The Role of Social Learning and Collective Norm Formation in Fostering Cooperation in LLM Multi-Agent Systems
Abstract: A growing body of multi-agent studies with LLMs explores how norms and cooperation emerge in mixed-motive scenarios, where pursuing individual gain can undermine the collective good. While prior work has explored these dynamics in both richly contextualized simulations and simplified game-theoretic environments, most LLM systems featuring common-pool resource (CPR) games provide agents with explicit reward functions directly tied to their actions. In contrast, human cooperation often emerges without full visibility into payoffs and population, relying instead on heuristics, communication, and punishment. We introduce a CPR simulation framework that removes explicit reward signals and embeds cultural-evolutionary mechanisms: social learning (adopting strategies and beliefs from successful peers) and norm-based punishment, grounded in Ostrom's principles of resource governance. Agents also individually learn from the consequences of harvesting, monitoring, and punishing via environmental feedback, enabling norms to emerge endogenously. We establish the validity of our simulation by reproducing key findings from existing studies on human behavior. Building on this, we examine norm evolution across a $2\times2$ grid of environmental and social initialisations (resource-rich vs. resource-scarce; altruistic vs. selfish) and benchmark how agentic societies comprised of different LLMs perform under these conditions. Our results reveal systematic model differences in sustaining cooperation and norm formation, positioning the framework as a rigorous testbed for studying emergent norms in mixed-motive LLM societies. Such analysis can inform the design of AI systems deployed in social and organizational contexts, where alignment with cooperative norms is critical for stability, fairness, and effective governance of AI-mediated environments.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies how groups of AI “agents” (powered by LLMs) learn to share a limited resource fairly and avoid ruin. Think of a lake with fish: if everyone catches too much, the fish disappear; if they cooperate, the lake stays healthy. The researchers built a simulation where AI agents must figure out how much to “fish,” whether to punish rule-breakers, and how to set group rules—all without being told their exact scores or the best strategy.
What questions did the researchers ask?
They asked simple but important questions:
- Can AI agents learn to cooperate and follow fair rules when their personal rewards are unclear?
- How do social learning (copying successful peers) and punishment (penalizing rule-breakers) help cooperation?
- Do different LLMs behave differently as members of a group?
- How do starting conditions—like a rich vs. poor environment, or mostly selfish vs. mostly altruistic agents—change what happens?
- Which parts of the system matter most: copying others, voting on rules, or both?
How did they study it?
They created a “common-pool resource” game (like a shared lake) and let many AI agents play it over time. The key twist: agents don’t see obvious scores or a perfect map from actions to rewards. Instead, they must infer what works by watching outcomes and others.
The shared resource game
- There’s a shared resource that can regrow but has a limit (like fish in a lake).
- Each round, every agent decides how hard to harvest (how much to fish).
- If too many fish are taken, the lake can collapse. If groups manage it well, it stays healthy.
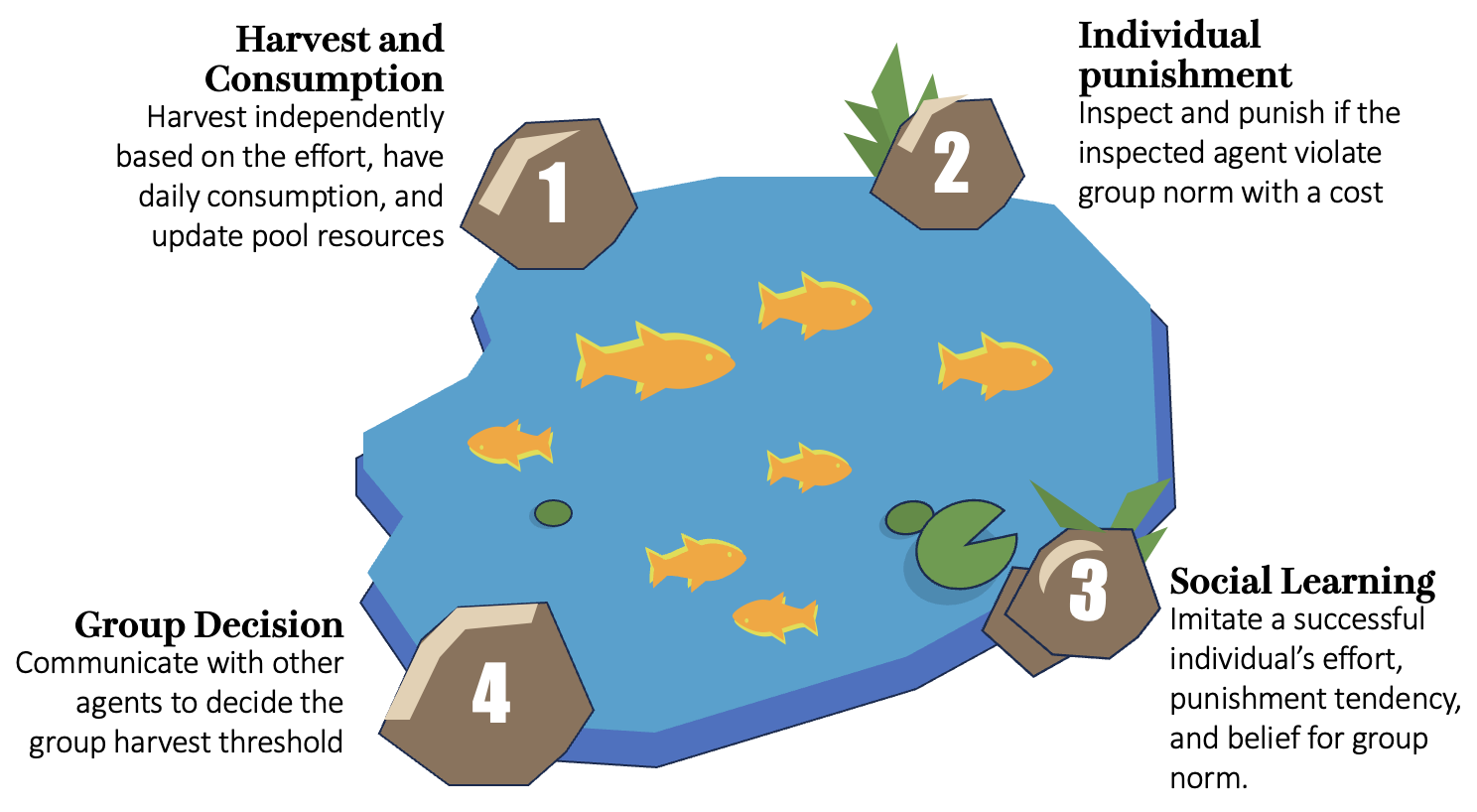
What agents can do (the four modules)
To keep this understandable, here are the four things agents can do each round:
- Harvest and consume: Decide how much effort to spend harvesting and then “use” some of what they get.
