Beyond the Black Box: Theory and Mechanism of Large Language Models
Abstract: The rapid emergence of LLMs has precipitated a profound paradigm shift in Artificial Intelligence, delivering monumental engineering successes that increasingly impact modern society. However, a critical paradox persists within the current field: despite the empirical efficacy, our theoretical understanding of LLMs remains disproportionately nascent, forcing these systems to be treated largely as ``black boxes''. To address this theoretical fragmentation, this survey proposes a unified lifecycle-based taxonomy that organizes the research landscape into six distinct stages: Data Preparation, Model Preparation, Training, Alignment, Inference, and Evaluation. Within this framework, we provide a systematic review of the foundational theories and internal mechanisms driving LLM performance. Specifically, we analyze core theoretical issues such as the mathematical justification for data mixtures, the representational limits of various architectures, and the optimization dynamics of alignment algorithms. Moving beyond current best practices, we identify critical frontier challenges, including the theoretical limits of synthetic data self-improvement, the mathematical bounds of safety guarantees, and the mechanistic origins of emergent intelligence. By connecting empirical observations with rigorous scientific inquiry, this work provides a structured roadmap for transitioning LLM development from engineering heuristics toward a principled scientific discipline.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making sense of how LLMs really work. Today, LLMs like ChatGPT and Gemini are great at answering questions and writing text, but to many researchers they still feel like “black boxes” — systems that work, but whose inner logic is hard to explain. The authors try to change that by organizing what we know into a clear roadmap. They split the life of an LLM into six stages (from gathering data to judging results) and use that structure to connect real-world successes with solid theory.
Think of it like turning a mystery recipe into a step-by-step cookbook: ingredients, cooking tools, cooking steps, seasoning to taste, serving, and taste-testing.
Key Questions the Paper Asks
To make LLMs less mysterious, the paper explores questions like:
- Data: What kinds of text should we collect, and how does mixing different sources help? Why does removing duplicates improve learning? How do we balance “remembering” exact text versus truly “understanding” and generalizing?
- Models: What can different model designs do in principle (their “power”), and what are their limits in real-life conditions (like finite memory and speed)?
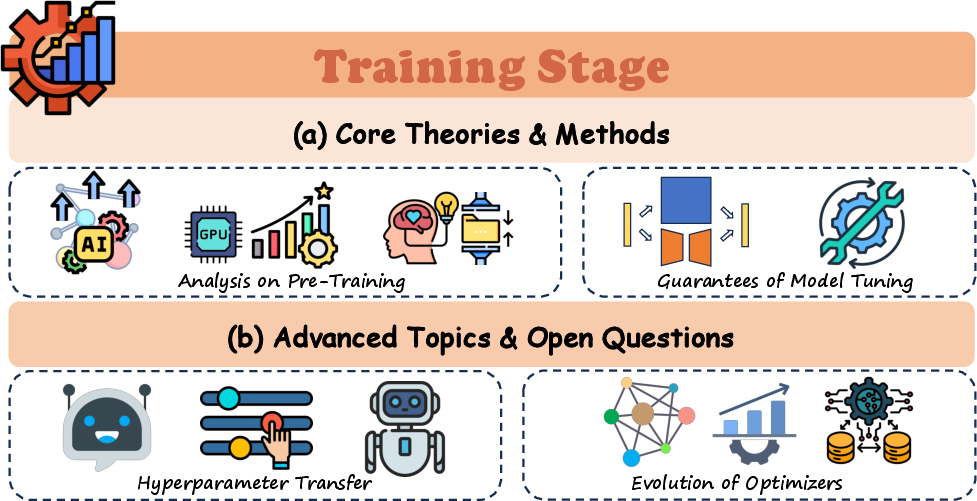
- Training and Alignment: How do training and “teaching” methods shape behavior, safety, and helpfulness?
- Inference and Evaluation: How should we run models and test them fairly, especially when test answers might accidentally be in the training data?
