- The paper introduces a feed-forward Transformer architecture that unifies dynamic 4D geometric reconstruction with open-vocabulary semantic alignment.
- It leverages a frozen StreamVGGT backbone and a Semantic Bridging Decoder with dual supervision to enhance spatial and temporal accuracy.
- The method demonstrates robust cross-scene generalization and real-time deployment potential for AR/VR, robotics, and video analysis.
Motivation and Context
4D scene understanding, encompassing both spatial geometry and dynamic temporal evolution, is a critical challenge for embodied AI, AR/VR, and semantic video analysis. Recent efforts have extended 3D vision–LLMs to 4D, yet the prevalent reliance on Gaussian Splatting architectures imposes explicit per-scene optimization, limiting scalability and real-time deployment. The paper "4DLangVGGT: 4D Language-Visual Geometry Grounded Transformer" (2512.05060) addresses these drawbacks by introducing a feed-forward, Transformer-based architecture that unifies dynamic geometric reconstruction and open-vocabulary semantic alignment for 4D environments.
Architectural Overview
4DLangVGGT is composed of three principal components:
- StreamVGGT-based Geometry Encoder: This module provides frozen, spatio-temporal geometric representations by leveraging a pre-trained StreamVGGT backbone, which retains fine-grained 3D structure and temporal continuity without need for retraining on semantics.
- Semantic Bridging Decoder (SBD): The SBD projects geometric features into a contextualized, language-aligned semantic space via a Dense Prediction Transformer (DPT) and dual-head design for both semantic embedding and RGB reconstruction.
- Multi-objective Supervision: The model is optimized by jointly minimizing semantic alignment losses (with time-sensitive and time-agnostic components) and a hybrid L1–L2 reconstruction loss, encouraging fidelity in both appearance and semantic consistency.
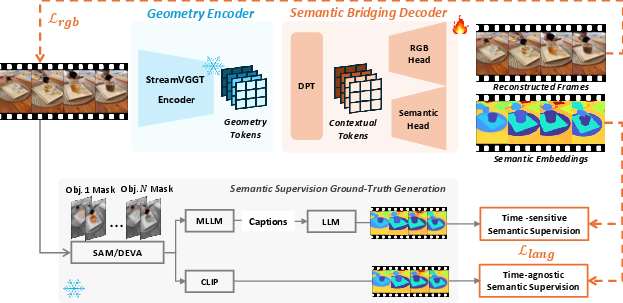
Figure 1: Overview of 4DLangVGGT, which integrates a frozen geometry encoder, a trainable semantic bridging decoder, and a multi-objective strategy for language-aware 4D representations.
This architecture operates in a unified, feed-forward manner, enabling training and inference across heterogeneous scenes without per-scene optimization.
Semantic Bridging and Supervision Design
The central innovation, the SBD, ensures that geometric features captured by the encoder are contextually enriched through DPT, resulting in a unified 4D feature map. Two heads output (i) temporally and spatially aligned semantic embeddings (trained via both CLIP-derived time-agnostic and LLM-derived time-sensitive targets) and (ii) RGB reconstructions for appearance-level consistency.
The supervision strategy includes:
- Time-agnostic supervision: Static, region-based semantics from CLIP serve as object-level anchors.
- Time-sensitive supervision: Multimodal LLM-generated, temporally consistent semantic descriptions track dynamic state changes.
- Dual loss: L1 regression and cosine similarity in the semantic space are employed with reconstruction penalties to reinforce both geometric alignment and semantic faithfulness.
4D Inference Pipeline
At inference, input videos are processed by the fixed StreamVGGT encoder to yield geometry tokens and camera information. SBD predicts per-frame semantic maps and RGB reconstructions. Depth and pose estimates are used to project 2D features into a 3D point cloud, onto which color and semantic embeddings are mapped, providing spatio-temporal 4D semantic fields.
