It's Never Too Late: Noise Optimization for Collapse Recovery in Trained Diffusion Models
Abstract: Contemporary text-to-image models exhibit a surprising degree of mode collapse, as can be seen when sampling several images given the same text prompt. While previous work has attempted to address this issue by steering the model using guidance mechanisms, or by generating a large pool of candidates and refining them, in this work we take a different direction and aim for diversity in generations via noise optimization. Specifically, we show that a simple noise optimization objective can mitigate mode collapse while preserving the fidelity of the base model. We also analyze the frequency characteristics of the noise and show that alternative noise initializations with different frequency profiles can improve both optimization and search. Our experiments demonstrate that noise optimization yields superior results in terms of generation quality and variety.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
Text-to-image AI models (like Stable Diffusion) can make amazing pictures from words, but there’s a problem: if you ask for several images with the same prompt, you often get results that look almost the same. This paper shows a simple way to fix that by “tuning the noise” the model starts from, so the set of images you get is much more varied without hurting image quality.
Think of the model as starting with TV static (random noise) and gradually turning that static into a picture that matches your prompt. The authors learn how to gently adjust that starting static so the final pictures spread out—different poses, colors, layouts—while still matching the prompt.
What questions the paper asks
- Why do text-to-image models keep giving look‑alike images for the same prompt?
- Can we make the images more diverse by directly adjusting the starting noise, instead of changing the model or writing fancy prompts?
- Which “diversity goals” work best for pushing images apart in a useful way?
- Does changing the type of starting noise (especially adding more low‑frequency patterns, called “pink noise”) help?
- Will this approach work across different popular models, and does it keep image quality and prompt matching?
How they did it (in simple terms)
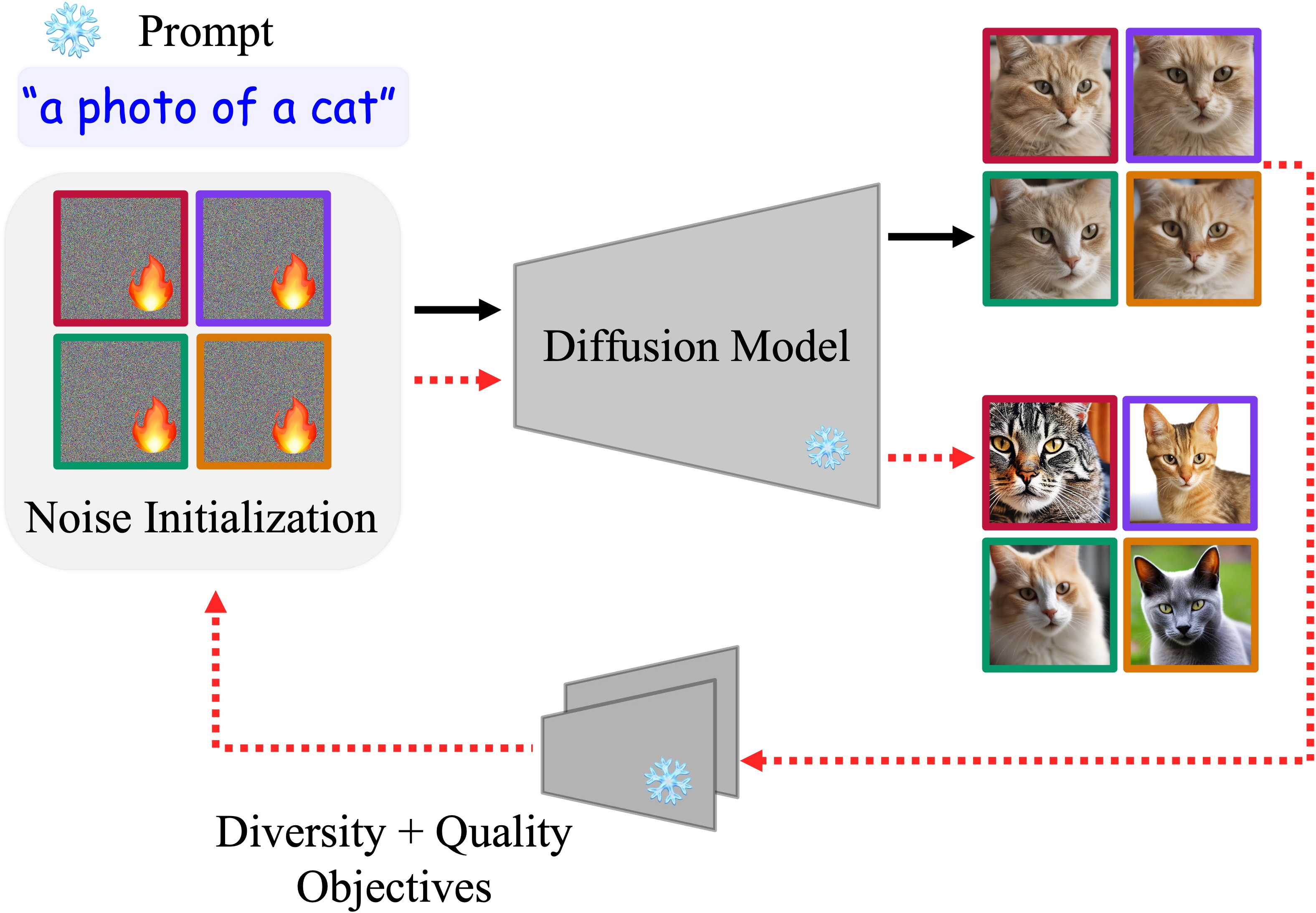
- Start with a batch (say, 4) of random noise seeds. Each seed becomes one image for the same prompt.
