- The paper demonstrates the novel contribution of reverse-engineered reasoning (REER) to generate human-like, step-by-step reasoning in open-ended tasks.
- It proposes a gradient-free, perplexity-guided local search process to iteratively refine reasoning trajectories, validated by strong performance on benchmarks.
- Empirical results highlight enhanced long-form coherence and robust performance in both creative writing and technical domains.
Reverse-Engineered Reasoning for Open-Ended Generation: A Technical Analysis
Introduction and Motivation
The paper "Reverse-Engineered Reasoning for Open-Ended Generation" (2509.06160) addresses a central challenge in LLM research: instilling deep, human-like reasoning in models for open-ended, non-verifiable tasks such as creative writing. While deep reasoning paradigms—such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT)—have demonstrated efficacy in verifiable domains (e.g., mathematics, programming), their extension to open-ended generation is hindered by the absence of objective reward signals and the high cost or limited scalability of existing approaches like reinforcement learning (RL) and instruction distillation.
The authors propose a new paradigm, Reverse-Engineered Reasoning (REER), which synthesizes plausible, step-by-step reasoning trajectories by working "backwards" from known high-quality outputs. This approach is operationalized as a gradient-free, perplexity-guided local search, enabling scalable generation of deep reasoning data without reliance on RL or expensive teacher models.
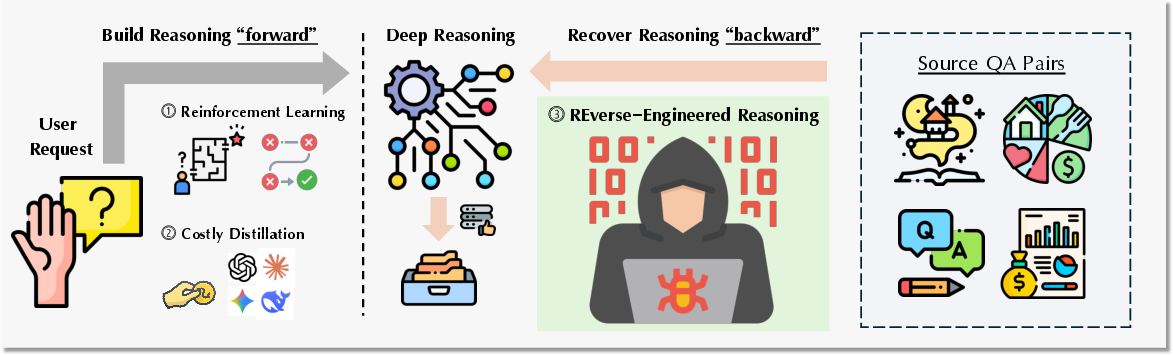
Figure 1: (Left) Existing methods attempt to build deep reasoning "forwards" for a user request through trial-and-error (RL) or costly distillation, which falter in open-ended domains that lack clear, verifiable reward signals. (Right) REER works "backwards", recovering plausible human-like thought process from known-good outputs in open-source QA pairs.
Methodology: REER and Data Synthesis
REER as a Gradient-Free Search
Given a query x and a high-quality reference solution y, the objective is to recover a reasoning trajectory z such that y is maximally probable given x and z. The search for z∗ is formalized as:
z∗=argz∈ZminPPL(y∣x,z)
where PPL denotes the perplexity of y conditioned on x and z. The search is performed via an iterative, segment-wise local refinement: starting from an initial trajectory, each segment is refined using LLM-generated candidates, and the candidate minimizing perplexity is selected. This process is repeated until convergence or a perplexity threshold is met.
Data Pipeline and Context Engineering
The data curation pipeline consists of:
- Sourcing: Query-solution pairs are collected from public writing platforms (e.g., r/WritingPrompts), public domain literature (with queries reverse-engineered from text), and instruction tuning datasets.
- Trajectory Synthesis: For each (x,y) pair, the iterative local search algorithm generates a detailed reasoning trajectory z∗.
- Context Engineering: Prompts are designed to enforce segment-wise edits, inject human-like thinking patterns (e.g., "Hmm...", "Let me think..."), and prevent degenerate or repetitive reasoning.
