Learning When to Stop: Adaptive Latent Reasoning via Reinforcement Learning
Abstract: Latent reasoning represents a new development in Transformer LLMs that has shown potential in compressing reasoning lengths compared to chain-of-thought reasoning. By directly passing the information-rich previous final latent state into the next sequence, latent reasoning removes the restriction to human language tokens as the medium for reasoning. We develop adaptive-length latent reasoning models and introduce a post-SFT reinforcement-learning methodology to optimize latent reasoning length by minimizing reasoning length while maintaining accuracy. This, in turn, further reduces compute usage and raises the bar on the compressive capabilities of latent reasoning models. Experiments on the Llama 3.2 1B model and the GSM8K-Aug dataset show a $52\%$ drop in total reasoning length with no penalty to accuracy. In future work, we plan to extend to additional models and datasets, analyze relationships between training coefficients, experiment with architecture variations, and continue our knowledge distillation for latent reasoning SFT efforts. We make our code and pretrained weights available at https://github.com/apning/adaptive-latent-reasoning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching an AI LLM to “think” efficiently and to know when to stop thinking. Instead of writing out long reasoning in words (called chain-of-thought), the model uses a faster, quieter kind of thinking called latent reasoning. The goal is to make the model use just enough thinking to get correct answers—no extra—so it’s quicker and uses less computer power.
The big questions the researchers asked
- Can an AI learn to decide, by itself, when it has thought enough and should stop?
- Can we make the model think fewer steps on easy questions (to save time) and more steps on hard questions (to stay accurate)?
- Can we reduce the “length” of thinking while keeping accuracy the same?
How did they study it?
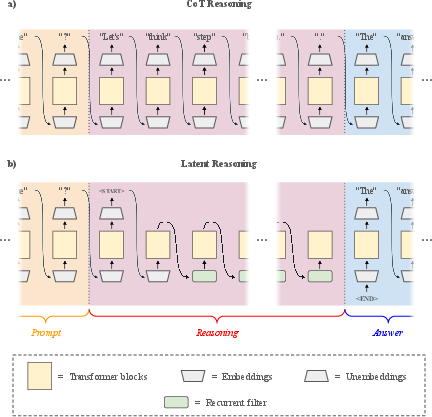
Chain-of-thought vs. latent reasoning
- Chain-of-thought (CoT): The model writes out its reasoning in regular text, step by step, before giving the final answer. This can be helpful but often wastes time and compute.