- Measure how similar the images are. The goal is to make them less similar (more diverse) while keeping them good and on-topic.
- Nudge the noise seeds using gradients (a standard machine learning tool for making small, smart adjustments) so that:
- The images in the set move away from each other (more variety).
- The images still match the prompt and look good.
To measure “different” and “good,” they use:
- Diversity measures (image-to-image differences):
- DINOv2, DreamSim, LPIPS: tools that compare how different images look in terms of shapes, textures, and features.
- Set-based scores like DPP and Vendi: these look at the entire group and reward sets where the images cover different “kinds” of looks, not just one odd outlier.
- Quality/prompt measures:
- CLIPScore and HPSv2: tools that check if images match the text and look appealing.
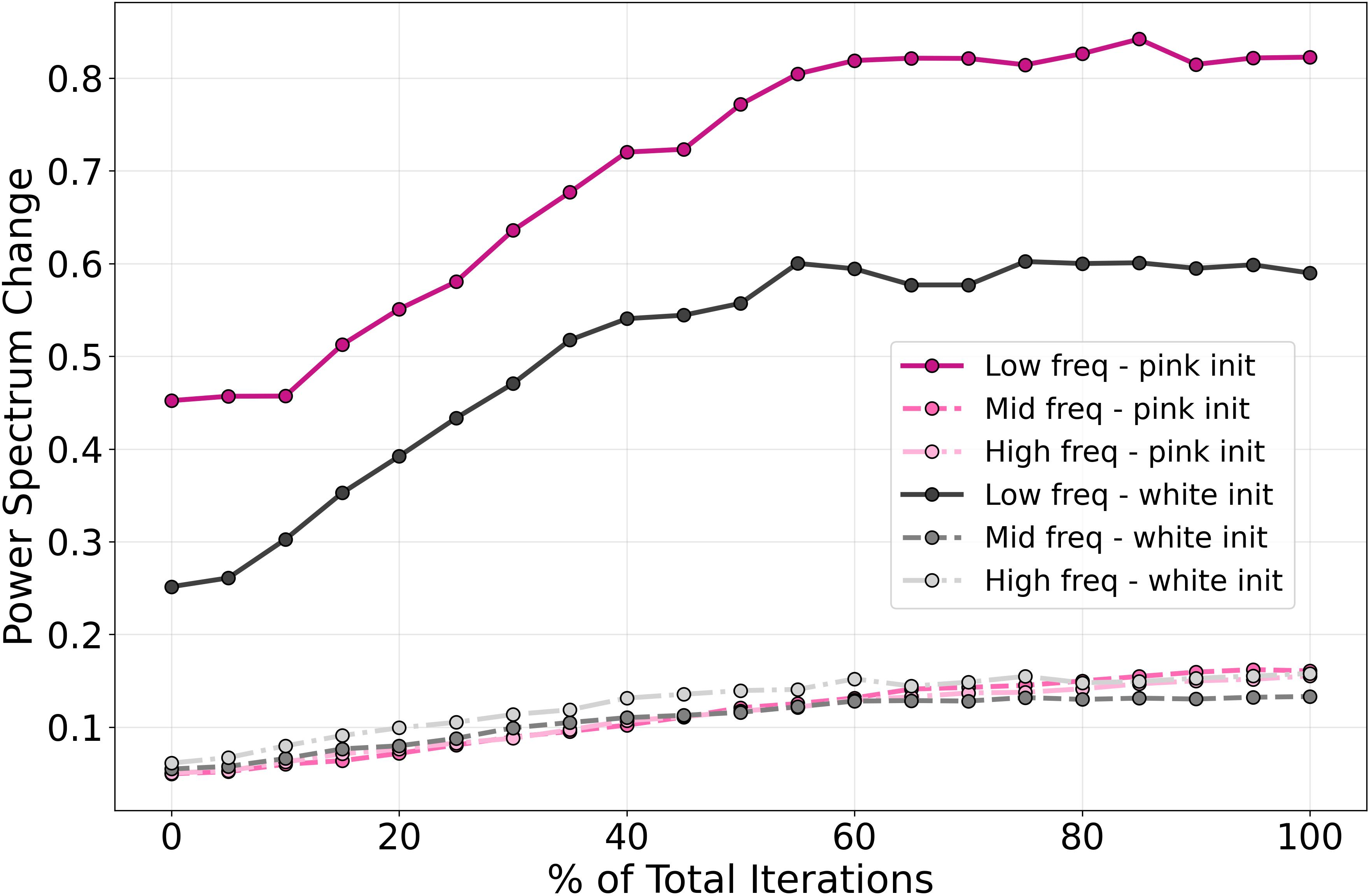
They also studied the “frequency” of the starting noise:
- Low frequencies = big shapes and smooth color areas.
