- The paper introduces NoiseShift, a training-free method that recalibrates noise levels to mitigate resolution-dependent exposure bias in diffusion models.
- It employs a coarse-to-fine grid search to align the denoiser's conditioning with perceptual noise distributions, yielding significant FID and CLIP score improvements.
- Empirical evaluations on models like Stable Diffusion and Flux-Dev demonstrate reduced artifacts and enhanced texture fidelity, enabling efficient low-resolution synthesis.
NoiseShift: Resolution-Aware Noise Recalibration for Low-Resolution Diffusion Image Synthesis
Motivation and Problem Statement
Diffusion models have established state-of-the-art performance in high-fidelity image synthesis, particularly in text-to-image generation. However, these models exhibit a pronounced degradation in image quality when tasked with generating images at resolutions lower than those used during their final training stages. This is a critical limitation for practical deployment scenarios that require computational efficiency, such as mobile inference, rapid prototyping, or large-scale sampling, where low-resolution outputs are desirable.
The core technical insight addressed in this work is that the standard noise schedulers used in diffusion models have non-uniform perceptual effects across resolutions. Specifically, the same absolute noise level σt erases a disproportionately larger fraction of the perceptual signal in low-resolution images compared to high-resolution ones. This leads to a train-test mismatch: the model, when sampled at a lower resolution, is exposed to a noise distribution that is perceptually more destructive than during training, resulting in artifacts and loss of semantic fidelity.
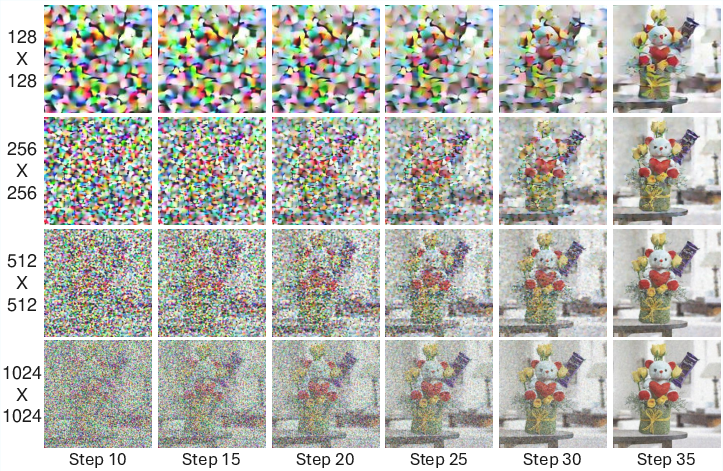
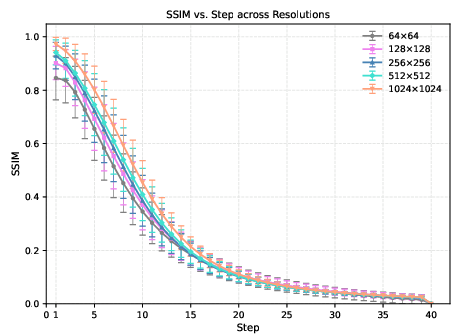
Figure 1: At the same sampling noise level σt, lower-resolution images experience more severe visual and structural corruption than high-resolution counterparts.
Analysis of Resolution-Dependent Exposure Bias
The paper provides a detailed empirical and theoretical analysis of the forward-reverse process misalignment in diffusion models when sampling at resolutions different from those seen during training. While the forward (noise addition) and reverse (denoising) processes are theoretically symmetric, in practice, this symmetry breaks at test time, especially at lower resolutions.