How the Researchers Approached the Topic
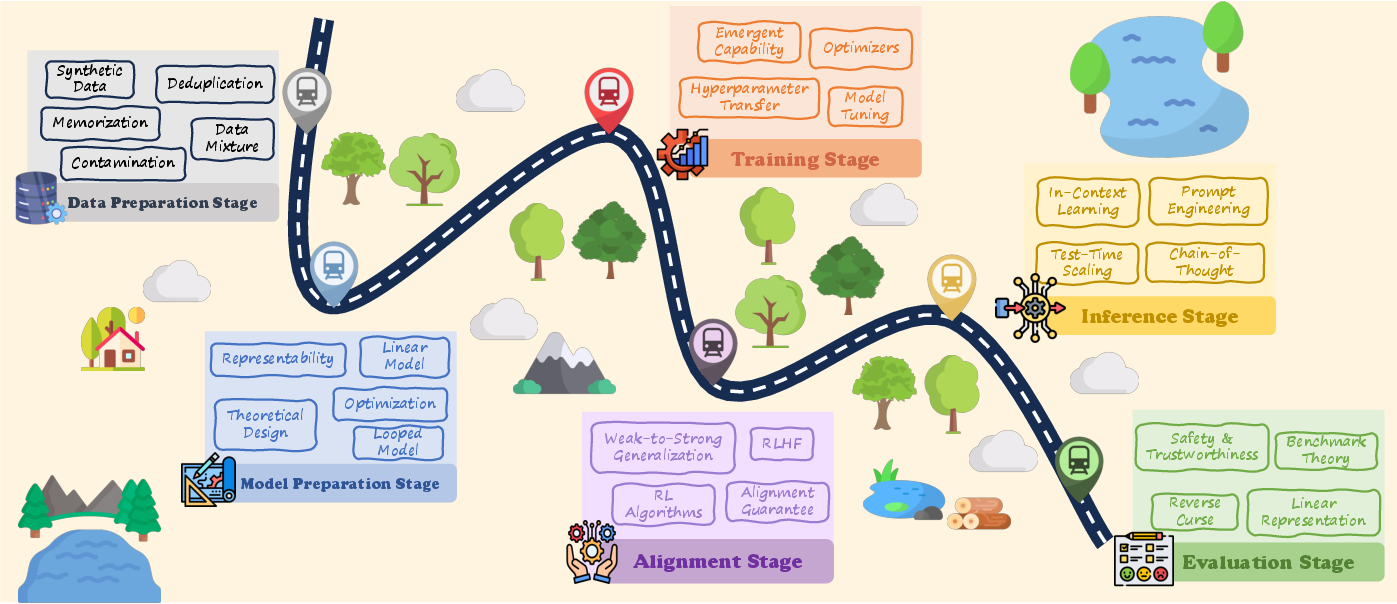
This is a survey paper, which means the authors read and organize many existing research studies rather than running one big new experiment. Their main move is to arrange the scattered theories into the six-stage lifecycle:
- Data Preparation (collecting and cleaning text)
- Model Preparation (choosing the architecture and starting settings)
- Training (teaching the model to predict the next word/token)
- Alignment (making the model helpful, safe, and honest)
- Inference (how the model answers questions at run-time)
- Evaluation (how we measure what the model can do)
They translate technical ideas into more understandable patterns. Here are some examples explained with everyday analogies:
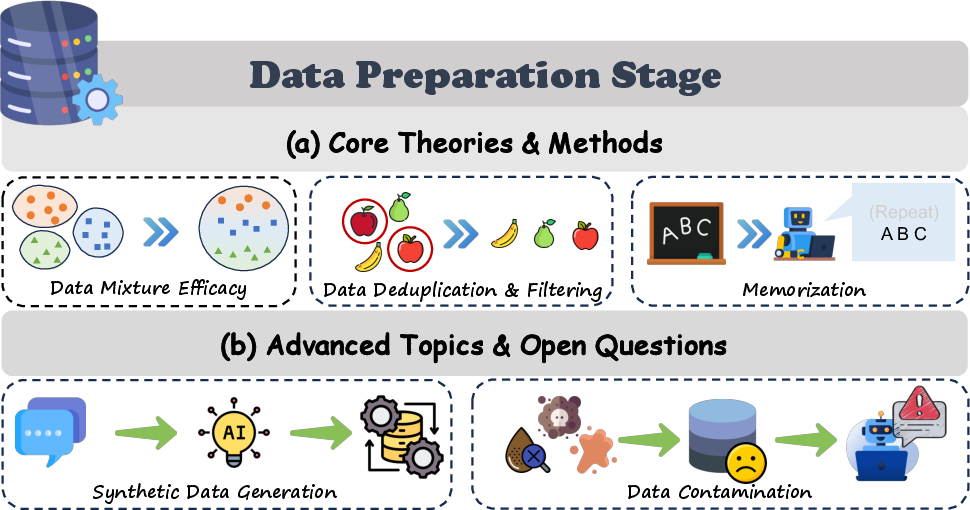
- Data mixtures: Like a balanced diet. Mixing books, web pages, code, and articles often teaches the model better than eating only one “food group.”
- Deduplication: Like not reading the exact same page 100 times. Removing duplicates or near-duplicates helps the model learn more broadly and reduces risky memorization.
- Memorization vs. generalization: Memorization is like cramming and recalling exact sentences. Generalization is like understanding the ideas so you can apply them in new situations. The paper shows this is a spectrum, not a simple on/off switch.
- Synthetic data: This is data generated by models themselves. It’s like writing your own practice questions. Helpful in some cases, but if you only study your own questions and stop reading real books, your knowledge can drift and degrade.
- Contamination: When test answers sneak into the training set. It’s like practicing with the exact test beforehand — you get a great score, but it doesn’t prove you truly learned.