- High frequencies = tiny details and fine textures.
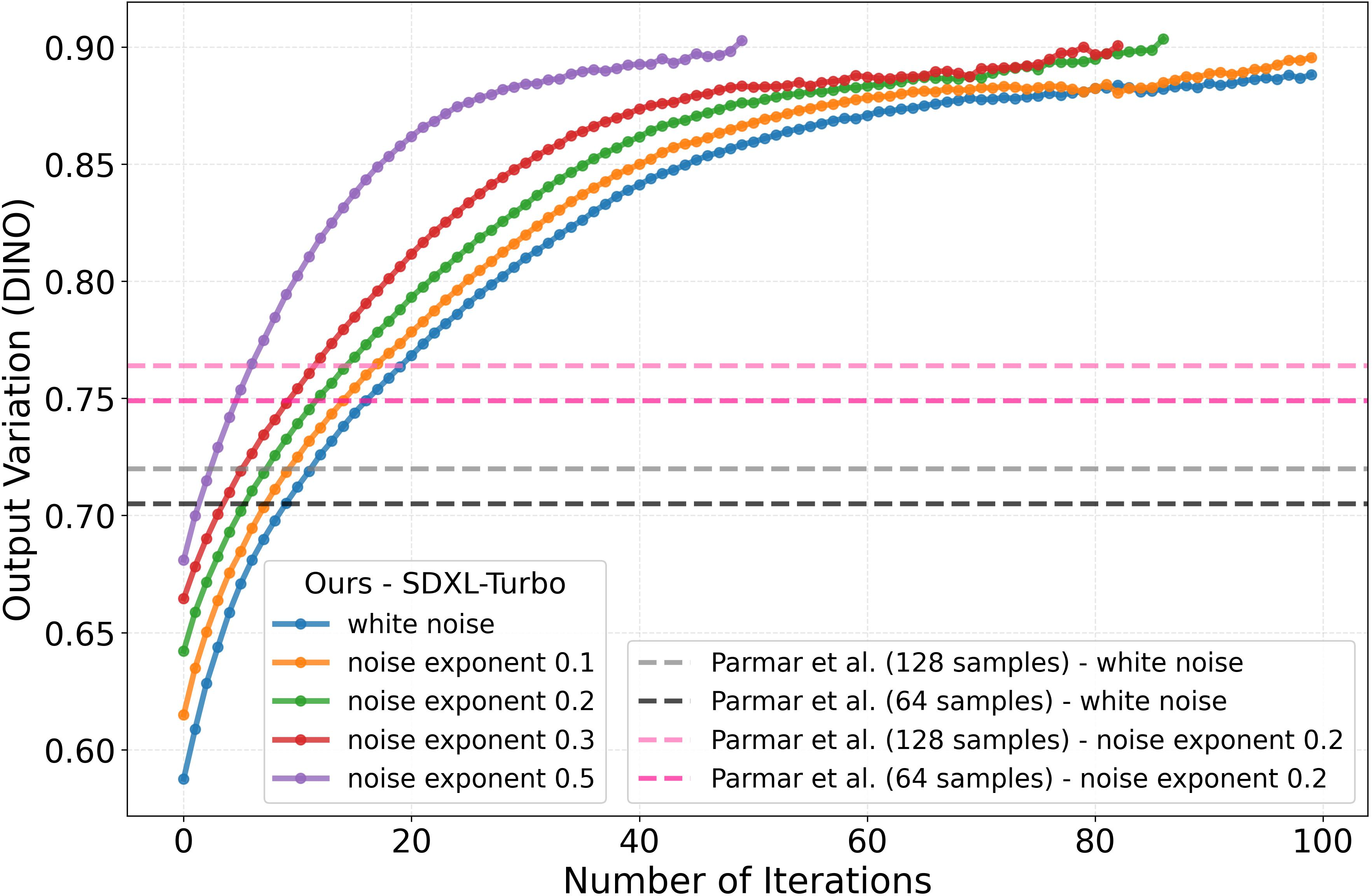
- They found their optimization mostly changes the low frequencies, so they tried “pink noise” (which naturally has more low frequencies, similar to how real images have more broad structure than fine speckles). This made it easier to get diversity.