- Punish: Pay a personal cost to penalize someone they think took too much. This mirrors real-life communities that fine or call out rule-breakers.
- Social learning: Notice which agents seem to be doing well over time and copy parts of their strategy. This is like students copying study habits from the top performers.
- Group decision (propose → vote): Each agent proposes a simple group rule (a norm), then everyone votes. The winning rule is shared for the next round. This replaces long chats with quick, scalable voting.
Important detail: Agents don’t see a neat, direct reward function. They only see messy, local information—like their last harvest, a few peers’ outcomes, and the current group rule—so they must reason under uncertainty.
Measuring success
The researchers looked at:
- Survival time: How long the group avoids collapse (resource depletion or agents “starving”).
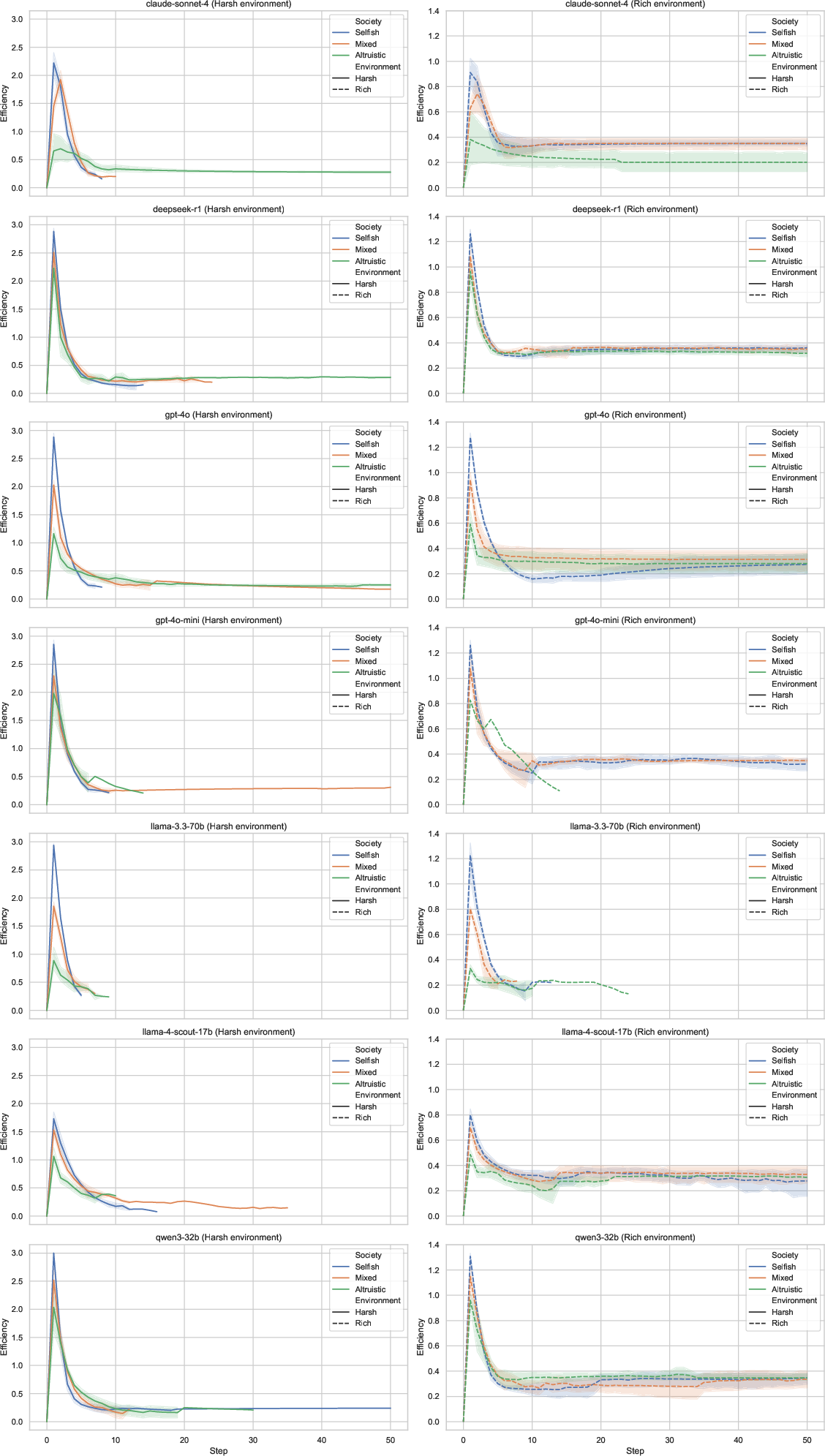
- Efficiency: How close the group is to the ideal, sustainable harvest (not too little, not too much).
What did they find?
