- The paper introduces a dual-centric framework combining high-fidelity data synthesis with agentic reinforcement learning to overcome data scarcity in Text-to-SQL systems.
- The methodology employs structural-aware synthesis and iterative gen-as-check refinement to ensure SQL query correctness and logical consistency.
- The approach achieves state-of-the-art performance on Spider and BIRD benchmarks, significantly enhancing model reasoning and execution accuracy.
An Authoritative Summary of "AGRO-SQL: Agentic Group-Relative Optimization with High-Fidelity Data Synthesis" (2512.23366)
Introduction
The paper "AGRO-SQL: Agentic Group-Relative Optimization with High-Fidelity Data Synthesis" presents a novel framework targeting the challenges in Text-to-SQL systems, particularly those associated with data scarcity and reasoning complexity. These systems aim to convert natural language queries into structured SQL commands. However, existing models are hampered by a lack of high-quality training datasets and the limitations of current reasoning methodologies.
AGRO-SQL addresses these constraints through a dual-centric approach: a Data-Centric synthesis of interactive, RL-ready data with verified correctness, and a Model-Centric strategy leveraging an innovative Agentic Reinforcement Learning framework. The latter utilizes Group Relative Policy Optimization (GRPO) to enhance model reasoning capabilities through feedback from the environment, leading to superior performance on benchmarks like BIRD and Spider.
Methodology
AGRO-SQL's framework integrates two main components: a data synthesis pipeline and an Agentic RL training strategy.
Data Synthesis Pipeline
AGRO-SQL introduces a rigorous data generation process designed to produce high-correctness, scalable datasets suitable for reinforcement learning. This pipeline employs the following stages:
- Structural-Aware Synthesis: Enhancements to existing synthesis methodologies are proposed, focusing on reducing noise in SQL execution and ensuring semantic-logical consistency.
- Iterative Gen-as-Check Refinement: Employs execution-based validation loops using a verifier to regenerate samples until they meet logical consistency requirements.
Agentic RL Training Framework
Building on the synthesized data, the Agentic RL employs a two-stage training approach:
