On the Fundamental Limits of LLMs at Scale
Abstract: LLMs have benefited enormously from scaling, yet these gains are bounded by five fundamental limitations: (1) hallucination, (2) context compression, (3) reasoning degradation, (4) retrieval fragility, and (5) multimodal misalignment. While existing surveys describe these phenomena empirically, they lack a rigorous theoretical synthesis connecting them to the foundational limits of computation, information, and learning. This work closes that gap by presenting a unified, proof-informed framework that formalizes the innate theoretical ceilings of LLM scaling. First, computability and uncomputability imply an irreducible residue of error: for any computably enumerable model family, diagonalization guarantees inputs on which some model must fail, and undecidable queries (e.g., halting-style tasks) induce infinite failure sets for all computable predictors. Second, information-theoretic and statistical constraints bound attainable accuracy even on decidable tasks, finite description length enforces compression error, and long-tail factual knowledge requires prohibitive sample complexity. Third, geometric and computational effects compress long contexts far below their nominal size due to positional under-training, encoding attenuation, and softmax crowding. We further show how likelihood-based training favors pattern completion over inference, how retrieval under token limits suffers from semantic drift and coupling noise, and how multimodal scaling inherits shallow cross-modal alignment. Across sections, we pair theorems and empirical evidence to outline where scaling helps, where it saturates, and where it cannot progress, providing both theoretical foundations and practical mitigation paths like bounded-oracle retrieval, positional curricula, and sparse or hierarchical attention.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a big question: how far can we push LLMs by making them bigger and training them on more data? The authors show that even if we keep scaling up, there are deep, built‑in limits that no amount of size or compute can fully fix. They focus on five stubborn problems—hallucination, using long contexts, reasoning, retrieval, and mixing text with images—and explain why these problems appear and why some of them are impossible to completely eliminate.
What goals or questions does the paper explore?
The paper looks at simple but powerful questions:
- Why do LLMs sometimes “make things up” (hallucinate), even when they sound confident?
- Why do models struggle to truly use very long inputs (like huge documents) even if their context window is large?
- Why do they prefer completing patterns over doing step‑by‑step logical reasoning?
- Why does adding search or a knowledge database (retrieval) help, but still break down in tricky situations?
- Why is mixing text with other types of input (like images) hard, and why does text often “dominate” the learning?
The main idea: some failures come from fundamental math limits and the nature of how we train LLMs—not just bad engineering or too little data.
How did the authors study this?
The paper uses a mix of math arguments and real‑world observations:
- Computability theory: Think of a teacher who can always craft a new question that trips up any student. The authors use classic math results to show that for every computable model, there will always be inputs it gets wrong, no matter how smart it is.
- Uncomputable problems: Some questions (like the famous “Halting Problem”) are impossible for any computer to solve perfectly for all cases. If you ask those kinds of questions, any model will fail on infinitely many inputs.
- Information theory and statistics: Imagine packing a giant wardrobe into a small suitcase. A model with finite capacity must compress information—and compression causes some errors, especially for rare or highly specific facts. Learning millions of unrelated facts would need an unrealistic amount of examples.
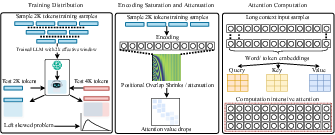
- Transformer geometry and training effects: Even if a model accepts very long inputs, it’s often under‑trained on faraway positions, positional signals can fade, and attention may get overcrowded—so the “effective” context it truly uses is much smaller.
- Empirical evidence: They pair the math with data and experiments showing long‑tail facts, outdated info, noisy sources, and evaluation practices that encourage guessing.
What are the main findings, and why do they matter?
Here are the five key limits the paper explains, each with a simple intuition:
- Hallucination is inevitable
- Why: Some questions are impossible to solve perfectly; models have limited memory and must compress; rare facts don’t appear often enough in training; and many benchmarks reward confident guessing over honest uncertainty.
- Everyday picture: Even the best student will be stumped by cleverly designed trick questions. Also, if you only saw a rare fact once, you’re more likely to guess wrong later.
