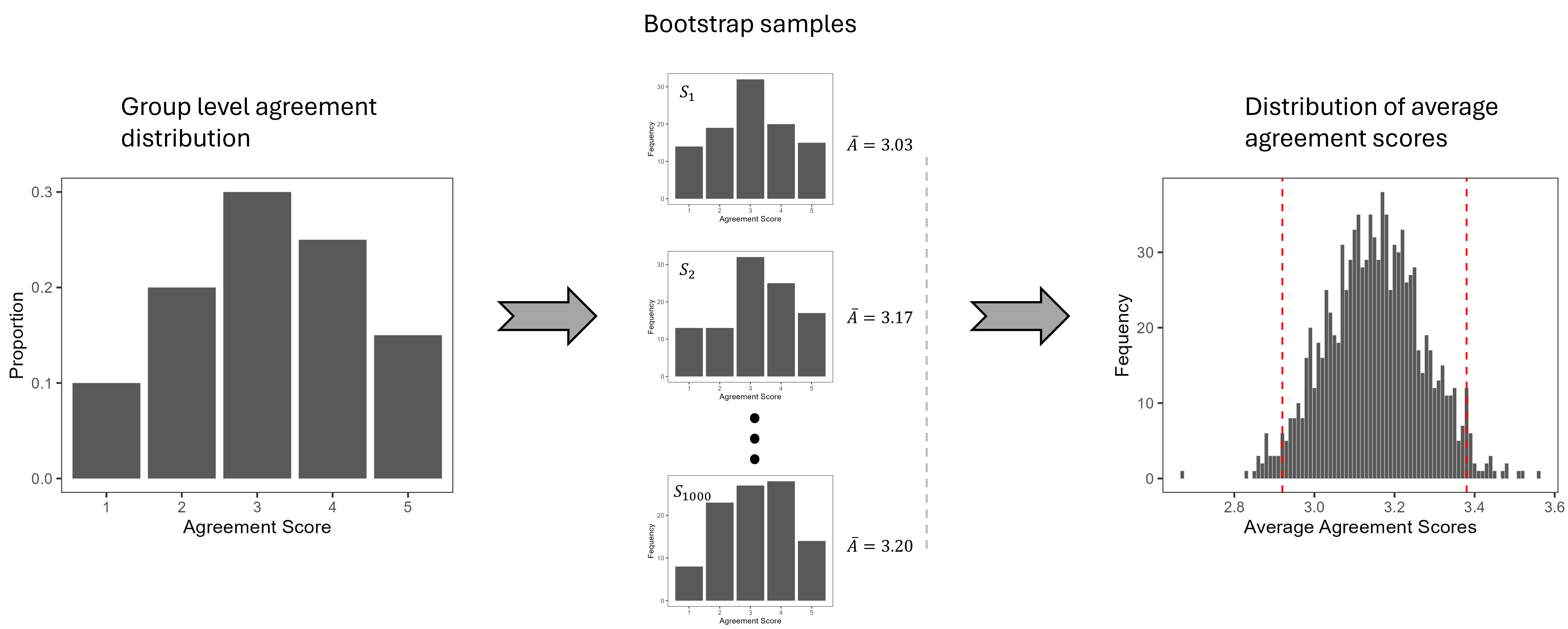
Figure 3: Bootstrap sampling is used to generate reliable group-level observations of agreement distributions.
Experimental Results
Preference Alignment and Agreement
The primary expectation is that agents with aligned preferences should agree more, while those with divergent preferences should disagree. The results confirm a monotonic decrease in agreement as the preference gap widens.