- Latent reasoning: Instead of writing in words, the model passes its internal “brain state” to itself over multiple steps. Think of this like a silent scratchpad full of compressed ideas—not sentences. It’s faster because it skips word-by-word explanations.
To make latent reasoning work, the model:
- Marks the start and end of a reasoning session with special tokens like <START> and <END>.
- Uses a small “filter” to tidy up its internal state between steps.
- Adds a simple “stop/continue” switch (a tiny classifier head) that decides after each step whether to keep thinking or stop.
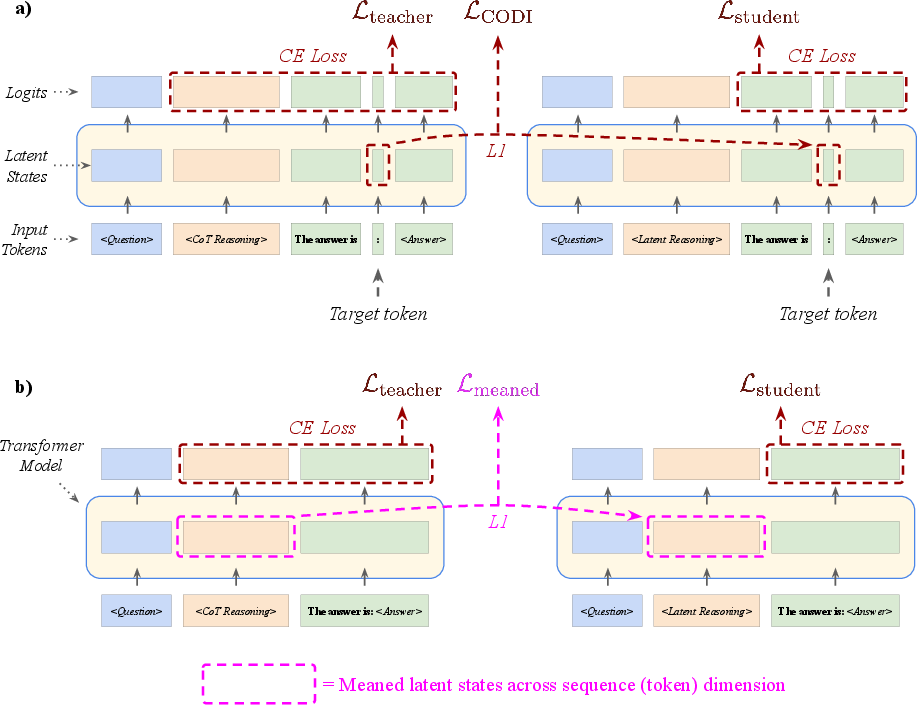
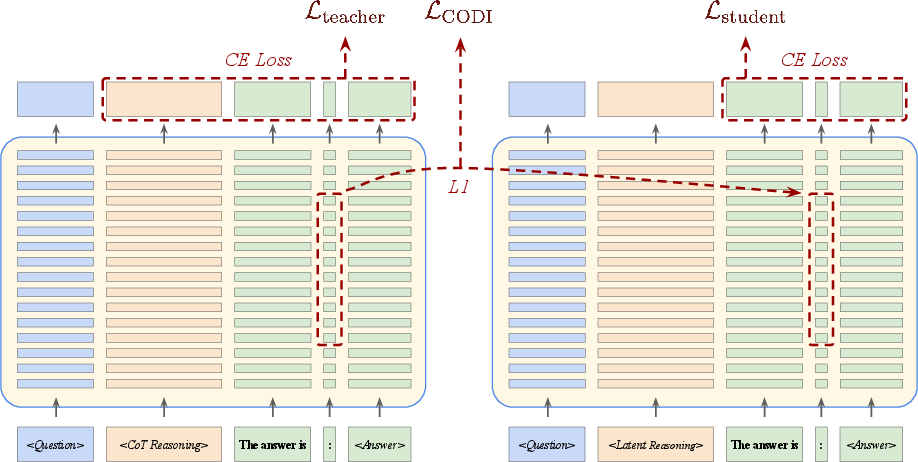
Teaching the model (SFT) with a teacher-student setup
First, they use supervised fine-tuning (SFT):
- A “teacher” run uses normal chain-of-thought.
- A “student” run uses latent reasoning.
- The student is trained to produce the correct answer and to match some of the teacher’s internal brain state near the end—like learning the key ideas the teacher had before the final answer. This approach is inspired by a method called CODI.
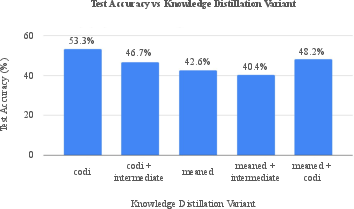
They also tried other ways to distill knowledge (like averaging many internal states or focusing on middle layers), but those didn’t beat the original CODI method.
Coaching the model with rewards (Reinforcement Learning)
After SFT, they use reinforcement learning (RL) to tune how long the model thinks. Imagine a coach awarding points:
- Correct answers earn points.
- Bad formatting (like missing the answer prefix) loses points.
- If a question seems easy (most attempts in a group are correct), the model is rewarded for shorter thinking.
- If a question seems hard (few are correct), the model is rewarded for longer thinking.
They use a method called GRPO (a popular RL technique for LLMs). It looks at multiple answers to the same question (a “group”) and compares rewards within that group, which fits perfectly with their length rewards.
To keep training efficient, they use LoRA—think of it as adding small “adapters” to the model so you don’t have to retrain everything from scratch.
Data, model, and evaluation
- Model: Llama 3.2 1B Instruct.
- Dataset: GSM8K-Aug (math word problems with reasoning), a larger version of GSM8K created using GPT-4.
- Evaluation: They use simple decoding and check if the number in the answer matches the correct one with a small tolerance.
What did they find?
