- The paper demonstrates that sparse activation with a high-sparsity MoE architecture and principled scaling laws enables over 7× active-compute efficiency in trillion-parameter models.
- It details a multi-stage training pipeline, including full-scale FP8 training and heterogeneous pipeline scheduling, that optimizes performance and cost.
- The report shows improved reasoning accuracy through modular design, adaptive RL strategies, and rigorous data composition, setting a new benchmark for general reasoning models.
Every Activation Boosted: Scaling General Reasoner to 1 Trillion Open Language Foundation
Overview
This technical report presents Ling 2.0, an open Mixture-of-Experts (MoE) LLM suite designed for scalable, reasoning-centric foundation modeling—demonstrating competitive reasoning accuracy and computational efficiency from base scale (16B) to trillion-parameter range (1T). The core principle is sparse activation: explicitly maximizing “every activation” to boost general reasoning capacity. Ling 2.0 leverages modular architectural innovations, rigorous scaling laws for hyperparameters and efficiency, advanced reasoning-oriented pretraining data composition, and infrastructure optimizations (notably full-scale FP8 training and heterogeneous pipeline parallelism). The suite empirically achieves >7× active-compute efficiency versus dense models, setting a new Pareto frontier for open general reasoning models.
Model Architecture, Scaling Laws, and Efficiency
High-Sparsity, Fine-Grained Mixture-of-Experts
Ling 2.0 uniformly utilizes a high-sparsity MoE architecture: 256 experts, eight routed plus one shared expert per token, ~3.5% activation ratio. This design demonstrates empirically strong trade-offs between training efficiency, routing balance, and specializable expert capacity.
Scaling Laws for Hyperparameters and Architectural Efficiency
Extensive scaling law experiments underpin all critical architectural and training hyperparameter selection. The authors distinguish MoE scaling from dense paradigms, fitting power-law relationships for optimal LR and batch size (Bopt, ηopt) as functions of compute budget (C), showing that increased sparsity prescribes larger batches and lower LR for stable training at scale.
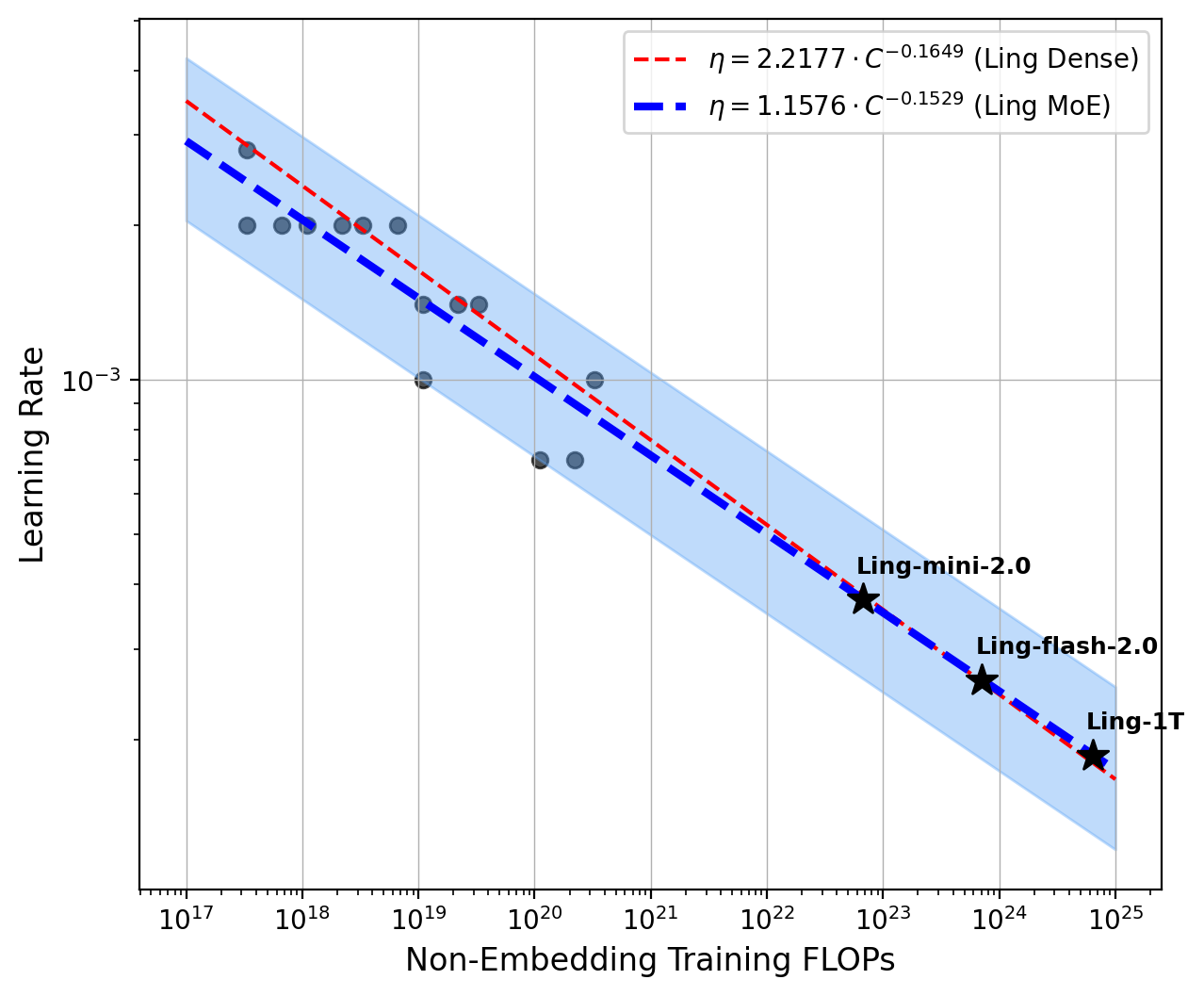
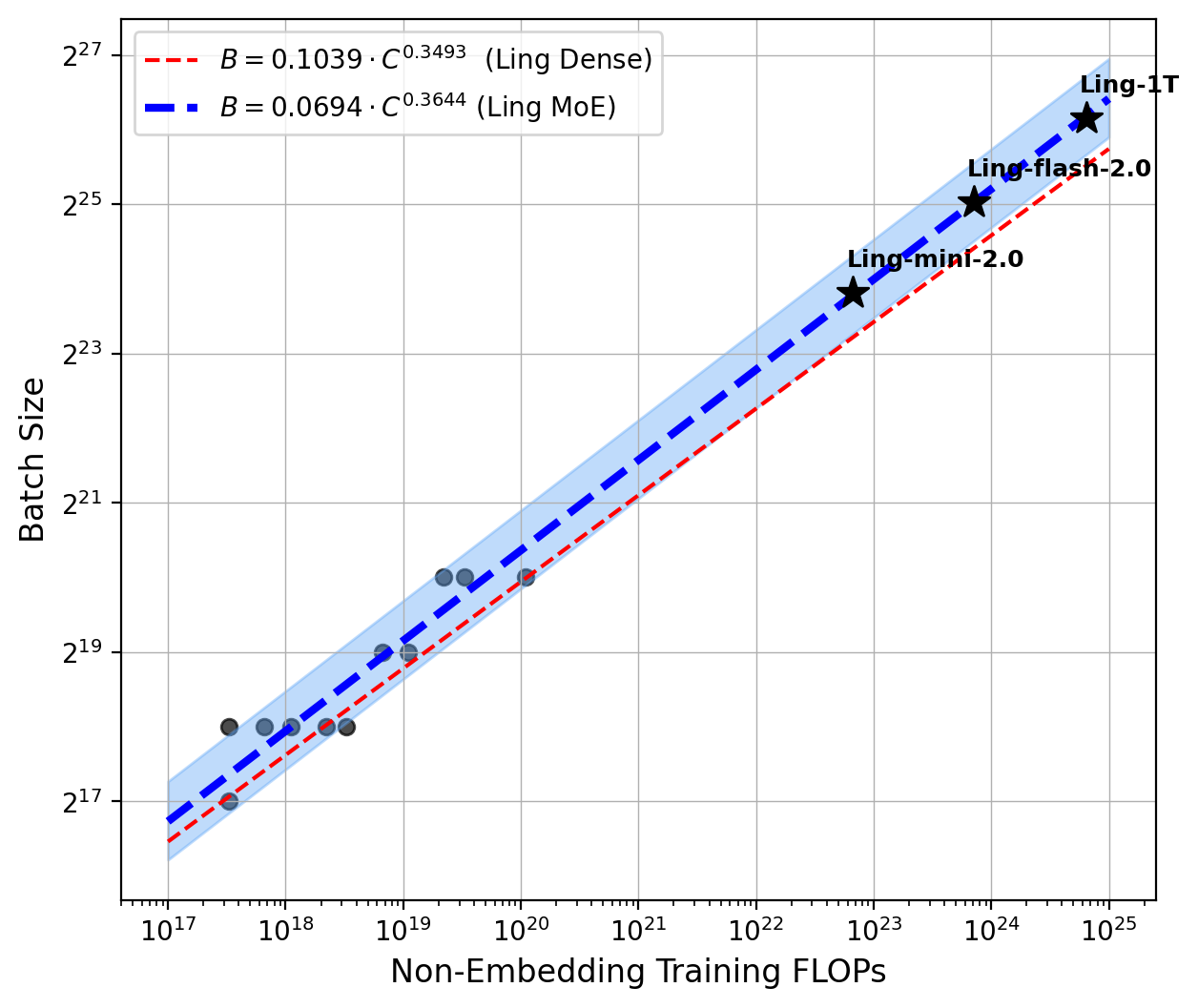
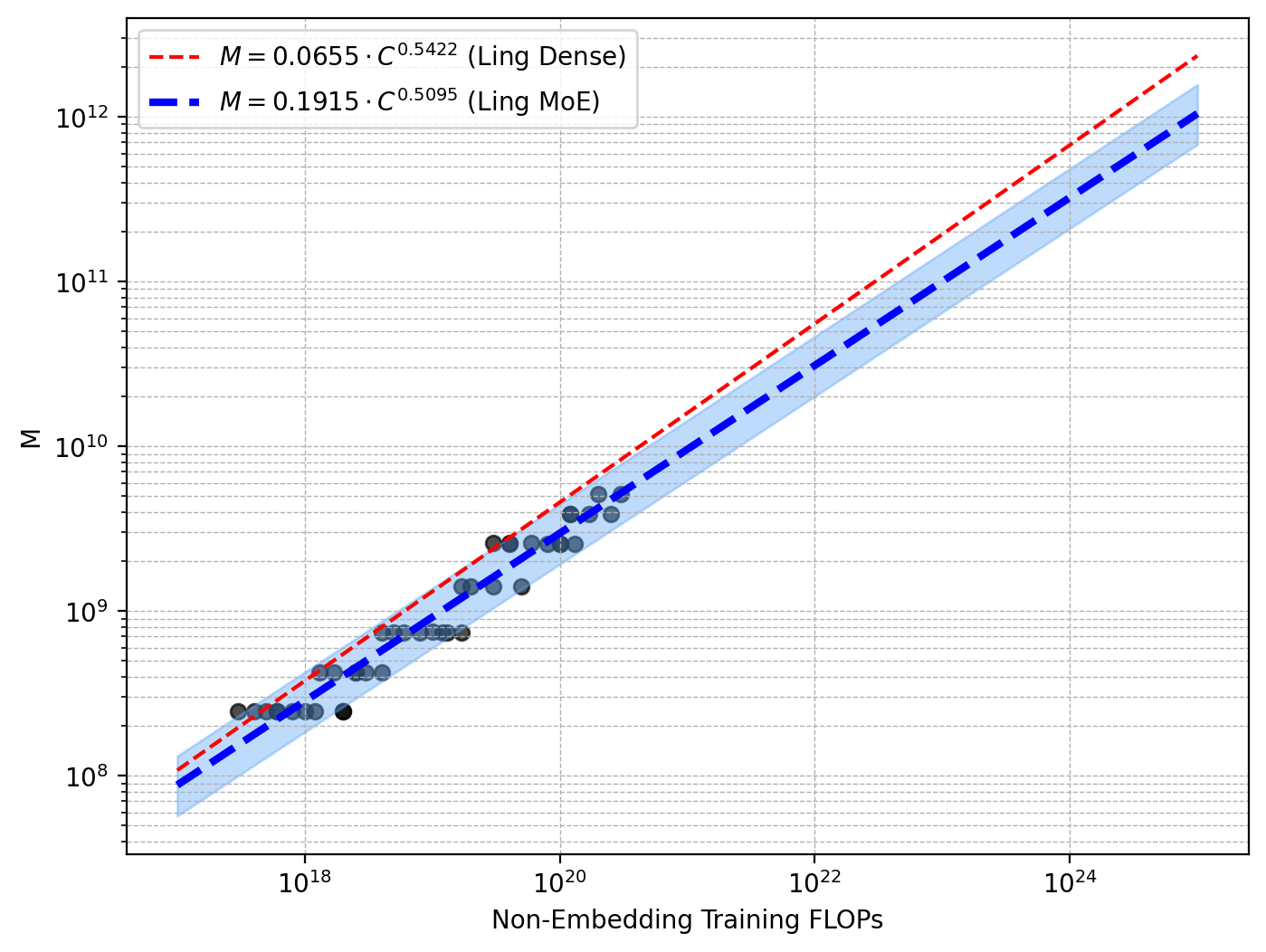
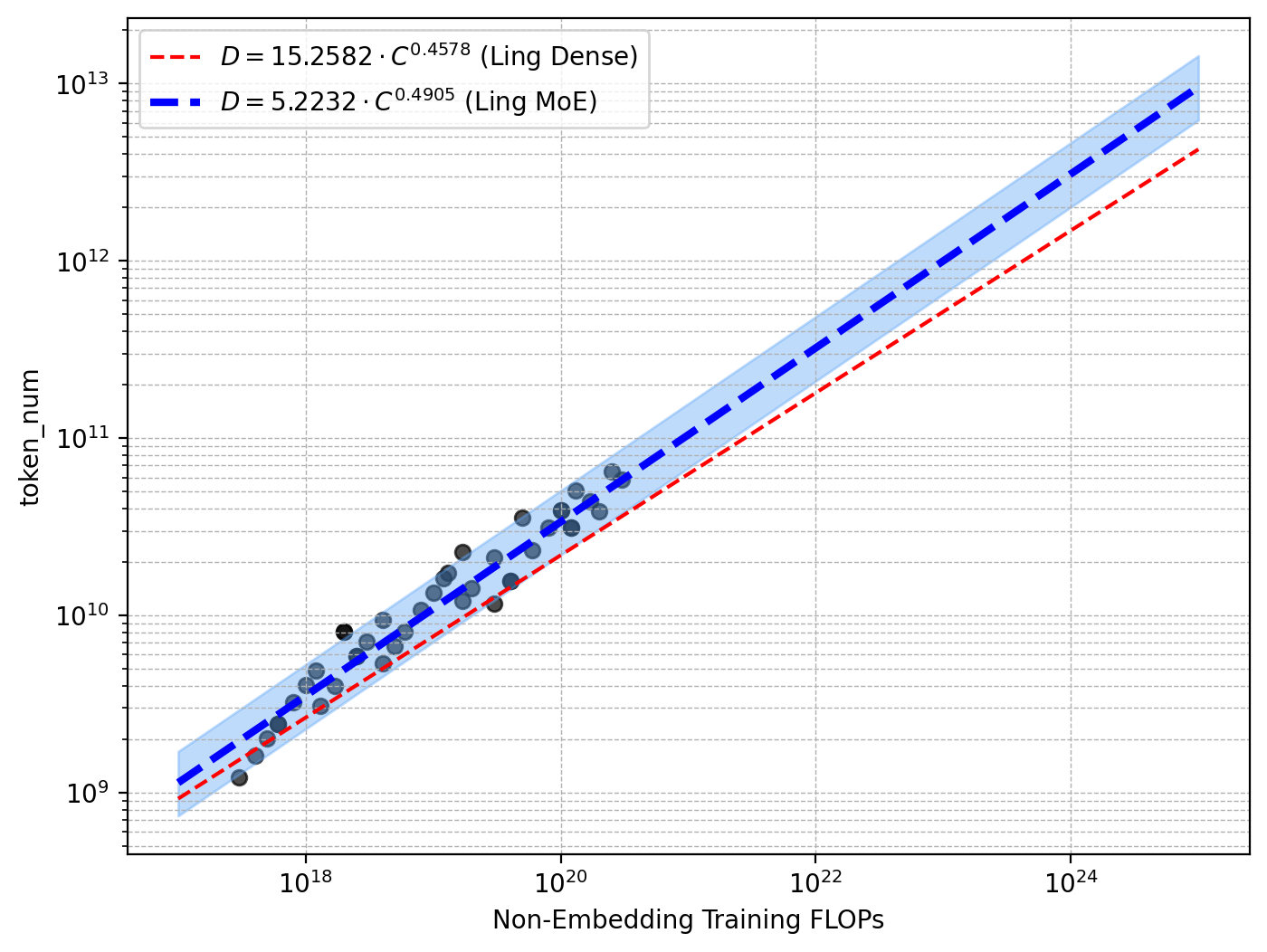
Figure 1: Scaling laws for optimal hyperparameters and model/data allocation, guiding efficient trillion-scale training.