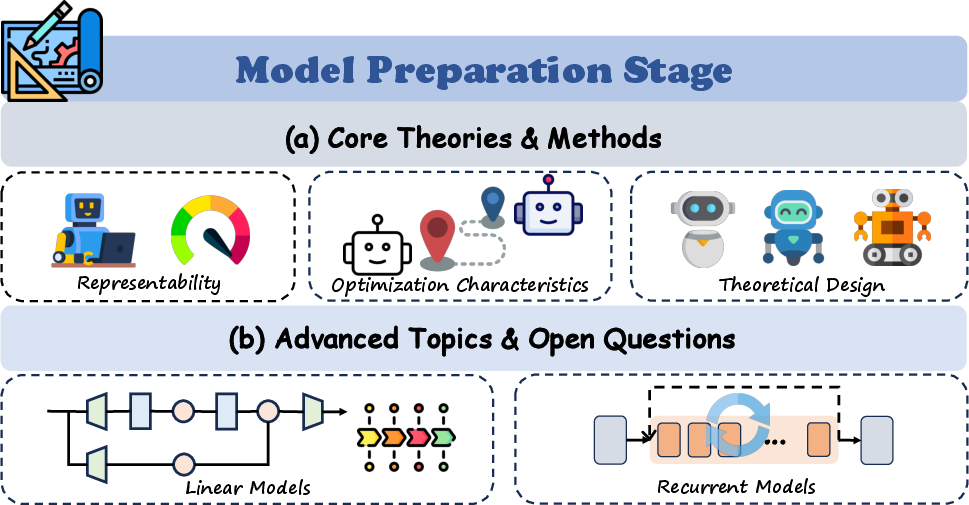
- Model “representability”: Asking what kinds of problems a model can solve in principle. For transformers, theory shows they can be extremely powerful, even “universal” in ideal conditions, but real-world limits (like precision and size) matter.
Main Findings and Why They Matter
Here are the main takeaways the authors highlight:
- A unified roadmap helps: Organizing research into six lifecycle stages clarifies how choices at each step affect the final model.
- Mixed data beats just “more data”: Carefully mixing different sources often improves performance more than simply increasing volume.
- Deduplication pays off: Removing duplicates cuts down on memorization, improves fairness in testing, and can speed up training.
- Memorization is more complex than copy-paste: Models can stitch together similar fragments (“mosaic memory”), and memorization tends to grow with model size unless actively managed.
- Predicting good data mixes is possible: “Data mixing laws” and related models can forecast how changing the recipe (proportions of sources, training steps) affects performance, saving time and money.
- Synthetic data is useful but risky: If you replace real data with only synthetic data, performance can collapse over generations (“copy of a copy” gets blurrier). Adding synthetic data on top of real data is much safer.
- Contamination can fake strong results: Accidentally training on test content can massively inflate scores. New methods can detect this, but avoiding it remains challenging.
- Transformers are powerful with limits: In perfect math worlds, they can do almost anything. In reality, constraints like finite precision, depth, and width create boundaries. Theory helps set expectations and guide smarter designs.
These findings matter because they shift LLM building from trial-and-error toward principled choices. That leads to models that are more capable, fair, and safe.
What This Could Mean for the Future
- Better data practices: Using theory-guided data mixing, smart deduplication, and careful contamination checks can make models more reliable and reduce privacy risks.
- Smarter model design: Understanding what architectures can and can’t do helps engineers choose designs that fit the task and the budget, avoiding dead ends.
- Honest evaluations: Stronger contamination detection keeps test scores meaningful, so we know when a model really understands versus just remembers.
- Safer alignment: Clearer math for alignment and safety can set real bounds on what models are allowed to do and how they avoid harmful outputs.
- A path beyond the “black box”: By connecting everyday engineering wins with theories, the field moves closer to building AI on solid scientific foundations. That’s essential if we want future systems to be trustworthy and, eventually, to reach more general forms of intelligence.
In short, this paper offers a guide to turning powerful but mysterious LLMs into understandable, controllable, and steadily improving tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of unresolved issues the paper surfaces but does not fully resolve across the lifecycle of LLMs.
- Data quality and information density: Provide a formal, operational definition of “data quality” and “information density” for heterogeneous, non-i.i.d. web-scale corpora, and derive generalization bounds that explicitly depend on these quantities rather than heuristic proxies.
- Extending classic learning theory: Develop a unified extension of statistical learning theory that handles multi-source, non-i.i.d. mixtures with heavy-tailed, long-range dependencies typical of web text, including tight bounds that reflect source overlap, semantic diversity, and deduplication.
- Domain mixture identifiability: Establish methods and error guarantees for latent domain discovery (unknown K) in data mixing laws; analyze identifiability and stability of domain parameters when validation sets are themselves mixtures or contaminated.
- Theory behind mixing laws: Connect empirical “data mixing laws” (and BiMix) to principled derivations from distribution shift or multi-task learning theory, including conditions under which fitted parameters extrapolate across scales, architectures, and training schedules.
- Optimization strategy equivalence: Characterize when REGMIX, UtiliMax, DoReMi, and bilevel optimization are provably equivalent or superior; provide convergence guarantees, sample complexity requirements, and robustness analyses under realistic LLM training noise and non-stationarity.
- Bilevel optimization at scale: Give first-order bilevel optimization algorithms formal convergence rates and regret bounds for LLM-scale settings, explicitly accounting for truncated inner loops, stale gradients, and computational constraints.
- Deduplication trade-offs: Quantify the theoretical trade-off between hard deduplication and soft reweighting (SoftDedup), including provable bounds on information loss, rare-phenomena coverage, and downstream generalization under different similarity metrics (syntactic vs semantic).
- Semantic similarity metrics: Formalize and validate semantic deduplication criteria (embedding-based) with guarantees on near-duplicate detection accuracy, false positives/negatives, and impact on model privacy and memorization risk.
- Privacy guarantees via dedup: Move beyond empirical reductions to develop formal privacy risk bounds that relate sequence-level repetition, deduplication strength, and adversarial extraction success probabilities.
