- The paper demonstrates the equivalence between linear self-attention and Fast Weight Programmers using dynamic memory updates.
- It introduces a novel delta rule-like update that selectively modifies key-value associations to improve memory capacity.
- The method, validated on synthetic tasks and language processing, enhances long-term dependency handling in Transformers.
Introduction
The paper "Linear Transformers Are Secretly Fast Weight Programmers" examines the formal equivalence between modern linear self-attention mechanisms used in Transformers and Fast Weight Programmers (FWPs) introduced in the early '90s. FWPs use a "slow" neural network to dynamically program the "fast weights" of another network, with these weights depending on the spatial-temporal context provided by the sequence inputs. The authors leverage this perspective to address the memory capacity limitations of linear Transformers and propose improvements through alternative programming instructions and a novel attention kernel.
FWPs use sequences of outer products of activation patterns (referred to as keys and values) for memory manipulation. Linear attention in Transformers can be viewed as equivalent operations, allowing for better memory interaction through linearisation techniques that avoid quadratic scaling of typical self-attention.
The FWP perspective showed that linear attention mechanisms face memory capacity constraints when sequence lengths exceed the dimensions of the associative memory, potentially leading to retrieval errors. The paper proposes a dynamic interaction model where the memory can selectively update or remove stored associations based on an improved delta-rule-like programming instruction.
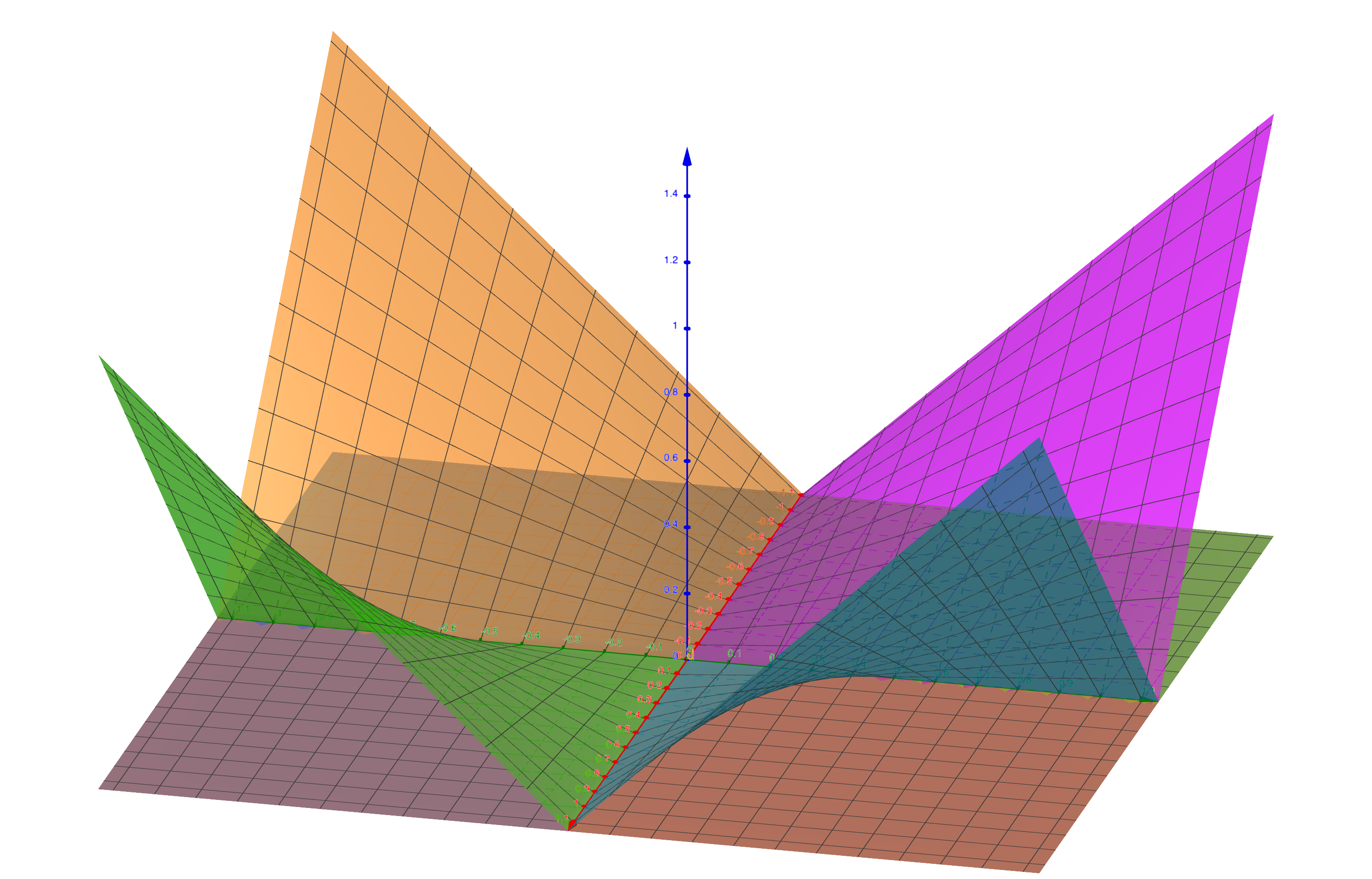
Figure 1: A visualisation of a DPFP from a 2d space (the xy-plane) to a 4d space (the four colored surfaces). Each surface is a partial function which represents one element of the 4d vector.