Analogy: Imagine arranging a band. If everyone plays the same melody (mode collapse), it’s boring. The authors tune the “starting notes” (noise) so each musician (image) plays something distinct but still fits the song (prompt).
What they found and why it matters
Main results:
- Much more variety for the same prompt, across several models (SDXL‑Turbo, SANA‑Sprint, PixArt‑α, and Flux.1 [schnell]).
- Image quality and prompt alignment stayed about the same (sometimes even improved slightly), because they include gentle “quality” checks during optimization.
- Set-based diversity goals (DPP and Vendi) were preferred in user studies—they create groups where all images are meaningfully different.
- Most of the useful changes happen in low frequencies of the noise. Starting with pink noise consistently boosted diversity, not just for their method but also for baseline methods.
- Their approach beats strong baselines that rely on sampling many candidates and then picking a diverse subset. Here, they get better diversity with fewer tries by directly optimizing the noise.
- It scales: you can generate large, diverse sets by doing it “one image at a time,” each time pushing the next image to differ from the ones you’ve already made (saves memory).
Why it matters:
- Better exploration: Artists, designers, and researchers get a wider range of ideas quickly.
- Efficiency: Instead of rolling the dice with hundreds of random seeds, you steer the seeds to cover more possibilities.
- Generality: You don’t need to retrain the model; you just adjust the starting noise at inference time.
What this could change going forward
- Creative tools: Faster brainstorming with richer variety for the same prompt.
- Fairness and coverage: For prompts that could produce many valid scenes (e.g., “a photo of a city street”), this helps cover more layouts, colors, and styles.
- Better defaults: Switching to pink noise or similar low‑frequency‑boosted noise could become a simple, standard improvement.
- Broader use: The same idea—optimizing the starting point for diversity—might help in video generation, 3D, or music models that also start from noise.
- Flexible control: You can dial the trade‑off—more diversity vs. more strict prompt following—by changing the objectives and stopping rules.
In short: By smartly tweaking the starting static (noise), we can “un-collapse” text‑to‑image models and get sets of images that are both diverse and high quality—without retraining the model.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and open directions that arise from the paper’s methods, analyses, and evaluations. Each item highlights a concrete gap that future work could address.
- Theoretical understanding of noise optimization
- Lack of convergence analysis, stability guarantees, or characterization of the optimization landscape when backpropagating through a frozen sampler to adjust initial noise.
- No formal link between diversity metrics used for optimization (e.g., DINO, DPP, Vendi) and the true coverage of the conditional data distribution p(x|c); unclear whether increased feature-space diversity corresponds to mode coverage rather than feature hacking.
- Radius-only regularization approximates the Gaussian prior marginally; absence of theory or diagnostics on whether angular deviations produce off-manifold latents that could degrade plausibility or provoke reward hacking.
- Diversity metrics and objective design
- Unclear robustness of DINO/DreamSim/LPIPS/DPP/Vendi as diversity signals across prompts, domains, and styles; limited human evaluation focused mainly on comparing metrics to DINO rather than baselining absolute user satisfaction or semantic coverage.
- Limited analysis of how set-level objectives (DPP/Vendi) scale numerically and computationally (e.g., conditioning, determinant gradients, eigen decompositions) for larger set sizes; stability and efficiency trade-offs are not characterized.
- Open question whether combining multiple complementary diversity signals (e.g., structure, color, layout, texture) yields better semantic diversity without sacrificing quality; no principled multi-objective weighting or adaptive curriculum is presented.
- Frequency analysis and pink-noise initialization
- Frequency analysis is coarse (three bins) and model-agnostic; no study of orientation-specific, channel-wise, or scale-dependent effects; lack of causal evidence that low-frequency emphasis is the driver rather than a correlated artifact.
- Pink-noise exponent α is chosen heuristically; no adaptive, prompt- or model-specific selection policy; quality–diversity trade-offs for α>0.2 are observed but not systematically mapped or controlled.
- No investigation of whether frequency-shaped noise should depend on spatial resolution, latent-space topology (e.g., VAE vs native pixel models), or sampler type (ODE vs SDE, deterministic vs stochastic steps).
- Generality across models, samplers, and tasks
- Experiments emphasize step-distilled and fast samplers; scalability to long-step samplers, stochastic SDE solvers, or non-distilled pipelines (e.g., SDXL base) is not empirically assessed.
- Application beyond text-to-image (e.g., video, 3D, multi-view, audio) remains untested; unclear whether observed low-frequency effects and optimization behavior transfer to temporal or 3D consistency constraints.
- Interaction with common inference-time controls (e.g., classifier-free guidance scales, negative prompts, compositional guidance) is not explored; open question whether combined steering yields additive or antagonistic effects.