For MoE architectural efficiency, the authors introduce 'efficiency leverage' (EL)—the ratio of compute cost for dense to sparse to reach equivalent performance. The key finding is that EL is governed almost exclusively by the activation ratio, with expert granularity acting as an independent log-polynomial modulator. As compute increases, the EL amplification effect is pronounced.
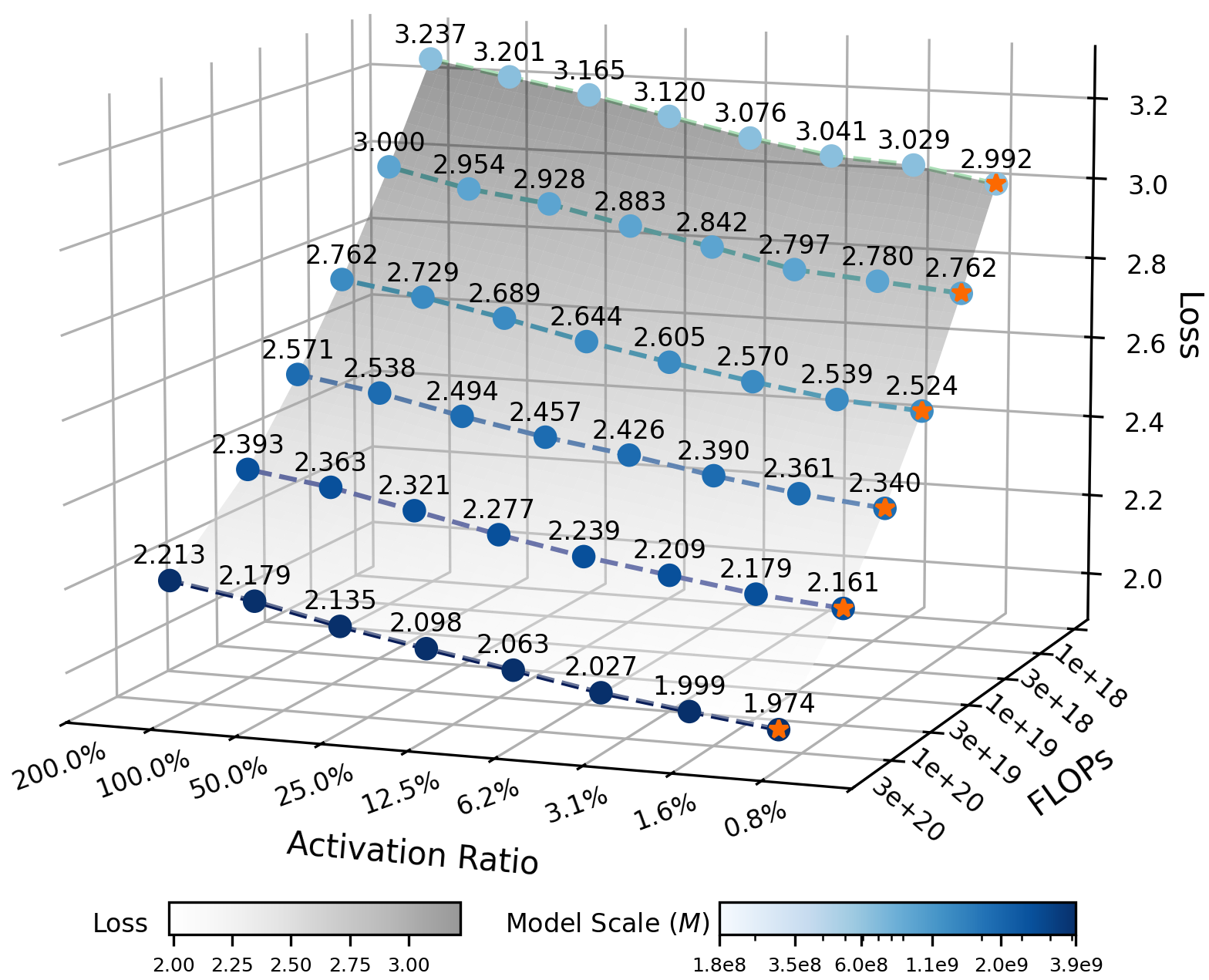
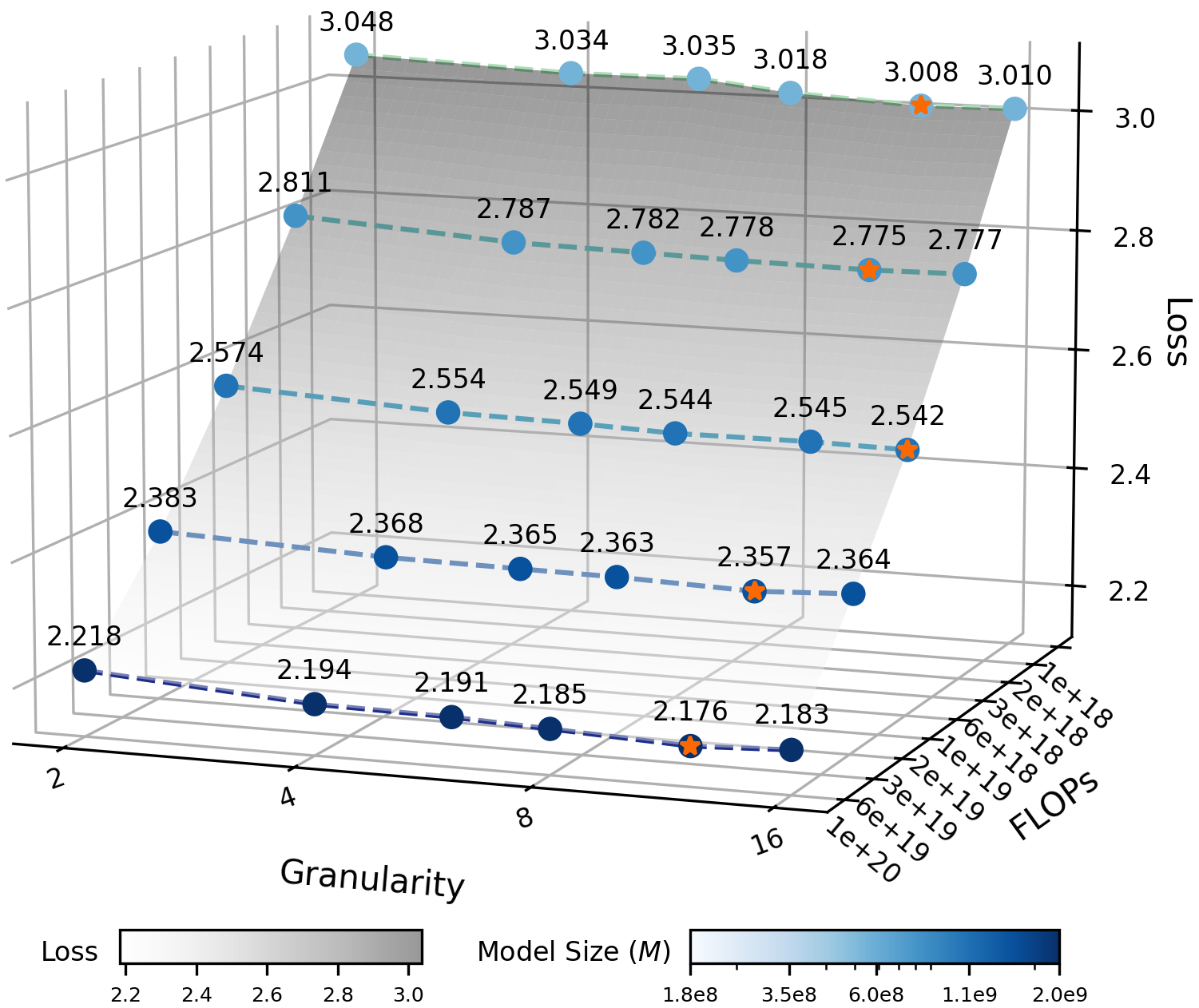
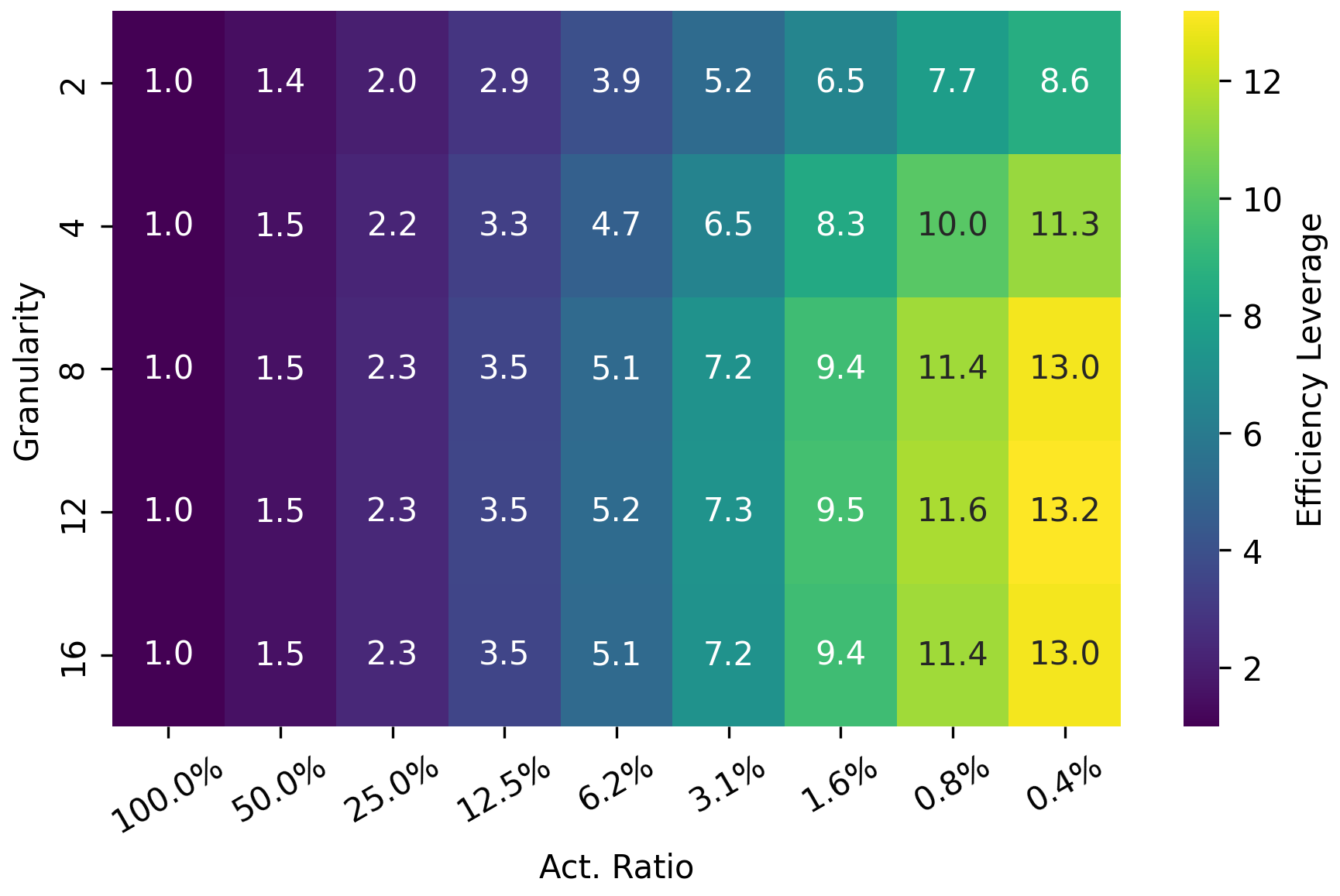
Figure 2: IsoFLOPs curves quantify activation ratio and expert granularity effects, illustrating the EL scaling law.
The Ling 'wind tunnel' system provides predictive, multi-scale experimental extrapolation to trillion-scale using 1% of the training cost, optimizing architecture and scheduling via standardized trials.
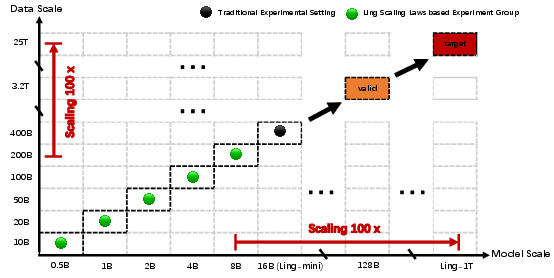
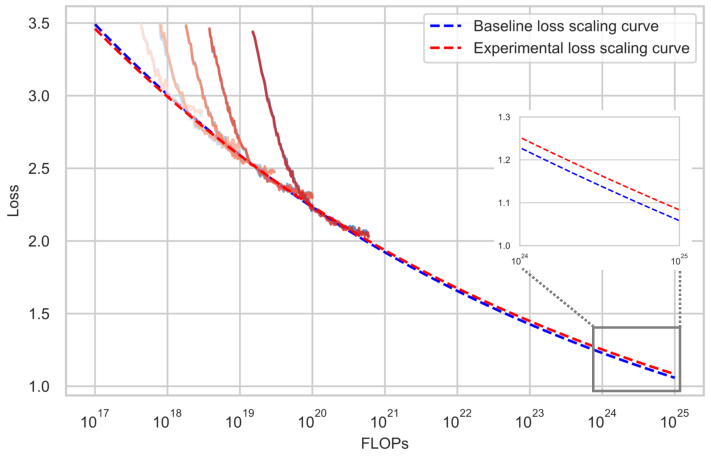
Figure 3: Wind tunnel experiments enable low-cost, stable extrapolation for architectural innovation compared to traditional ablations.
Pre-Training Data and Strategy
