- The paper demonstrates that LLMs approximate Bayesian inference when provided with enough in-context coin flip examples.
- It quantifies model priors through controlled experiments and shows that instruction tuning partially mitigates bias miscalibration.
- It finds that LLMs perform local Bayesian updating using a discounted filter, emphasizing recent evidence over older data.
Bayesian Behavior in LLMs via In-Context Learning: An Analysis of "Enough Coin Flips Can Make LLMs Act Bayesian"
Introduction
"Enough Coin Flips Can Make LLMs Act Bayesian" (2503.04722) presents a systematic investigation into whether LLMs perform structured probabilistic reasoning—specifically Bayesian inference—when exposed to in-context learning (ICL) demonstrations. The study leverages controlled stochastic processes, primarily biased coin flips, to precisely quantify the alignment between LLM predictions and normative Bayesian updates. The work addresses the critical question of whether LLMs' apparent generalization in ICL is a result of pattern matching or if it reflects genuine probabilistic updating consistent with Bayesian principles.
Experimental Framework and Methodology
The authors design a suite of experiments using open-source LLMs (e.g., Llama-3.1, Gemma-2, Phi-3.5, Mistral-7B, OLMoE, and the Pythia Scaling Suite) and their instruction-tuned variants. The core experimental paradigm involves:
- Extracting Model Priors: Models are prompted with 50 variants of coin-flip queries to estimate their implicit prior over the Bernoulli parameter θ (probability of heads).
- Explicit Biasing: Prompts include explicit statements about coin bias to test whether LLMs can override their priors with direct instructions.
- In-Context Learning (ICL): Models are provided with sequences of coin-flip outcomes as demonstrations, and their posterior predictions are compared to the Bayesian posterior.
- Scaling Analyses: The impact of model size and instruction tuning on prior calibration and ICL performance is systematically evaluated.
- Attention Analysis: The relationship between attention allocation to in-context examples and the quality of Bayesian updates is empirically assessed.
The primary evaluation metric is the total variation distance (TVD) between the model's predicted distribution and the true Bayesian posterior.
LLM Priors and the Challenge of Calibration
The initial analysis reveals that all evaluated LLMs encode a strong prior bias toward "heads" in the coin-flip task, with some models assigning up to 70% probability to heads even in the absence of evidence.
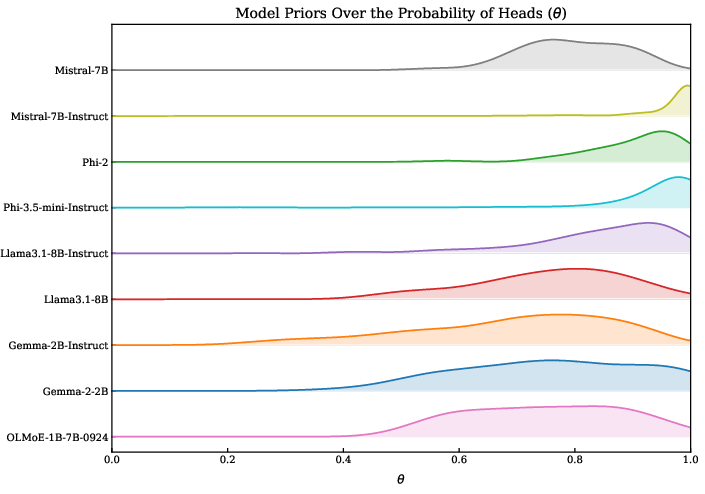
Figure 1: All LLMs evaluated present a bias towards heads.
This prior bias is robust to prompt variation and is only weakly mitigated by explicit biasing instructions in the prompt. Non-instruct models largely ignore explicit bias statements, while instruction-tuned models show improved, but still imperfect, alignment—especially at the extremes (0% or 100% heads).
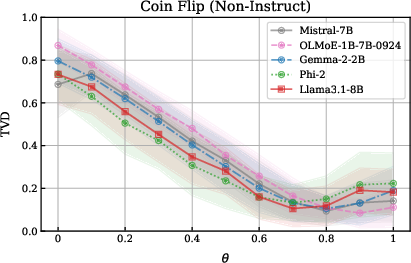
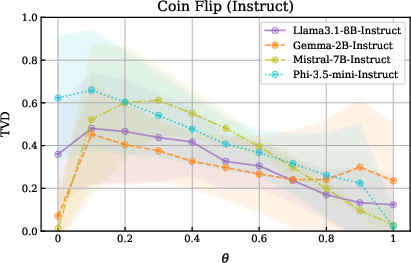
Figure 2: Non-instruct models ignore biasing instructions and default to a heads-biased distribution; instruct models attend to biasing information and perform better at extreme biases.