- Filtering: Heuristics remove trajectories with excessive repetition or incomplete reasoning.
The final dataset, DeepWriting-20K, comprises 20,000 high-quality (x,z∗,y) triples spanning 25 categories, with a strong emphasis on artistic and creative writing.
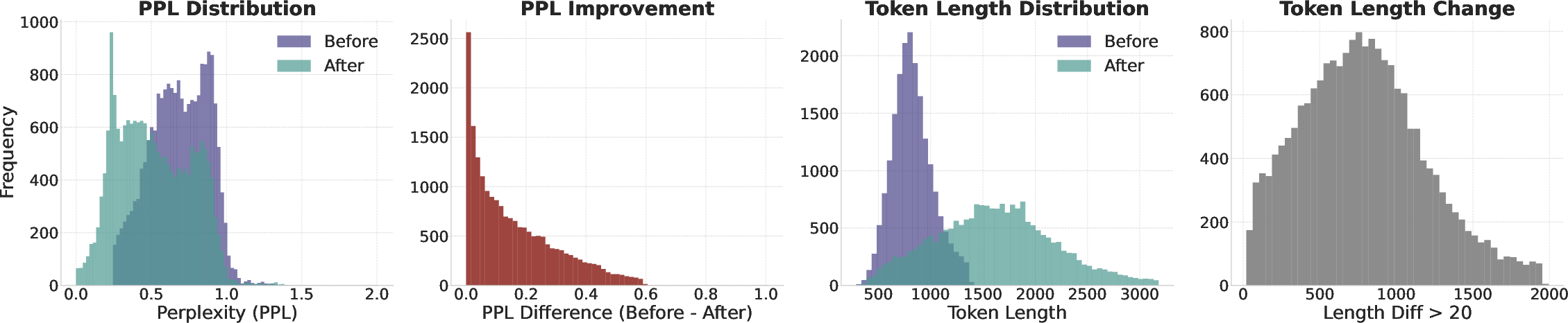
Figure 2: The iterative search process consistently reduces perplexity and increases the token length of the thinking trajectory, reflecting more detailed reasoning steps.
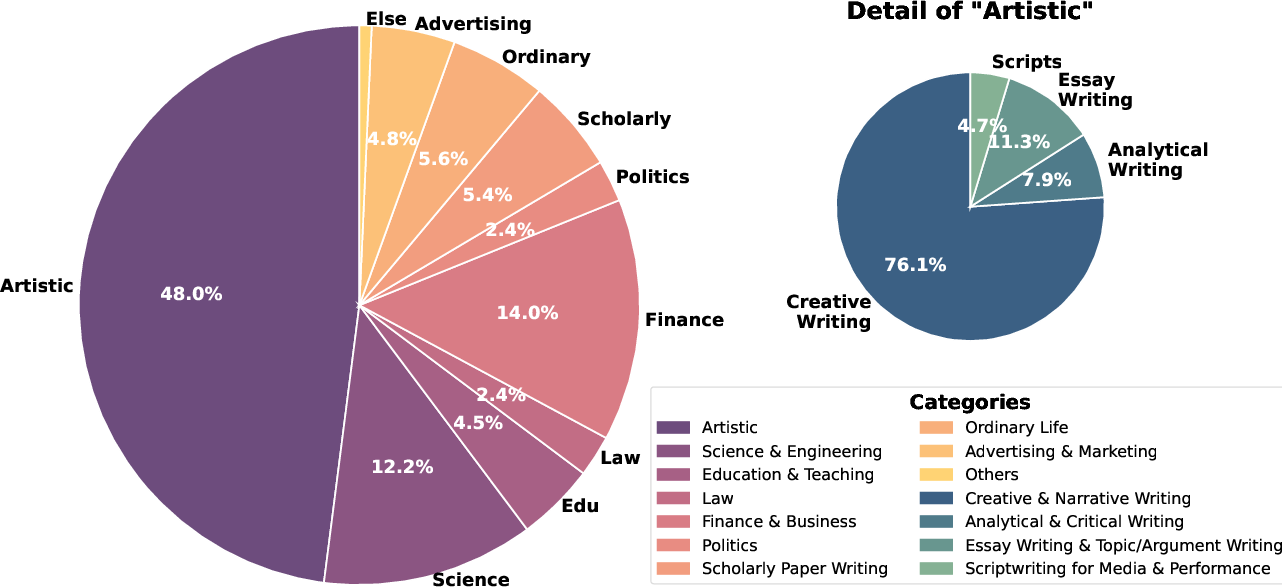
Figure 3: The DeepWriting-20K dataset covers a diverse range of topics, with a large emphasis on Artistic writing and sub-genres such as Creative Writing.