Reasoning-Centric Data Composition
The Ling corpora are heavily weighted toward math and code reasoning, built using aggressive quality stratification. Continuous ablation with small code/math models validates data utility, supporting efficient architecture and recipe selection.
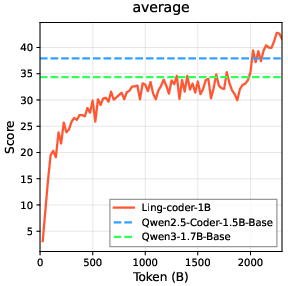
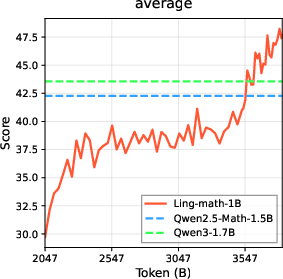
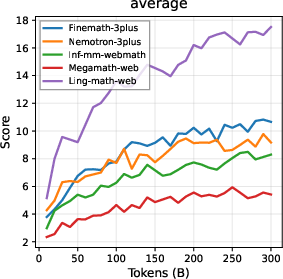
Figure 4: Ling Code Corpus training demonstrates equivalency or better results versus Qwen2.5/3 even at 1B scale, supporting corpus quality.
The math corpus uses multi-stage recall, filtering, and synthetic augmentation. Benchmarks show the Ling-math-1B model surpasses comparable open-source models.
Multi-Stage Training Pipeline
Ling 2.0 employs a multi-stage pipeline: general pretraining (4K context), mid-training with context extension (up to 128K) and reasoning CoT data for pre-activation, and checkpoint merge-based LR scheduling.
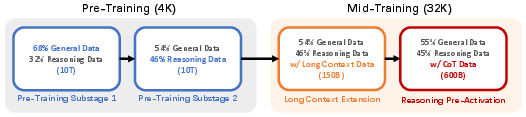
Figure 5: Multi-stage training strategy aligns context expansion and reasoning pre-activation with staged data mixtures.