- Memorization-generalization calculus: Provide a unified theory that links mosaic memory, adversarial compression ratio (ACR), scaling laws of fact memorization, and entropy-memorization observations to specific training dynamics and architecture properties.
- Black-box memorization detection: Establish the statistical power, false-positive/negative rates, and robustness of black-box memorization detectors (e.g., PEARL) under adversarial prompts, post-training alignment, and output obfuscation.
- Memorization sinks guarantees: Prove that “memorization sinks” isolate and remove memorized content without degrading general language ability; specify conditions and architecture-agnostic mechanisms that guarantee no collateral damage.
- Synthetic data information gain: Formalize the “reverse-bottleneck” framework with measurable information gain criteria, and derive bounds that predict when synthetic data improves generalization versus amplifies spurious correlations.
- Collapse-free synthetic workflows: Build a dynamical systems model of training distribution drift to derive precise thresholds and schedules (ratio, curriculum, mixing strategies) that prevent model collapse under “accumulate” vs “replace” workflows.
- Subjective data synthesis limits: Theorize why synthetic data underperforms for high-subjectivity tasks; define diversity/subjectivity metrics, and derive target distributions and sampling schemes that restore performance parity with human data.
- Contamination taxonomy and metrics: Create standardized, quantitative contamination metrics (including approximate/noisy contamination), with thresholding rules that correlate with evaluation inflation across task types and model sizes.
- Post-alignment contamination detection: Provide reliable contamination detection protocols after RLHF or policy optimization (where likelihood signals vanish), including formal criteria for “policy collapse” and entropy-based diagnostics.
- Automated corpus auditing: Design scalable, provably sound corpus auditing systems that combine embedding drift (KDS), targeted queries (name cloze), and document provenance to continuously monitor and mitigate pretraining contamination.
- Benchmark integrity under scale: Establish methodologies to construct and maintain contamination-resilient benchmarks (e.g., strict release post cut-off, adversarial variants) and quantify how contamination skews perceived reasoning vs memorization.
- Transformer expressivity under constraints: Bridge infinite-precision/Turing-complete results to finite-precision, bounded depth/width settings with tight upper and lower bounds for tasks representative of LLM workloads (hierarchical, algorithmic, long-context).
- Conditions for efficient approximation: Validate and refine Jackson-type bounds by specifying real-world conditions (e.g., low-rank temporal dependencies) and diagnostic tests to verify when Transformers “approximate efficiently.”
- Depth lower bounds and separations: Complete lower-bound characterizations that separate tasks solvable with O(1) depth from those requiring super-constant depth, and relate these to known circuit complexity classes and attention patterns.
- Interpretability vs capability: Develop a global interpretability framework consistent with provable behavior (addressing “myopic analysis is misleading”) that explains learned attention patterns in bounded-Dyck and other structured tasks.
- Tokenization and initialization theory: Provide principled analyses of how tokenization granularity, subword choices, and parameter initialization schemes affect expressivity, optimization dynamics, and emergent abilities in large-scale language modeling.
- Efficiency–representation trade-offs: Derive formal limits for linear/recurrent/weight-tied architectures (sub-quadratic attention proxies) identifying tasks and conditions where efficiency gains necessarily induce representational bottlenecks or reasoning failures.
- Cross-stage theoretical integration: Construct a unified, testable theory that connects data preparation, model architecture, training dynamics, alignment objectives, and inference-time behaviors to explain emergent phenomena (ICL, scaling laws, “aha” moments) with predictive power.
Practical Applications
Overview
Below are practical applications derived from the paper’s lifecycle-based framework and the reviewed theories and mechanisms (Data Preparation, Model Preparation, Training, Alignment, Inference, Evaluation). Each item notes sectors, deployment potential, emergent tools/workflows, and key assumptions or dependencies. Applications are grouped as Immediate Applications (deployable now) and Long-Term Applications (requiring further research, scaling, or development).
Immediate Applications
- Optimized data-mixture design for domain-specific LLMs
- Sectors: software, healthcare, finance, legal, education
- What: Use data-mixing laws and optimization strategies (REGMIX, UtiliMax, DoReMi, bilevel optimization like DOGE/ScaleBIO) to tune pretraining/finetuning corpora for target domains (e.g., oncology, AML compliance, tax codes).
- Workflow: Fit data-mixing laws on small-scale experiments; deploy a sampling optimizer that balances utility, diversity, and scale to set per-source sampling weights; monitor validation loss per domain over training.
- Tools: “Data Mix Optimizer,” “Portfolio-style Sampler,” “Generalization-Focused Bilevel Sampler”
- Assumptions/Dependencies: Rank-invariance and cross-scale transfer hold; access to representative domain datasets; model capacity sufficient to exploit shared structure across sources.
- GPU-accelerated deduplication and soft reweighting to reduce training cost and over-memorization
- Sectors: software/data platforms, content moderation, cloud ML ops
- What: Adopt FED-style MinHash LSH on GPUs for scalable dedup; complement with semantic dedup (D4) and SoftDedup reweighting to down-weight common content and up-weight rare/diverse content.
- Workflow: End-to-end dedup pipeline integrated into data ingestion; semantic clustering via embeddings; dynamic sampler adjusts example weights (soft dedup) rather than discarding.