- Quality, alignment, and safety trade-offs
- Prompt adherence is maintained via a weak CLIPScore reward, yet systematic compositional faithfulness and attribute binding (e.g., GenEval’s fine-grained relations) are not deeply evaluated; risk of semantic drift during diversity maximization is underexplored.
- HPSv2 and CLIPScore provide limited coverage of image quality and alignment; no thorough user studies quantifying perceived fidelity/realism as diversity increases, nor comparisons to aesthetic/scoring rewards known to track human preference.
- Safety implications are not discussed: optimizing initial noise to maximize diversity may inadvertently increase unsafe or undesirable content incidence or bypass internal safety heuristics/rejectors.
- Compute, efficiency, and fair comparison
- Compute budget parity with baselines is not rigorously established across models and settings (e.g., FLOPs or wall-clock equality vs group inference with 64/128 candidates); iteration counts vs sampler calls not normalized for fair cost–benefit comparisons.
- Per-image latency, memory footprint, and throughput under different batch sizes and set sizes are not reported; practical deployment constraints (e.g., mobile/edge) remain unclear.
- Sequential generation for large sets is qualitatively shown but not quantitatively benchmarked; computational overhead of maintaining and updating set-level diversity objectives against a growing history is not analyzed.
- Robustness and reproducibility
- Sensitivity to hyperparameters (learning rate, step count, clipping, λ weights, thresholds τs and τD) is not systematically ablated; lack of robust defaults or auto-tuning strategies.
- Effect of sampler stochasticity on gradient estimates and reproducibility is not discussed; unclear whether gradients are biased under stochastic solvers or require reparameterization tricks.
- No analysis of seed sensitivity or variance across runs; reproducibility details (code, exact configs for each model, seed control) are not specified.
- Objective hacking and distribution shift risks
- Potential for feature-space diversity objectives (e.g., DINO) to be gamed by subtle artifacts or textures that inflate metric distances without meaningful semantic diversity is acknowledged but not diagnosed; no safeguards (e.g., adversarial/consistency checks).
- Lack of explicit controls to ensure that diversity arises from valid variations consistent with the prompt (e.g., object counts, layout constraints) rather than incidental background or color changes.
- Coverage and evaluation scope
- Benchmarks are limited to GenEval and a subset of T2I-CompBench (50 prompts per category); missing assessments on complex long prompts, typography/OCR, rare concepts, styles (e.g., photorealism vs illustration), and multi-object compositionality beyond aggregate CLIPScore/HPSv2.
- Limited human preference study scope (primarily comparing diversity objectives) and small sample sizes; absence of large-scale user studies to validate perceived diversity, semantic coverage, and quality across prompt types.
- Regularization and prior matching
- Regularization matches only the χ-distributed radius; no exploration of richer priors that constrain direction/structure of latents (e.g., spectral, spatial, or learned priors) to prevent off-manifold drift while preserving diversity gains.
- Open question whether learning a noise prior or a prompt-conditional noise initializer (e.g., via meta-learning) outperforms hand-crafted frequency shaping.
- Scalability in set size and complexity
- Pairwise objectives scale as O(B2); cost and stability for larger B are not analyzed; no use of submodular approximations or streaming estimators to maintain diversity with bounded compute.
- Diminishing returns with increasing set size are not characterized; no guidance on optimal set size vs compute for different prompts/models.
- Interactions with personalization and identity preservation
- Not evaluated on personalization scenarios (e.g., DreamBooth, HyperDreamBooth); unclear whether diversity optimization disrupts identity/style consistency or can be constrained to keep identities intact.
- Resolution and architecture dependence
- Impact of spatial resolution (e.g., 512 vs 1024) and backbone architecture (UNet vs DiT-like transformers) on optimization efficacy and frequency dynamics remains untested.
- Implementation-specific ambiguities
- Frequency-shaped noise for latent spaces: not specified whether FFT is applied per-channel, how padding and boundary conditions are handled, or how spectral operations change with latent spatial size/resolution.
- For DPP/Vendi optimization, numerical tricks (e.g., log-determinant stabilization, kernel normalization) and gradient computation details are omitted, which may affect reproducibility and scaling.
Glossary
- 1/f power spectrum: A frequency distribution where power decreases inversely with frequency, common in natural images. "However, natural images have a $1/f$ power spectrum: lower frequencies have more power than higher frequencies ~\cite{field1987relations, simoncelli2001natural, torralba2003statistics}."
- Best-of-n sampling: A strategy that generates n candidates and selects the best according to a metric. "However, the most popular approach is to utilize best-of-n sampling approaches~\cite{dalle, vqvae2,imageselect,pickscore,ma2025inference} or direct noise optimization approaches."
- Chi distribution (χd law): The distribution of the radius of a vector drawn from a multivariate standard normal; governs the norm of Gaussian noise in d dimensions. "the radius follows a $\smash{\rchi^d}$ law under ."