- Long context isn’t fully usable
- Why: Models are trained mostly on shorter inputs, so positions far from the start are under‑practiced; signals that mark “where” a token is can fade with distance; and attention gets crowded when too many tokens compete.
- Everyday picture: Reading dozens of open browser tabs at once means you’ll miss details. The more you cram in, the harder it is to keep track of what matters.
- Reasoning degrades under the usual training
- Why: LLMs are trained to predict the next word, which rewards pattern completion and fluency, not strict logical steps. Without a special “reasoning loss,” they get great at sounding right, not proving they’re right.
- Everyday picture: Completing the sentence “Because rain is wet, umbrellas…” feels easy, but proving a math statement step‑by‑step is different. LLMs mostly practice the first kind.
- Retrieval (using search or tools) is fragile
- Why: There’s a limit to how much relevant info fits in the token budget; rankings can pick the wrong sources; extra documents can distract the model; and as you retrieve “more,” the useful signal per token often drops.
- Everyday picture: If you hand someone too many articles to skim quickly, they lose the thread and miss the key facts.
- Multimodal misalignment (text + images) is hard
- Why: Text tends to dominate training and gradients; images and text live in different “shapes” of data; and shallow cross‑modal links cause visual illusions or symbolic confusion.
- Everyday picture: Two friends speak different languages and one talks much louder. Even if they chat a lot, the quieter friend’s message gets lost.
These findings matter because they reset expectations: scaling helps, but some ceilings are mathematical or structural. Knowing the limits helps us design safer, more reliable systems.
What methods or fixes do they suggest?
The authors don’t just point out problems—they suggest practical directions:
- Use oracles and tools wisely: Let the model call bounded, high‑quality sources and be clear about token budgets, so retrieval doesn’t drown out the answer.
- Positional curricula and better attention: Train more on long‑range positions; use sparse or hierarchical attention to reduce crowding.
- Encourage honest uncertainty: Change evaluations to give credit for “I’m not sure” when appropriate, so models aren’t punished for being careful.
- Calibrate and constrain decoding: Tune models to estimate confidence better; use guardrails so they don’t free‑associate on high‑risk queries.
- Continual learning with care: Update knowledge over time to fight staleness, but manage forgetting of older facts.
So what’s the big takeaway?
The paper’s message is simple and important:
- Some LLM failures are not just bugs—they come from deep mathematical and informational limits.
- Scaling alone won’t erase hallucination, fully unlock long contexts, guarantee perfect reasoning, or make multimodal models perfectly aligned.
- We should build systems around these realities: combine models with tools, design better training/evaluation setups, and accept that uncertainty is part of responsible AI.
In short, this work helps move the field from “just make it bigger” to “make it wiser”: understand the limits, mitigate them where possible, and design AI that is reliable, honest, and practical in the real world.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper and could guide future research:
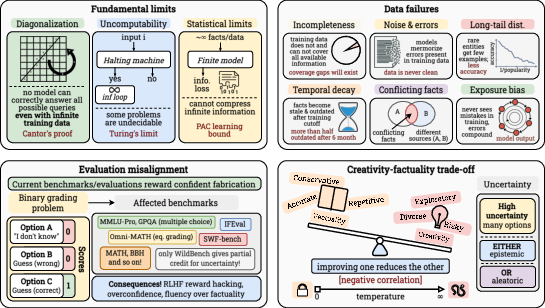
- Worst-case vs typical-case bounds: The diagonalization and undecidability arguments are worst-case; there is no distributional analysis quantifying hallucination risk under realistic user/query distributions.
- Practical prevalence of undecidable queries: The paper does not estimate how often real-world tasks reduce to undecidable instances or provide proxy identification tests for such queries in deployment.
- Ground-truth construction assumptions: The diagonalization proofs rely on adversarially constructed computable ground-truth functions; it remains unclear how to map these to naturalistic tasks without adversarial design.
- Formalization of hallucination risk: The paper lacks a precise, deployment-relevant definition and measurement protocol for “hallucination risk” that unifies open-ended generation, multiple-choice, and tool-augmented settings.