- Tools: “GPU Dedup Engine,” “Semantic Diversity Selector,” “Soft-Weighted Data Sampler”
- Assumptions/Dependencies: Availability of GPU resources and high-quality embedding models; well-chosen similarity thresholds to avoid excessive information loss; measurable benefits validated via downstream metrics.
- Privacy risk mitigation through memorization audit and control
- Sectors: healthcare (PHI), finance (PII), government, consumer platforms
- What: Reduce duplication-driven memorization; instrument PEARL-based detection (perturbation sensitivity), adversarial compression prompts (ACR), and integrate “memorization sinks” to localize and remove memorized content without degrading general capabilities.
- Workflow: Periodic memorization audits on sensitive corpora; retraining/finetuning with deduplicated sequences; neuron-level sink activation for isolating content; compliance logging.
- Tools: “Memorization Auditor,” “PII/PHI Leak Monitor,” “Sink-Based Mitigation Toolkit”
- Assumptions/Dependencies: Access to training pipelines; reliable detection accuracy; retraining budget; organizational privacy policies aligned with legal standards (e.g., GDPR, HIPAA).
- Evaluation integrity and benchmark hygiene
- Sectors: academia (NLP/ML benchmarks), model vendors, third-party evaluators
- What: Detect and prevent data contamination (KDS representation-shift measurement, TS-Guessing protocols, name-cloze queries; Self-Critique post-RLHF).
- Workflow: Pre-release benchmark audits; pretraining canyon scans for overlap; post-RLHF entropy-based policy collapse checks; periodic benchmark refresh targeting post-cutoff problems.
- Tools: “Contamination Auditor,” “Benchmark Integrity Scanner,” “Post-RLHF Self-Critique Probe”
- Assumptions/Dependencies: Access to model representation space or probe APIs; crawl provenance; ability to modify evaluation sets; coordination with benchmark maintainers.
- Controlled use of synthetic data in data-scarce domains
- Sectors: specialized technical education (STEM tutors), medical subfields, legal subdomains, code reasoning
- What: Adopt “accumulate” workflow to mix synthetic data with real data, keep synthetic ratio below empirically safe thresholds; use RL-on-incorrect-responses to debias spurious correlations (e.g., math reasoning); apply information-gain checks (reverse-bottleneck framing) to avoid collapse.
- Workflow: Synthetic data planner validates domain coverage gaps; additive mixing with real data; targeted RL for error-correction; continuous monitoring for diversity, entropy, and performance deltas.
- Tools: “Synthetic Data Planner,” “Error-Correction RL Toolkit,” “Collapse Risk Monitor”
- Assumptions/Dependencies: Base model can generate non-trivial new information; robust diversity metrics; access to real seed data; careful ratio management aligned with stability findings.
- Architecture selection guided by representability insights
- Sectors: software, embedded systems, edge AI
- What: Use theoretical bounds to select architectures for target tasks (e.g., Transformers for low-rank temporal dependencies; Universal Transformers or weight-tied recurrent variants for finite precision and iterative reasoning; shallow Transformers for automata-like tasks).
- Workflow: Architecture Decision Records (ADR) incorporate representability and complexity constraints; task analysis for structural properties (hierarchy, depth bounds, state-machine behavior).
- Tools: “Theory-Backed ADR Templates,” “Task–Architecture Match Evaluator”
- Assumptions/Dependencies: Clear task characterization; performance targets versus compute budgets; acceptance of trade-offs between expressivity and cost.
- Cost and efficiency gains in training pipelines
- Sectors: cloud ML ops, model vendors
- What: Combine dedup, soft reweighting, and mixture optimization to reduce tokens processed for equivalent quality; target faster convergence and lower compute spend.
- Workflow: Pretraining pipeline refactor with dedup checkpoints; periodic sampler re-calibration; track loss-per-token and wall-time-to-milestones.
- Tools: “Cost-to-Quality Dashboard,” “Token Efficiency Optimizer”
- Assumptions/Dependencies: Measurable KPIs; reproducible experimental setups; compute accounting.
- Copyright and content provenance checks
- Sectors: publishing, content platforms, legal compliance
- What: Name-cloze and targeted memory excavation to identify memorized copyrighted material; adjust training sets and model policies to avoid infringing outputs.
- Workflow: Periodic provenance audits; content filters and refusals; legal review pipelines.
- Tools: “Copyright Memory Scanner,” “Provenance Compliance Manager”
- Assumptions/Dependencies: Access to model outputs; legal cooperation; clear takedown/remediation processes.
- End-user reliability improvements
- Sectors: consumer apps, enterprise chatbots
- What: Integrate contamination audits and memorization controls to reduce misleading “stored answers” and privacy leaks; improve trust with better evaluation hygiene and dataset quality.
- Workflow: Release gates tied to contamination and memorization metrics; user-facing transparency notes (training cutoff, data sources).
- Tools: “Release Compliance Checklist,” “Trust & Safety Metrics Panel”
- Assumptions/Dependencies: Organizational buy-in; standardization of release criteria; monitoring integrated into MLOps.
Long-Term Applications
- Self-improving LLMs with theoretical stability guarantees
- Sectors: software, education, research tooling
- What: Establish principled synthetic data loops guided by information-gain metrics (reverse-bottleneck), collapse-aware accumulation policies, and automated diversity/entropy maintenance.