- Cold Start with Supervised Fine-Tuning (SFT): This phase distills expertise from a teacher model to pre-train the agent, ensuring a robust starting policy through a curated dataset of high-quality interactions.
- Group Relative Policy Optimization (GRPO): A novel RL approach refining policies by evaluating relative execution rewards within trajectory groups, promoting efficient exploration and training stability under sparse reward domains.
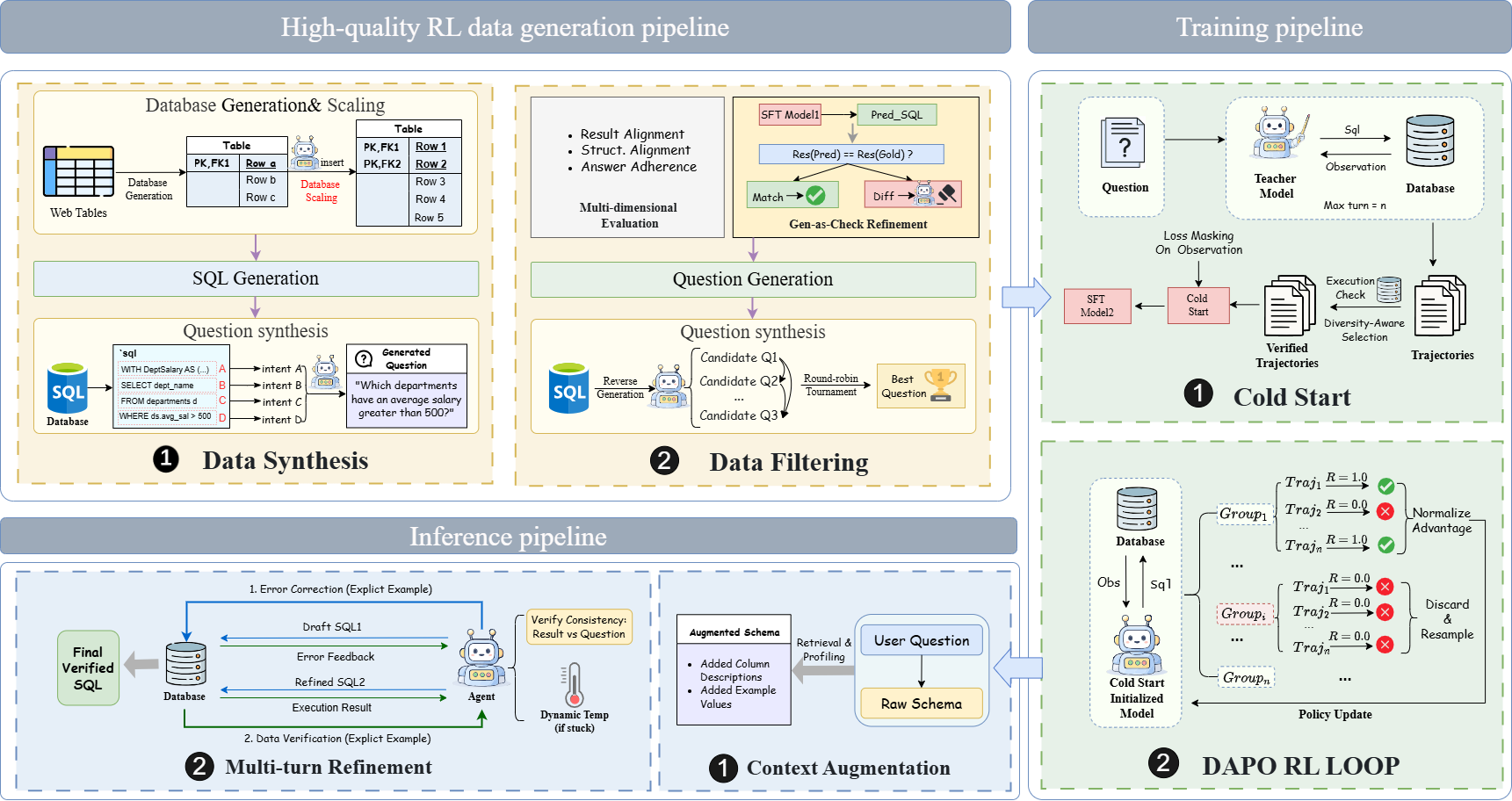
Figure 1: The overall pipeline of our framework. Given a natural language question and database schema, the policy model generates SQL candidates. Our core Advantage Shaping Module then computes reshaped token-level advantages, which are used to update the policy model via the GRPO algorithm.
Experimental Results
AGRO-SQL was evaluated on two prominent Text-to-SQL benchmarks: Spider and BIRD. The experiments demonstrated that AGRO-SQL outperforms existing single-model solutions, achieving new state-of-the-art results. Specifically, in the challenging BIRD benchmark, AGRO-SQL improved execution accuracy through its synergy of RL with high-quality data synthesis, underscoring the effectiveness of its methodological innovations.
Discussion and Implications
AGRO-SQL marks significant progress in overcoming the bottleneck caused by data scarcity in Text-to-SQL systems. By producing a vast amount of verified synthetic data and pioneering GRPO, AGRO-SQL enhances reasoning capabilities and exploration efficiency. The research paves the way for deploying more reliable Text-to-SQL systems with improved logical accuracy and reduced annotation costs.
Future work could focus on scaling this methodology to encompass more diverse queries and systems, potentially integrating additional layers of semantic validation. Moreover, exploring the applicability of GRPO within other NLP tasks might extend its utility across broader AI domains.
Conclusion
The paper on AGRO-SQL introduces substantial refinements in both data generation and reinforcement learning strategies for Text-to-SQL systems. By leveraging a data-centric approach for synthesizing high-fidelity training data and a novel AGRO framework for model optimization, the authors have effectively bridged critical gaps in current methodologies, leading to better performance on complex benchmarks. AGRO-SQL stands as a notable contribution to the field of Text-to-SQL research.