- Complexity measures for LLMs: VC-dimension and generic PAC bounds are invoked, but no transformer-specific capacity measures (e.g., algorithmic stability, norm-based, compression-based, or sequence-Rademacher complexity) are developed to yield actionable sample complexity estimates.
- Structure vs arbitrary facts: Sample complexity lower bounds assume independent, unstructured facts; the paper does not analyze how structured knowledge (graphs, logical constraints, compositionality) changes error floors or data requirements.
- Retrieval-theoretic analysis: Claims about mutual information decay with retrieval breadth lack a formal channel model; no closed-form bounds connect ranker quality, k, token budgets, cross-attention noise, and end-to-end accuracy.
- Conditions where retrieval helps vs hurts: No threshold analyses specify when retrieval-augmented generation strictly improves or degrades performance as a function of oracle precision/recall, latency, and coupling noise.
- Bounded-oracle retrieval theory: The proposed mitigation is not formalized; open is a theory of bounded oracles (accuracy, coverage, cost) and optimal policies for allocating token budgets between query, retrieved evidence, and reasoning.
- Context-compression constants: The “effective context scales sub-linearly” claim lacks quantified constants and predictive laws across different positional encodings, architectures, scaling regimes, and training curricula.
- Positional under-training mechanisms: There is no controlled empirical study isolating position-frequency effects, RoPE overlap, and gradient attenuation to causally attribute long-context failures.
- Softmax crowding: The hypothesized shrinking of logit margins with context length is not derived; a formal analysis of crowding as a function of vocabulary size, head count, and layer depth is missing.
- Architectural remedies with proofs: Sparse/hierarchical attention and external memory are proposed, but no theoretical guarantees or comparative bounds show when these architectures provably alleviate context-compression limits.
- Reasoning vs pattern completion: The paper asserts next-token likelihood favors completion over inference but does not provide impossibility results for logical consistency under token-level objectives or sufficiency results for alternative objectives (e.g., step-level or proof-verification losses).
- Chain-of-thought guarantees: There is no theory relating supervising intermediate steps (CoT) to calibrated improvements in logical validity or error propagation bounds under exposure bias.
- Exposure bias mitigation: The paper does not analyze DAgger-style rollouts, self-consistency, or verifier feedback in a theoretical framework that yields guarantees on compounding-error control.
- Calibration and abstention: While evaluation misalignment is discussed, there is no development of proper scoring rules, selective prediction, or conformal methods tailored to LLMs that provably reduce overconfidence without crippling utility.
- RLHF reward hacking: Open are methods and proofs showing how to design preference models and training objectives that disentangle fluency/verbosity from factuality and reduce confident fabrication.
- LM-as-judge bias: There is no formal model or empirical protocol to quantify and correct length/verbosity bias, sensitivity to subtle factual errors, or self-consistency bias in LM-based evaluators.
- Temporal decay modeling: The staleness phenomenon is described but not modeled; open are hazard-rate models for fact obsolescence, optimal update cadences, and staleness-aware retrieval/training policies with proven error reductions.
- Continual learning trade-offs: No theoretical or empirical treatment quantifies catastrophic forgetting vs staleness reduction in large LLMs and establishes update protocols that optimize the stability–plasticity trade-off.
- Data noise floors: The asserted 2–3% noise rates lack controlled experiments linking noise levels to irreducible hallucination floors at web-scale pretraining; methods to robustly estimate and mitigate these floors are open.
- Contamination and model collapse: The dynamics of training on model-generated data are not formalized; there is no quantitative framework predicting when synthetic data inflates hallucination or induces distributional drift.
- Multimodal gradient imbalance: The claim that language dominates gradients is not theoretically grounded; needed are training-dynamics analyses, identifiability results, and interventions (optimizers, losses, curricula) with guarantees for cross-modal alignment.
- Cross-modal manifold alignment: The paper lacks a theory for when latent manifolds are alignable, required sample sizes, and how contrastive vs generative objectives trade off alignment fidelity and downstream robustness.
- Interaction effects among limits: No causal or game-theoretic model quantifies how mitigating one axis (e.g., retrieval) exacerbates another (e.g., reasoning distraction), nor a multi-objective optimization framework describing Pareto frontiers across the five limits.