Here are the main results, explained in plain language:
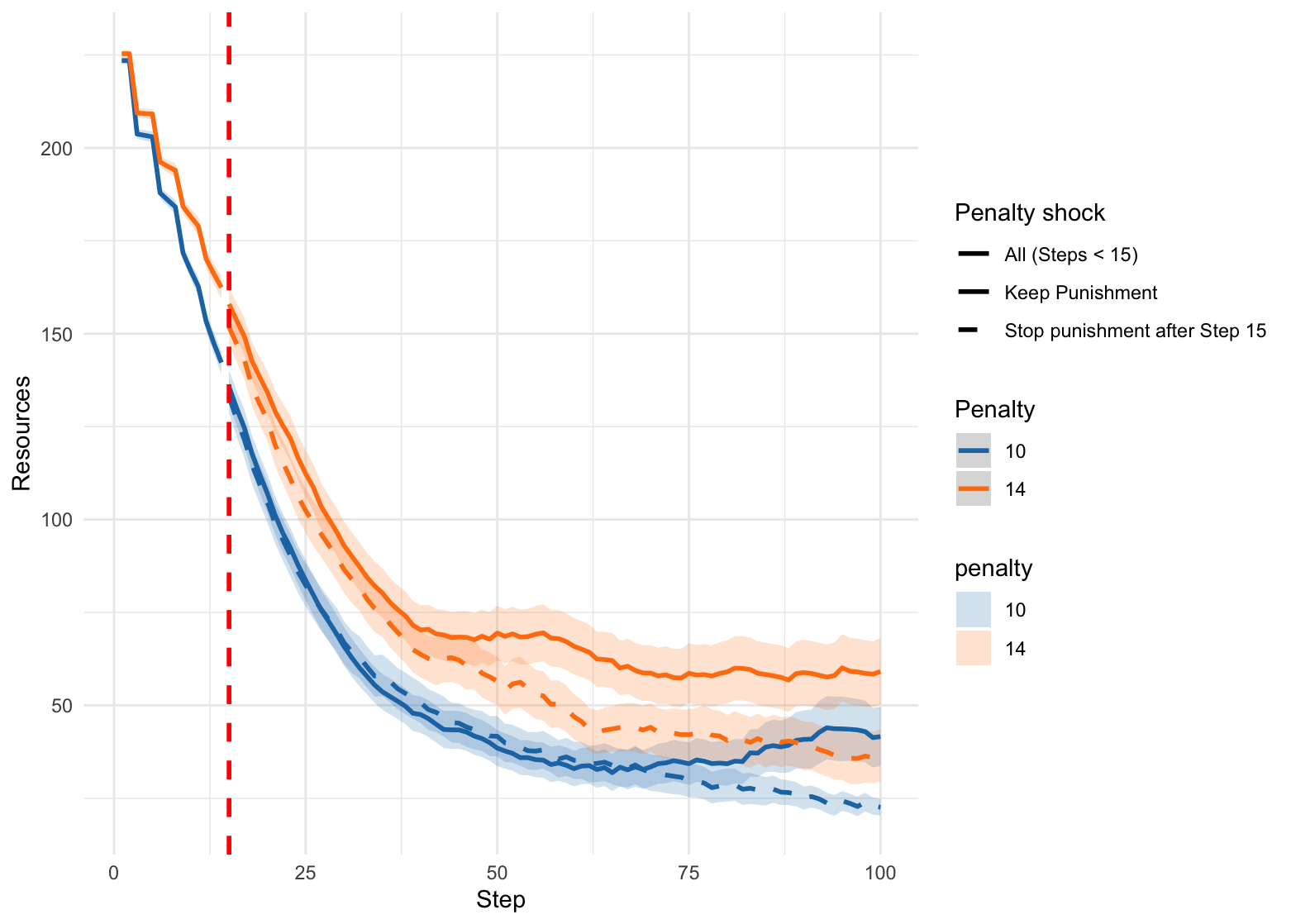
- Punishment matters: When agents can punish over-harvesters, cooperation lasts longer. Turn punishment off, and cooperation quickly breaks down.
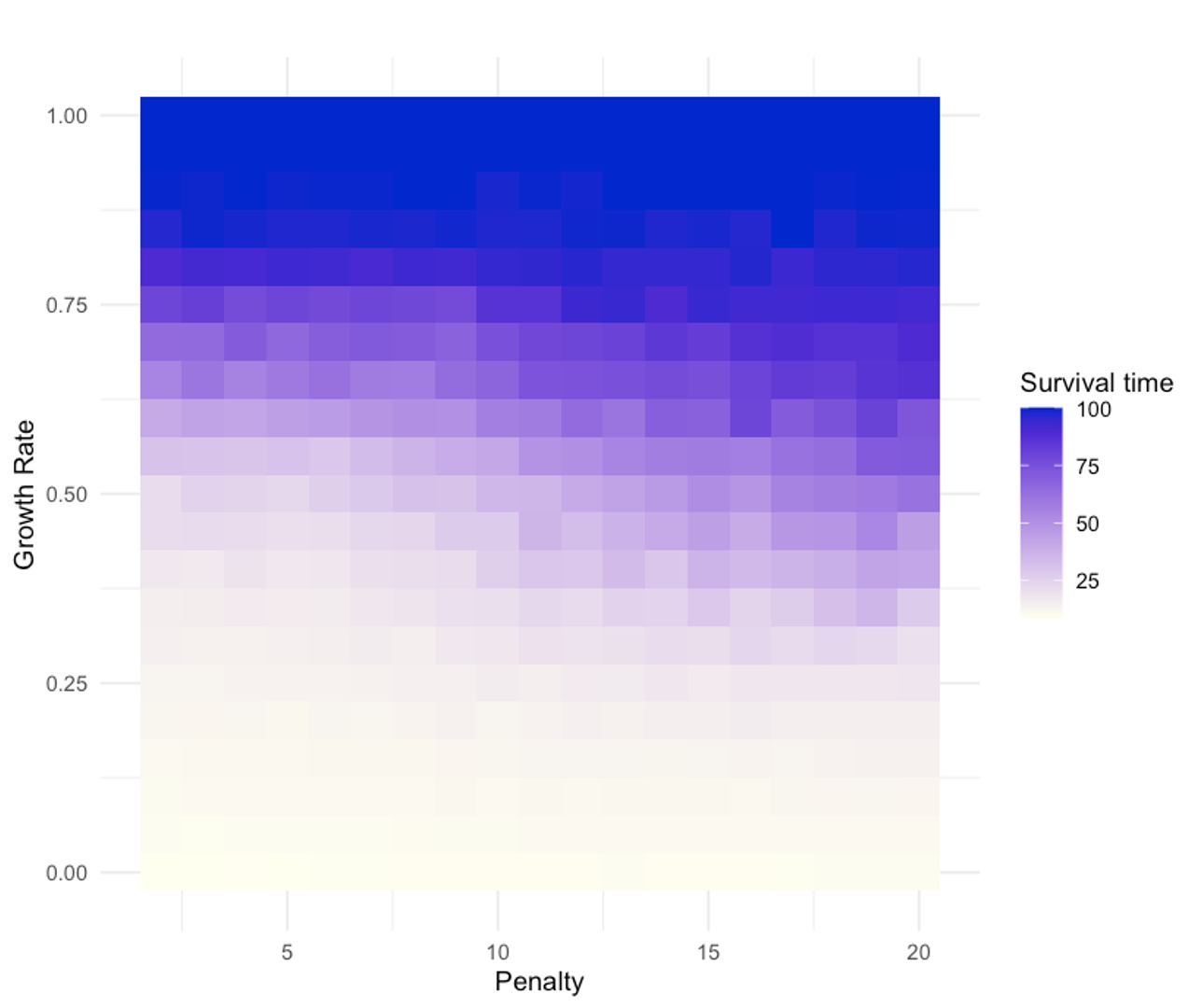
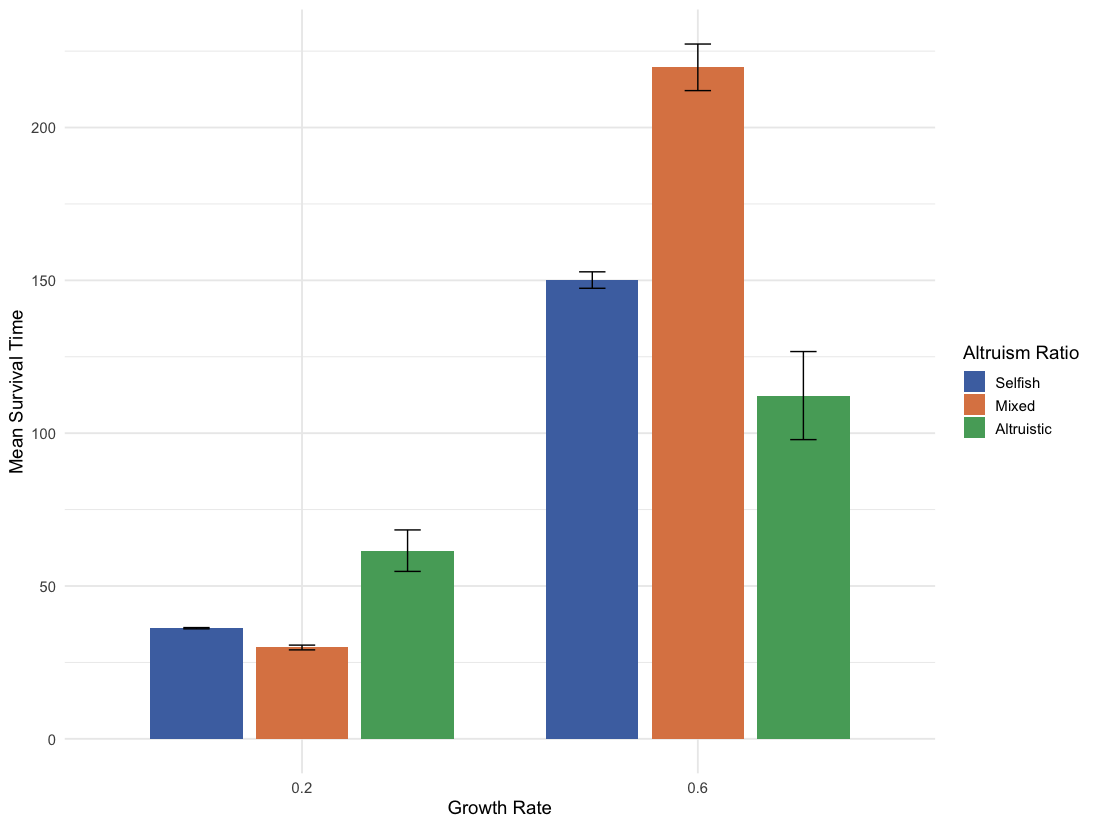
- Environment changes the best strategy:
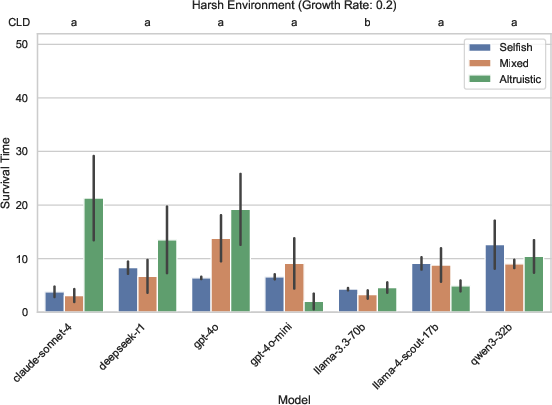
- In harsh environments (low resource growth), altruistic groups do better because they protect the resource.
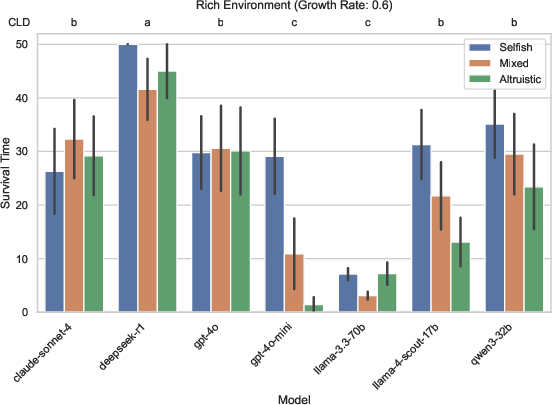
- In rich environments (high resource growth), mixed or slightly selfish groups can do well by avoiding underuse, but they still need coordination to prevent overuse.