- Potential products: “Self-Improvement Orchestrator,” “Information-Gain Meter,” “Synthetic Diversity Guardian”
- Assumptions/Dependencies: Reliable estimation of information gain; robust diversity metrics; sustained availability of real data seeds; better mechanistic understanding of collapse dynamics.
- Standards and certification for evaluation integrity and privacy
- Sectors: policy/regulatory bodies, standards organizations, enterprise governance
- What: Formal guidelines for contamination detection, benchmark refresh cadence, memorization audits, and acceptable synthetic-to-real ratios; certification labels for “Contamination-Minimized,” “Privacy-Audited.”
- Potential products: “Contamination Risk Index,” “Memorization Compliance Certificate,” “Synthetic Ratio Standards”
- Assumptions/Dependencies: Multi-stakeholder consensus; auditing infrastructure; enforceable disclosure practices.
- Automated data procurement and curation markets
- Sectors: data marketplaces, enterprise data strategy
- What: Portfolio-optimization-based data purchasing/sourcing platforms that quantify utility/diversity/scale; bilevel pipelines that continuously optimize mixture weights against held-out generalization targets.
- Potential products: “Data Portfolio Manager,” “Curation-as-a-Service”
- Assumptions/Dependencies: Reliable per-source utility estimation; interoperability and provenance tracking; robust validation frameworks.
- Continual benchmark renewal and resilience
- Sectors: academia, third-party evaluators, model vendors
- What: Systems that automatically identify contaminated tasks, generate post-cutoff replacements, and test medium-to-hard generalization under strict novelty constraints.
- Potential products: “Benchmark Refresh Engine,” “Novelty Enforcer”
- Assumptions/Dependencies: Access to post-cutoff content pools; content authoring pipelines; stable novelty detection metrics.
- Privacy-preserving training protocols integrating memorization sinks and differential privacy
- Sectors: healthcare, finance, public-sector AI
- What: Combine sink-based memorization control with DP guarantees to reduce leakage risks while maintaining utility; standardized audits embedded in training cycles.
- Potential products: “Private-Training Suite,” “Leak-Resilient Finetuning”
- Assumptions/Dependencies: Advances in sink targeting precision; DP parameter tuning that preserves model utility; legal frameworks recognizing such protections.
- Architecture innovations for efficiency–expressivity trade-offs
- Sectors: edge AI, robotics, AR/VR
- What: Practical weight-tied recurrent models for iterative reasoning under finite precision; linear/attention hybrids with sub-quadratic compute while preserving key representational properties.
- Potential products: “Iterative Reasoner on Edge,” “Sub-Quadratic Transformer Variants”
- Assumptions/Dependencies: Continued theory on lower/upper bounds under realistic constraints; hardware co-design; training stability on new paradigms.
- Mechanistically bounded safety and alignment guarantees
- Sectors: AI safety, governance
- What: Formal bounds on safety objectives and alignment algorithms; integration into alignment pipelines with verifiable guarantees (e.g., limits on unsafe generations or misgeneralization).
- Potential products: “Safety Bounds Monitor,” “Alignment Guarantee Reporter”
- Assumptions/Dependencies: Mature theoretical frameworks for safety limits; accepted risk metrics; scalable verification methods.
- Enterprise-grade lifecycle orchestration based on the six-stage taxonomy
- Sectors: software, ML ops
- What: End-to-end governance platforms that enforce stage-specific quality gates (Data Preparation → Model Preparation → Training → Alignment → Inference → Evaluation), with audit trails and reproducible metrics.
- Potential products: “LLM Lifecycle Orchestrator,” “Stage-Gated MLOps”
- Assumptions/Dependencies: Organizational adoption; integration with existing pipelines; shared metrics taxonomy.
- Consumer-facing trust indicators
- Sectors: daily-life apps, education, healthcare chatbots
- What: User-visible badges/indicators signaling contamination audits, privacy-protective training, and benchmark integrity; clearer disclosures to improve informed usage.
- Potential products: “AI Trust Badge,” “Data Source Disclosure Widget”
- Assumptions/Dependencies: Standardization across vendors; consumer education; third-party verification.
These applications operationalize the survey’s unified lifecycle framework and the reviewed theory (data mixture efficacy, deduplication and soft reweighting, memorization and privacy, synthetic data stability, contamination detection, and representability-guided architecture selection). They provide immediate levers for industry and academia to improve quality, integrity, and efficiency, while outlining long-term pathways for robust self-improvement, governance, and safety.
Glossary
- Adversarial Compression Ratio (ACR): An adversarial metric for judging whether a training sequence is memorized by checking if it can be elicited from a prompt much shorter than the sequence itself; used to assess privacy and compliance risks. "proposing the ``Adversarial Compression Ratio'' (ACR)~\cite{schwarzschild2024rethinking}."
- Alignment Stage: The phase in an LLM lifecycle focused on aligning model outputs with human preferences or safety constraints, often via specialized optimization or feedback methods. "Alignment Stage, Inference Stage, and Evaluation Stage."
- AGI: A hypothetical level of machine intelligence capable of understanding, learning, and performing any intellectual task a human can. "the quest for AGI necessitates a balanced synergy where continuous theoretical research and rigorous engineering implementation are recognized as equally indispensable pillars."