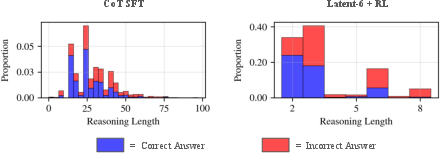
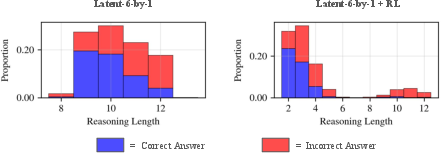
- Their best adaptive latent reasoning setup cut reasoning tokens by about 53% with no drop in accuracy compared to the same model before RL.
- Another variant reduced reasoning by about 62% but lost around 3% accuracy.
- Overall, latent reasoning was much shorter than chain-of-thought. One adaptive model used about 7.6 times fewer tokens than standard chain-of-thought on average.
- The models naturally learned to think more on harder questions and less on easier ones—exactly what they wanted.
In short: they taught a small Llama model to stop thinking earlier when it’s confident and to keep thinking longer when it’s not, saving compute without hurting results.
Why does it matter?
- It makes AI faster and cheaper to run by cutting unneeded thinking.
- It helps the model focus effort where it matters: spend time on hard problems, breeze through easy ones.
- Latent reasoning shows that models don’t need to spell out every step in human language to reason well. Silent, compressed reasoning can be both powerful and efficient.
- This approach can scale to bigger models and tougher tasks, making future AI systems more practical.
The team plans to:
- Try more models and datasets.
- Tune the RL reward settings further.
- Experiment with the design of the latent reasoning parts.
- Improve knowledge distillation methods for latent reasoning.
Their code and pretrained models are open-source, so others can build on it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Generalization is untested: results are limited to Llama 3.2 1B on GSM8K-Aug; evaluate across model sizes (small→medium→large), architectures, and diverse tasks (MATH, ProofWriter, coding, commonsense planning, multi-step QA).
- Accuracy gap persists: latent models remain ~5.7% below CoT SFT; conduct error analysis, plot accuracy–length Pareto curves, and test whether adaptive stopping can close the gap without sacrificing compression.
- Compute savings are proxy-based: reductions are measured via token counts only; profile real-world speed and memory (FLOPs, wall-clock latency, energy, KV-cache size) for CoT vs latent steps to validate efficiency claims.
- Stop-head training is under-specified: the paper does not detail how the binary stopping head is trained during SFT (labels, losses, or supervision); clarify training signals and evaluate calibration (precision/recall, ROC, ECE) of the stopping policy.
- Difficulty estimation is simplistic: the GRPO switch between penalty and reward uses group correctness proportion with p_cutoff=1; ablate different p_cutoff values, alternative difficulty signals (entropy, logit margin, verifier score, error predictors), and mixed criteria.
- RL did not extend maximum reasoning length: models never exceeded pre-RL maxima, undermining the “think longer on hard inputs” goal; relax architectural or reward constraints, allow dynamic upper bounds, and test if longer latent sequences improve hard cases.
- Reward coefficients lack sensitivity analysis: λ_penalty=1e−4 and λ_reward=0.1 are fixed; systematically tune, schedule, or adapt these coefficients and study their stability, convergence, and accuracy–length trade-offs.
- GRPO configuration is opaque: group size, sampling temperature, and diversity during RL are not reported; examine how these factors affect learning signals for length control and accuracy.
- Decoding strategy is narrow: evaluation uses greedy decoding only; compare temperature/nucleus sampling, beam search, and self-consistency to assess interactions with adaptive latent reasoning and stopping.
- Formatting penalty is brittle: reliance on a specific answer prefix risks reward hacking and extraction errors; test robust extraction (normalized parsing, verifier-based rewards) and measure formatting error rates.
- CODI fragility is anecdotal: claims of divergence and dataset filtering challenges lack quantitative evidence; systematically measure divergence frequency, identify failure modes, and propose robustness fixes (loss scaling, gradient clipping, normalization).
- Negative results need deeper diagnosis: Meaned Reasoning Loss and Intermediate Block Loss underperformed, but confounds (block selection, σ_j normalization, weighting with CE losses, stop-gradient placement) are not ablated; run controlled studies to isolate causes and salvage useful variants.
- Architecture ablations are missing: only a 2-layer MLP+LayerNorm recurrent filter and <START>/<END> tokens are tested; compare alternative filters (GRU/LSTM, gated MLP, adapters), token schemes, and state-aggregation strategies (e.g., passing multiple past states).