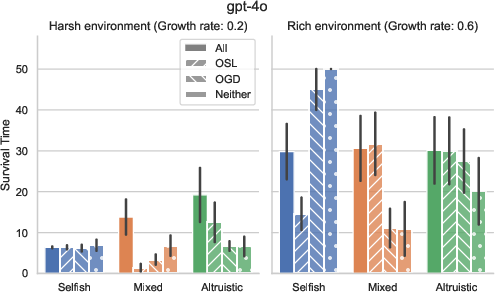
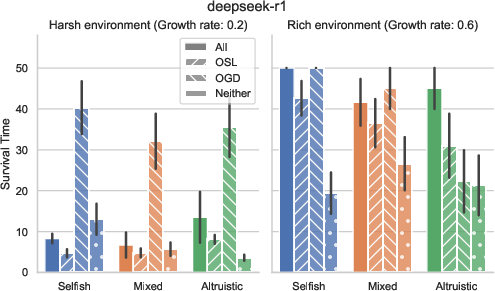
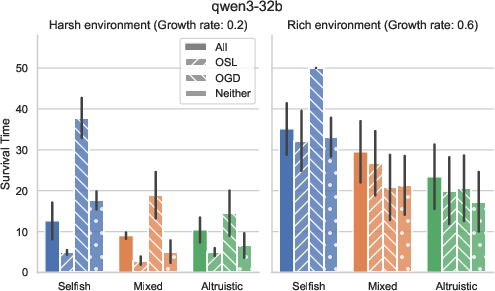
- Different LLMs act differently:
- Larger, stronger models tended to cooperate better and adapt their behavior sensibly.
- Some models (like deepseek-r1) explored more and often survived longest, especially in rich settings.
- Others (like gpt-4o and claude-sonnet-4) tended to settle into steady, more conservative (altruistic) behavior sooner.
- Smaller models often collapsed early, regardless of how they started, because they struggled to adapt.
- Initial attitude helps, but model choice matters more:
- Starting with altruistic norms helps in harsh environments.
