- The paper presents a novel gated quantized VAE architecture that dynamically learns variable-length token representations to replace fixed algorithms like BPE.
- It integrates transformer-based encoder, gater, and decoder components with specialized losses for reconstruction, compression, and quantization.
- Empirical results show improved compression efficiency and faster language model convergence compared to traditional fixed-token methods.
GQ-VAE: A Gated Quantized VAE for Learning Variable Length Tokens
Introduction
Tokenization is a vital step in language processing and modeling pipelines, traditionally governed by deterministic algorithms like byte-pair encoding (BPE). These algorithms, while ubiquitous, impose certain limitations, including a reliance on fixed-length vocabulary mappings which preclude the encoding of semantic information inherent in variable-length tokens. In this context, the paper introduces the Gated Quantized Variational Autoencoder (GQ-VAE), a novel architecture designed to provide an independent, learnable tokenization scheme, thereby offering a potential replacement for traditional tokenizers like BPE. The GQ-VAE architecture aims to dynamically learn token representations, allowing for improved compression and language modeling capabilities.
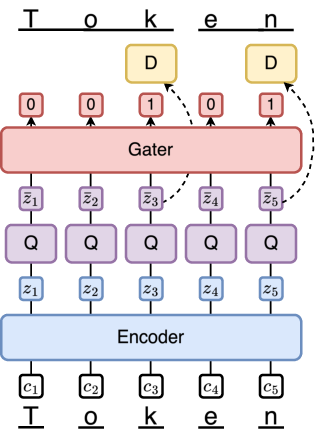
Figure 1: GQ-VAE Architecture. D=Decoder, Q=Quantizer. Encoder and Gater are transformers. The decoder head is illustrated in Figure 2.
GQ-VAE Architecture
The GQ-VAE architecture is composed of several integral components designed to support the seamless encoding and decoding of variable-length tokens. The system consists of an encoder, quantizer, gater, and decoder. The encoder maps the input byte sequence into latent space, from which the quantizer assigns these representations to discrete codes within a codebook. The gater differentiates token boundaries while the decoder transforms the quantized representations back into character sequences of variable lengths.
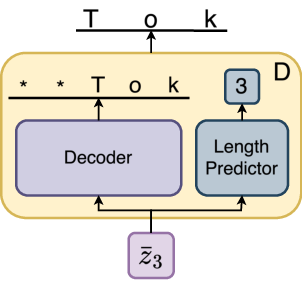
Figure 2: Decoder Head.
For variable-length token creation, the architecture employs a gating mechanism that enables selective token utilization based on thresholds, allowing a customizable compression ratio. Training is guided by a combination of reconstruction, compression, length prediction, and quantization losses. GQ-VAE employs specialized losses such as reconstruction loss and compression loss alongside traditional VQ-VAE commitments to fine-tune the model's adaptability to the input length and complexity.
Compression and Reconstruction
The GQ-VAE model offers notable compression capabilities, nearly matching the efficiency of traditional BPE methods while exceeding those achieved by fixed-size token models. The study showcases GQ-VAE's proficiency in maintaining or surpassing compression performance, as indicated by the comparative analysis using fixed-frequency gating to mimic established models.
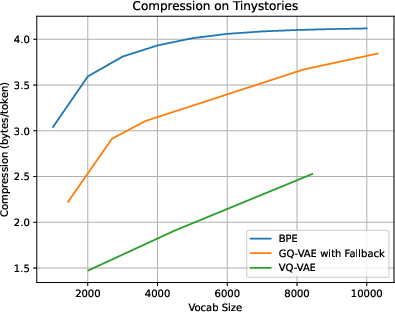
Figure 3: Compression and Vocabulary Size. VQ-VAE represents a fixed token length GQ-VAE, and higher vocab results continue the linear trend but are omitted for scale. GQ-VAE vocab sizes are distilled to represent only the number of unique tokens, while the codebook sizes in the model are [2k, 5k, 10k, 20k, 50k].