- Safety-critical deployment: The work does not specify risk thresholds, selective abstention policies, or verification pipelines that are provably sufficient for given domains (e.g., medicine, law) under bounded compute and latency.
- Tool use and external solvers: The computability-based ceilings are not re-derived for tool-augmented LLMs; open are composite-system limits when bounded, verifiable oracles (calculators, theorem provers, web) are available.
- Benchmarks with uncertainty: While benchmark misalignment is highlighted, there is no released suite with abstention options, proper scoring rules, and verifiability criteria to measure calibrated knowledge and defer-when-uncertain behavior.
- Replication artifacts: The paper states “paired theorems and empirical evidence,” but comprehensive, reproducible experiments and ablations validating each proposed mechanism (context compression, retrieval drift, multimodal misalignment) are not provided.
- Multilingual and low-resource generality: The limits and proposed mitigations are not evaluated or theorized across diverse languages and scripts, where tokenization, morphology, and data scarcity could alter both bounds and practical failure modes.
- Compute–data–quality trade-offs: There is no quantitative treatment of how improvements in data curation vs more parameters vs better objectives each reduce hallucination risk, nor compute-optimal policies targeting reliability instead of loss.
Practical Applications
The following applications translate the paper’s theoretical limits on LLM scaling into practical actions across sectors, distinguishing what can be deployed today versus what likely requires further research and engineering.
Immediate Applications
- Evidence-constrained retrieval-augmented generation (RAG) pipelines
- Sector: healthcare, finance, legal, scientific support, enterprise search
- Tools/products/workflows: bounded-oracle retrieval modules that cap breadth; strict “generate-from-evidence” decoders; citation-and-attribution UX; query re-writing and re-ranking to reduce semantic drift; diversity-aware top-k selection; token-budget optimizers
- Assumptions/dependencies: access to curated, timestamped knowledge bases; reliable vector/keyword indices; willingness to restrict generation to retrieved content; monitoring for retrieval coupling noise
- Uncertainty-aware interfaces and abstention-by-default
- Sector: policy/regulation (model governance), education (assessment), consumer apps (assistants), customer support
- Tools/products/workflows: “I don’t know” buttons; calibrated confidence displays; abstention scoring in evaluations; content risk labels; LM-as-judge configurations that penalize ungrounded verbosity
- Assumptions/dependencies: usable confidence calibration (e.g., temperature scaling, self-consistency scores); organizational acceptance of abstention; updated KPI/benchmark rubrics that reward honesty over guessing
- Time-aware answering and staleness control
- Sector: news/media, compliance, clinical decision support, financial analysis
- Tools/products/workflows: timestamp-conditioned prompts; retrieval filters by publication date; staleness monitors and scheduled data refresh; “as-of” disclosure in outputs
- Assumptions/dependencies: metadata-rich corpora; operational data pipelines; policies that surface date provenance and discourage timeless phrasing for time-sensitive claims
- Context management for long inputs
- Sector: enterprise knowledge management, legal eDiscovery, customer support
- Tools/products/workflows: structured chunking and index-aware summarization; selective copy for salient spans; hierarchical prompting; positional-curriculum fine-tuning to reduce positional under-training; RoPE/encoding tuning
- Assumptions/dependencies: control over fine-tuning or inference-time prompt policies; acceptance that effective context is sub-linear in nominal window; compute limits for re-ranking and multi-pass summarization
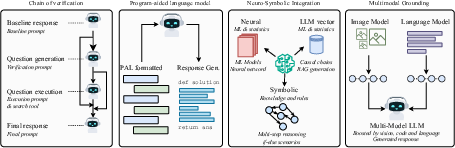
- Reasoning-through-tools workflows (program-aided reasoning)
- Sector: software engineering, STEM tutoring, operations planning, data analytics