- In rich environments, starting selfish can sometimes work out—if the model can still coordinate and avoid over-harvesting.
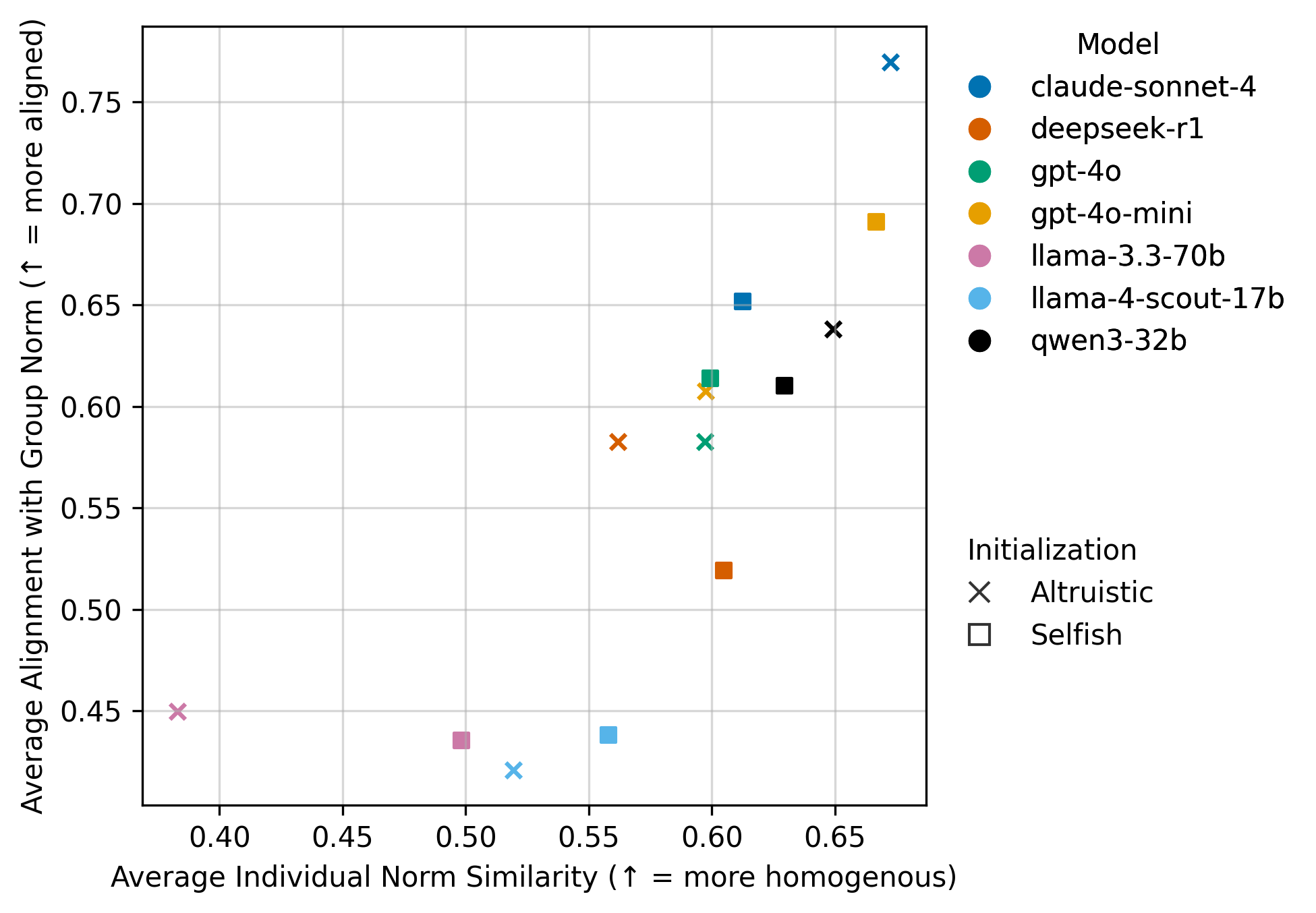
- Overall, differences between model families were larger than differences caused by initial settings.
- Voting and copying play different roles:
- Removing both alignment tools (no social learning, no group voting) makes the group fail fastest.
- Voting on a shared rule alone can sometimes be enough to keep things stable.
- Copying successful peers without a shared rule tends to be unstable, because short-term wins can mislead the group.
- The best setup depends on the model: some models do great with strong group rules; others benefit from having both copying and voting to balance exploration and stability.
Why this is important: These patterns match what human communities often show—punishment, shared rules, and social learning help cooperation—so the simulation looks realistic and useful. It also reveals that different AI models have different “personalities” in group settings.
Why does this matter?
- Building trustworthy AI teams: If AI agents help run platforms, markets, or online communities, we want them to cooperate, be fair, and avoid harmful cycles like overuse of shared resources. This framework helps test whether an AI model is likely to play nicely with others.
- Designing better rules: The study shows that simple tools—like quick voting on rules and fair punishment—can stabilize a group, even when individuals can’t see perfect feedback.
- Choosing the right model: Different LLMs lead to different group outcomes. Picking the model is not just a technical choice—it affects fairness, stability, and long-term success.
In short
The paper builds a realistic, easy-to-scale playground for studying how AI agents learn to share. It shows that:
- Cooperation can emerge without clear rewards if agents have social learning, punishment, and simple voting.
- Model choice and environment both matter.
- This approach can guide safer, fairer AI systems used in schools, workplaces, and online communities—places where “playing nice together” is essential.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what the paper leaves missing, uncertain, or unexplored, aimed at guiding future research.
- Scaling to larger societies remains untested: most simulations use N≈10 agents; evaluate coordination quality, collapse rates, and API costs at N=100–1000, and report throughput/latency and failure modes of the propose→vote mechanism at scale.
- Reproducibility is hampered by missing implementation details: release the full parameter table, all prompts (initial norm templates, effort/punish/propose/vote), decoding settings (temperature, top-p), seeds, and code to enable independent replication.
- Metrics are underspecified/typo-prone: clarify and validate the efficiency metric and collapse criteria, disentangling resource-collapse versus starvation, and report sensitivity to metric choices.
- Unclear norm vectorization: specify exactly how natural-language norms are embedded into vectors (embedding model, preprocessing, dimensionality), and study sensitivity to representation choices.
- LLM “social learning” is in-context, not strategy copying: quantify selection strength (analogue of ) for LLM agents, measure imitation fidelity, and test whether explicit parameter copying changes outcomes.
- Punishment detection by agents themselves is not validated: measure false positives/negatives, bias across agents/models, and compare language-based enforcement to ground-truth numeric thresholds under identical conditions.