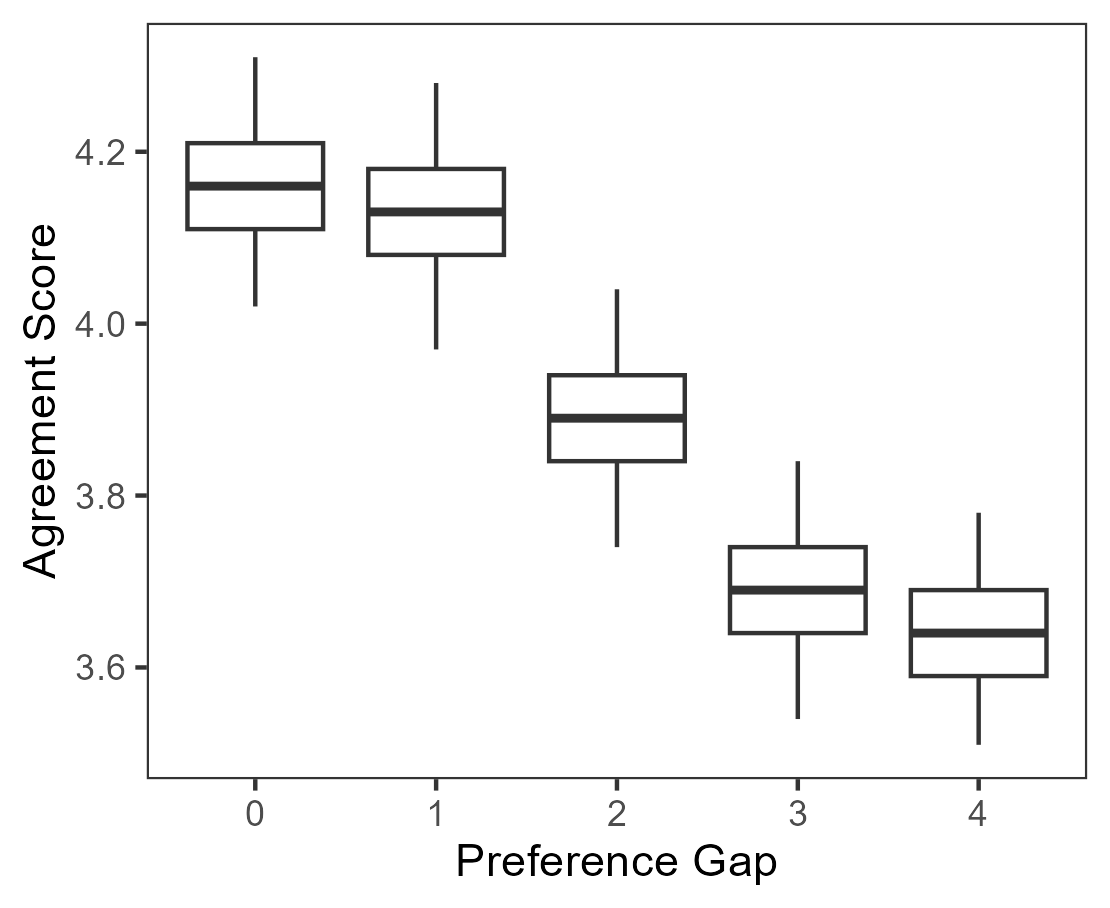
Figure 4: Average agreement score decreases as the preference gap between agent pairs increases.
However, deeper analysis reveals several systematic inconsistencies:
- Suppression of Disagreement: Even at maximal preference divergence, agents rarely disagree outright. The observed mean agreement score for maximally divergent