- CLIPScore: An image-text alignment metric based on CLIP embeddings. "To assess image quality and prompt alignment, we report CLIPScore~\cite{hessel2021clipscore,clip} and HPSv2~\cite{hps,hpsv2}, and provide standard deviations across test samples."
- Classifier-Free Guidance (CFG): A conditioning technique that steers diffusion sampling without an explicit classifier by mixing conditional and unconditional predictions. "Drawing from the success of classifier-free guidance (CFG) mechanisms~\cite{cfg,chung2024cfg++} in steering diffusion models towards desired objectives,"
- DINOv2: A self-supervised vision transformer used to compute image embeddings for similarity or diversity. "we can flexibly select different optimization objectives that facilitate diversity in generated outputs (e.g.\ DINOv2~\cite{dinov2}, LPIPS~\cite{lpips}, DreamSim~\cite{fu2023dreamsim})."
- Determinantal Point Processes (DPP): Probabilistic models that favor diverse subsets by modeling repulsion via determinants of kernel matrices. "Further, we also investigate the usage of set-level diversity objectives such as Determinantal Point Processes (DPP)~\cite{elfeki2019gdpp} and Vendi Score~\cite{friedman2022vendi} and find that they are more suitable to provide increased variation backed by user studies."
- DreamSim: A perceptual similarity metric based on learned representations for images. "Output diversity is measured with averaged pairwise DINO, DreamSim, and LPIPS scores."
- Flow matching: A generative modeling approach that learns a vector field for ODE-based sampling from noise to data. "Score-based diffusion~\citep{song2021scorebased, kingma2023variational, karras2022elucidating,ho2020denoising,ddim} and flow matching~\citep{rf1, rf2, rf3} models share the observation that the process $\bx_t$ can be sampled dynamically using a stochastic or ordinary differential equation (SDE or ODE)."
- Group inference: A sampling strategy that generates a large pool and selects a diverse subset using group-level objectives. "image sets generated from -sampled noise initializations, and the recent group inference method~\cite{gi}."
- Hinge-penalized objective: A loss that uses hinge penalties to enforce thresholds on quality and diversity. "We minimize a hinge-penalized diversity and quality objective"
- HPSv2: A human preference score metric for image quality evaluation. "Our optimization pipeline does not hurt the overall image quality (measured by HPSv2) across different diversity objectives"
- LPIPS: Learned Perceptual Image Patch Similarity, measuring perceptual distance between images. "Output diversity is measured with averaged pairwise DINO, DreamSim, and LPIPS scores."
- Mode collapse: A failure mode of generative models where outputs lack variety and concentrate on few modes. "Contemporary text-to-image models exhibit a surprising degree of mode collapse, as can be seen when sampling several images given the same text prompt."
- Ordinary differential equation (ODE): A deterministic differential equation used to simulate diffusion/flow trajectories for sampling. "using a stochastic or ordinary differential equation (SDE or ODE)."
- Patch embedding: Feature vectors computed from localized image patches for measuring diversity or similarity. "with a patch embedding and a distance metric (e.g.\ cosine distance)."
- Particle guidance: A guidance mechanism that steers multiple particles (samples) to achieve target properties like diversity. "including the usage of particle guidance~\cite{particle}"
- Pink noise: Noise with power spectral density proportional to 1/fα, emphasizing low frequencies. "In particular, we consider pink noise initialization where we apply spectral filtering in the frequency domain."
- Power spectral density: Distribution of signal power across frequencies; constant for white noise. "Diffusion models commonly initialize the denoising process with white Gaussian noise where the power spectral density is constant across all frequencies."
- Radial frequency: The magnitude of the frequency vector in the 2D spectrum, used for filtering. "For each frequency component at position , we compute the radial frequency ."
- Score-based diffusion: Generative modeling that learns the score (gradient of log-density) of noisy data to guide denoising. "Score-based diffusion~\citep{song2021scorebased, kingma2023variational, karras2022elucidating,ho2020denoising,ddim}"
- Set-level diversity objectives: Metrics that evaluate diversity over a set collectively rather than pairwise, preventing trivial improvements by a single outlier. "Further, we also investigate the usage of set-level diversity objectives such as Determinantal Point Processes (DPP)~\cite{elfeki2019gdpp} and Vendi Score~\cite{friedman2022vendi}"
- Stochastic differential equation (SDE): A differential equation with noise terms used to sample diffusion processes. "using a stochastic or ordinary differential equation (SDE or ODE)."
- Step-distilled samplers: Generators whose multi-step processes are distilled into fewer steps for faster inference. "Our experiments cover popular step-distilled samplers including SDXL-Turbo~\cite{sdxlturbo}, SANA-Sprint~\cite{sanasprint}, PixArt--DMD~\cite{pixartalpha}, and Flux.1 [schnell]~\cite{flux}."