- Sanction strength effects in LLM societies are not systematically explored: sweep penalty and punisher cost (as done in ABM) for LLM agents to quantify how sanction parameters shape cooperation.
- Observation noise and misinformation are not modeled: introduce controlled noise, delays, and adversarial misreporting in , and evaluate robustness of cooperation and norm enforcement under imperfect information.
- Voting rule dependence is unexamined: compare majority/median, ranked-choice, supermajority, quorum, veto, and weighted voting; assess how aggregation rules affect stability, fairness, and susceptibility to norm capture.
- Collusion and manipulation risks are untested: probe whether agents can coordinate to entrench selfish norms (e.g., vote buying, coalition formation), and evaluate resilience to Sybil attacks and strategic proposal framing.
- Social network structure is absent: replace uniform random interactions with realistic network topologies (degree heterogeneity, clustering) to study how networked monitoring/punishment and prestige-based imitation affect norm spread.
- Multi-resource and intergroup dynamics are missing: extend to multiple interdependent resources and cross-group interactions to test norm layering, spillovers, and group-level selection under migration and competition.
- Long-horizon dynamics are truncated: run extended simulations to probe norm drift, hysteresis, cyclical behaviors, resilience to shocks, and recovery post-collapse; include seasonality and stochastic growth in .
- Model coverage and attribution are limited: expand the LLM pool (more model families/sizes, open-source variants), and disentangle capacity versus training/preference-tuning effects on cooperative tendencies.
- Prompt and decoding sensitivity is not systematically studied: perform prompt ablations and decoding sweeps (temperature, top-p, nucleus sampling) to quantify robustness and to identify prompt-design principles that generalize.
- Memory constraints and retention are not evaluated: test how context length, memory tools, and external state influence norm persistence, compliance, and path dependence; compare short vs. long memory regimes.
- Distributional outcomes are not measured: quantify inequality in wealth , punishment burden, and individual welfare; examine trade-offs between efficiency, equity, and stability.
- Content analysis of norms is qualitative: conduct systematic coding of proposed norms over time (e.g., conservatism, conditionality, sanction severity), link linguistic features to outcomes, and release annotated corpora.
- Compliance ground-truth is absent: calibrate language-based enforcement decisions against numeric thresholds to establish an accuracy baseline and create a benchmark for norm violation detection.
- Agent heterogeneity is narrow: vary consumption , productivity , monitoring propensity , and initial norm diversity; assess how heterogeneity shapes cooperation and sanction effectiveness.
- Parameter transparency and sensitivity are lacking for LLM runs: report (and vary) peer-sampling sizes, mutation/noise levels, selection parameters, and monitoring probabilities; conduct sensitivity analyses akin to ABM sweeps.
- External validity to human groups is not tested: run human-in-the-loop experiments or human-only baselines in the same latent-payoff CPR setting to compare norm evolution, enforcement accuracy, and stability.
- Mechanism isolation is incomplete in LLM settings: ablate punishment and sanction channels for LLM societies (as in ABM) to isolate the causal roles of punishment versus social learning versus group voting.
- Institutional co-evolution is only proposed: implement dynamic governance (e.g., evolving monitoring, sanction tiers, voting rules), and test stability of institution–norm co-evolution under shocks and strategic behavior.
- Exploration vs. exploitation is not operationalized: define quantitative measures of model-specific exploratory bias and relate them to decoding settings and survival/efficiency trajectories.
- Safety risks are not evaluated: assess potential emergence of harmful/exclusionary norms, manipulation, and exploitation; design and test safeguard mechanisms (e.g., constitutional constraints, oversight agents).
- Resource dynamics are stylized: evaluate alternative growth models, nonstationarity in , and exogenous shocks; test whether observed cooperation patterns generalize beyond logistic growth.
- Information design is fixed: vary transparency (visibility of others’ outcomes, the group norm, enforcement outcomes) to measure how information availability affects social learning and compliance.
- Statistical power is limited: increase the number of trials, report effect sizes and confidence intervals consistently, and consider preregistration of hypotheses and analysis plans to improve inferential robustness.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, linked to sectors, potential tools/workflows, and feasibility notes.
- Bold model selection and governance testbed for multi-agent deployments — software/AI ops
- Use the paper’s CPR framework to benchmark LLMs for cooperative behavior before integrating them into multi-agent products (e.g., assistants, automation teams). Prefer models with conservative/altruistic biases for stability (e.g., gpt-4o, claude-sonnet-4) and exploratory biases for adaptation (e.g., deepseek-r1), depending on context.
- Tools/workflows:
LLM Society Sandboxfor survival/efficiency stress tests;Cooperation Monitordashboard tracking collapse risk and norm alignment; pre-deployment CI pipelines that include mixed-motive tests. - Assumptions/dependencies: Models’ inductive biases hold across domains; benchmark parameters map meaningfully to target tasks; API cost manageable; closed-source model differences transparently documented.
- Propose→vote norm module for enterprise agent workflows — software
- Integrate the scalable propose→vote primitive (two API calls per agent per round) to set shared policies (e.g., task priorities, resource caps) among agents without long deliberation.
- Tools/workflows:
NormVotemicroservice; Slack/Teams bot for proposing and voting on norms;Norm Broadcaststep that conditions agent actions; governance runbooks favoring explicit norm broadcasts over pure imitation to reduce volatility (per ablation findings). - Assumptions/dependencies: Norm text must be reliably mapped to numeric controls; prompt templates tuned to reduce ambiguity; logging and audit trails for compliance.
- Multi-tenant rate-limiting and quota governance — cloud/software
- Treat API credits, compute cycles, or shared caches as common-pool resources; use group norms to set per-agent caps and apply graduated sanctions (e.g., throttling, temporary demotion) when caps are violated.
- Tools/workflows:
Quota Governorusing propose→vote to set caps;Sanction Engineapplying graduated penalties; payoff-biased social learning to propagate effective usage patterns. - Assumptions/dependencies: Accurate monitoring of use; fair and transparent sanctions; mapping language norms to enforcement rules; regulatory constraints on automated sanctions.
- Online community moderation and trust & safety heuristics — platforms/policy
- Deploy a norm-based moderation approach that emphasizes explicit group norms and graduated sanctions over opaque reward signals; use social learning to propagate good-conduct exemplars.
- Tools/workflows:
Community Norms Studiofor proposing and voting on rules;Graduated Sanctionsladder (warnings → limited posting → suspensions). - Assumptions/dependencies: Clear community acceptance of norms; careful design to avoid biased enforcement; integration with existing moderation tools.