- Tools/products/workflows: automatic tool invocation (calculators, code runners, theorem checkers); stepwise verification (self-consistency, unit tests); “plan then execute” agents with sandboxed execution
- Assumptions/dependencies: safe execution environments; guardrails to prevent tool misuse; task decomposition that separates correlation completion from exact inference
- Retrieval noise mitigation and semantic drift detection
- Sector: search engines, internal KBs, e-commerce catalogs
- Tools/products/workflows: learned re-rankers; query expansion with controlled diversity; coupling-noise diagnostics; deduplication of near-duplicates; re-grounding prompts during long generations
- Assumptions/dependencies: high-quality embeddings plus lexical indices; instrumentation to measure mutual information loss as breadth increases; token budgets that can accommodate re-ranking passes
- Multimodal guardrails and evidence gating
- Sector: medical imaging, autonomous systems, e-commerce product moderation, content safety
- Tools/products/workflows: require visual evidence (e.g., bounding boxes or segmentation overlays) for text claims; cross-modal confidence gating that downweights language priors when visual signals disagree; per-modality loss balancing in fine-tunes
- Assumptions/dependencies: labeled multimodal datasets with spatial annotations; inference-time pipelines that can render evidence; acceptance of conservative behavior when modalities misalign
- Governance, policy, and benchmark adjustments to reduce guessing incentives
- Sector: policy/regulation, procurement, academic evaluation, model governance
- Tools/products/workflows: benchmarks with abstention options and calibration metrics; provenance and citation requirements for high-stakes uses; deployment policies that treat LLM outputs as suggestions, not decisions
- Assumptions/dependencies: stakeholder agreement to revise leaderboards and acceptance criteria; organizational risk appetite aligned with irreducible error; audit trails and logging
Long-Term Applications
- Sparse/hierarchical attention and long-context memory architectures
- Sector: software/model providers, enterprise AI platforms
- Tools/products/workflows: hierarchical attention, block-sparse kernels, external memory modules; curriculum training on rare positions to counter softmax crowding and encoding attenuation
- Assumptions/dependencies: significant model retraining budgets; new benchmarks that capture effective context use; hardware optimization for sparse ops
- Formal detectors for undecidable or non-answerable queries with escalation policies
- Sector: software assurance, security, compliance
- Tools/products/workflows: heuristics and static-analysis-inspired classifiers for halting-style or self-referential tasks; automatic abstention or human escalation; “proof required” modes
- Assumptions/dependencies: reliable detection rates at scale; user acceptance of frequent abstentions on borderline logic/code tasks
- Certified retrieval and proof-carrying generation
- Sector: legal drafting, scientific publishing, regulatory filings
- Tools/products/workflows: decoders that constrain outputs to derivations from retrieved evidence; formal verification or justification graphs attached to claims; audit-ready provenance trails
- Assumptions/dependencies: structured knowledge stores amenable to formal derivation; tight integration between LM and symbolic provers; performance trade-offs acceptable in regulated contexts
- Continual learning with anti-forgetting and time-aware knowledge lifecycle
- Sector: enterprise knowledge management, healthcare guidelines, financial regulations
- Tools/products/workflows: adapters or LoRA with elastic weight consolidation; time-indexed memory; recurrent update schedules with regression tests on tail facts
- Assumptions/dependencies: robust data governance; evaluation suites for interference and drift; privacy-preserving update pipelines
- PAC-aware dataset design and long-tail coverage planning
- Sector: academia, model training teams, public datasets
- Tools/products/workflows: coverage meters for rare entities; active data collection targeting long tails; sample complexity calculators to estimate error floors
