- The paper presents SQLForge, a framework that leverages SQL parsing, templating, and reverse translation to synthesize diverse text-to-SQL data.
- It integrates four key components—SQL Parser, SQL Foundry, Schema Architect, and Question Reverse-Translator—to ensure semantic fidelity and domain diversity.
- SQLForge-LM achieves 85.7% EX accuracy on Spider and 59.8% on BIRD, significantly narrowing the performance gap with closed-source models.
SQLForge: Synthesizing Reliable and Diverse Data to Enhance Text-to-SQL Reasoning in LLMs
Introduction
The paper introduces SQLForge, a data synthesis framework designed to address the significant performance gap observed in text-to-SQL tasks between open-source LLMs and their closed-source counterparts. SQLForge aims to enhance the reliability and diversity of synthesized data by embedding SQL syntax constraints and SQL-to-question reverse translation mechanisms, thereby improving text-to-SQL reasoning in LLMs. SQLForge-LM, the resultant family of models from this framework, achieves state-of-the-art performance on benchmarks like Spider and BIRD, demonstrating considerable improvement among open-source models.
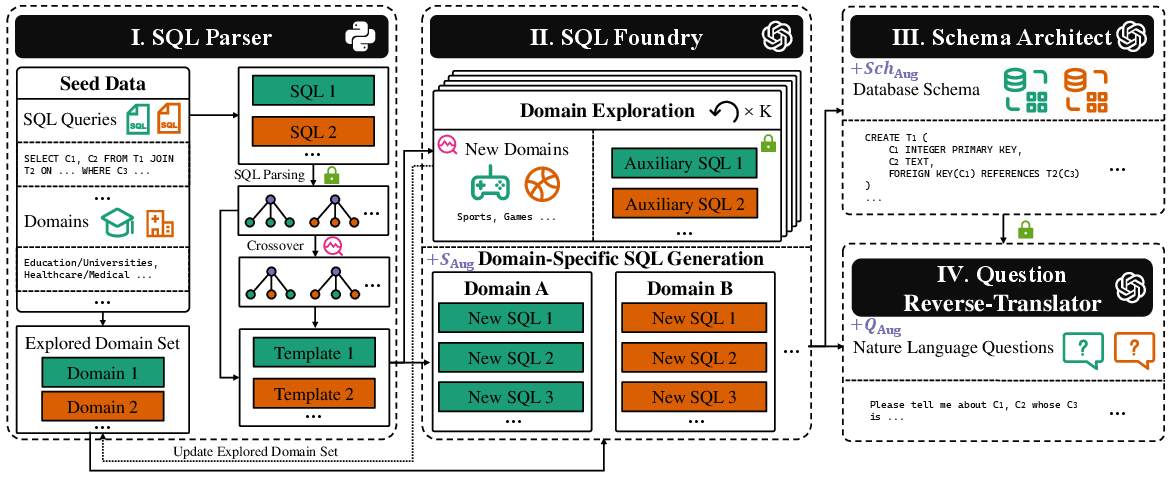
Figure 1: Overview of the proposed SQLForge framework, detailing its four key components.
SQLForge Framework
SQLForge comprises four core components: SQL Parser, SQL Foundry, Schema Architect, and Question Reverse-Translator.
SQL Parser
The SQL Parser plays a crucial role in transforming seed SQL queries into templates, thereby standardizing SQL syntax while preserving contextual integrity. By representing SQL queries in abstract syntax tree (AST) form, SQLForge ensures adherence to SQL standards during data synthesis, enhancing the reliability of generated SQL statements.