Memory Programming Instruction
The improved programming instruction allows FWPs to dynamically correct current mappings from keys to values and compute adaptive learning rates. The crucial addition involves a delta rule-like update where each association can be selectively updated without affecting unrelated ones—an area where past approaches fell short. This method ensures that retrieval maintains orthogonal vector associations, preventing interference during memory access.
Experimental Validation
The authors conducted experiments on several synthetic tasks designed to measure the memory capacity and evaluate the effectiveness of the proposed memory update strategies. With tasks increasing in complexity, the results indicated the strengths of the new programming instruction, especially in scenarios where keys must be frequently updated to bind context-specific values.
In machine translation and language modelling tasks, the proposed methods showed improvements over existing linear attention mechanisms due to better handling of long-term dependencies facilitated by dynamic memory interactions.
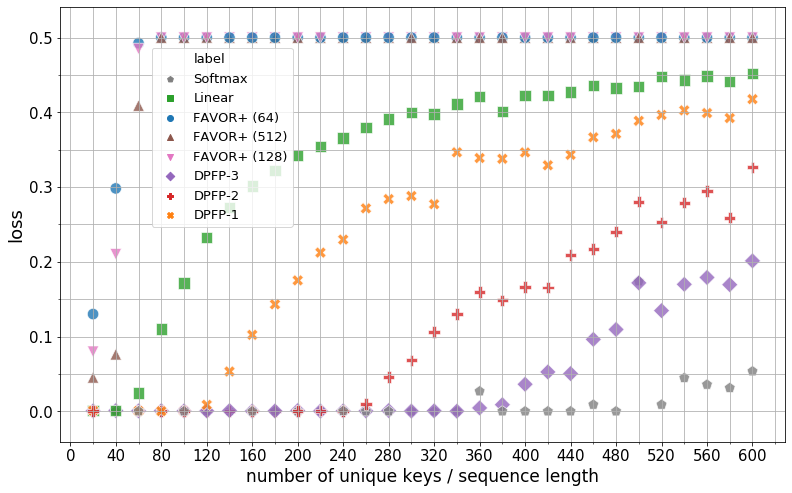
Figure 2: Final evaluation loss of the softmax memory and various linear attention mechanisms on associative retrieval problems with the total number of unique associations ranging from 20 to 600. Each individual symbol is a model trained until convergence.
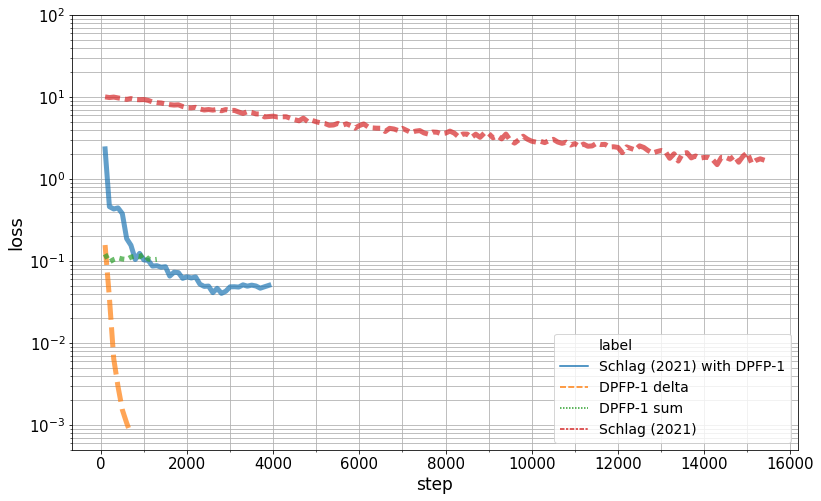
Figure 3: Learning curves for different update rules. Sequence length of 40 and 20 unique keys/values sampled with replacement.
Linear Attention Kernel Design
The paper introduces Deterministic Parameter-Free Projection (DPFP), a new kernel for linear attention. DPFP aims for simplicity while increasing the dot product space, mitigating the memory limitations of previous linearisation techniques. DPFP is deterministic and scalable, contrasting with the complex stochastic approaches of alternative methods like FAVOR+.
Conclusion
The paper underscores the relationship between linear attention mechanisms in Transformers and FWPs, providing insights into overcoming existing limitations through novel memory programming instructions and attention mechanisms. The research lays the groundwork for further exploration of improved programming strategies, aiming at enhancing the efficiency and capabilities of Transformers in processing sequences with longer contexts without the need for extensive memory overhead. Future work may explore extensions to this framework, enabling robust operation beyond the constraints imposed by current implementations.