- Assumptions/dependencies: accurate measurement of tail distributions; budget and ethics for targeted data acquisition; transparent data documentation
- Multimodal alignment advances (entropy balancing and gating)
- Sector: robotics, autonomous vehicles, industrial inspection
- Tools/products/workflows: modality-specific gradient scaling; disentangled latent manifolds; cross-modal consistency training; reliability checks that prioritize perception over language priors
- Assumptions/dependencies: large, balanced multimodal corpora; evaluation protocols measuring cross-modal failure rates; deployment-time fusion stacks
- Calibration-aware RLHF/DPO and uncertainty-sensitive reward models
- Sector: model providers, safety teams
- Tools/products/workflows: reward functions that penalize overconfidence and reward appropriate abstention; multi-signal judges (evidence, brevity, correctness)
- Assumptions/dependencies: high-quality human or expert feedback; scalable pipelines for training with calibration targets; community acceptance of less verbose, more cautious models
- Neuro-symbolic reasoning engines integrated with LLM front-ends
- Sector: math education, compliance analytics, program synthesis
- Tools/products/workflows: hybrid stacks that offload inferential steps to solvers/provers; structured intermediate representations; correctness-by-construction templates
- Assumptions/dependencies: seamless tool APIs; latency budgets compatible with solver calls; user workflows tolerant of slower, more reliable outputs
- Semantic firewalls and dynamic token-budget optimizers
- Sector: enterprise search, knowledgeOps
- Tools/products/workflows: middleware detecting semantic drift during generation; adaptively reallocating tokens across retrieval, reasoning, and output; early stopping when evidence coverage drops
- Assumptions/dependencies: robust telemetry on mutual information and drift; policy definitions for halting or escalating responses
- Benchmark and governance overhauls for high-stakes deployments
- Sector: policy/regulation, standards bodies, industry consortia
- Tools/products/workflows: standardized calibration metrics, abstention rates, provenance checks; disclosure requirements for confidence and sources in sensitive domains (health, finance, law)
- Assumptions/dependencies: multi-stakeholder coordination; legal frameworks recognizing irreducible error; alignment with existing compliance regimes
These applications assume the paper’s core premises: hallucination is irreducible in open-ended domains; effective context is sub-linear in window size; likelihood training favors pattern completion over inference; retrieval breadth trades off against grounding; and multimodal scaling alone does not fix alignment. Feasibility hinges on curated data access, tool APIs, compute budgets, organizational risk tolerance, and willingness to prioritize calibrated reliability over raw fluency.
Glossary
- Abstention: Withholding an answer when uncertain; in evaluation settings, often scored the same as an incorrect answer, incentivizing guesses. "This creates a rational incentive structure that strictly favors guessing over abstention."
- Aleatoric uncertainty: Uncertainty arising from inherent randomness or ambiguity in the data, not reducible by more information. "epistemic uncertainty (what they don't know) versus aleatoric uncertainty (inherent ambiguity)."
- Architectural colonization effects: Phenomenon where one modality’s pathway (often language) dominates or constrains another in multimodal architectures. "cross-modal inputs introduce architectural colonization effects, epistemic pitfalls, and scaling/deployment challenges."
- Autoregressive generation: Generating tokens sequentially where each token conditions on previously generated tokens. "At inference, they generate text autoregressively, feeding their own predictions back as input."
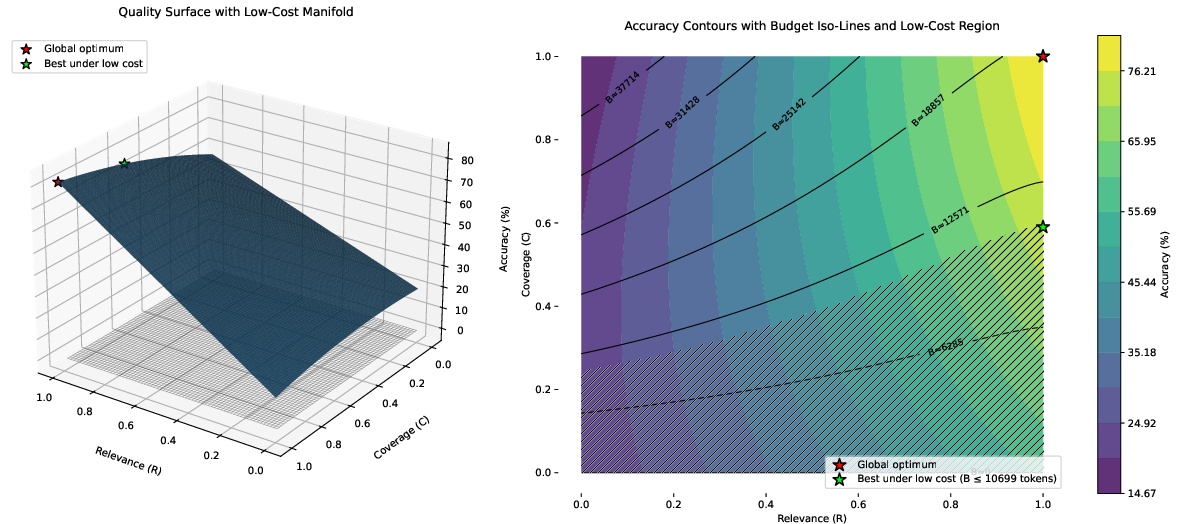
- Bounded-oracle retrieval: Retrieval setup with limited, controlled external knowledge access used to mitigate errors. "bounded-oracle retrieval, positional curricula, and sparse or hierarchical attention."