- LoRA constraints may cap capability: both SFT and RL use LoRA; evaluate full fine-tuning or selective layer tuning, vary LoRA ranks, and measure impact on stopping behavior, stability, and final accuracy.
- Evaluation parsing is fragile: regex numeric extraction with “small tolerance” may mis-score edge cases; quantify parsing failures and adopt verifier-based correctness or standardized normalization routines.
- Dataset filtering may bias learning: removing negative-valued answers and final reasoning steps (for CODI) changes data distribution; assess the effect of these filters and design distillation methods robust to negatives and last-step answers without data removal.
- Statistical rigor is lacking: no confidence intervals, seed variance, or significance tests are reported; include multi-seed runs, standard errors, and training stability metrics to substantiate conclusions.
- Stopping policy behavior is unanalysed: no distributional analysis of stop decisions across difficulty; measure correlations between allocated steps, correctness, and calibrated difficulty to validate adaptive allocation.
- Per-sample adaptivity validation is missing: verify that the model allocates more steps to genuinely hard instances using external difficulty labels or verifier signals (e.g., solution checks, proof length, error predictors).
- Baseline coverage is incomplete: no direct comparison to other stopping methods (e.g., COCONUT’s binary classifier, ACT/ponder nets, halting probability in Transformers); implement and benchmark against these baselines under matched conditions.
- Token–compute misalignment is unaddressed: latent steps and CoT tokens may have different memory/KV-cache behavior; profile per-step compute/memory to ensure compression translates to real resource savings.
- Task scope is narrow: assess whether adaptive latent reasoning benefits long-form proofs and program synthesis where constant length is inadequate; include datasets like MATH, ProofWriter, HumanEval/MBPP.
- Safety/failure modes are unexplored: early stopping may increase brittle or hallucinated answers; integrate verifier- or uncertainty-aware stopping, and measure error severity and robustness under perturbations.
- Rewards are sparse and binary: correctness-only rewards can be noisy; test richer signals (distance-to-target, verifier probability, logit-based shaping, step-wise scaffolding) to improve learning stability and encourage constructive longer reasoning when needed.
- Curriculum and bounds are static: the paper does not explore curricula for latent lengths or dynamic bounds; design curricula that gradually relax/enforce length constraints to foster genuine adaptivity.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, grounded in the paper’s methods (adaptive latent reasoning with a binary stop head, GRPO-based RL with relative length rewards/penalties, and LoRA fine-tuning). Each item includes sector links and key feasibility notes.
- Cost-optimized math reasoning in tutoring and support bots — sectors: Education, Software Use adaptive latent reasoning for math word problems and numeric queries to cut inference tokens by ~50% without accuracy loss (as shown on GSM8K-Aug with Llama 3.2 1B). Potential product/workflow: “Adaptive Think Mode” in a tutoring chatbot; integrate the binary stop head and GRPO reward into the generation loop; track compression ratio and accuracy. Assumptions/dependencies: Transferability from GSM8K-Aug to target curricula; model architectures must support latent reasoning tokens (<START>, <END>); RL hyperparameters need tuning per domain.
- Cloud inference cost reduction for CoT-heavy workloads — sectors: Software, Energy, Finance
Deploy an inference server plugin that switches CoT to latent reasoning and uses adaptive stopping to reduce compute, latency, and energy.
Potential product/workflow: vLLM/TGI wrapper that exposes config for
p_cutoff,λ_penalty,λ_reward, and max latent steps; dashboards for Avg Reasoning Tokens and Compression Ratio. Assumptions/dependencies: Requires latent reasoning SFT/RL and stop head; careful monitoring to avoid accuracy regressions on non-numeric tasks. - On-device assistants and calculators with battery savings — sectors: Consumer (daily life), Mobile Use a small model (e.g., Llama 3.2 1B with LoRA) to provide step-aware solutions with adaptive stopping, enabling offline math helpers on phones/tablets. Potential product/workflow: Mobile app that offers worked solutions; variable latent iterations based on battery and latency budgets. Assumptions/dependencies: Tasks mostly numeric; memory constraints; robust formatting/parsing (the paper’s regex-based evaluation assumes numeric outputs with a known prefix).