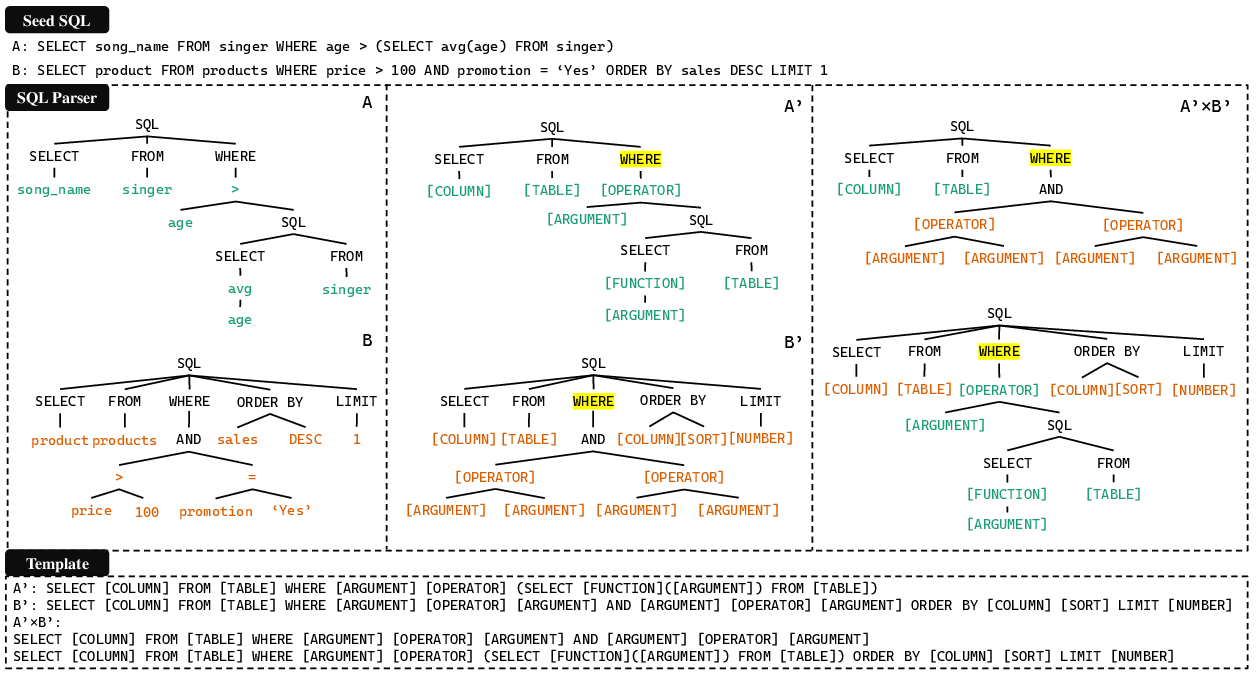
Figure 2: An example of the SQL Parser converting SQL into templates or generating new templates with AST.
SQL Foundry
SQL Foundry generates SQL statements across diverse domains using enriched templates. The mechanism involves an iterative domain exploration technique to synthesize auxiliary SQL statements, enhancing domain diversity and structural variation among generated SQL data. This approach ensures extensive coverage and exploration of new domains, strengthening model generalization.
Schema Architect
Given the novelty of generated domains, Schema Architect augments SQL statements by producing corresponding database schema expressions. This process substantially boosts the fidelity of the text-to-SQL data by defining database schema constraints clearly and systematically, reinforcing semantic alignment throughout data generation.
Question Reverse-Translator
Finally, the Question Reverse-Translator converts SQL statements into natural language questions that align with augmented schemas. This component addresses prevalent issues, such as semantic misalignment and inadequate reference resolution, by incorporating schema information into question generation, thereby achieving high semantic fidelity and linguistic naturalness.
Experimental Evaluation
The paper extensively evaluates the SQLForge framework through multiple experiments demonstrating the efficacy of the synthesized data.
SQLForge-LM, fine-tuned on data synthesized by SQLForge, surpasses existing open-source model-based methods in text-to-SQL tasks, achieving 85.7% EX accuracy on the Spider Dev set and 59.8% on the BIRD Dev set.