- Catastrophic forgetting: Tendency of models to overwrite previously learned knowledge when trained on new data. "a phenomenon known as catastrophic forgetting in continual learning."
- Characteristic function (of a problem): Function that maps inputs to 1 if they are in a set (e.g., halting instances) and 0 otherwise. "be the characteristic function of the Halting Problem"
- Constraint-based decoding: Decoding strategies that enforce logical or structural constraints to reduce errors. "retrieval-augmented generation (oracle access), continual learning (adaptive capacity expansion), and constraint-based decoding can reduce hallucination"
- Coupling noise: Interference introduced when integrating retrieved evidence with generation, degrading fidelity. "suffers from semantic drift and coupling noise"
- Cross-modal alignment: The degree to which representations across modalities (e.g., vision and language) correspond. "multimodal scaling inherits shallow cross-modal alignment"
- Continual learning: Training paradigm that incrementally incorporates new data while trying to retain prior knowledge. "retrieval-augmented generation (oracle access), continual learning (adaptive capacity expansion), and constraint-based decoding"
- Description length: The amount of information required to encode a model or data; finite limits imply compression error. "finite description length enforces compression error"
- Diagonalization: A construction showing no single model class can be correct on all inputs by adversarially defining failures. "diagonalization guarantees inputs on which some model must fail"
- Direct Preference Optimization (DPO): A preference-based training method optimizing models to align with human choices. "reinforcement learning from human feedback (RLHF) or direct preference optimization (DPO)"
- Distributional shift: Mismatch between training and deployment input distributions that degrades performance. "The distributional shift can be quantified via the KL divergence:"
- Encoding attenuation: Weakening of positional/content encoding effectiveness over long contexts. "encoding attenuation"
- Epistemic pitfalls: Failure modes arising from limitations in knowledge representation or uncertainty handling. "epistemic pitfalls"
- Epistemic uncertainty: Uncertainty due to lack of knowledge that could, in principle, be reduced with more information. "epistemic uncertainty (what they don't know) versus aleatoric uncertainty (inherent ambiguity)."
- Exposure bias: Training–inference mismatch where models never see their own errors during training, causing error compounding at test time. "This exposure bias means the model never experiences its own errors during training, leading to compounding mistakes at test time"
- Gradient decay: Reduction of gradient signal at distant positions, impeding learning over long contexts. "Gradient decay at rare positions, vanishing sinusoidal/RoPE overlap, and logarithmic score-margin growth show"
- Halting Problem: The undecidable problem of determining whether an arbitrary program halts on an input. "The canonical example is the Halting Problem"
- Hierarchical attention: Attention mechanisms organized in multi-level structures to scale to long contexts. "sparse or hierarchical attention"
- Information-theoretic: Pertaining to limits and measures from information theory that bound learnability and accuracy. "information-theoretic and statistical constraints bound attainable accuracy"
- Inverse temperature: Scaling factor in softmax-based policies controlling determinism versus exploration. "where is the inverse temperature."
- Kolmogorov complexity: The length of the shortest program that outputs an object; a measure of intrinsic complexity. "Let be an LLM with Kolmogorov complexity ."
