Inference-Optimal Vision-LLMs: Evaluating Visual Token Reduction and Model Scaling
Vision LLMs (VLMs) have seen significant progress in their capabilities, effectively bridging the gap between vision and language to handle diverse tasks that include both text and image inputs. However, real-world deployments, particularly on resource-constrained devices, face hurdles due to the computational costs associated with handling a large number of visual input tokens. Recent research has explored various strategies to alleviate this issue, including either downsizing the LLM or reducing the number of input image tokens. This paper investigates the optimal trade-off between these strategies using scaling laws to understand their impact on inference cost and performance.
Key Findings and Scaling Laws
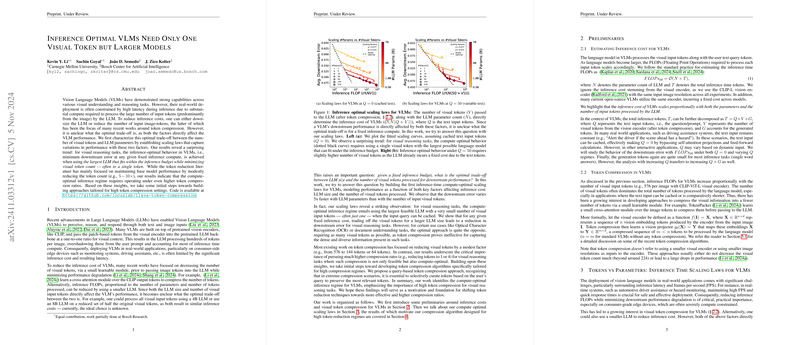
The paper reveals a counterintuitive insight for visual reasoning tasks: the inference-optimal regime involves using the largest LLM possible while minimizing the number of visual input tokens to the extent that often only one token is used. This finding contrasts with prior works that have limited their focus on modest token reduction (e.g., 5 to 10 times reduction). The authors establish scaling laws that show how the number of LLM parameters and visual tokens affect downstream performance. They observe that for a fixed inference compute budget, performance error changes five times more rapidly with LLM parameters than with visual input tokens, underscoring the relative importance of using larger LLMs versus retaining more visual tokens.
Practical Implications and Application Scenarios
The implications of these findings are multifaceted: for environments where text input can be cached (eliminating the cost associated with text tokens in inference), it is advantageous to prioritize expanding LLM size while drastically compressing visual token input. This approach proves beneficial for visual reasoning tasks, but exceptions are noted in specific applications such as Optical Character Recognition (OCR) or document understanding. In these instances, the retrieval of dense and varied visual information necessitates maintaining a larger number of visual tokens, as token compression in these contexts is less effective.
Novel Contributions and Future Directions
This work also introduces an initial exploration of tailoring token compression algorithms for high-compression regimes. The authors propose a query-based token compression approach, recognizing that in scenarios with extreme compression, it is crucial to selectively retain tokens pertinent to the user's query. They report promising results on various benchmarks, achieving competitive performance levels even at substantial compression rates.
The paper's contribution indicates a shift in the focus for future research from merely matching base model performance with moderate token reductions to embracing extreme token compression coupled with larger model scaling. This redirection could ignite the development of advanced token reduction techniques adept at handling extreme compression without significant loss of information quality.
Concluding Remarks
The authors provide a compelling argument for revisiting existing strategies for deploying VLMs with computation constraints, especially on edge devices. By establishing scaling laws that link inference efficiency with visual token compression and LLM scaling, the paper sets a foundation for informed decision-making in optimizing VLM architectures. The results invite further exploration into advanced token compression methodologies that can operate robustly under extreme conditions, potentially opening new avenues for both theoretical advancements in model scaling and practical innovations in diverse application environments. The research propels a nuanced recalibration of approaches in visual token handling, aligning with the growing demand for efficient yet powerful VLMs in real-world uses.