Scaling model size (from 70M to 12B parameters) does not substantially improve prior calibration or the ability to model arbitrary biased distributions, although the relative ordering among different biases shifts with scale.
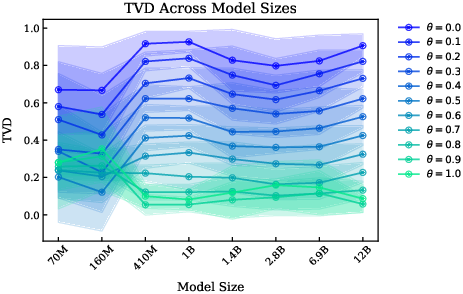
Figure 3: Model size does not significantly affect TVD for a given bias, but the relative ordering among biases shifts as model size increases.
In-Context Learning as Bayesian Updating
The central finding is that, when provided with sufficient in-context demonstrations of coin flips, LLMs' posterior predictions converge toward the Bayesian posterior, even when their initial priors are miscalibrated. The improvement in TVD is substantial with as few as three in-context examples, but even with 100 examples, models do not achieve perfect alignment with the true posterior.
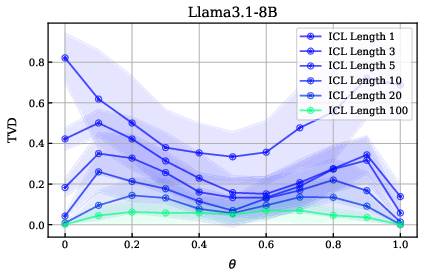
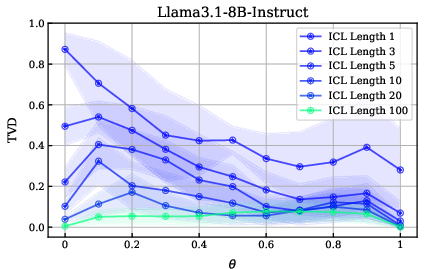
Figure 4: Increasing the number of in-context examples improves model alignment with the true distribution, but even 100 examples do not fully close the gap.
Instruction tuning enhances the ability to utilize in-context evidence, but the effect of model size on ICL performance is negligible or even negative at the largest scales.
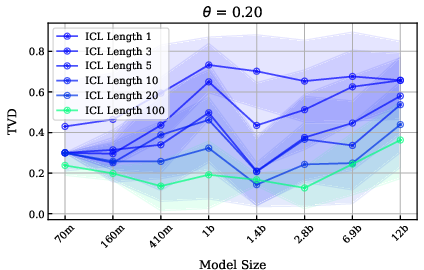
Figure 5: Model size does not have a clear impact on the benefits from ICL; larger models can perform worse.
Dynamics of Posterior Updates and Local Bayesian Filtering
To probe the nature of the update process, the authors analyze model predictions in a non-stationary environment where the underlying coin bias shifts mid-sequence. The trajectory of model predictions closely tracks the Bayesian posterior, but with a notable deviation: models behave as if they apply a discounted Bayesian filter, giving more weight to recent evidence and discounting older observations.
