- The paper introduces a process-oriented framework assessing LLM behavioral fidelity by comparing LLM strategies to human decision-making in auction and newsvendor tasks.
- It finds that LLM agents, even under risk-framed and imitation interventions, show low variability and conservative, deterministic strategies compared to the diverse human behaviors.
- The study underscores the need for enhanced adaptive mechanisms and rigorous behavioral audits to bridge the gap between LLM optimization and human unpredictability.
Process-Oriented Evaluation of LLM Behavioral Fidelity in Dynamic Decision-Making
Introduction
This paper presents a rigorous, process-oriented framework for evaluating the behavioral fidelity of LLMs in dynamic decision-making tasks, specifically focusing on their ability to simulate human-like variability and adaptability. The study addresses a critical gap in current LLM evaluation paradigms, which predominantly emphasize outcome-oriented metrics such as accuracy and profit, neglecting the stochastic and history-dependent nature of human decision-making. By introducing progressive interventions—intrinsicality, instruction, and imitation—the authors systematically assess the extent to which LLM agents can reproduce the noise, diversity, and bounded rationality observed in human subjects.
Experimental Design and Methodology
The evaluation framework is instantiated on two canonical behavioral economics tasks: the second-price auction and the newsvendor problem. Each task is designed to elicit strategic adaptation and variability, with closed-form optimal solutions enabling direct comparison between LLM and human behaviors.
- Second-Price Auction: Agents set reserve prices over 60 rounds, facing simulated bidder valuations drawn from cube-root and cube distributions. The number of bidders varies per round, and agents receive feedback on profit, allowing for adaptive strategy revision.
- Newsvendor Problem: Agents select order quantities over 30 rounds under stochastic demand, with profit determined by the critical fractile rule.
The framework applies three levels of intervention:
- Intrinsicality: LLMs operate without external guidance, mirroring human experimental conditions.
- Instruction: Agents receive explicit risk-framed prompts (risk-seeking or risk-averse).
- Imitation: Agents are provided with partial human decision histories and tasked with continuing the behavior under direct, context-aware, or theory-guided imitation.
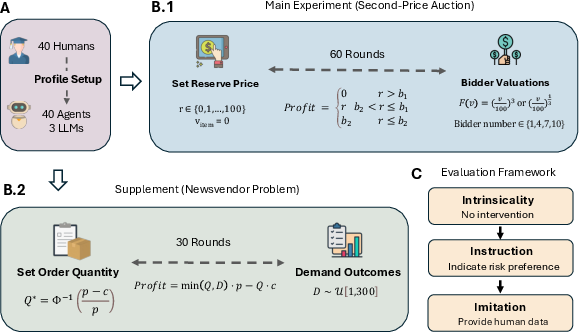
Figure 1: Overview of the experimental design, illustrating agent instantiation, task structure, and the progressive intervention framework.
Robustness is ensured via multiple replications, temperature sweeps, and statistical controls. Key behavioral metrics include reserve price/order bias distributions, sell-through and premium capture rates, Kolmogorov–Smirnov (KS) distance for distributional similarity, and entropy for behavioral variability.
Main Findings: Second-Price Auction
Intrinsicality
LLM agents, across GPT-4o and Claude variants, consistently converge on stable, low-variance strategies, setting reserve prices within a narrow range and achieving profits comparable to human subjects. However, the variance and entropy of reserve prices are substantially lower than those observed in humans, who display greater strategic dispersion and threshold phenomena.
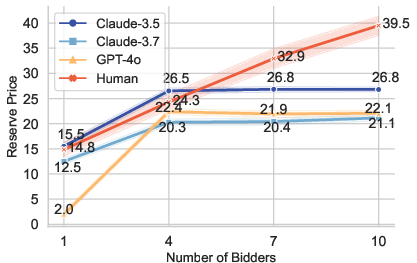
Figure 2: Reserve price variation with the number of bidders, showing LLMs' conservative and stable strategies compared to humans' adaptive escalation.
Sell-through rates (STR) are high for LLMs, indicating a preference for transaction completion, while premium capture rates (PCR) are lower and less variable than in humans. Notably, GPT-4o exhibits an especially conservative profile, with STR near 0.9 and PCR tightly clustered around 0.1.
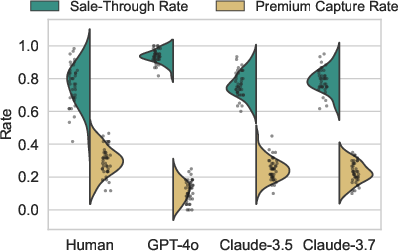
Figure 3: Split violin and dot plot comparing STR and PCR, highlighting reduced variability in LLM agents relative to human subjects.
Instruction
Risk-framed instructions modulate LLM behavior predictably: risk-seeking prompts induce higher reserve prices, while risk-averse prompts align closely with intrinsic behavior. Despite this responsiveness, the resulting distributions remain tightly clustered, lacking the diversity and stochasticity of human decision-making.
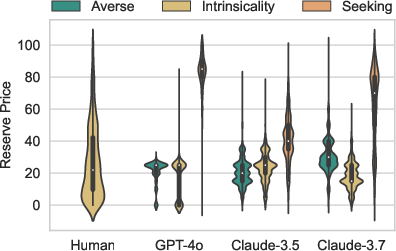
Figure 4: Reserve price distributions across risk-framed instruction conditions, demonstrating LLMs' directional but low-variance adaptation.
Imitation
In-context learning with human data increases behavioral dispersion, with direct imitation most closely approximating human reserve price distributions and entropy. However, even the best imitation mode fails to fully recover the upper bounds of human variability, as measured by KS distance and entropy.