Model Training and Evaluation
Model Architecture and Training
DeepWriter-8B is trained by fine-tuning Qwen3-8B-Base on the DeepWriting-20K dataset, blended with public reasoning datasets (e.g., OpenThoughts) to prevent catastrophic forgetting of general reasoning skills. The training protocol uses a constant learning rate and a global batch size of 96, with Qwen2.5-32B-Instruct as the generator for trajectory synthesis.
Benchmarks
Evaluation is conducted on three benchmarks:
- LongBench-Write: Assesses ultra-long-form text generation and coherence.
- HelloBench: Evaluates real-world, open-ended QA and creative continuation.
- WritingBench: Measures domain-specific proficiency across six professional and creative domains.
Automated LLM-based judges (Claude-3.7, GPT-4o) are used for scoring, following established protocols.
Empirical Results and Analysis
Main Results
DeepWriter-8B demonstrates strong empirical performance:
- Outperforms open-source baselines (e.g., LongWriter-8B) by substantial margins across all benchmarks.
- Competitive with proprietary models: On HelloBench HB-B (creative tasks), DeepWriter-8B matches GPT-4o and Claude 3.5. On LongBench-Write, it surpasses both GPT-4o and Claude 3.5, indicating superior long-range coherence.
- Domain transfer: Training on creative/narrative data improves performance even in technical domains.
Ablation Studies
Ablations confirm the necessity of each component:
- Synthesized deep thinking trajectories are critical; removing them causes the largest performance drop.
- Iterative refinement (vs. single-pass generation) yields significant gains, especially on complex writing tasks.
- Reflection tokens (e.g., "Hmm...", "Wait...") enhance performance in artistic domains, supporting the hypothesis that explicit cognitive markers foster flexible, human-like reasoning.
- Trajectory length: Longer traces are essential for structured professional writing, while shorter traces benefit creative ideation.
- Data diversity: Excluding artistic/literature data degrades performance across all domains, indicating generalization benefits.
Qualitative Analysis
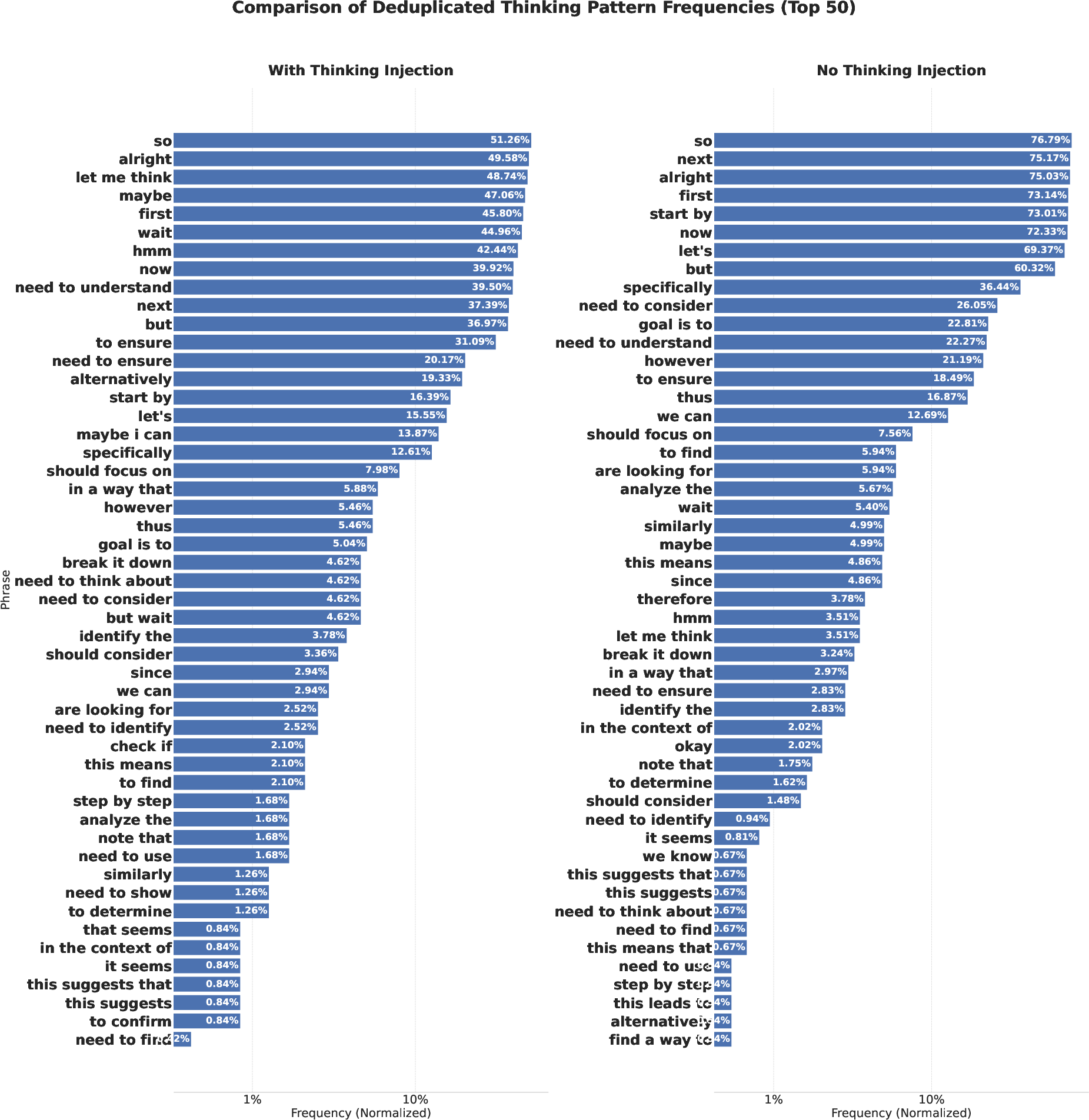
Figure 4: Injection of human-like thinking patterns during data synthesis leads to a more diverse and balanced distribution of reasoning patterns, compared to formulaic outputs without injection.
Qualitative evaluation on five dimensions (problem decomposition, logical consistency, depth of analysis, presentation clarity, factual grounding) shows that DeepWriter-8B exhibits a well-rounded reasoning profile, outperforming open-source baselines and approaching the capabilities of top proprietary models, particularly in depth of analysis and factual grounding.
Behavioral and Distributional Analysis
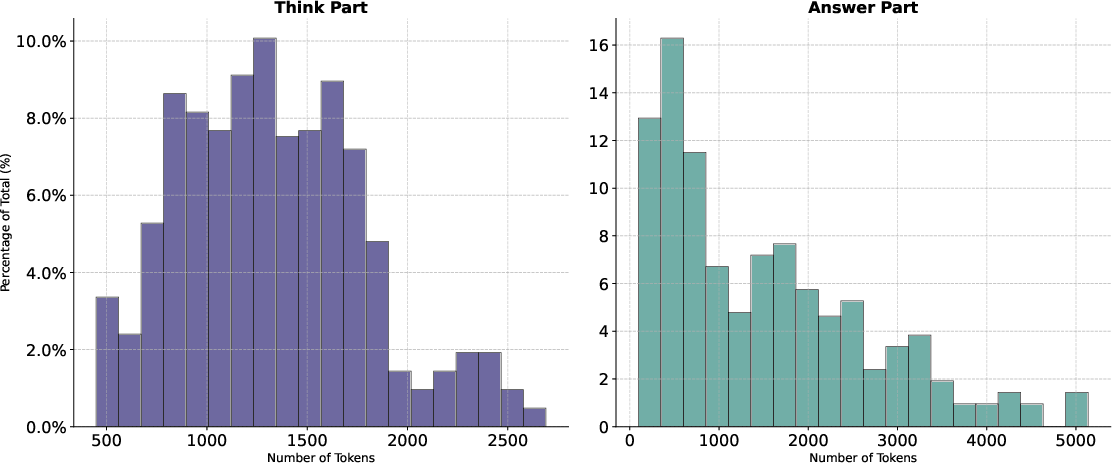
Figure 5: Token length distribution of the thinking and answer parts in DeepWriter-8B, illustrating the model's capacity for extended reasoning.