- Vendi Score: A set-level diversity metric derived from kernel eigenvalues, rewarding spread across feature space. "Further, we also investigate the usage of set-level diversity objectives such as Determinantal Point Processes (DPP)~\cite{elfeki2019gdpp} and Vendi Score~\cite{friedman2022vendi}"
- White Gaussian noise: Zero-mean Gaussian noise with constant power across frequencies. "Diffusion models commonly initialize the denoising process with white Gaussian noise where the power spectral density is constant across all frequencies."
- Latents (noise latents): The internal noise vectors (latent variables) that seed diffusion generation. "We compute the spectrum via a Fourier Transform on the raw noise latents and track how it evolves over the course of optimization."
Practical Applications
Below are practical applications derived from the paper’s findings on inference-time noise optimization to recover diversity in trained diffusion models, along with the use of set-level diversity objectives and pink noise initialization. Each point notes sector relevance, potential tools/products/workflows, and feasibility dependencies.
Immediate Applications
- Boldly diverse image sets for creative production (media, advertising, design)
- Use set-level noise optimization to generate varied concept boards, mood boards, and art directions from a single prompt without retraining.
- Tools/workflows: a “Diversity Booster” plugin for Stable Diffusion/Flux pipelines (e.g., Diffusers, ComfyUI, AUTOMATIC1111) that implements batch noise optimization with DPP/Vendi objectives and CLIP/HPSv2 quality rewards; pink-noise initialization α≈0.2 as a default option.
- Assumptions/dependencies: access to model weights and gradients (not just a closed API), GPU budget for 6–15 optimization iterations per prompt, integration of DINOv2/CLIP/HPSv2 for reward computation, and regularization to keep latents plausible.
- Ad creative A/B variant generation (marketing, finance)
- Rapidly produce diverse visual variants for A/B tests to improve CTR/conversion while maintaining brand alignment by enforcing CLIPScore/HPSv2 thresholds.
- Tools/workflows: server-side “Diverse Batch Generation” endpoint that returns 4–8 optimized samples; ranking with Vendi/DPP to avoid trivial pairwise diversity inflation.
- Assumptions/dependencies: experiment tracking/analytics pipeline to measure downstream performance; prompt adherence guardrails; compute cost management.
- Catalog and product imagery variety at scale (e-commerce, retail)
- Generate multiple product shots with varied backgrounds, compositions, and lighting while preserving prompt fidelity.
- Tools/workflows: sequential generation mode to scale to large sets without memory overhead; per-image optimization that penalizes similarity to previously generated items.
- Assumptions/dependencies: brand/style constraints encoded as auxiliary quality rewards; QA to curb unrealistic artifacts when diversity weights are high.
- Synthetic data augmentation for vision model training (software, robotics)
- Create diverse training images for object detection/classification via set-level diversity objectives to increase pose, background, and color variation.
- Tools/workflows: pipeline that uses DINOv2 patchwise distances/DPP or Vendi to diversify batches; sequential generation to build large datasets economically.
- Assumptions/dependencies: careful domain-specific reward design to preserve label semantics; validation that synthetic diversity translates to downstream metric gains; possible slight trade-off with prompt alignment.
- Editorial and publishing asset variation (media, education)
- Produce multiple book cover/illustration options by optimizing noise for variety and ranking with human-aligned set metrics (DPP/Vendi).
- Tools/workflows: in-house generator with “diversity knob” and stopping criteria (CLIPScore ≥ threshold and diversity ≥ target).
- Assumptions/dependencies: human-in-the-loop selection; consistent licensing policies for generative content.
- Design system and UI asset exploration (software, UX/UI)
- Generate diverse iconography/hero images with controlled visual spread and quality constraints.
- Tools/workflows: preset objective bundles (e.g., Color histogram + LPIPS + CLIPScore) for design teams; pink noise on by default for broader coverage of low-frequency layouts.
- Assumptions/dependencies: alignment with brand color palettes and accessibility guidelines; integrating preference scores for aesthetics (e.g., HPSv2).
- Prompt-to-layout control hacks via noise frequency (software, robotics sim)
- Leverage low-frequency emphasis to influence global layout/object placement without modifying prompts or model weights.
- Tools/workflows: pink-noise initialization with adjustable α and per-prompt autotuning; small iterations to surpass best-of-n baselines.
- Assumptions/dependencies: prompt adherence may slightly drop with higher α; require quality guardrails and fallback to white noise when necessary.
- Benchmarking and model evaluation for collapse (academia, QA in industry)
- Use set-level metrics (Vendi/DPP) to detect and quantify mode collapse across prompts and models as an acceptance test for deployments.
- Tools/workflows: “Diversity Audit” suite that reports pairwise DINO/DreamSim/LPIPS and set-level Vendi/DPP, plus CLIP/HPSv2, and frequency analyses before/after optimization.
- Assumptions/dependencies: standardized prompts (e.g., GenEval/T2I-CompBench subsets), consistent reward models and thresholds.