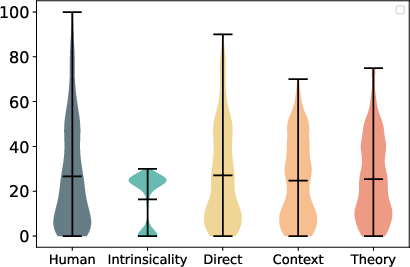
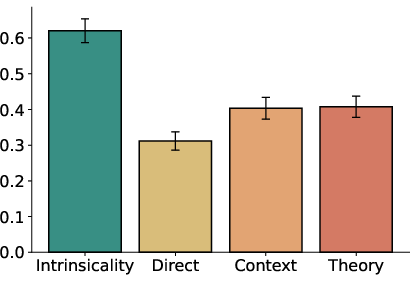
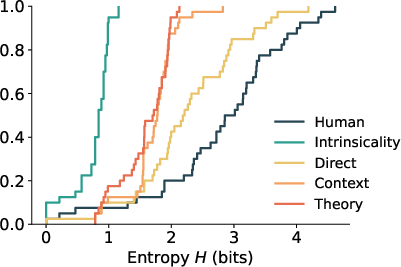
Figure 5: Reserve price distribution under imitation conditions, showing partial recovery of human-like variability.
Supplementary Findings: Newsvendor Problem
The newsvendor task corroborates the main findings. Intrinsic LLM agents consistently order near the theoretical optimum, exhibiting minimal round-to-round variability. Risk-framed instructions shift order quantities as expected, but distributions remain narrow. Direct imitation increases order dispersion and entropy, but does not fully match human stochasticity.
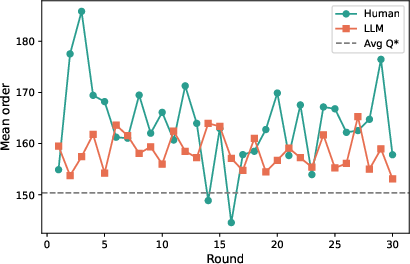
Figure 6: Order quantities over rounds, contrasting human variability with intrinsic LLM agents' deterministic optimization.
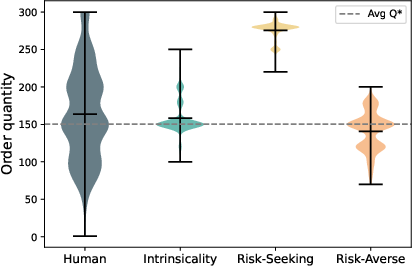
Figure 7: Order quantity distributions across risk-framed instruction conditions, reinforcing LLMs' reduced behavioral diversity.
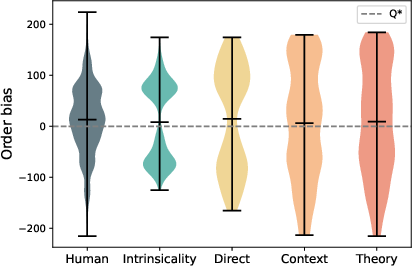
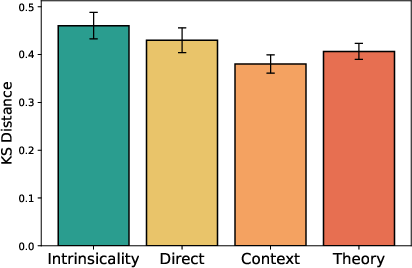
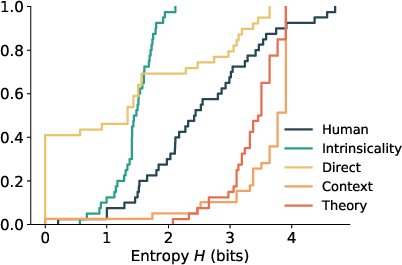
Figure 8: Order bias distribution under imitation, illustrating partial but incomplete recovery of human-like order variability.
Discussion
The study demonstrates that state-of-the-art LLMs, when deployed as synthetic agents in dynamic decision-making tasks, inherently favor rational, profit-maximizing strategies with low intra- and inter-agent variance. This deterministic optimization is a direct consequence of training objectives and decoding strategies that prioritize high-probability outputs. While textual framing and in-context demonstrations can nudge LLMs toward more human-like behavior, these interventions do not fully replicate the stochasticity and context-sensitive adaptation intrinsic to human decision-making.
The persistent alignment gap in behavioral fidelity has significant implications for the use of LLMs as proxies in social science research, synthetic data generation, and experimental simulation. Without the noise and variability that characterize human cognition, LLM-based simulations risk overestimating equilibrium convergence and misrepresenting welfare allocation. The authors advocate for behavioral audits and transparent reporting of variability gaps when employing LLMs in behavioral studies.
Implications and Future Directions
The process-oriented evaluation framework provides a practical methodology for auditing LLM behavioral realism in dynamic tasks. The findings suggest that future model development should balance optimization with mechanisms that induce stochasticity and adaptive heuristics, potentially via reinforcement learning, memory-based adaptation, or multi-agent conditioning. Extending the framework to interactive, multi-agent environments and more diverse human populations will further elucidate the boundaries of LLM behavioral fidelity.
Conclusion
This work establishes that current LLMs, despite their proficiency in reasoning and optimization, do not faithfully reproduce the variability and adaptability of human decision-making in dynamic contexts. Progressive interventions can partially bridge the gap, but full behavioral realism remains elusive. The proposed framework sets a new standard for process-aware evaluation and highlights the necessity of behavioral audits in the deployment of LLMs as synthetic human proxies.