- Shared budget allocation and spend discipline — finance/operations
- Use the framework to manage team-level budgets as a common pool: agents propose spending caps; group votes set norms; violations trigger mild penalties (e.g., reduced discretionary spend).
- Tools/workflows:
Budget Norms Boardfor caps;Spend Sanctionworkflow;Efficiency Indexto monitor aggregate outcomes (analogue to survival/efficiency). - Assumptions/dependencies: Accurate spend telemetry; leadership buy-in; ensuring sanctions don’t harm essential operations.
- Classroom and organisational training on commons governance — education/daily life
- Use the simulator to teach Ostrom’s principles and cultural evolution in practice; run student or team exercises on norm formation, punishment strength, and environment parameters.
- Tools/workflows:
Commons Labcourse modules; case-based learning with propose→vote; analytics on heterogeneity, alignment, and collapse conditions. - Assumptions/dependencies: Accessible interface; clear learning outcomes; safeguarding against gaming the simulation.
- Policy sandboxing for AI governance — public policy/reg-tech
- Evaluate sanction strength, growth rates, and norm mechanisms to avoid collapse in AI-mediated environments (e.g., markets, procurement platforms). Prefer explicit norm sharing when priors are selfish (ablation insight).
- Tools/workflows:
Policy Stress-Test Sandboxfor mixed-motive scenarios;Compact Letter Displaystyle statistical reporting to compare governance designs across model families. - Assumptions/dependencies: Transferability from simulated CPR dynamics to real policy domains; stakeholder transparency; ethical review.
- Agent team operations and risk management — software/product
- Apply graduated sanctions and group norms to reduce over-harvesting behaviors in agent teams (e.g., aggressive scraping, heavy API calls, or excessive experimentation).
- Tools/workflows:
Agent Ops Guardrailswith group cap broadcasting;Violation Detectorand automated penalty ladder; periodic propose→vote to update norms based on performance. - Assumptions/dependencies: Reliable telemetry; human oversight for exceptions; alignment between norms and KPIs.
- Pilot scheduling aids for scarce hospital resources — healthcare
- Treat OR time, ICU beds, or imaging slots as CPRs; assistants propose allocation norms (e.g., per-service caps), vote, and apply mild penalties for overuse (e.g., reduce overbooking privileges).
- Tools/workflows:
Clinical Capacity Normsboard;Scheduling Sanctions(soft constraints);Outcome Feedbackloops to adjust norms over time. - Assumptions/dependencies: Clinical governance approval; strong human-in-the-loop; patient safety overrides; rigorous evaluation before adoption.
- Game and simulation design to build cooperative habits — education/HR
- Create training simulations that reward efficient collective behavior under uncertainty; emphasize the paper’s finding that explicit norms stabilize better than imitation alone.
- Tools/workflows:
Cooperate or Collapsetraining scenarios; analytics on norm alignment and individual similarity; reflective debriefs. - Assumptions/dependencies: Participant engagement; meaningful mapping to workplace tasks; avoid reinforcing punitive cultures.
Long-Term Applications
Below are use cases that benefit from further research, scaling, or development, including sector linkage, potential tools, and feasibility notes.
- AI-mediated urban resource governance (water, fisheries, shared mobility) — energy/environment/policy
- Use norm-based governance (propose→vote, monitoring, graduated sanctions) to manage city-level CPRs; incorporate heterogeneous agent populations and multi-tier institutions.
- Tools/workflows:
City Commons OSwith multi-level norms; sensors integrated with enforcement; cross-community social learning for best practices. - Assumptions/dependencies: Robust mapping from language to policy; legal frameworks for sanctions; inclusive civic participation; data governance.
- Microgrid and storage management under demand uncertainty — energy
- Treat shared batteries and peak capacity as CPRs; agents set consumption caps and adjust norms via feedback; penalties deter overuse that risks outages.
- Tools/workflows:
Grid Norm Controller; market-awareGraduated Tariffsas sanctions;Efficiency vs Survivalmetrics aligned with reliability indices. - Assumptions/dependencies: High-fidelity forecasting; grid operator collaboration; safety-critical validation.
- Multi-robot fleet coordination and resource sharing — robotics/logistics
- Warehouse or delivery robots share constrained resources (charging docks, aisle access, bandwidth); apply group norms and penalties (e.g., reduced priority or speed caps) for congestion control.
- Tools/workflows:
Fleet Norm Manager;Congestion Sanctionsmodule; onboard social learning parameters tuned for robustness. - Assumptions/dependencies: Real-time telemetry; safety guarantees; adversarial robustness; mapping language norms to control policies.
- Algorithmic regulation platforms and adaptive policy evaluation — policy/reg-tech
- Institutionalize propose→vote and payoff-biased social learning to update rules in digital markets; use ablation insights to balance explicit alignment and exploration.
- Tools/workflows:
Adaptive RegOpsplatform; sandboxed policy iteration; continuous measurement of collapse risk and fairness. - Assumptions/dependencies: Legal legitimacy; transparency and appeal mechanisms; bias auditing; public trust.
- Cross-institution AI compute governance — AI infrastructure
- Coordinate shared compute pools across labs using explicit norms (caps, scheduling) and structured sanctions (priority queues) to avoid resource collapse and lab “free-riding.”
- Tools/workflows:
Compute Commons Governor; federated propose→vote; cross-tenant monitoring and graduated priority adjustments. - Assumptions/dependencies: Inter-org agreements; secure telemetry; equitable access; resistance to gaming.
- Financial risk governance with agentic desks — finance
- Use norm-based caps on risk exposures; agents propose risk limits and vote; apply sanctions (e.g., automatic position limit reductions) to stabilize against tail-risk “overharvesting.”
- Tools/workflows:
Risk Norms Council;Exposure Sanctionsladder; payoff-biased learning to propagate effective hedging behaviors. - Assumptions/dependencies: Regulatory compliance; integration with risk engines; human oversight; prevention of collusion.
- Autonomous organisations (AI-native DAOs) with norm-based governance — software/web3
- Replace hardcoded incentive functions with endogenously evolving group norms; punish misaligned behaviors via on-chain sanctions; vote on collective policies at scale.
- Tools/workflows:
On-chain NormVote;Sanction Smart Contracts;Norm Retentionbroadcast mechanism. - Assumptions/dependencies: Secure and interpretable mapping from natural language norms to smart contract actions; governance minimises manipulation; community buy-in.