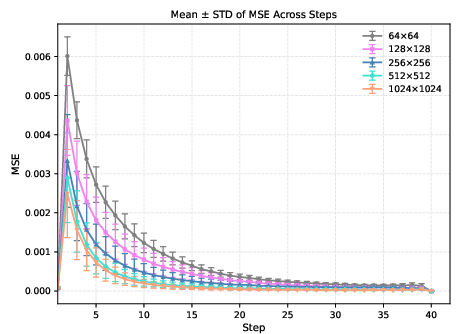
Figure 2: The forward and reverse processes diverge during test-time sampling, with the mean squared error between predicted and actual noisy images increasing as resolution decreases and at early sampling steps.
The authors demonstrate that, for a fixed σt, the structural similarity index (SSIM) between the clean and noisy images degrades more rapidly at lower resolutions. This is attributed to the fact that each pixel in a low-resolution image encodes a larger region of semantic content, making the image more susceptible to perceptual corruption by noise. Consequently, the denoising model is forced to operate on inputs that are statistically and perceptually out-of-distribution relative to its training regime.
The NoiseShift Method
To address this resolution-dependent exposure bias, the paper introduces NoiseShift, a training-free, test-time calibration method that recalibrates the noise level conditioning of the denoiser based on the target resolution. The method does not require any modification to the model architecture or the sampling schedule and is compatible with existing pretrained diffusion models.
The key idea is to replace the nominal timestep t (and its associated noise level σt) with a surrogate timestep t~, or equivalently, a calibrated noise level σ^t, such that the denoiser's conditioning better matches the perceptual noise distribution at the target resolution. This is achieved via a coarse-to-fine grid search that minimizes the one-step denoising error between the model's prediction and the ground-truth forward sample, performed once per resolution and cached for inference.
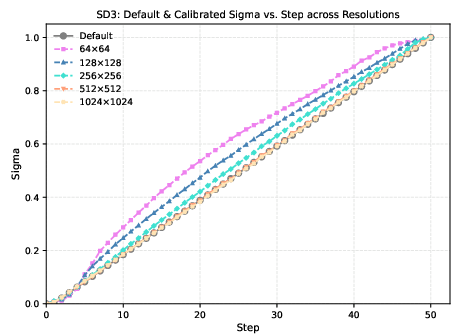
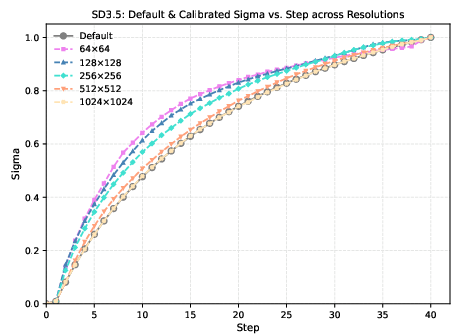
Figure 3: The default sampling noise schedule (gray) and the resolution-specific calibrated conditioning σ^t for SD3 and SD3.5. At lower resolutions, the optimal σ^t curves deviate upward, indicating a need for stronger conditioning.
At inference, the model samples using the original noise schedule but conditions the denoiser on the precomputed, resolution-specific σ^t∗ values. This simple intervention realigns the reverse process with the true noise distribution, mitigating exposure bias and improving image quality at low resolutions.
Empirical Evaluation
NoiseShift is evaluated on multiple state-of-the-art flow-matching diffusion models, including Stable Diffusion 3, Stable Diffusion 3.5, and Flux-Dev, across a range of resolutions and datasets (LAION-COCO, CelebA). The method consistently yields significant improvements in FID and CLIP scores at low and intermediate resolutions, with negligible or no degradation at the default (training) resolution.
- On LAION-COCO, NoiseShift improves SD3.5 by 15.89% and SD3 by 8.56% in FID on average at low resolutions.
- On CelebA, improvements are 10.36% for SD3.5 and 5.19% for SD3 in FID.
- For Flux-Dev, which already incorporates a resolution-aware scheduler, NoiseShift still provides measurable gains, demonstrating its complementarity.
Qualitative results further corroborate the quantitative findings, showing that NoiseShift reduces structural artifacts and enhances texture fidelity in low-resolution generations.


Figure 4: Qualitative comparison of Flux-Dev before and after applying NoiseShift on CelebA (left) and LAION-COCO (right).


Figure 5: Qualitative comparison of SD3.5 before and after applying NoiseShift on CelebA (top) and LAION-COCO (bottom).
Ablation and Robustness
The method's calibration is robust to the number of samples used during the grid search, with the optimal σ^t values converging rapidly even with a small calibration set. This ensures that the computational overhead of calibration is minimal and can be amortized across many generations.
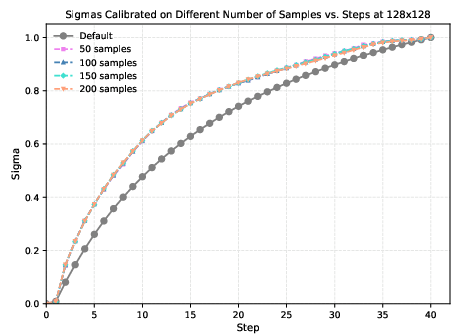
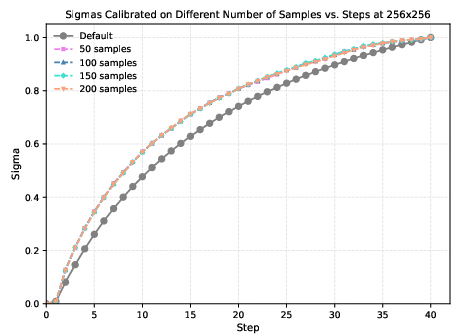
Figure 6: Ablation studies on the number of samples used during calibration and the resulting new sigmas at 128×128 and 256×256.
Implications and Future Directions
NoiseShift exposes a fundamental limitation in the standard design of diffusion models: the assumption of resolution-invariant noise schedules is not valid for perceptual quality. The method demonstrates that simple, training-free test-time interventions can substantially improve cross-resolution generalization without retraining or architectural changes.
Practically, this enables the deployment of high-capacity diffusion models in resource-constrained environments, broadening their applicability. Theoretically, the work suggests that future diffusion model architectures and training regimes should explicitly account for the resolution-dependent perceptual effects of noise, potentially via joint training across resolutions or by learning resolution-conditional noise embeddings.
Further research could explore integrating NoiseShift with learned adapters, dynamic token routing, or resolution-specific fine-tuning, as well as extending the approach to other modalities (e.g., video, audio) where similar scale-dependent noise effects may arise.
Conclusion
NoiseShift provides a principled, efficient, and effective solution to the problem of resolution-dependent exposure bias in diffusion models. By recalibrating the denoising conditioning at test time, it achieves substantial improvements in low-resolution image generation quality, is compatible with existing models, and incurs negligible computational overhead. This work highlights the importance of perceptual alignment in generative modeling and opens new avenues for robust, scalable, and efficient diffusion-based synthesis across diverse deployment scenarios.