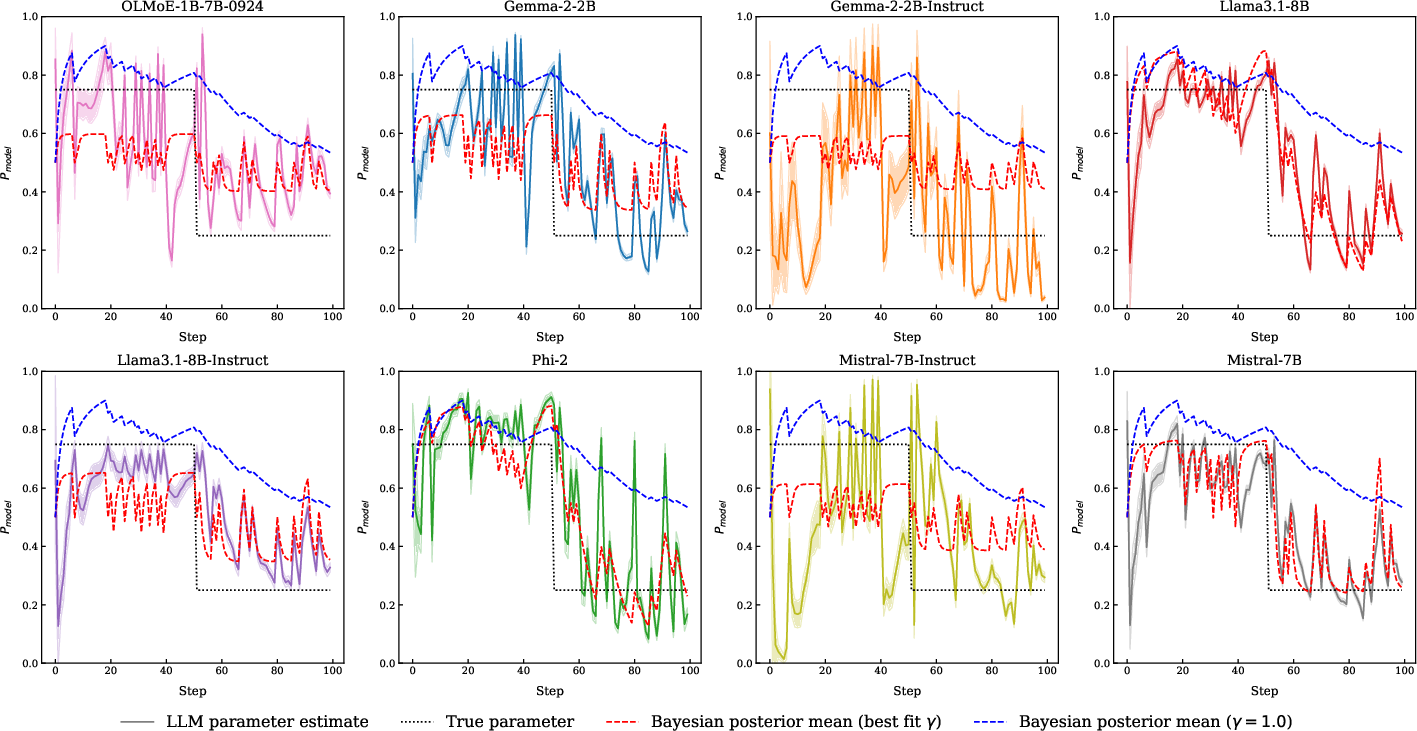
Figure 6: Model predictions align with Bayesian updates, but are better fit by a discounted Bayesian filter with a shorter time horizon.
This "local Bayesian" behavior is quantified by fitting an exponential decay parameter γ to the update process, revealing that instruction-tuned models tend to have shorter effective memory (lower γ), i.e., they are more responsive to recent evidence.
Attention Mechanisms and Update Quality
Contrary to some prior hypotheses, the magnitude of attention paid to in-context examples is uncorrelated with the extremity or quality of the model's point estimate under the Bayesian posterior.
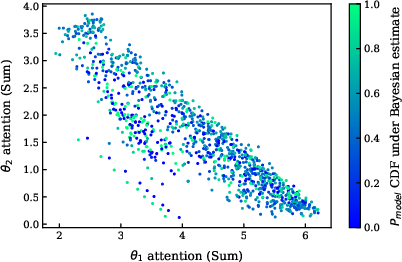
Figure 7: The extremity of the model point estimate under the Bayesian model appears uncorrelated with the attention.
Further, the fraction of attention assigned to specific segments of the prompt does not predict update performance.
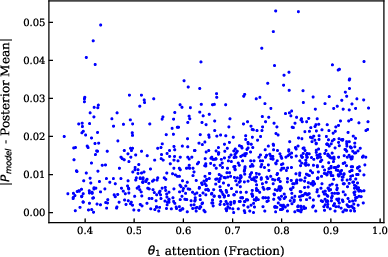
Figure 8: Relative attention to in-context examples does not directly predict update performance.
However, the model does modulate attention in a manner that reflects the informativeness of new evidence: when the number of samples from a new distribution is high, attention shifts accordingly, but this shift is not a direct driver of Bayesian update quality.