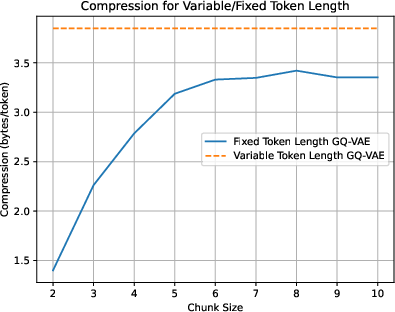
Figure 4: Compression for fixed-length token models. These models are all trained on the same hyperparameter setup as the 3.85 bits/byte variable length GQ-VAE baseline.
Language Modeling
The GQ-VAE's impact on language modeling is a central consideration. The architecture demonstrates gains in learnability, reducing training iteration counts compared to equivalently compressed BPE models. With an 18 million parameter transformer, experiments indicate superior convergence rates and lower loss metrics when utilizing GQ-VAE tokenizations versus traditional methods with the same vocabulary constraints.
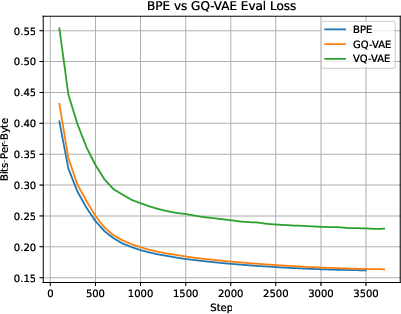
Figure 5: Language Modeling with GQ-VAE, BPE, and VQ-VAE (fixed token length GQ-VAE). Models are trained on all of tinystories, so the lower-compression GQ-VAE trains for more steps on the same data. The exact "used" vocabulary sizes for these models are BPE=10000, GQ-VAE=10314, VQ-VAE=13201.
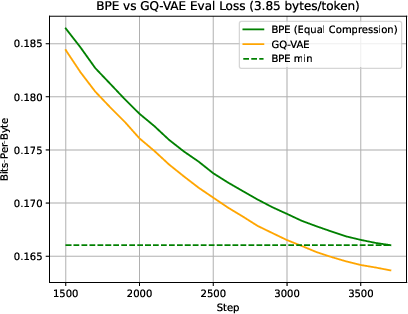
Figure 6: Language Modeling with GQ-VAE and BPE, same compression level.
One of the revealing insights is the uniformity in token frequency distributions offered by the GQ-VAE system, indicated by more balanced frequencies across the spectrum, which may facilitate learning processes for less frequent or niche word forms.
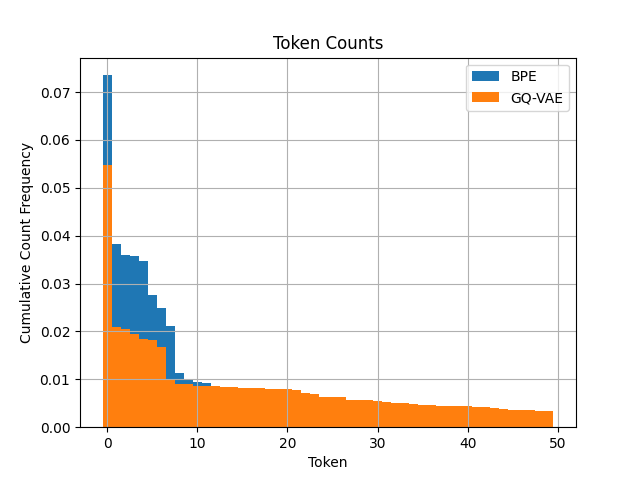
Figure 7: Histogram of Token Frequencies. Only the 50 most common tokens are included, but the frequency trend of GQ-VAE having higher frequencies in the distribution's tail continues for later tokens.
Conclusion
GQ-VAE represents a significant step in evolving tokenization approaches by accommodating variable-length and more semantically rich representations without the complexity constraints imposed by traditional methods. Despite limitations in initialization sensitivity and applications confined to specialized datasets, the model opens new research paths, particularly in adapting tokenization strategies for diverse linguistic and multimodal contexts. Potential future developments could explore improvements in compression efficiency and broader applications across languages and non-textual data domains.