pairs is approximately double the expected value under a symmetric model, indicating strong suppression of disagreement.
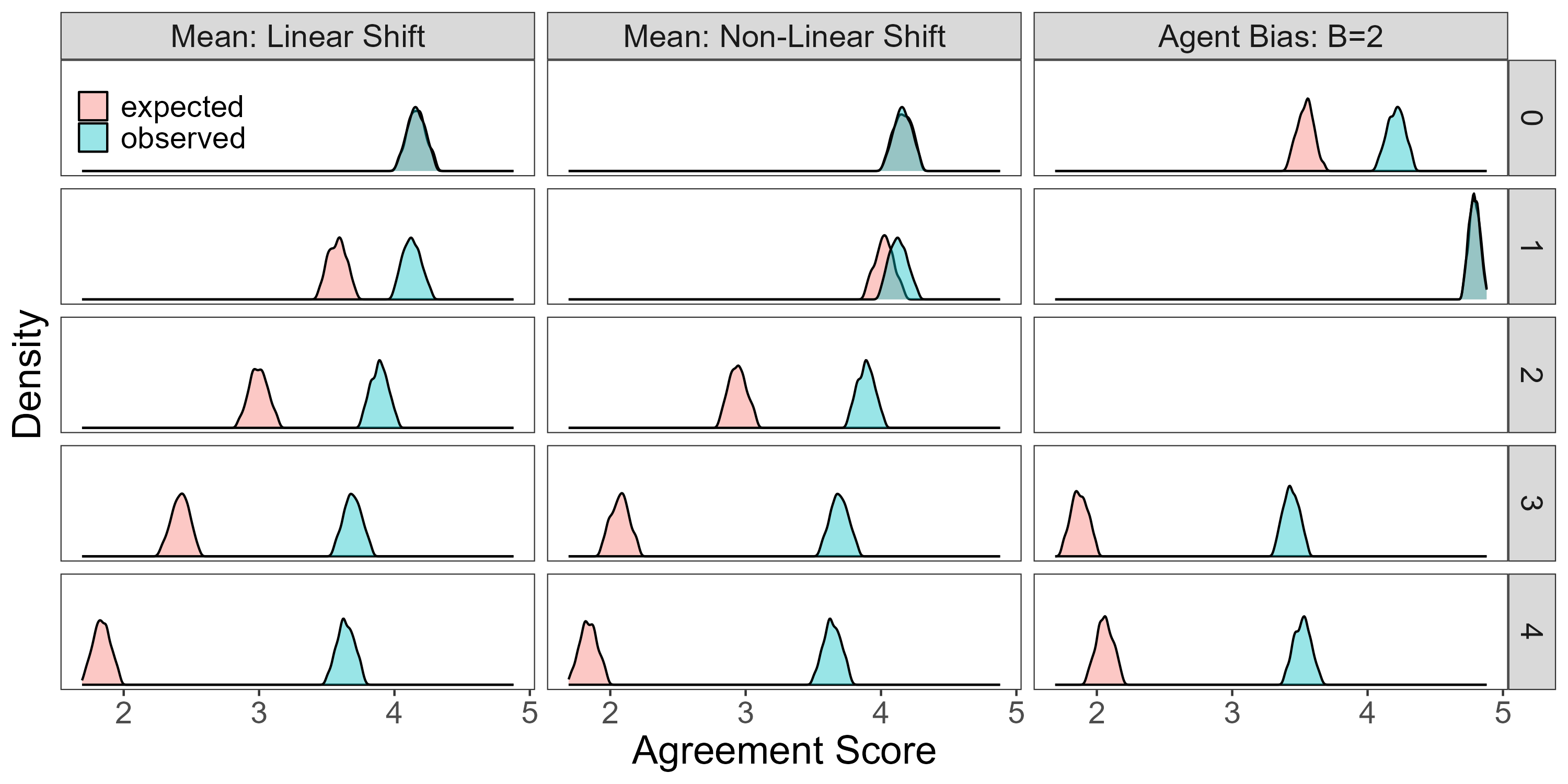
Figure 5: Observed agreement distributions show substantial suppression of disagreement compared to expected distributions, even when agents are explicitly biased.