- Kullback-Leibler (KL) divergence: A measure of discrepancy between two probability distributions. "The Kullback-Leibler (KL) divergence term penalizes models"
- Latent manifolds: Low-dimensional structures in representation space on which data embeddings lie. "misaligned latent manifolds"
- Length bias: Tendency of evaluators (including LM judges) to favor longer answers regardless of correctness. "LM judges are susceptible to length bias, favoring longer responses even when they contain errors"
- Likelihood-based training: Optimization using next-token log-likelihood, which can prioritize pattern completion over reasoning. "likelihood-based training favors pattern completion over inference"
- LM-as-judge evaluation: Using a LLM to grade outputs of other models. "LM-as-judge evaluation, where another LLM grades outputs."
- Long-tail distribution: Skew where many items (e.g., facts/entities) appear rarely, challenging memorization and generalization. "Long-tail distribution and memorization failures."
- Miscalibration: Systematic mismatch between predicted confidence and actual accuracy. "Related to reward hacking is the issue of miscalibration: models systematically overestimate their correctness probability."
- Modality entropies: Differences in information content across modalities affecting learning dynamics. "Differing modality entropies"
- Mutual information: Measure of shared information between variables; used to quantify retrieval grounding. "mutual information with the target decays"
- Multimodal misalignment: Systematic mismatch between modalities within a joint model. "multimodal misalignment."
- Oracle access: Availability of an external, authoritative source during inference to answer queries. "retrieval-augmented generation (oracle access)"
- PAC learning (Probably Approximately Correct): Framework quantifying learnability via sample complexity and generalization bounds. "probably approximately correct (PAC) learning"
- PAC-Bayesian bounds: Generalization bounds incorporating a prior over models and posterior after training. "The PAC framework can be refined further through PAC-Bayesian bounds, which incorporate prior knowledge."
- Positional curricula: Training schedules that progressively extend or vary positional distributions to improve long-context learning. "bounded-oracle retrieval, positional curricula, and sparse or hierarchical attention."
- Positional under-training: Insufficient training signal at far positions, limiting effective context use. "positional under-training"
- Positional-encoding overlap: Interference from position encodings that become less distinguishable at long ranges. "positional-encoding overlap"
- Retrieval-augmented models: Models that incorporate external document retrieval to inform generation. "Retrieval-augmented models~\citep{lewis2020retrieval,borgeaud2022improvinglanguagemodelsretrieving} inherit theoretical fragilities"
- Reward hacking: Exploiting flaws in reward/evaluation to maximize scores in ways misaligned with true goals. "This creates a reward hacking dynamic"
- RoPE (Rotary Position Embeddings): Positional encoding scheme enabling relative position modeling in transformers. "vanishing sinusoidal/RoPE overlap"
- Sample complexity: Number of training examples required to learn a target function to desired accuracy. "long-tail factual knowledge requires prohibitive sample complexity"
- Score-margin: Difference between top and competing logits/probabilities; its growth affects separability. "logarithmic score-margin growth"
- Semantic drift: Gradual deviation from the intended meaning or target due to retrieval or generation noise. "suffers from semantic drift and coupling noise"
- Softmax crowding: Competition among many tokens in the softmax leading to diluted attention or decision margins. "softmax crowding"
- Sparse attention: Attention mechanisms that restrict token-to-token connections to reduce compute and improve focus. "sparse or hierarchical attention"
- Temporal staleness: Likelihood that facts have become outdated since the model’s training cutoff. "Define the temporal staleness of a fact as:"
- Token budgets: Limits on the number of tokens available for inputs, retrieval, or context windows. "bounded token budgets"
- Uncomputability: Existence of problems no algorithm can solve for all inputs. "uncomputability, which demonstrates that certain problems lie beyond the reach of any algorithm"
- Undecidability: Property of problems for which no algorithm can decide all instances correctly. "This contradicts the undecidability of the Halting Problem"
- Union bound: Probability bound stating that the chance any of multiple events occurs is at most the sum of their probabilities. "and applying a union bound over facts"
- Vapnik–Chervonenkis (VC) dimension: Capacity measure of hypothesis classes determining generalization behavior. "The Vapnik-Chervonenkis (VC) dimension is a measure of the complexity or capacity of a class of functions"
- VC inequality: Generalization bound relating empirical error, VC dimension, and sample size. "By the VC inequality, to achieve error at most on each fact"
Collections
Sign up for free to add this paper to one or more collections.