- Amortized intrinsic dimensionality: In multi-task learning, the effective number of additional parameters needed per task beyond a shared representation, often much smaller than learning each task independently. "In MTL, the amortized intrinsic dimensionalityâthe number of additional parameters needed per task on top of a shared representationâis significantly smaller than what is required to learn each task from scratch."
- BiMix: A bivariate predictive law modeling how per-domain validation loss scales with both the domain’s data proportion and total training steps. "This concept was further refined by BiMix~\cite{ge2024bimix}, which proposes a more granular bivariate law."
- Bilevel Optimization: A nested optimization framework where outer-loop variables (e.g., data mixture weights) are optimized for generalization while an inner loop optimizes model parameters for training loss. "is Bilevel Optimization. This framework directly targets generalization by defining a nested objective: the outer loop optimizes the data source sampling weights to minimize validation loss, while the inner loop finds the optimal model parameters that minimize training loss given those weights."
- Bracketing number: A measure of the complexity of a function class (or distribution space) used to bound estimation error; smaller bracketing numbers imply better learnability. "They establish a general distribution estimation error bound (Theorem 3.2) based on the bracketing number:"
- C4 dataset: A large-scale cleaned web text corpus widely used in NLP pretraining, known to contain benchmark contamination in some cases. "confirm that the C4 dataset~\citep{10.5555/3455716.3455856} contains contaminated examples from NLP benchmarks."
- Circuit complexity: A theoretical framework analyzing the minimal circuit size or depth required to compute a function or solve a problem, used to derive expressivity lower bounds. "lower bounds that characterize the minimum circuit or communication complexity needed to solve computational tasks."
- Conditional generative modeling: Modeling the distribution of inputs given conditions (labels or contexts), used to analyze multi-source learning with formal error bounds. "offer a pioneering theoretical analysis of MSL within the framework of conditional generative modeling."
- Data contamination: The presence of evaluation benchmark samples in pretraining or fine-tuning data that artificially inflates reported performance and undermines generalization assessment. "Data contamination, the inadvertent inclusion of benchmark evaluation samples within the pre-training corpus, poses another critical open challenge in the data preparation stage."
- Data Deduplication: The removal of duplicate or near-duplicate examples from training corpora to improve generalization and reduce memorization and privacy risks. "The Benefits of Data Deduplication."
- Data mixing laws: Predictive relationships that map training data mixture proportions to validation losses across domains, enabling low-cost mixture optimization. "A significant breakthrough was the introduction of ``data mixing laws''~\cite{ye2024data}, which establish a predictable, functional relationship between the mixing proportions of training data and the model's validation loss on each domain."
- D4: A data selection framework that moves from syntactic to semantic deduplication, using embeddings to choose diverse, non-redundant documents. "The D4~\cite{tirumala2023d4} framework further evolved this concept."
- DOGE: A method employing bilevel optimization to tune data source weights for generalization, scalable to large models. "methods like DOGE~\cite{pmlr-v235-fan24e} and ScaleBIO~\cite{pan-etal-2025-scalebio}, is Bilevel Optimization."
- DoReMi: A data mixture optimization method that uses min-max objectives to minimize worst-case performance across domains for robustness. "DoReMi~\cite{xie2023doremi} leverages min-max optimization, formulating the objective as minimizing the worst-case performance across all data domains, thereby enhancing the model's robustness and uniformity."
- Dyck language (): A formal language of properly nested parentheses with k types, used to test hierarchical structure processing in models. "such as "
- Entropy-Memorization Law: A proposed empirical law stating that data entropy correlates linearly with memorization score—lower-entropy data is memorized more easily. "The ``Entropy-Memorization Law''~\cite{huang2025entropy} was proposed to investigate the inherent difficulty of memorizing data."
- FED: A scalable deduplication framework that accelerates MinHash LSH via reusable hashing and end-to-end GPU parallelization. "This mechanism-level bottleneck was addressed by frameworks like FED~\cite{son2025fed}, which introduces a reusable hash function with lower computational cost and performing end-to-end GPU parallel optimization for the entire MinHash LSH process, reducing tasks from weeks to hours."
- Finite precision: The realistic constraint that model computations use finite numerical precision, impacting expressivity results like Turing completeness. "show that standard finite-precision Transformers are not Turing complete"
- Finite-state automaton: A computational model with a finite number of states; shallow Transformers can simulate such automata for sequences of bounded length. "prove that a shallow Transformer with layers can exactly simulate any finite-state automaton processing a sequence of length "
- Hessian matrix: The square matrix of second-order partial derivatives; used in second-order optimization analyses but computationally prohibitive at LLM scale. "due to the need for second-order information (i.e., the Hessian matrix)"
- In-context learning (ICL): The ability of LLMs to learn tasks from a few examples provided in the input context without parameter updates. "in-context learning (ICL)~\citep{brown2020language}"
- Jackson-type approximation bounds: Classical approximation theory bounds adapted to Transformers, linking approximation efficiency to low-rank temporal dependencies. "derive explicit Jackson-type approximation bounds for Transformers"
- KDS: A contamination detection framework that measures changes in the similarity structure of embeddings before and after fine-tuning. "propose the KDS framework."