- Asymmetry in Sentiment Alignment: Pairs sharing strong negative sentiment (e.g., both strongly disliking a topic) exhibit systematically lower agreement than pairs sharing strong positive sentiment, even when preference gaps are identical.
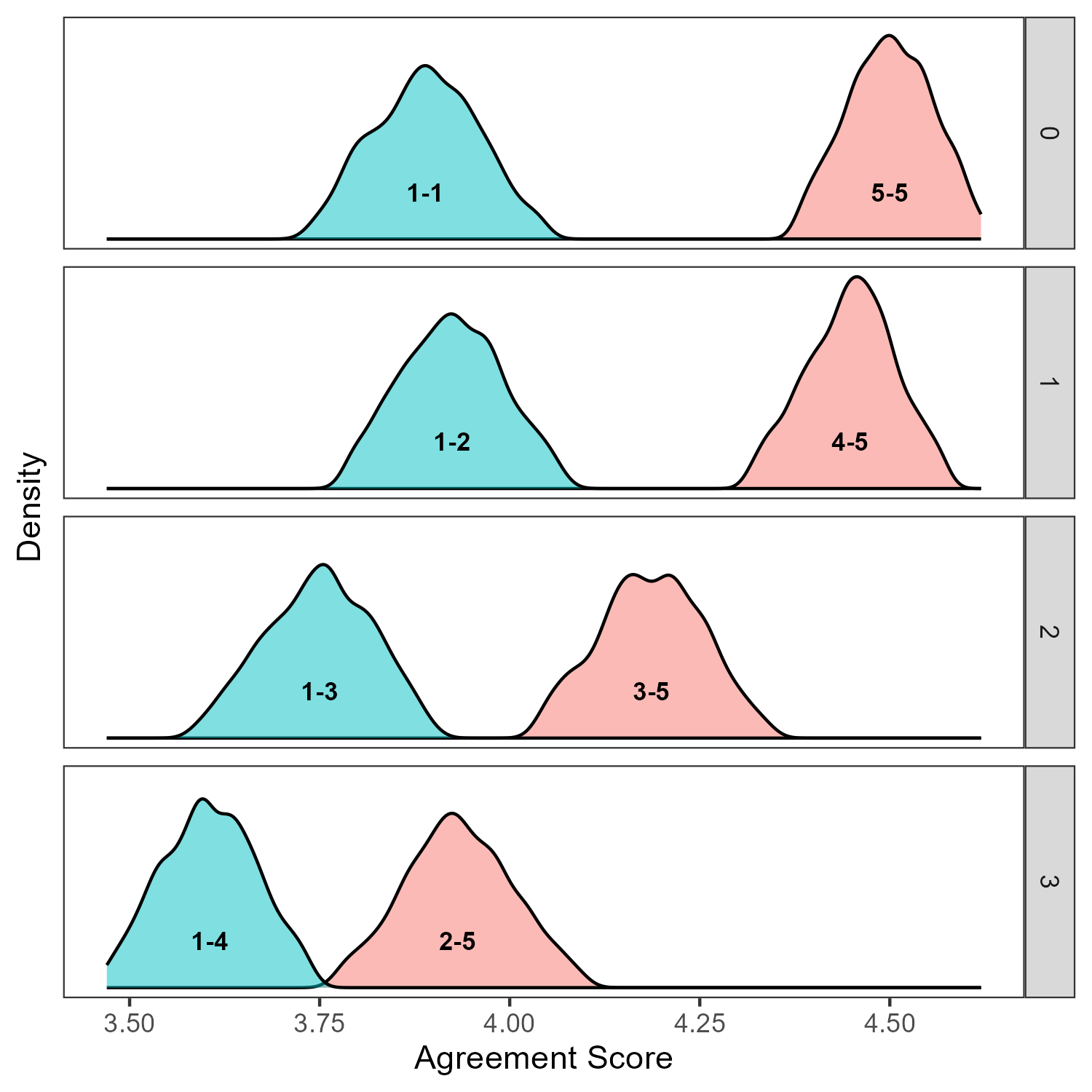
Figure 6: Agreement scores for pairs with fixed sentiment anchors reveal that negative sentiment alignment yields lower