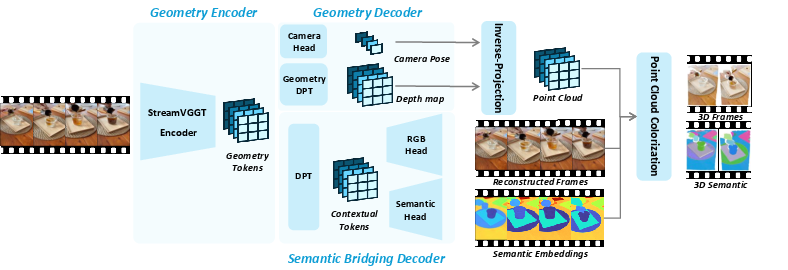
Figure 3: 4D inference pipeline of 4DLangVGGT, where video frames are transformed to geometry tokens and then jointly decoded into 3D spatial and semantic maps for each time step.
Experimental Results
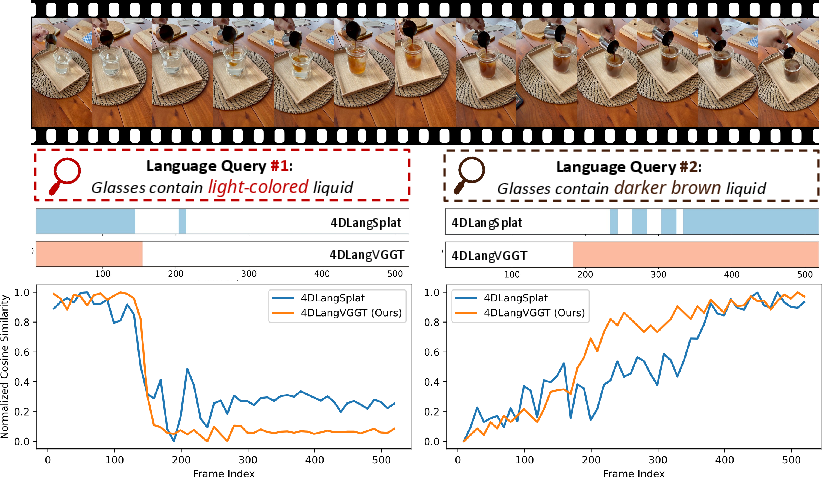
Experiments were conducted on HyperNeRF and Neu3D datasets with benchmarks including LangSplat, Feature-3DGS, Gaussian Grouping, and 4DLangSplat. Two training protocols were used: per-scene optimization and multi-video single-model (joint training across scenes).
Key Numerical Results and Claims:
Additional ablation studies confirmed that the auxiliary RGB reconstruction head and use of UNet architectures in output heads materially benefit both semantic and spatial accuracy.

Figure 2: Mask extraction accuracy for time-agnostic queries; 4DLangVGGT demonstrates robust segmentation even for fragmented objects, whereas 4DLangSplat degrades.
Generalization and Robustness
4DLangVGGT demonstrates strong generalization to unseen data, as evidenced by:
Practical and Theoretical Implications
From a practical standpoint, the model’s ability to train on diverse scenes and apply feed-forward inference enables realistic deployment in large-scale or real-time applications, in contrast to the scene-specific optimization requirements of Gaussian Splatting methods. This paradigm shift makes open-vocabulary 4D semantic mapping tractable for robotics, AR/VR, and video intelligence.
Theoretically, the joint modeling of geometry and language via contextual Transformers establishes architecture and loss-design principles for unified, generalizable 4D field learning. The intrinsic separation of geometric feature extraction and semantic alignment facilitates straightforward incorporation of additional modalities or supervision sources in future extensions.
Future Directions
Several limitations are noted by the authors—primarily the constrained diversity of evaluation benchmarks. Future research may:
- Scale the approach to substantially larger, more complex, or real-world dynamic scene datasets.
- Incorporate fine-grained mask-grounding and richer dynamic semantic supervision.
- Develop domain-specialized large models for 4D language fields as foundation models for embodied AI.
Conclusion
4DLangVGGT delivers a Transformer-based, scalable, and unified solution for 4D geometric and semantic grounding. Its superior cross-scene and cross-query generalization, strong performance on dynamic scene understanding, and scalable architecture offer a promising foundation for advancing open-vocabulary 4D field learning and deployment in real-world vision–language systems.