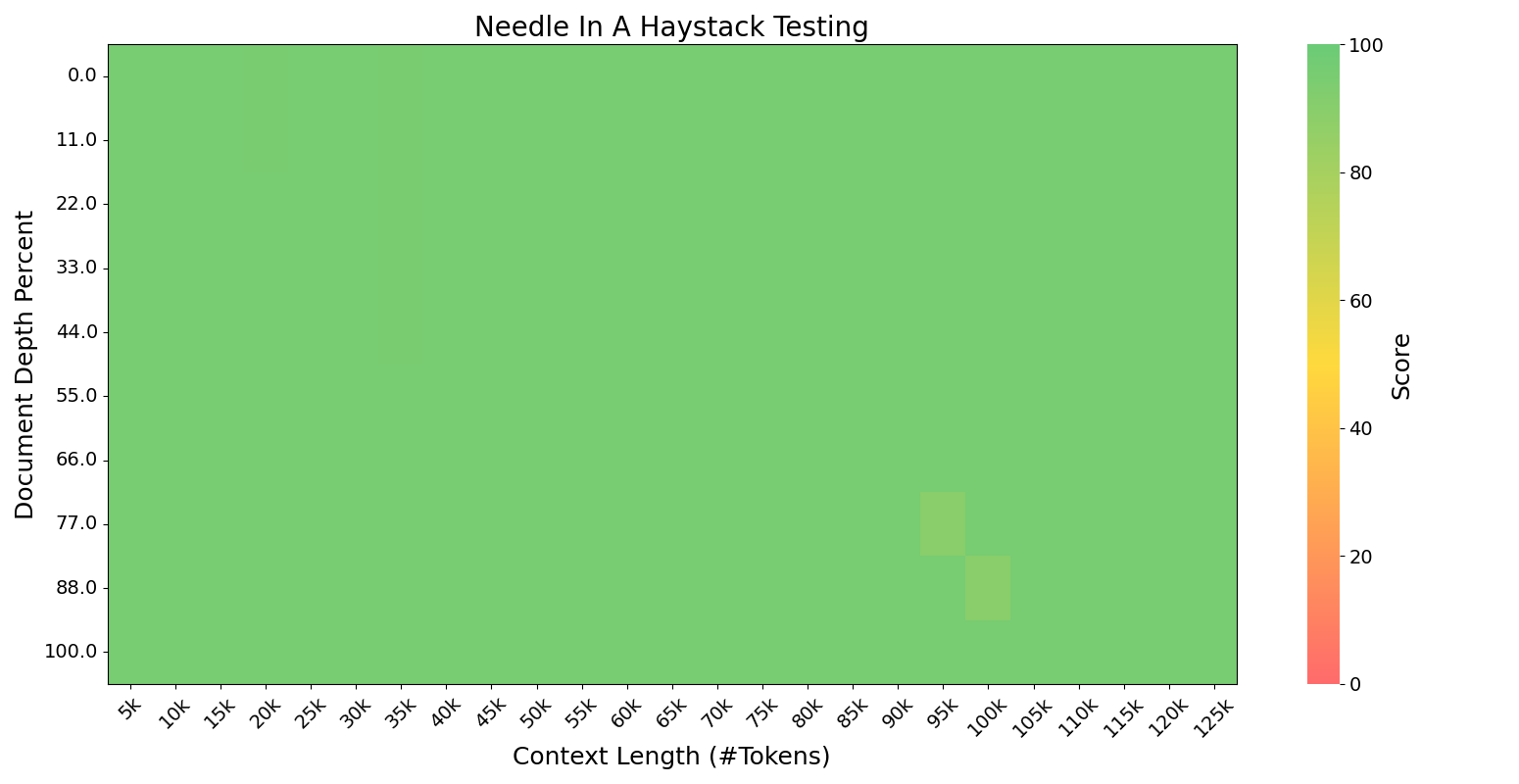
Figure 6: Needle in a Haystack evaluation shows robust long-context reasoning up to 128K following mid-training.
WSM Scheduler
Checkpoints are merged post-hoc for annealing, theoretically and empirically equivalent to LR decay but more flexible and robust.
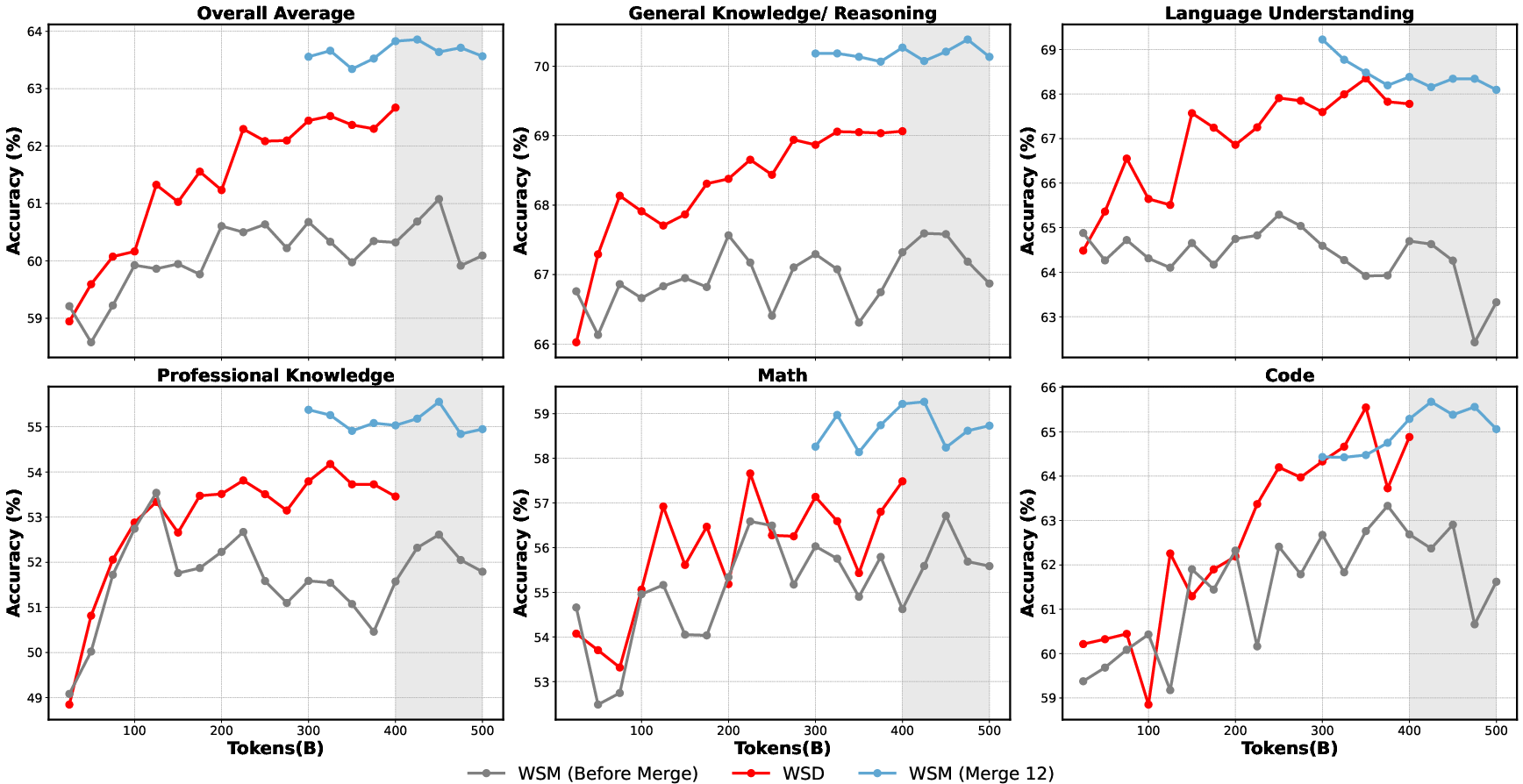
Figure 7: WSM (checkpoint merge) schedulers consistently outperform traditional LR decay in benchmark gains and robustness.
Post-Training: SFT, Evolutionary RL, and Human Alignment
Decoupled Fine-Tuning (DFT) and Evolutionary Chain-of-Thought (Evo-CoT)
DFT establishes instant-response and deep-reasoning modes, increasing the reasoning capacity ceiling, especially when coupled with CoT data. RL (Evo-CoT) then adaptively scales reasoning depth per task, using dynamic length/accuracy/form rewards and domain-specific augmentation.
(Ling Code/Math RL-finets strongest on multi-turn agents and competition-level tasks.)
Linguistic-unit Policy Optimization (LPO)
LPO performs sentence-level importance sampling and clipping, stabilizing policy updates for RL. Compared to alternatives (GRPO/GSPO), LPO yields smoother reward trajectories, faster convergence, and higher test-set generalization.