- Enterprise analytics helpers for spreadsheets/KPI computation — sectors: Finance, Enterprise Software Reduce API costs for numeric derivations (e.g., KPI calculations, budgeting scenarios) by compressing reasoning length while keeping accuracy steady. Potential product/workflow: Excel/BI plugins that perform adaptive latent reasoning for formula explanations and “what-if” analyses. Assumptions/dependencies: Domain adaptation beyond GSM8K; format penalties and extraction rules adapted to enterprise schemas; data privacy policies.
- Research kit for training adaptive latent reasoning — sectors: Academia, Software Reproduce the paper’s SFT+GRPO pipeline to study token savings versus accuracy on new datasets and models. Potential product/workflow: Open-source training harness (from the paper’s repo) with telemetry for accuracy, tokens, and difficulty proxies. Assumptions/dependencies: Availability of labeled datasets; compute budget for group sampling; reproducibility of CODI-like SFT steps and RL.
- A/B testing of RL reward coefficients in production — sectors: Industry R&D
Tune
p_cutoff,λ_penalty, andλ_rewardby workload to balance token reductions against accuracy. Potential product/workflow: Controlled experiments over representative prompts with group-relative normalization; switch to length rewards when correctness is low. Assumptions/dependencies: Requires multi-sample groups per prompt and robust correctness/format checks; careful monitoring to avoid reward hacking. - Green AI KPIs that include reasoning-length compression — sectors: Policy, Energy Add “Compression Ratio” (CoT tokens over latent tokens) and Avg Reasoning Tokens to model cards and sustainability reporting. Potential product/workflow: Internal dashboards and external disclosures for procurement decisions. Assumptions/dependencies: Stakeholder adoption; standardized measurement across vendors; mapping token savings to energy outcomes.
- Cascaded model routing with adaptive compute budgets — sectors: Software, MLOps Early-stop easy queries with small models and escalate to larger models or more latent steps only for hard queries. Potential product/workflow: Orchestrator that routes based on difficulty signals (e.g., correctness fraction proxies, confidence scores). Assumptions/dependencies: Robust difficulty estimation beyond numeric tasks; fallbacks when accuracy drops; calibration per domain.
- Adaptive math practice in EdTech — sectors: Education Adjust “thinking time” (latent steps) per problem difficulty to keep students’ feedback fast on easy items and thorough on hard ones. Potential product/workflow: Tutor app with dynamic latent reasoning and transparency about computation and confidence. Assumptions/dependencies: Domain alignment; oversight and guardrails for pedagogical quality; fairness across student populations.
- Benchmarking harnesses with token-efficiency metrics — sectors: Academia, Industry Extend evaluation suites to record accuracy, Avg Reasoning Tokens, and Compression Ratio alongside standard metrics. Potential product/workflow: Benchmarks replicating the paper’s numeric extraction and token accounting, adapted to broader tasks. Assumptions/dependencies: Reliable answer extraction for non-numeric outputs; standardization across datasets.
Long-Term Applications
The following use cases require further research, scaling to larger models/datasets, multimodal integration, or rigorous validation.
- Domain-general adaptive latent reasoning at scale — sectors: Software, Education, Healthcare Extend SFT+RL beyond GSM8K-style numeric problems to code, scientific QA, legal reasoning, and clinical protocols, with dynamic stop decisions. Potential product/workflow: Larger LLMs with latent reasoning heads; domain-specific reward shaping and validation pipelines. Assumptions/dependencies: New datasets; safety and compliance reviews; avoiding accuracy loss in complex tasks.
- Multimodal adaptive latent reasoning for robotics and planning — sectors: Robotics Use latent iterations over internal states (vision, proprioception) with a stop head to decide when planning is “good enough.” Potential product/workflow: Robot planner with breadth-first latent computations and adaptive termination. Assumptions/dependencies: Architecture changes for multimodal latents; simulation-to-real transfer; safety certification.
- Compute-aware agents for edge and IoT — sectors: Energy, Consumer Agents that dynamically throttle latent iterations based on battery, thermal constraints, and latency SLAs. Potential product/workflow: Runtime policies linking resource telemetry to reasoning length budgets. Assumptions/dependencies: On-device RL alignment; robust fallbacks when budgets tighten; privacy guarantees.