agreement than positive alignment, even under identical preference gaps.
- Topic Contentiousness Effects: Agreement is unduly influenced by topic contentiousness, overriding the effect of preference alignment. Even when preferences are held constant, more contentious topics yield lower agreement.
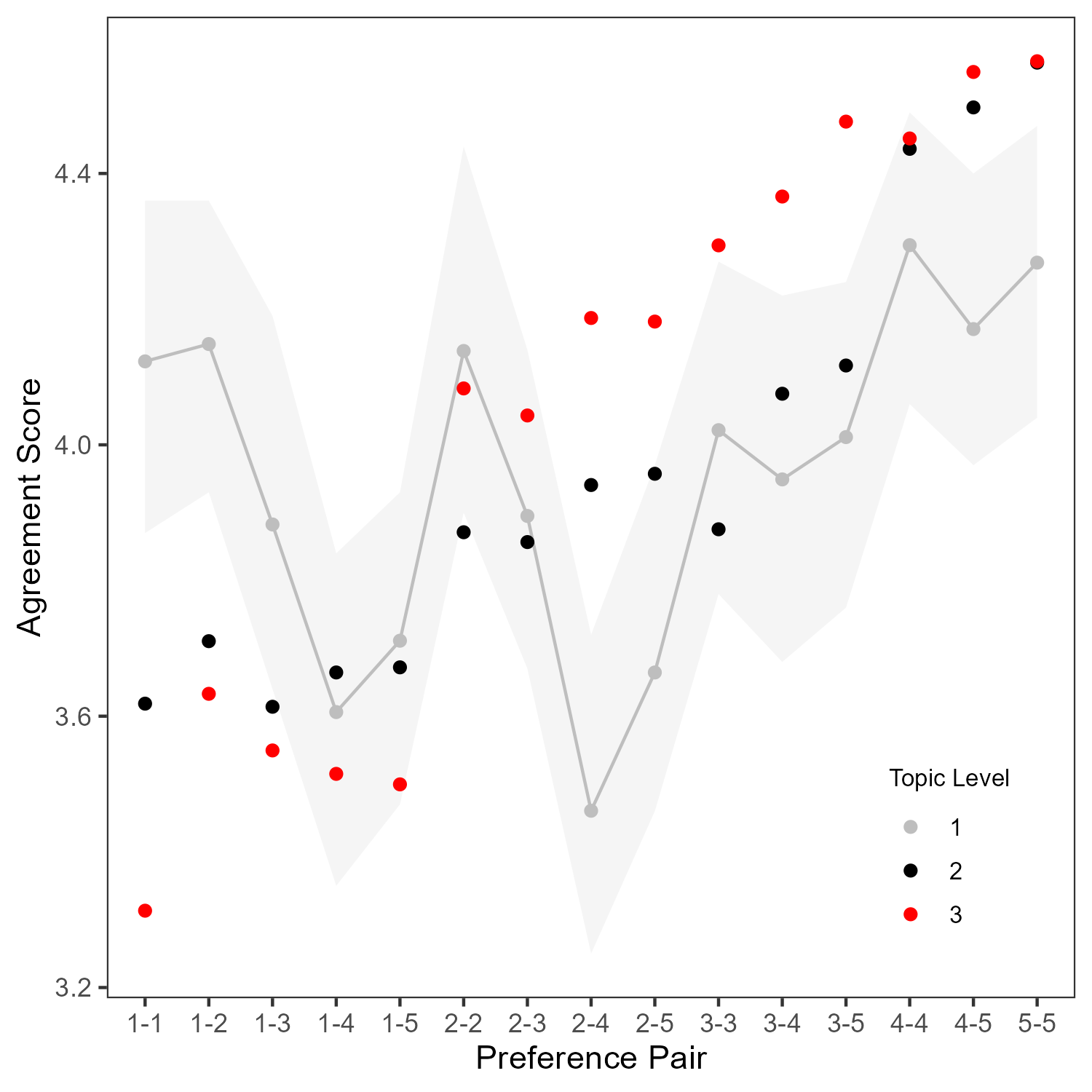
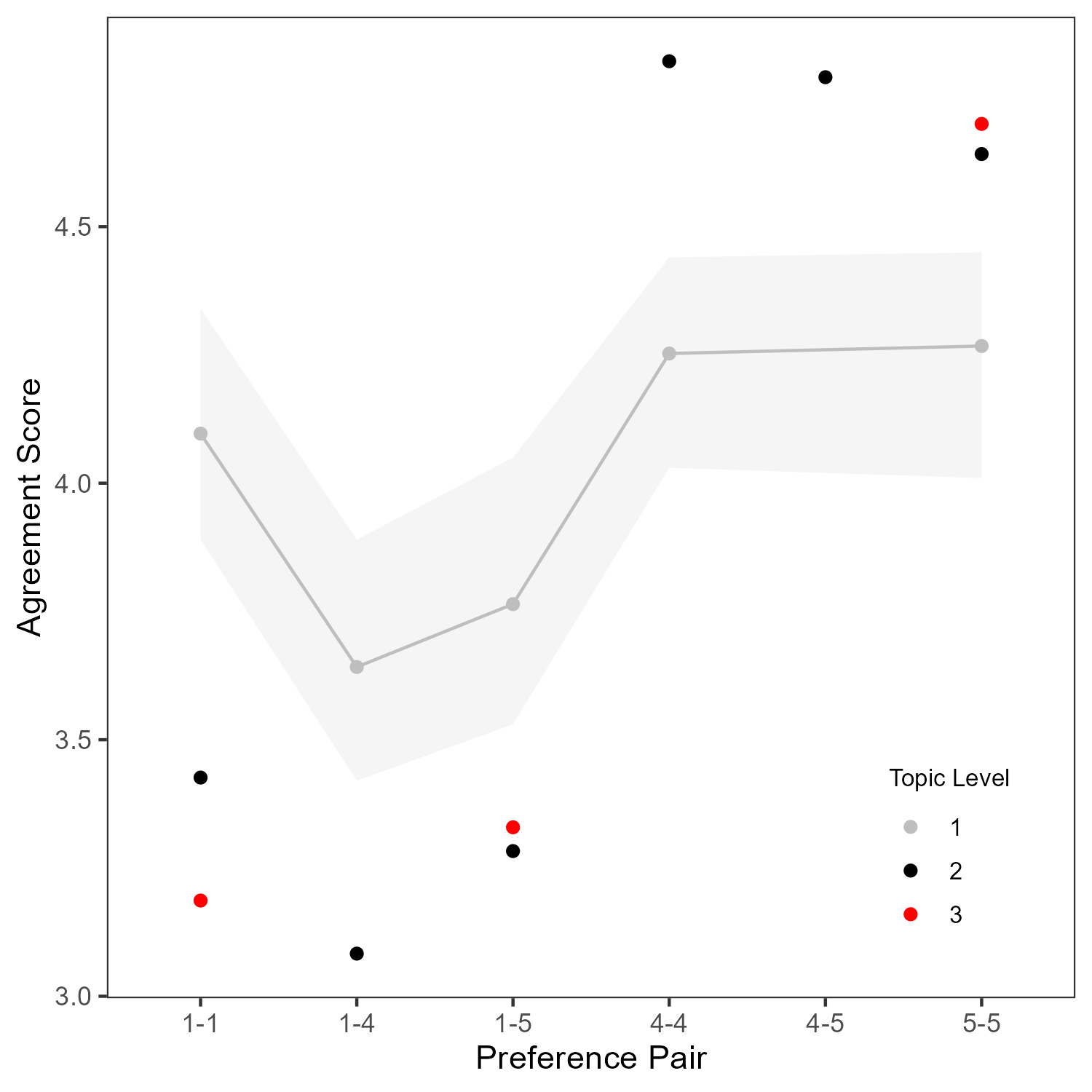