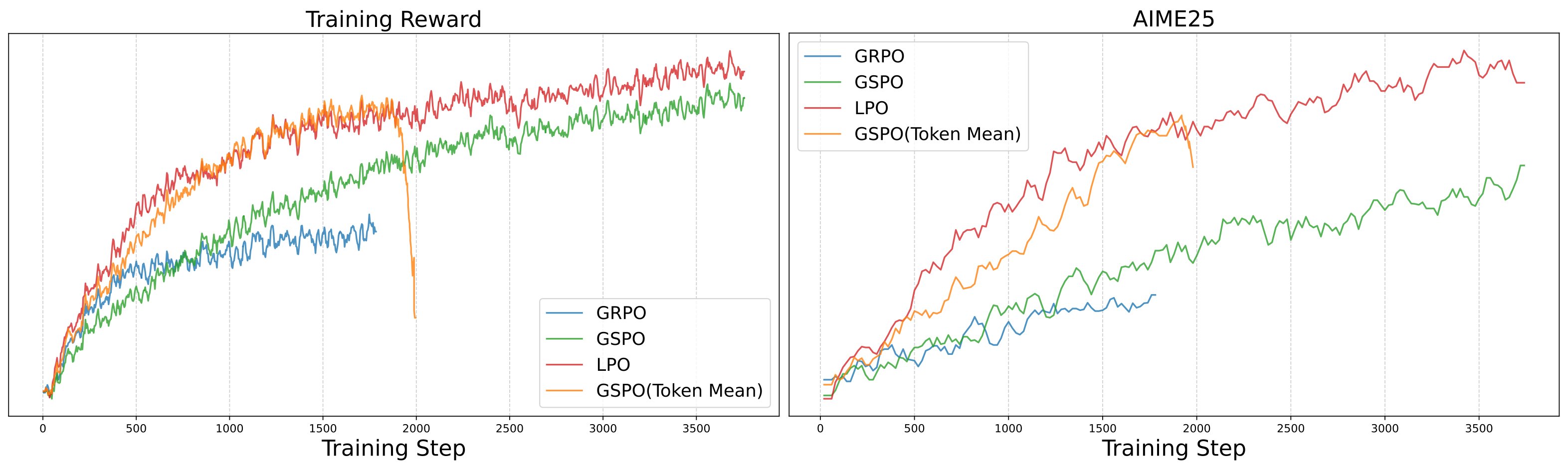
Figure 8: LPO training curves on reasoning RL, highlighting stability and competitive reward growth.
Group Arena Reward (GAR) and RubriX
GAR significantly reduces reward noise in open-ended RLHF through intra-group comparative evaluation, while RubriX provides domain-extended, multi-dimensional rubrics for fine-grained alignment.
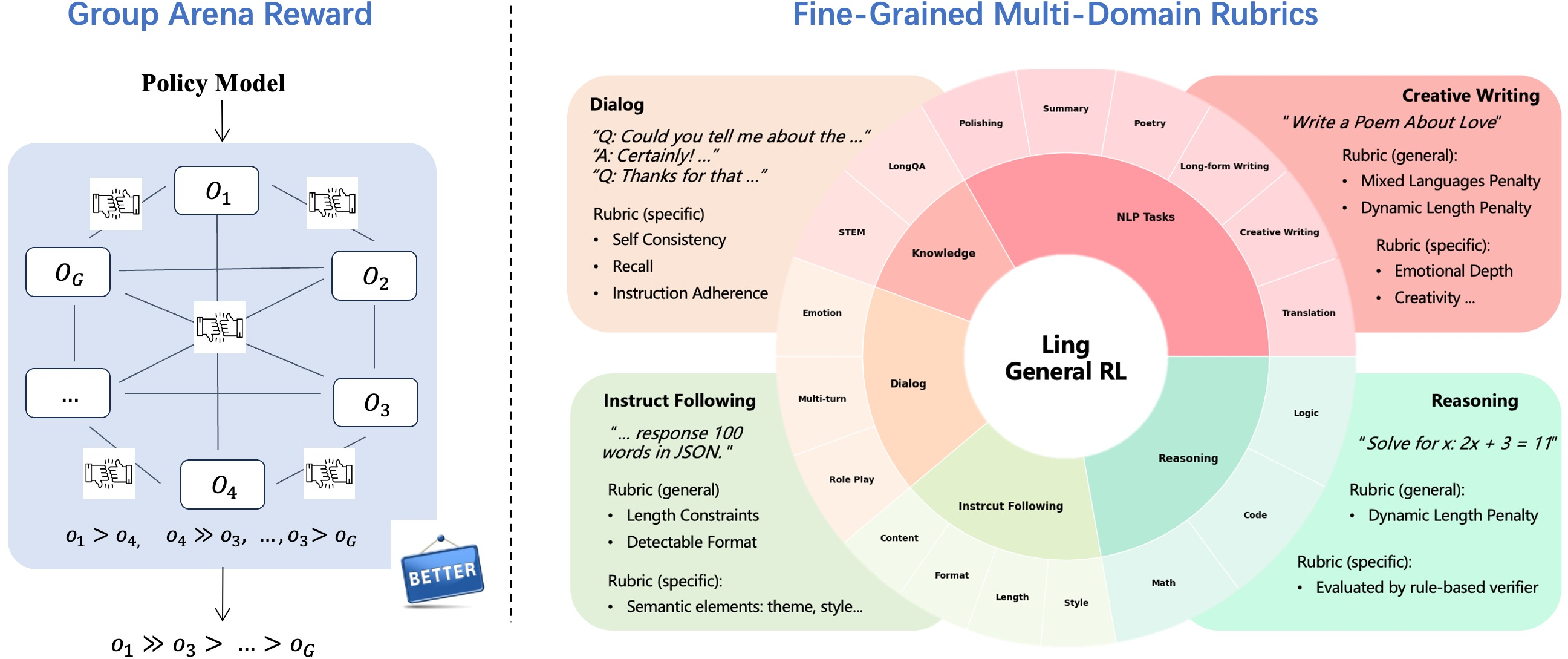
Figure 9: GAR mechanism for intra-group comparative RLHF, improving alignment signal on subjective tasks.
ApexEval
ApexEval selects RL checkpoints by pass@k and LLM-as-judge metrics, optimizing initialization for further reasoning improvement.
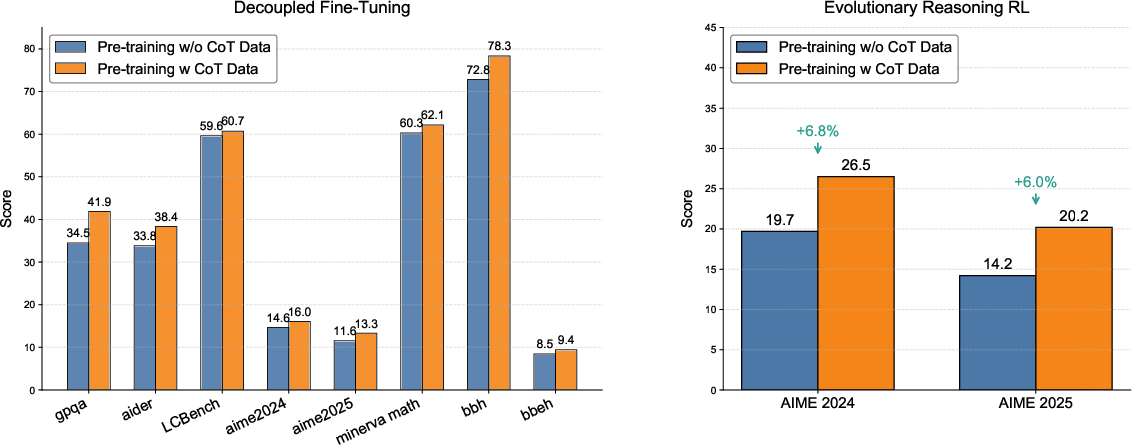
Figure 10: ApexEval checkpoint selection: pretraining with CoT lifts the RL performance ceiling and accelerates trajectory.
Infrastructure and Systems Engineering
Full-Scale FP8 Training
Ling 2.0 presents the largest open FP8-trained model suite, with fine-grained blockwise quantization, QKNorm for outlier mitigation, and online precision safeguarding. The loss gap with BF16 remains ≤ 0.25% over long runs, and CPU/VRAM optimizations further accelerate data throughput.