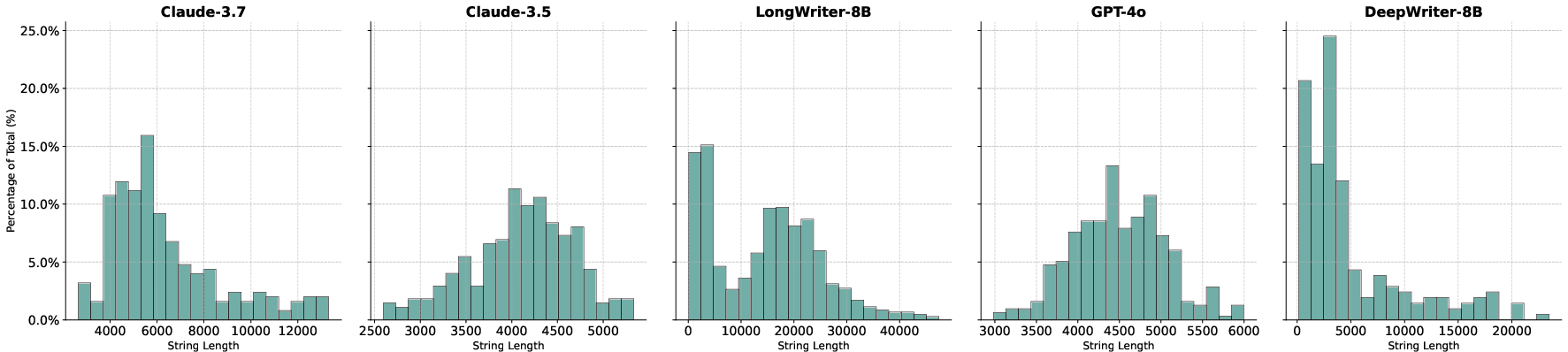
Figure 6: Response string length distribution across different models, highlighting DeepWriter-8B's ability to generate longer, coherent outputs.
The model's outputs are characterized by increased length and complexity in both the reasoning and answer segments, supporting the claim that explicit training on deep reasoning trajectories induces more elaborate and structured generation.
Implications and Future Directions
The REER paradigm provides a scalable, automatable alternative to RL and distillation for instilling deep reasoning in LLMs for open-ended generation. By leveraging perplexity as a proxy for reasoning quality and employing gradient-free local search, the approach sidesteps the need for reward models or expensive teacher queries. The empirical results suggest that explicit modeling of the reasoning process—especially with human-like cognitive markers—yields substantial improvements in both creative and technical domains.
Practically, this enables the development of smaller, open-source models with capabilities previously restricted to large proprietary systems, democratizing access to advanced generative AI. The release of DeepWriting-20K further addresses data scarcity in open-ended reasoning research.
Theoretically, the work raises questions about the limits of backward reasoning synthesis, the optimality of perplexity as a proxy for reasoning quality, and the transferability of reasoning skills across domains. Future research may explore alternative search objectives, integration with RL for hybrid approaches, and extension to multimodal or interactive settings.
Conclusion
"Reverse-Engineered Reasoning for Open-Ended Generation" introduces a novel, scalable paradigm for instilling deep reasoning in LLMs for non-verifiable, open-ended tasks. The REER approach, operationalized as a perplexity-guided, gradient-free local search, enables the synthesis of high-quality reasoning trajectories at scale. Empirical results demonstrate that models trained with this methodology achieve strong performance across diverse benchmarks, rivaling proprietary systems and surpassing open-source baselines. The work provides both a practical toolkit and a conceptual advance for the development of more capable, interpretable, and accessible generative models.