- Min-max optimization: An objective that minimizes the maximum loss across domains or adversaries to improve robustness. "leverages min-max optimization, formulating the objective as minimizing the worst-case performance across all data domains"
- MinHash LSH: A locality-sensitive hashing technique for efficiently detecting near-duplicates based on MinHash signatures. "Traditional CPU-based MinHash LSH~\cite{indyk1998approximate} implementations were too slow."
- Model Collapse: A degenerative process where repeated training on model-generated data reduces diversity and accuracy over generations. "The primary theoretical hurdle to recursive self-improvement is ``Model Collapse''."
- Mosaic Memory: A form of memorization where models recombine overlapping fragments rather than recalling exact sequences. "A foundational study introduced the concept of ``Mosaic Memory''~\cite{shilov2024mosaic}."
- Multi-source learning (MSL): Training a single model across multiple source domains to leverage shared structure and reduce distribution complexity. "Modern analysis for mixed data training further relies on the perspective of multi-task learning (MTL) or multi-source learning (MSL)."
- Multi-task learning (MTL): Training a shared model on multiple tasks to exploit shared representations and reduce amortized complexity. "Modern analysis for mixed data training further relies on the perspective of multi-task learning (MTL) or multi-source learning (MSL)."
- Name cloze: A targeted query technique that blanks out names to detect memorization of copyrighted or sensitive text. "use ``name cloze'' queries to identify a wide range of memorized copyrighted books"
- Optimal Transport (OT): A framework measuring distances between probability distributions (e.g., via Wasserstein distance), used in domain adaptation theory. "latter DA theories leverage Optimal Transport (OT) to measure the geometric distance~\cite{courty2016optimal} (e.g., Wasserstein distance) between source and target distributions"
- PEARL: A perturbation-based framework to detect memorized content by its sensitivity to input changes. "The PEARL~\cite{djire2025memorization} framework was introduced as a novel detection method based on a perturbation sensitivity hypothesis."
- Permutation equivariant functions: Functions whose output permutes in the same way as the input, for which certain attention modules are universal approximators. "even a one-layer, single-head self-attention module becomes a universal approximator for continuous permutation equivariant functions on a compact domain."
- Policy collapse: A post-RLHF phenomenon where optimization reduces entropy diversity, indicating memorization or overfitting of policies. "The proposed
Self-Critique'' method probes forpolicy collapse'' by comparing the token-level entropy sequences" - RefinedWeb: A large, filtered web dataset showing that aggressively filtered and deduplicated web data can outperform curated corpora. "The RefinedWeb~\cite{penedo2023refinedweb} provided a key insight: models trained on aggressively filtered and deduplicated web data could outperform those trained on curated corpora."
- REGMIX: A regression-based data mixture optimizer assuming rank invariance across scales and data volumes. "For instance, REGMIX~\cite{liu2025regmix} frames the problem as a regression task."
- RLHF: Reinforcement Learning from Human Feedback, an alignment technique that trains models using human preference signals. "after RLHF, where optimization erases traditional likelihood signals."
- ScaleBIO: A scalable bilevel optimization approach adapted to LLMs via first-order methods to optimize data mixtures for generalization. "ScaleBIO~\cite{pan-etal-2025-scalebio}"
- Scaling laws: Empirical regularities relating performance, model size, data, and compute, guiding the scaling of LLMs. "scaling laws~\citep{scalinglaw1}"
- Self-Critique: A method that elicits an alternative critique response to reveal policy collapse through entropy sequence similarity. "The proposed
Self-Critique'' method probes forpolicy collapse'' by comparing the token-level entropy sequences" - SoftDedup: A soft reweighting approach to reduce redundancy without hard removal, balancing common and rare data to avoid information loss. "The most recent conceptual advance, SoftDedup~\cite{he-etal-2024-softdedup}, addresses a theoretical flaw in ``hard deduplication'' methods: the risk of information loss, and further proposes a soft reweighting mechanism instead."
- Spurious correlations: Incorrect intermediate patterns that lead to right answers, which models can learn and must unlearn for robust reasoning. "identify and unlearn ``spurious correlations'' (i.e., incorrect intermediate steps that happen to lead to a correct final answer)"
- Total Variation: A statistical distance metric between probability distributions used to bound estimation errors. "the average Total Variation error $\mathcal{R}_{\overline{TV}$"
- TS-Guessing: A contamination detection protocol where models fill masked wrong options, revealing memorization of test formats. "Choi introduce an innovative detection method called TS-Guessing."
- Turing complete: A property of a system capable of simulating any Turing machine, indicating maximal computational expressivity. "prove that Transformers are indeed Turing complete under the assumption of infinite precision."
- Universal Approximation Theorem: A theorem stating neural networks can approximate any continuous function under mild conditions. "the proposal of the Universal Approximation Theorem~\cite{hornik1989multilayer}"
- Universal Transformer: A variant of the Transformer that introduces recurrence to overcome finite-precision expressivity limits. "the proposed Universal Transformer which combines parallel self-attention with recurrence can overcome this limitation."
- UtiliMax: A portfolio-optimization-inspired method balancing utility, diversity, and scale to choose data mixtures. "Differently, UtiliMax~\cite{held2025optimizing} draws an analogy to financial portfolio optimization."
- Wasserstein distance: An OT-based metric measuring the cost of transporting probability mass, used to quantify distributional differences. "(e.g., Wasserstein distance)"
Collections
Sign up for free to add this paper to one or more collections.