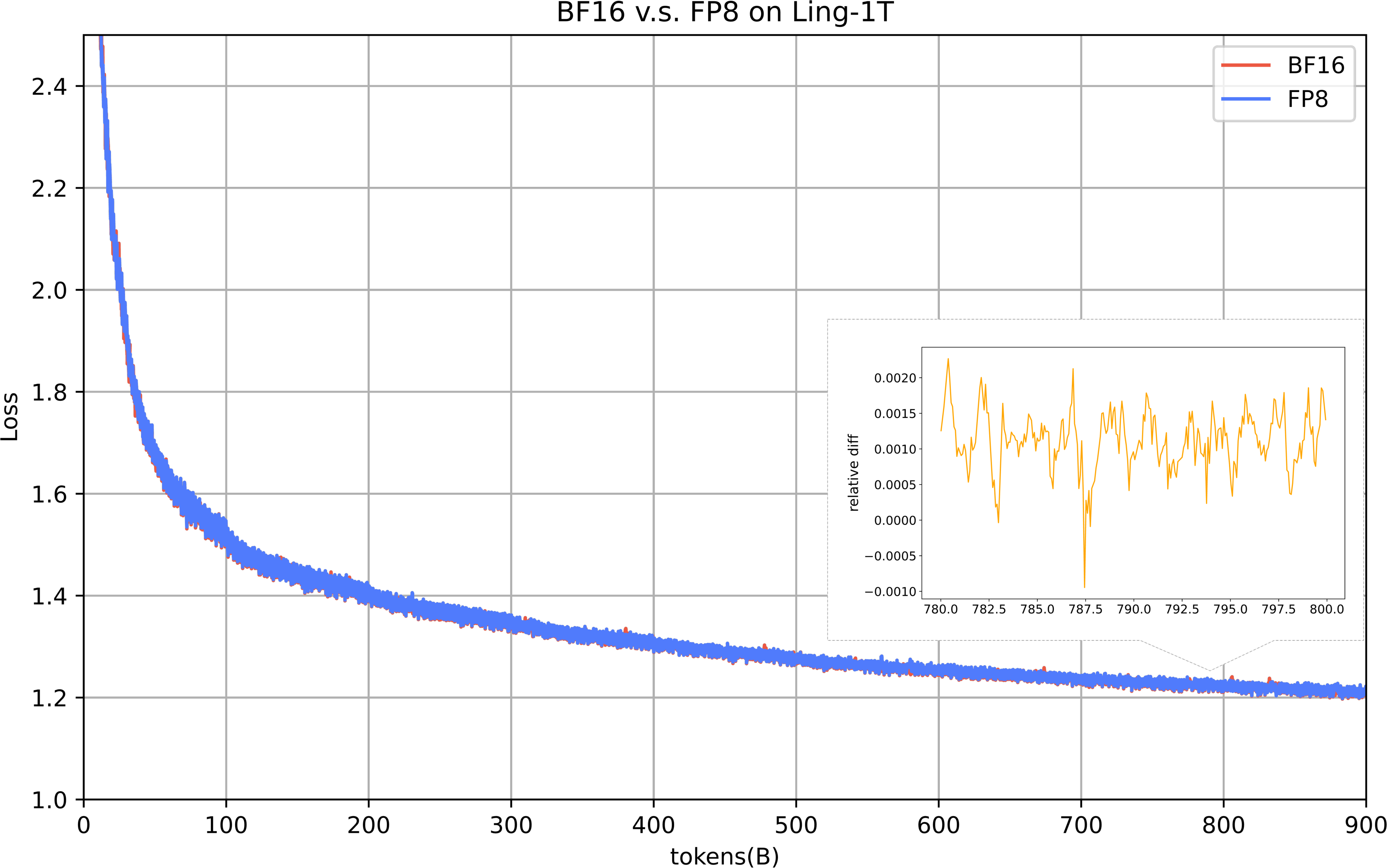
Figure 11: FP8 achieves near-lossless pretraining performance versus BF16 on Ling-1T.
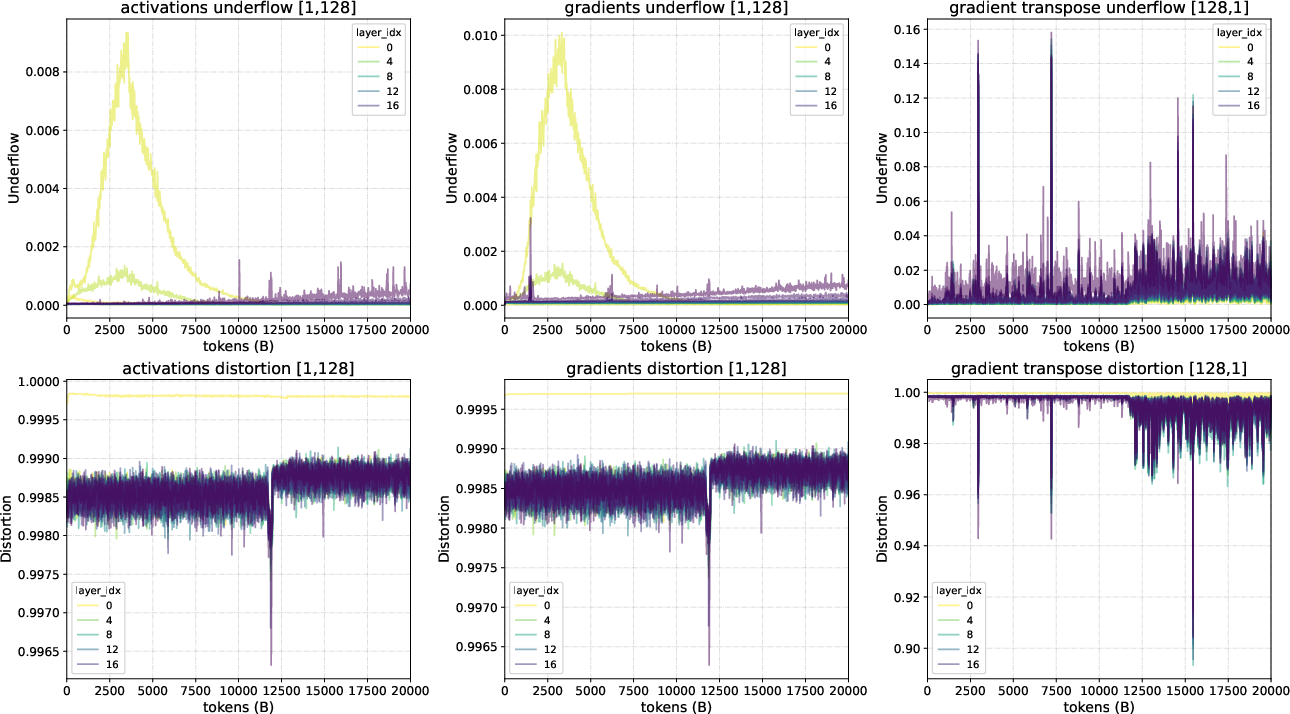
Figure 12: FP8 quantization error tracking (underflow/distortion) demonstrates safe precision, especially with QKNorm damping outliers.
Heterogeneous Pipeline and Scheduling
MTP-specific split scheduling, fine-grained partitioning, and interleaved 1F1B reduce pipeline bubble ratio, enabling balanced scaling for very large MoE models.
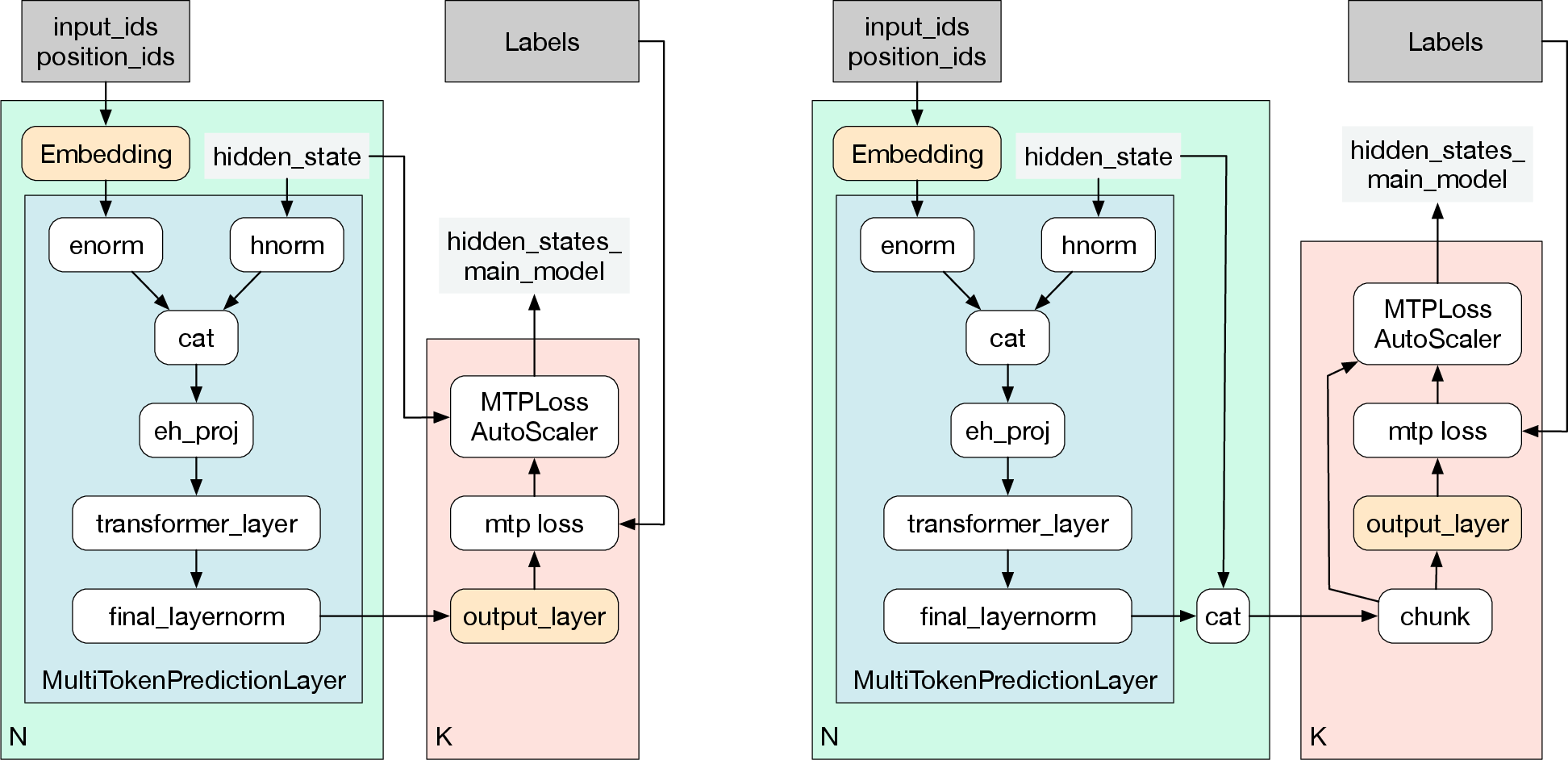
Figure 13: Fine-grained computation flow for MTP partitioning supports efficient scheduling.