- Rich deliberative mechanisms beyond propose→vote — software/human–AI interaction
- Extend to multi-turn debate, memory, and justification; scale to larger populations while maintaining cost-effective interactions; study when deliberation improves over median-voter rules.
- Tools/workflows:
Deliberation Enginewith summarization/memory;Consensus Metricstracking norm stability and fairness. - Assumptions/dependencies: Longer context handling; robust memory; avoiding conversational capture and bias.
- Sector-specific CPR simulators for training and decision support — academia/industry
- Tailor the framework to domain CPRs (e.g., fisheries, forestry, spectrum allocation); use survival/efficiency metrics to guide policy and training.
- Tools/workflows:
Sector Commons Simkits; role-based agent libraries; embedded analytics and reporting. - Assumptions/dependencies: Domain-specific ecological/economic models (beyond logistic growth); credible validation with field data; ethical oversight.
- Standards and audits for multi-agent cooperation — academia/industry/policy
- Establish evaluation protocols for cooperative competence in mixed-motive settings; include cross-model “family clustering” effects and sensitivity to prompting as audit dimensions.
- Tools/workflows:
Cooperation Certificationprogram; public benchmarks of survival time and norm alignment; model selection guidelines for high-stakes deployments. - Assumptions/dependencies: Community consensus; reproducibility across closed/open models; funding and governance for maintaining standards.
Cross-cutting assumptions and dependencies
- Mapping from natural-language norms to enforceable numeric controls is reliable, audited, and explainable.
- Monitoring and sanctions are fair, transparent, and appropriately graduated to avoid harmful or biased enforcement.
- Model-specific inductive biases (e.g., conservative vs. exploratory) and prompt sensitivity significantly affect outcomes; careful selection and tuning are required.
- Human-in-the-loop oversight remains essential in safety-critical domains (healthcare, energy, robotics, finance).
- Transferability from simulated CPR dynamics to real-world institutional contexts must be validated with domain data and stakeholder engagement.
Glossary
- 95% CI: A statistical interval that estimates the range within which the true parameter lies with 95% confidence. "Shaded bands denote 95\% CI (s.e.m.)."
- Agent-Based Modeling (ABM): A simulation approach where individual agents with rules interact to produce emergent system-level behavior. "using Agent-Based Modeling (ABM)."
- Agentic society: A simulated or modeled society composed of autonomous agents capable of making decisions and interacting. "an agentic society"
- Bioeconomic models: Models that combine biological resource dynamics with economic decision-making to analyze resource use and policy. "classic bioeconomic models."
- Black-box policies: Decision policies implemented by models (e.g., LLMs) whose internal workings are not transparent, treated as input-output mappings. "LLM interfaces (black-box policies)"
- Carrying capacity: The maximum population or resource level that an environment can sustain over time. "carrying capacity "
- Catch function: A function describing how much resource is harvested as a function of effort and resource stock. "we assume a standard catch function"
- Compact Letter Display (CLD): A notation used after multiple-comparison tests to indicate which groups differ significantly. "Compact Letter Display (CLD) notation"
- Common-pool resource (CPR): A resource system where it is costly to exclude users and where one user’s consumption reduces availability for others. "common-pool resource (CPR) games"
- Conformity bias: A social learning tendency to adopt behaviors or norms prevalent in a group, regardless of payoffs. "including payoff-biased social learning, conformity bias, and punishment."
- Cultural evolution: The study of how behaviors, norms, and strategies change and spread in populations through learning and social processes. "cultural evolution theory"
- Density-dependent growth: Population/resource growth that slows as the population approaches environmental limits. "captures density-dependent growth"
- Donor Game: A game-theoretic model where one agent can pay a cost to confer a benefit to another, used to study generosity and cooperation. "In the Donor Game"
- Exponential moving average: A smoothed statistic giving exponentially decreasing weights to older observations. "e.g., an exponential moving average"
- Graduated sanctions: Enforcement mechanisms where penalties increase with the severity or frequency of violations. "Ostromâs principles emphasise graduated sanctions"
- Group-beneficial norms: Norms that improve collective outcomes even if they may be costly for individuals to follow. "group-beneficial norms"
- Group-level selection: Selection processes operating on groups (not just individuals), favoring traits that benefit group performance. "as well as group-level selection as evolutionary mechanisms"
- Intrinsic growth: The inherent growth rate of a population or resource in the absence of constraints. "intrinsic growth "
- Maximum sustainable yield: The highest long-term average catch or harvest that can be taken from a resource without depleting it. "maximum sustainable yield"
- Median-voter rule: A collective decision method where the median of proposed policies is selected as the group choice. "median-voter rule"
- Mixed‑motive: Situations where individual incentives conflict with collective welfare, creating social dilemmas. "mixedâmotive scenarios"
- Ostrom’s institutional design principles: Empirically grounded guidelines for governing commons effectively through monitoring, sanctions, and local rule-making. "Ostromâs institutional design principles for governing the commons"
- Pairwise-logit rule: A probabilistic imitation/update rule where the chance of adopting another’s strategy depends on payoff differences via a logistic function. "pairwise-logit rule"
- Payoff-biased imitation: Preferentially copying strategies of higher-performing peers. "payoff-biased imitation drives high-payoff strategies to spread"
- Payoff-biased social learning: Social learning that favors adopting behaviors associated with higher observed payoffs. "payoff-biased social learning"
- Propose→vote procedure: A scalable collective-choice mechanism where agents propose norms and then vote to adopt one. "proposevote rule"
- Public good: A good that is non-excludable and non-rivalrous, where individual contributions benefit all. "tokens contributed to the public good"
- Sanctioning: Penalizing norm violators to enforce compliance and sustain cooperation. "via sanctioning"
- Selection strength: A parameter controlling how strongly payoff differences influence the probability of adopting another strategy. "controls selection strength"
- Stag Hunt: A coordination game illustrating the trade-off between safe, low-payoff choices and risky, high-payoff cooperation. "the Stag Hunt"
- Standard error of the mean (s.e.m.): A measure of how precisely a sample mean estimates the population mean. "with s.e.m."
- Tukey's HSD: A post-hoc multiple-comparison test used after ANOVA to find which group means differ. "Tukey's HSD post-hoc tests"
- Two-way ANOVA: A statistical test analyzing the effects of two factors (and their interaction) on a dependent variable. "two-way ANOVA"
- Variation–selection–retention loop: A framework where behaviors vary, selection favors some variants, and successful ones are retained and propagated. "variation-selection-retention loop"
- Verhulst growth: Another name for logistic growth, modeling population/resource growth with a carrying capacity. "Verhulst growth"
Collections
Sign up for free to add this paper to one or more collections.