- New cloud pricing/billing based on latent iterations — sectors: Finance, Cloud Charge for internal latent passes rather than only output tokens, aligning incentives for efficient reasoning. Potential product/workflow: Metering for latent steps and dynamic pricing tiers (“Short Think,” “Deep Think”). Assumptions/dependencies: Provider support; transparent measurement; interoperability with existing token-based billing.
- Healthcare decision support with adaptive depth — sectors: Healthcare Triaging and protocol adherence systems that flex computation based on case complexity while maintaining validated accuracy. Potential product/workflow: Clinical support tools that escalate latent steps for ambiguous cases; strict audit logs. Assumptions/dependencies: Extensive clinical trials; regulatory approval; domain-specific datasets; clear non-diagnostic labeling where appropriate.
- Robust knowledge distillation from CoT to latent reasoning — sectors: Academia, Software Improve KD methods beyond CODI; address the paper’s challenges with meaned reasoning loss and block selection. Potential product/workflow: New distillation losses that avoid single-token fragility, better intermediate-block selection, or contrastive objectives. Assumptions/dependencies: Algorithmic advances; ablations across architectures; stability under longer proofs and negative-valued outputs.
- Hardware–software co-design for latent loops — sectors: Energy, Semiconductors Optimize kernels for recurrent latent passes, memory reuse, and rapid stop-head evaluation to minimize energy/latency. Potential product/workflow: GPU/ASIC features that accelerate latent reasoning iterations and gating. Assumptions/dependencies: Vendor collaboration; workload characterization; economic viability.
- Agent frameworks with “anytime reasoning” — sectors: Software, Robotics Schedulers that choose reasoning length under strict latency or cost budgets, with graceful interruption and resumption. Potential product/workflow: Agent SDKs integrating RL-tuned stop policies, budget-aware planning, and fallback strategies. Assumptions/dependencies: Reliable uncertainty estimates; risk-aware policies; comprehensive evaluation in dynamic environments.
- Policy and standards for compute efficiency in AI procurement — sectors: Policy Require reporting of token-efficiency metrics and adaptive reasoning capabilities in public tenders and sustainability filings. Potential product/workflow: Model card standards that include Avg Reasoning Tokens, Compression Ratio, and energy proxies. Assumptions/dependencies: Multi-stakeholder agreement; harmonized measurement; alignment with carbon-accounting frameworks.
- Safety and reliability research on “overthinking” vs. correctness — sectors: Academia, Industry
Establish guardrails that prevent harmful accuracy trade-offs when shortening reasoning; detect hard cases early.
Potential product/workflow: Monitors that trigger longer latent runs or escalate to expert models; continuous calibration of
p_cutoffand rewards. Assumptions/dependencies: Task-specific reliability metrics; robust difficulty proxies beyond group correctness fraction; human-in-the-loop protocols.
Glossary
- Adaptive latent reasoning: The capability of a model to decide when to terminate its latent reasoning based on input difficulty. "In order to enable adaptive latent reasoning lengths, we add a simple linear binary classification head to the end of the model."
- Beam search: A decoding strategy that explores multiple candidate sequences in parallel to find higher-quality outputs. "beam search"
- Binary classification head: A simple linear output layer that predicts one of two classes (e.g., continue or stop reasoning). "we add a simple linear binary classification head to the end of the model."
- Chain-of-Thought (CoT): A prompting and generation technique where models produce intermediate reasoning steps before the final answer. "Compared to chain-of-thought (CoT) reasoning~\citep{wei2023chainofthoughtpromptingelicitsreasoning, kojima2023largelanguagemodelszeroshot}, latent reasoning..."
- Correctness reward: An RL reward that grants +1 for correct answers and 0 otherwise. "We utilize a simple correctness reward which assigns $1$ reward for correctness and $0$ otherwise."
- Cross-entropy (CE) loss: A standard classification loss used for next-token prediction in language modeling. "Cross-entropy (CE) next-token-prediction loss is applied to the CoT reasoning sequence tokens and answer tokens of the teacher pass"
- Curriculum learning: A training strategy that introduces tasks in an increasingly difficult order to stabilize and improve learning. "COCONUT uses a staged curriculum learning strategy where increasingly large proportions of the CoT reasoning sequence are replaced with latent reasoning during training."
- Formatting penalty: An RL penalty applied when outputs do not follow required formatting, preventing answer extraction. "We also define a formatting penalty, , which subtracts $1$ reward if the output does not contain the required answer prefix."