Figure 14: Heterogeneous pipeline scheduling drastically lowers training cost by reducing pipeline bubbles.
All operator design choices were evaluated for algorithm-system trade-offs, with operator efficiency trending toward mid-range balance due to First-K-Dense and Group Routing. Cross-platform experiments show sub-millith error, supporting robust deployment.
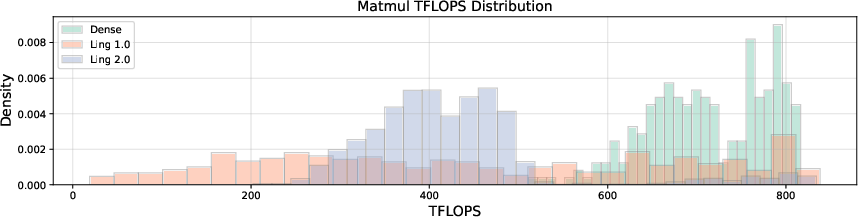
Figure 15: Operator efficiency comparison: Ling 2.0's architecture mitigates bottlenecks compared to previous dense and MoE models.
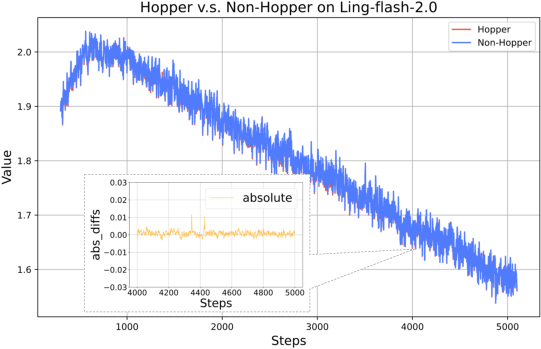
Figure 16: Loss alignment of Ling-flash-2.0 on Hopper vs. non-Hopper GPUs confirms negligible numerical discrepancy.
Benchmark Results
Across math, code, reasoning, knowledge, and agent benchmarks, Ling 2.0 models consistently surpass or match dense baselines with <1/7th active parameters. Ling-1T's reasoning accuracy and efficient thinking represent a distinct Pareto frontier.
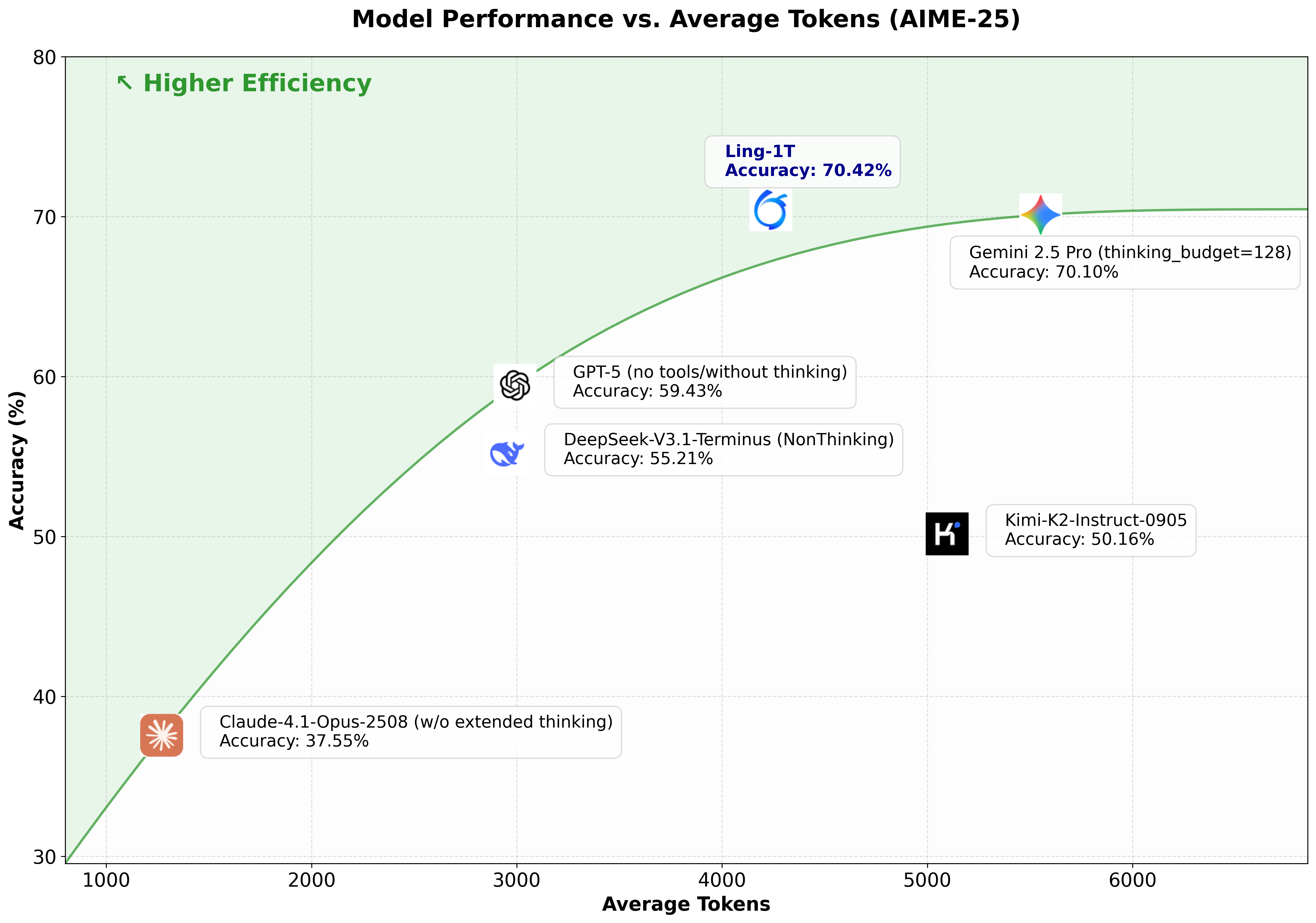
Figure 17: Model performance versus average tokens on AIME-25, highlighting Pareto efficiency between cost and reasoning depth.
Implications and Future Directions
Ling 2.0 demonstrates that a synergy of high-sparsity MoE architecture, data-centric reasoning activation, and advanced infrastructure can scale general reasoning to a trillion-parameter foundation without prohibitive cost. The "every activation boosts reasoning" hypothesis is supported by strong numerical results: verified 7× efficiency leverage, high precision under FP8, and exceptional reasoning performance.
Ling 2.0 remains limited in long-context efficiency (grouped-query attention bottlenecks), maximum effective reasoning depth, and full instruction/agentic potential. The authors outline ongoing transition toward linear/sparse attention, enhanced adaptive reasoning, and generalized agentic frameworks (cf. Ring series), with infrastructure co-design being critical for future scaling.
Conclusion
Ling 2.0 provides a robust blueprint for scaling open-source general reasoning models via efficient sparse activation, principled architectural selection, and tightly engineered infrastructure. The suite's performance supports its core principles, yet leaves open essential challenges in long-context management, continual depth scaling, and agentic alignment—pointing toward further research on algorithmic and infrastructural co-design for efficient, autonomous reasoning systems.