- Immediate policy and governance checks for generative deployments (policy, compliance)
- Introduce acceptance criteria that include set-level diversity (e.g., minimum Vendi/DPP scores) and quality thresholds (CLIPScore/HPSv2) to reduce repetitive outputs and ensure consistent prompt adherence.
- Tools/workflows: procurement guidelines that require diversity metrics in vendor testing; runtime caps on inference-time scaling to manage energy/carbon budgets.
- Assumptions/dependencies: organizational alignment on metrics; monitoring of compute overhead and content moderation risks as diversity increases.
Long-Term Applications
- Diversity-as-a-Service APIs and platform features (software, cloud)
- Offer “diversity knobs” in commercial T2I services (akin to CFG) that expose set-level objectives (DPP/Vendi) and sequential generation workflows for large sets.
- Tools/products: cloud API endpoints with adjustable diversity weights, quality thresholds, and noise initialization types; on-demand latency/compute scheduling.
- Assumptions/dependencies: vendor willingness to allow gradient access or provide surrogate optimization hooks; robust autoscaling and cost controls.
- Enterprise creative pipelines with brand-safe diversity (media, retail)
- Integrate noise optimization deeply into asset management systems to generate diverse compliant variants across campaigns, localizations, and channels.
- Tools/workflows: style-conditioned reward models; automated guardrails for brand motifs and legal compliance; continuous learning from human preferences (e.g., preference optimization).
- Assumptions/dependencies: custom reward models aligned with brand guidelines; governance on IP/licensing for large-scale generative use.
- Fairness-aware dataset curation via set-level diversity (policy, academia, healthcare)
- Use diversity optimization to curate synthetic datasets with more representative coverage (e.g., environments, lighting, non-sensitive attributes), improving robustness of downstream models.
- Tools/workflows: domain-specific diversity kernels and constraints; human-in-the-loop audits; provenance tracking and watermarks.
- Assumptions/dependencies: careful ethical design to avoid inappropriate manipulation of sensitive attributes; regulatory compliance in healthcare/biometrics; validation that diversity improves fairness metrics.
- Extension to video, audio, and 3D generation (software, entertainment, robotics)
- Apply low-frequency-aware noise initialization and optimization to temporal/spatial domains for diverse storyboards, animations, and simulation scenes.
- Tools/workflows: frequency-controlled initializations for video diffusion; set-level temporal diversity metrics; integration with layout control methods.
- Assumptions/dependencies: further research on temporal consistency and reward design; higher compute budgets; guardrails to balance diversity with coherence.
- Robotics and control: diverse trajectory generation for sim-to-real robustness (robotics)
- Adapt noise optimization to diffusion policies to produce varied trajectories and environments for training, improving robustness and generalization.
- Tools/workflows: diversity objectives over state/action sequences; combination with latent space RL; sequential generation for curriculum learning.
- Assumptions/dependencies: extensions of the method to control domains; safety testing; performance validation against baselines.
- Adaptive inference-time scaling under resource and environmental constraints (energy, policy)
- Smart schedulers that modulate optimization iterations based on carbon intensity or latency targets, delivering “best effort” diversity.
- Tools/workflows: green scheduling and compute budgets; dynamic stopping criteria and mixed precision; caching and reuse of optimized noise seeds.
- Assumptions/dependencies: telemetry on energy use; model/server instrumentation; user-configurable SLAs for diversity vs. latency.
- Automated α-selection for pink noise and prompt-specific objective tuning (software, academia)
- Autotune the noise frequency profile and the diversity/quality weight ensemble per prompt to maximize perceptual diversity without damaging fidelity.
- Tools/workflows: meta-optimization or small pilot iterations that choose α and objective weights; prompt classifiers that predict good settings.
- Assumptions/dependencies: extra compute and engineering complexity; risk of overfitting to reward models; need for robust defaults.
- Standards for diversity metrics in generative evaluation (policy, standards bodies)
- Establish common set-level diversity metrics (e.g., Vendi/DPP variants) and reporting practices for model releases and regulatory filings.
- Tools/workflows: standardized benchmarks and audit kits; publication of diversity–quality trade-off curves; documentation on inference-time scaling settings.
- Assumptions/dependencies: consensus across stakeholders; updating frameworks as metrics evolve; transparency on reward-model biases.
These applications rely on the paper’s core innovations:
- End-to-end gradient-based noise optimization at inference-time to increase set-level diversity while preserving quality via explicit reward thresholds.
- Adoption of human-aligned set objectives (DPP, Vendi) over pairwise-only metrics to avoid trivial diversity inflation.
- Pink-noise initialization to boost low-frequency content in latents, improving diversity across models and even simple i.i.d. sampling.
- Sequential generation to scale diverse sets without large memory overhead, enabling practical deployment in production pipelines.
Collections
Sign up for free to add this paper to one or more collections.