Figure 7: Agreement scores are modulated by topic contentiousness, with more controversial topics reducing agreement even among aligned pairs.
Openness and Persuadability
Surface-level trends indicate that higher openness correlates with higher agreement, as expected. However, when isolating cases of maximal preference divergence, this effect weakens or disappears. In many cases, increased openness does not reliably increase agreement when agents begin from diametrically opposed positions.
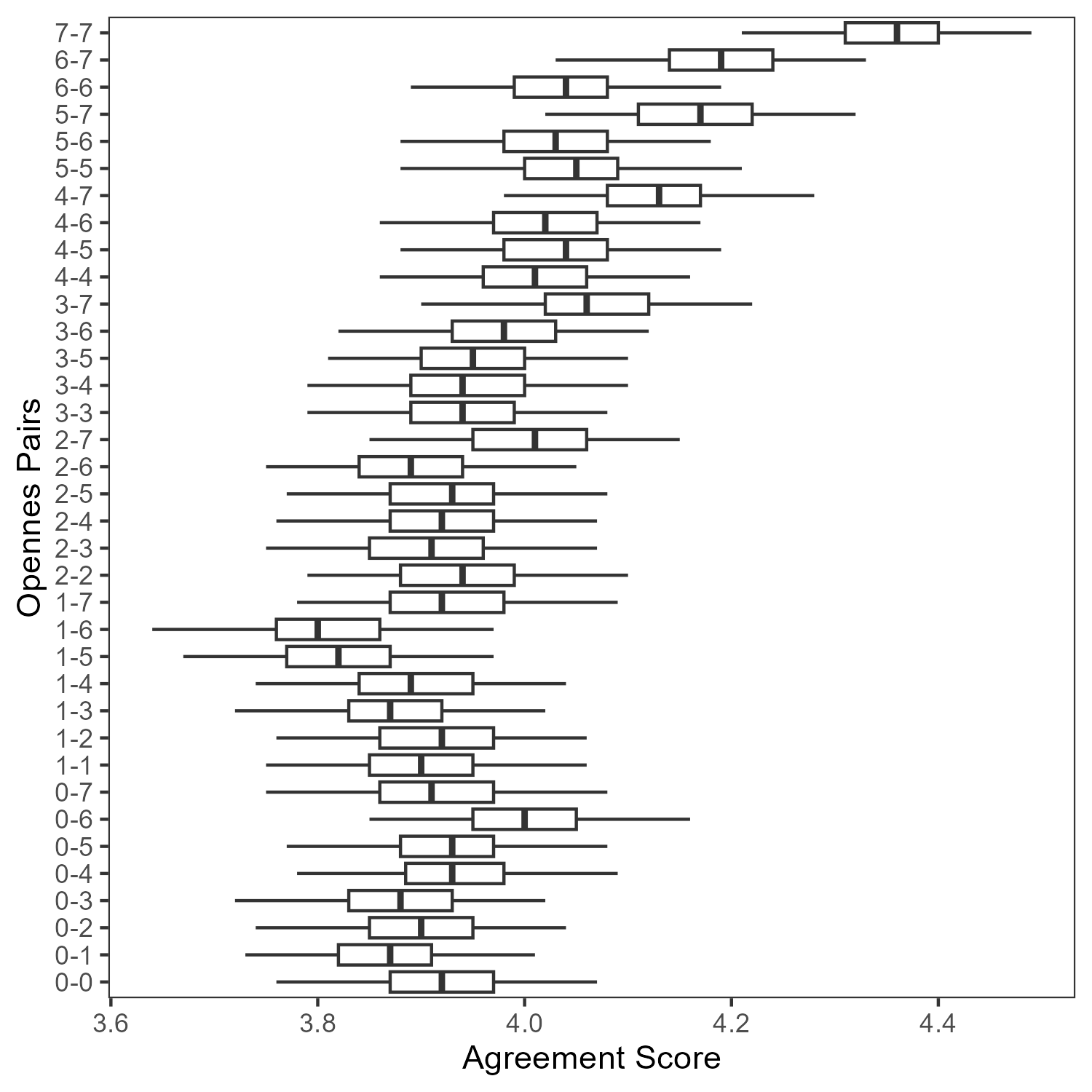
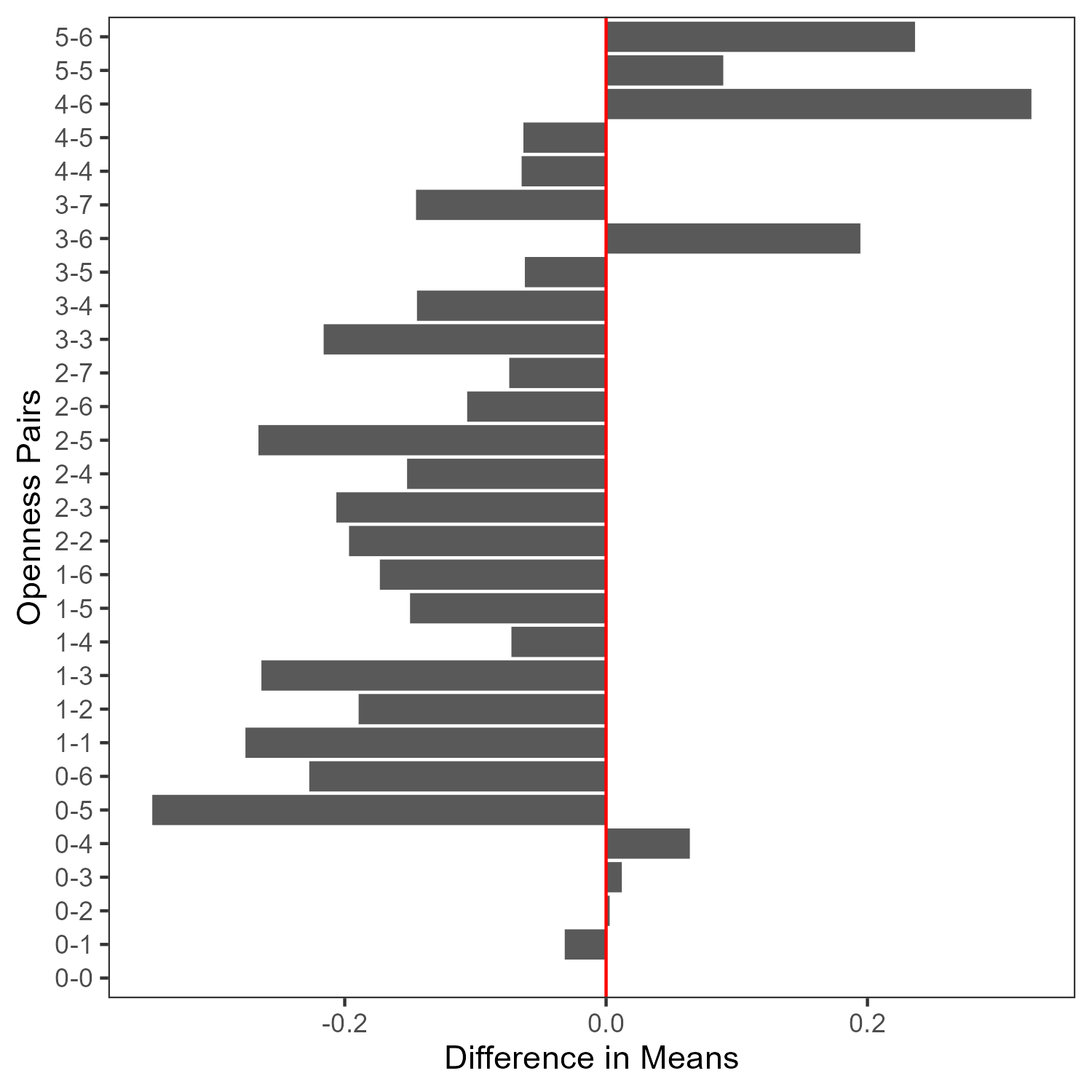
Figure 8: Agreement scores as a function of openness show that the expected positive relationship breaks down under maximal preference divergence.