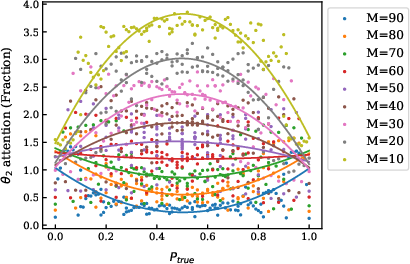
Figure 9: As the number of samples from a new distribution increases, the model pays more attention to those samples when they significantly influence the final distribution.
Extended Results: Robustness Across Models and Tasks
The study extends its findings to additional models and to a die-rolling task, confirming that the observed phenomena—miscalibrated priors, improvement with ICL, and local Bayesian updating—generalize across architectures and categorical stochastic processes.
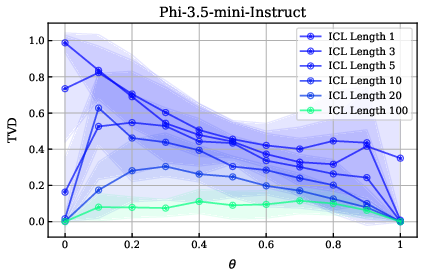
Figure 10: TVD vs. bias percentage for several ICL example lengths on the coin flipping task for the Phi-3.5-mini-instruct model.
Figure 11: TVD vs. bias percentage for several ICL example lengths on the coin flipping task for the Llama-3.1-8B-Instruct model.
Figure 12: TVD vs. bias percentage for several ICL example lengths on the coin flipping task for the Llama-3.1-8B model.
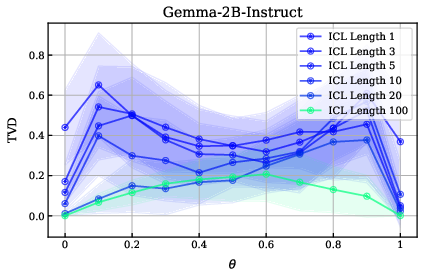
Figure 13: TVD vs. bias percentage for several ICL example lengths on the coin flipping task for the Gemma-2-2B-IT model.
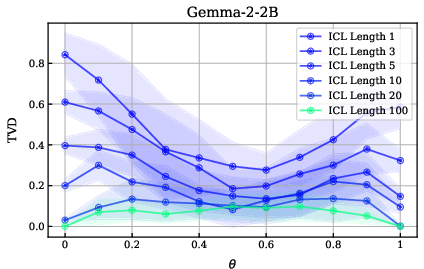
Figure 14: TVD vs. bias percentage for several ICL example lengths on the coin flipping task for the Gemma-2-2B model.
Implications and Theoretical Considerations
The results have several important implications:
- LLMs as Implicit Bayesian Agents: LLMs can approximate Bayesian inference in simple, controlled settings when provided with sufficient in-context evidence, despite having poorly calibrated priors.
- Limitations of Explicit Prompting: Direct instructions about the underlying distribution are largely ignored by non-instruct models and only partially effective for instruct models, highlighting the dominance of in-context evidence over explicit biasing.
- Scaling and Instruction Tuning: Model size does not guarantee improved probabilistic reasoning or ICL performance; instruction tuning is more effective for aligning model updates with Bayesian principles.
- Attention Is Not the Mechanism: The quality of Bayesian updating is not explained by attention magnitude, suggesting that the mechanism underlying ICL is not a simple function of attention allocation.
- Local Bayesian Updating: LLMs implement a form of Bayesian filtering with a finite memory, adapting quickly to recent evidence but discounting older data, which may be advantageous in non-stationary environments but suboptimal for stationary processes.
Limitations
The study is limited to discrete, categorical stochastic processes with known posteriors. The evaluation is restricted to open-source models where logits can be extracted, and the analysis does not extend to continuous or high-dimensional distributions. The findings may not generalize to more complex real-world probabilistic reasoning tasks, where prior calibration and hierarchical inference are critical.
Conclusion
This work provides a rigorous empirical foundation for understanding the probabilistic reasoning capabilities of LLMs under in-context learning. The primary limitation in LLMs' simulation of stochastic processes is the miscalibration of their priors, not a failure of Bayesian updating per se. With sufficient in-context evidence, LLMs can approximate Bayesian inference, but their updates are local and discount older evidence. These findings have direct implications for the use of LLMs as world models in simulation, planning, and agent-based modeling: reliable probabilistic reasoning requires either prior calibration or sufficient demonstration data. Future research should extend these analyses to more complex domains, explore methods for explicit prior calibration, and further dissect the mechanisms underlying ICL beyond attention-based explanations.