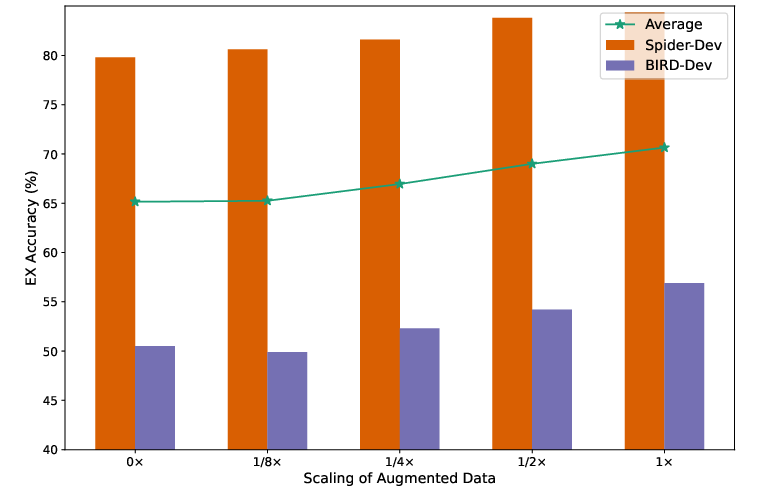
Figure 3: Effect of different scaling of augmented data with CodeLlama-7B as the base model.
Data Analysis
Analysis of the augmented data reveals that SQLForge effectively fills gaps in the semantic space, expanding distribution coverage and showcasing robust synthesis scalability.
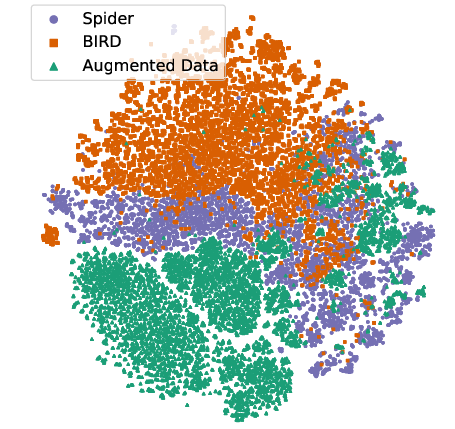
Figure 4: 2-D t-SNE illustrating the distribution of seed and augmented data in the semantic space.
Robustness Studies
SQLForge-LM exhibits resilience against perturbations and exceptional generalization capabilities across diverse datasets, including SYN, REALISTIC, and DK. Furthermore, scalability and adaptability tests confirm SQLForge's consistent performance with complex SQL statements and stability in open-source environments.
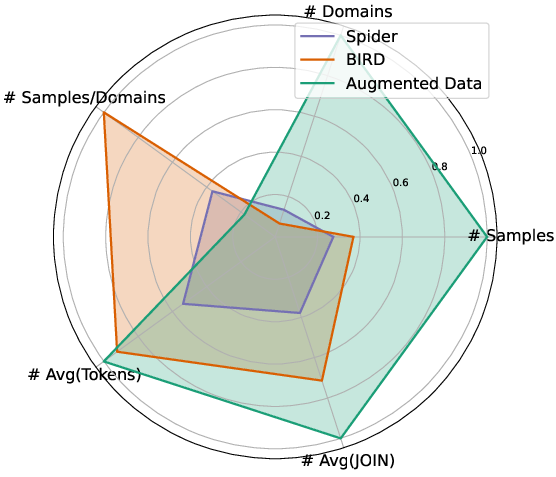
Figure 5: Detailed comparison between seed data and augmented data.
Conclusion
SQLForge marks a significant enhancement in text-to-SQL reasoning tasks for open-source models. By synthesizing reliable and diverse text-to-SQL data, the framework substantially narrows the performance gap with closed-source models, offering valuable insights into model improvement strategies. The adaptability and scalability of SQLForge demonstrate its potential application in various resource-constrained scenarios, paving the way for further advancements in text-based reasoning tasks in artificial intelligence.