Model Robustness and Generalization
The authors formalize six behavioral consistency tests, spanning both surface-level and in-depth criteria. All tested models (Qwen2.5, Llama3.1, Gemma, Mistral, Olmo) pass surface-level tests (preference gap and openness correlation), but none pass the in-depth tests (disagreement symmetry, sentiment alignment, and topic independence). These failures are consistent across model sizes and families, indicating that the observed inconsistencies are not idiosyncratic to a particular architecture.
External Validity: Diversity, Naturalness, and Faithfulness
The study also evaluates the external validity of simulated dialogues:
- Diversity: Most agents produce diverse conversations, as measured by Self-BLEU.
- Naturalness: Human annotators rate the majority of conversations as plausibly human, though naturalness declines with conversation length.
- Faithfulness: Dialogues generally reflect the demographic and persona attributes specified in agent prompts.
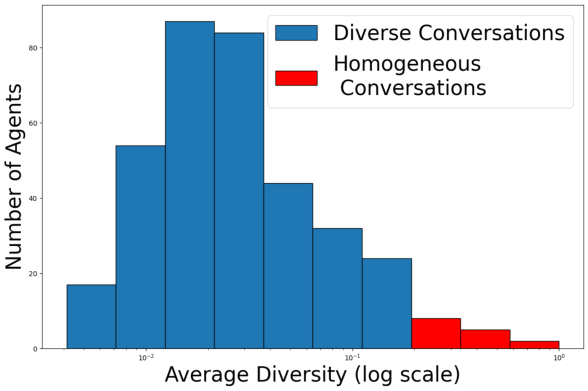
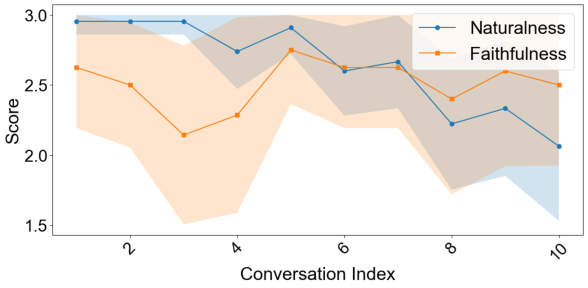
Figure 9: (a) Distribution of diversity scores across agents; (b) Naturalness decreases with conversation length, but faithfulness remains stable.
Implications and Future Directions
The findings have significant implications for the use of LLM agents in social simulation and behavioral research:
- Internal Consistency as a Core Criterion: The results demonstrate that current LLM agents, despite surface-level plausibility, systematically fail to maintain internal behavioral coherence. This undermines their reliability as substitutes for human participants in research settings where trait-driven consistency is essential.
- Suppression of Disagreement and Sentiment Asymmetry: The strong bias toward agreement and the penalization of negative sentiment suggest that LLMs are not neutral simulators of social behavior, but are shaped by alignment and safety tuning that may distort emergent group dynamics.
- Framework Extensibility: The modular probing framework can be extended to other latent traits (e.g., agreeableness, neuroticism) and broader demographic or topical domains, providing a generalizable tool for evaluating behavioral consistency in LLM agents.
Future work should focus on:
- Expanding the range of latent traits and conversational contexts.
- Developing LLM architectures or training regimes that explicitly model and enforce internal state coherence.
- Integrating social theory to inform the design of agent profiles and interaction protocols.
- Evaluating the impact of alignment and safety tuning on emergent group-level behaviors.
Conclusion
This study provides a rigorous evaluation of behavioral coherence in LLM agents, revealing that current models systematically fail to maintain internal consistency between stated preferences, openness, and conversational behavior. These failures persist across model families and sizes, challenging the substitution thesis that LLM agents can reliably stand in for humans in social simulation. The proposed framework offers a principled approach for diagnosing and addressing these limitations, and should serve as a foundation for future research on the behavioral fidelity of synthetic agents.