- Greedy decoding: A decoding method that selects the highest-probability token at each step without exploring alternatives. "We use greedy decoding during evaluation."
- Group Relative Policy Optimization (GRPO): An on-policy RL algorithm that normalizes rewards within groups of sampled outputs and removes the critic. "We utilize Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmathpushinglimitsmathematical}, a recent on-policy RL algorithm"
- GSM8K-Aug: An augmented dataset derived from GSM8K, extended via GPT-4 prompting for reasoning tasks. "we use the GSM8K-Aug dataset~\citep{whynlp2025gsm8kaug, deng2023implicitchainthoughtreasoning}"
- Knowledge distillation: A training technique where a student model learns from a teacher model’s representations or outputs. "Finally, the knowledge distillation loss component, , constrains the latent states of the token directly preceding the answer tokens in the student pass to the latent states of the same token in the teacher pass."
- Layernorm: A normalization technique applied to neural activations within a layer to stabilize training. "uses a two-layer MLP followed by a layernorm as the recurrent filter."
- Latent reasoning: A method where models pass hidden states (latent representations) as the reasoning medium instead of language tokens. "Latent reasoning represents a new development in Transformer LLMs that has shown potential in compressing reasoning lengths compared to chain-of-thought reasoning."
- Latent state: The hidden representation output by a model layer used to carry information across steps. "the final latent state of the Transformer is passed back in as input."
- Length penalty: An RL training term that discourages overly long generated responses. "a length penalty was used which penalized the longer responses within a group of generations to the same input."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank matrices into transformer weights. "We use LoRA~\citep{hu2021loralowrankadaptationlarge} to train during both SFT and RL phases."
- Monte Carlo Tree Search (MCTS): A search algorithm that uses stochastic sampling to explore decision trees for planning or reasoning. "Monte Carlo Tree Search (MCTS)"
- On-policy (RL): A class of RL methods where the policy used to select actions is the same as the one being updated. "a recent on-policy RL algorithm"
- Proximal Policy Optimization (PPO): A stable policy-gradient RL algorithm that uses clipped objectives to constrain policy updates. "GRPO is a variant of PPO~\citep{schulman2017proximalpolicyoptimizationalgorithms}"
- Recurrent filter: A module applied to latent states before feeding them back into the model during latent reasoning. "the latent state is passed through a module denoted here as the recurrent filter before being input into the Transformer."
- Regex: Regular expressions used for pattern matching and extraction from text outputs. "We use regex to extract the number from the answer"
- Reinforcement learning (RL): A learning paradigm where models optimize behavior via rewards obtained from interactions. "we use reinforcement learning to refine the latent reasoning model"
- Relative length penalty: A group-relative penalty applied only to correct responses to discourage longer-than-average reasoning lengths. "We term it the relative length penalty."
- Relative length reward: A group-relative reward that encourages longer reasoning on harder questions (lower group correctness). "We define the relative length reward as exactly the negative of the relative length penalty."
- Reward hacking: A failure mode where the model exploits the reward function to achieve higher rewards without truly improving the task. "to prevent reward hacking where the model trades accuracy for shorter reasoning length"
- Self-distillation: A distillation technique where a model’s own outputs (teacher) guide its latent-reasoning student. "Meanwhile, CODI takes a self-distillation approach."
- Smooth L1 loss: A robust regression loss blending L1 and L2 behaviors, used here for latent-state matching. "smooth_L1"
- Stop-gradient (SG): An operation that prevents gradients from flowing through certain tensors during backpropagation. "and be the stop-gradient operation which prevents the knowledge distillation gradient from flowing from the student through the teacher."
- Supervised fine-tuning (SFT): Post-pretraining training on labeled data to adapt models to specific tasks or behaviors. "both employ supervised fine-tuning (SFT) on pretrained LLMs to develop latent reasoning capability."
- Transformer: A neural architecture based on attention mechanisms widely used in language modeling. "Transformer-based LLMs generally consume the same amount of compute per-token."
- Two-layer MLP: A multi-layer perceptron with two linear layers used as part of the recurrent filter. "uses a two-layer MLP followed by a layernorm"
Collections
Sign up for free to add this paper to one or more collections.

