- The paper introduces a novel loss function that combines SIREN's periodic encoding with geometric keypoint supervision to improve dynamic scene reconstruction.
- It decomposes scene dynamics into low- and high-frequency streams and demonstrates significant improvements using metrics like FVD, FID, and LPIPS on multiple datasets.
- The approach generalizes to various architectures, offering robust, temporally coherent 4D motion modeling for monocular video applications.
SirenPose: High-Fidelity Dynamic Scene Reconstruction with Geometric Supervision
Introduction
Accurate and temporally consistent 4D (spatiotemporal) reconstruction from monocular video remains a significant challenge, particularly in scenarios dominated by rapid object motion, complex dynamics, occlusions, or multi-target interactions. Existing frameworks, notably those leveraging Neural Radiance Fields (NeRF) and Gaussian Splatting, achieve impressive static and slow-motion reconstructions, yet frequently manifest artifacts such as motion blur, trajectory jitter, and geometrically implausible deformations under dynamic or ambiguous supervision. The absence of explicit high-frequency regularization and geometric priors in these models fundamentally limits their temporal coherence and motion fidelity.
SirenPose addresses these limitations by introducing a principled loss function that exploits the periodic activation capabilities of Sinusoidal Representation Networks (SIREN), fused with strong geometric keypoint supervision. This enables enhanced high-frequency modeling capacity while providing robust physical and structural constraints, yielding high-fidelity, temporally coherent scene reconstructions.
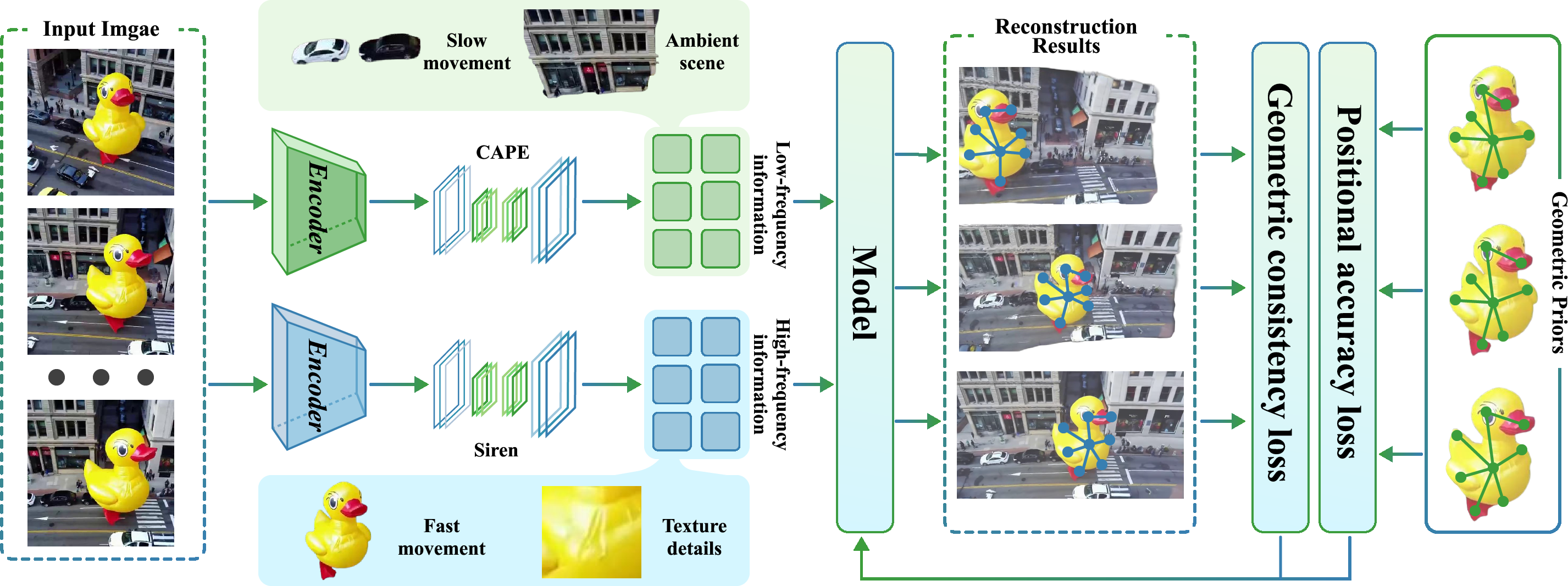
Figure 1: The pipeline fuses low-frequency (CAPE) and high-frequency (SIREN) streams for dynamic keypoint estimation, supervised by positional and geometric consistency losses.
Technical Approach
Spatiotemporal Frequency Decomposition
SirenPose employs explicit decomposition of scene dynamics into low- and high-frequency components: the low-frequency stream (e.g., CAPE) captures scene structure and slow dynamics, while the SIREN-based high-frequency stream models fine motion and detail. These complementary representations are fused at the keypoint level, leveraging the periodic encoding capability of SIREN for signal fidelity in regions exhibiting fast deformation and occlusion.
SIREN-Based High-Frequency Signal Modeling
Sinusoidal activations, σ(z)=sin(ω0z), facilitate expressive high-frequency fitting, but require careful parameter initialization and scale management to ensure stable learning (e.g., specific initialization of Wl weights and selection of ω0). SirenPose utilizes a frequency hyperparameter ω0=30 and principled initialization to maintain activation variance across layers, as detailed in the SIREN literature (Sitzmann et al., 2020). This setup enables the network to capture subtle geometric changes and motion details unattainable with ReLU or other non-periodic activations.
Geometric Keypoint Supervision
A novel aspect of SirenPose is the integration of geometric priors via large-scale keypoint annotations (600k instances, extension of the UniKPT/X-Pose dataset (Yang et al., 2023)). This supervision is not category-specific, supporting broad generalization via category-agnostic keypoint detection and graph neural network-based relational modeling. The use of geometric keypoints as structural anchors ensures motion representations that are not only visually plausible but also physically valid.
SirenPose Loss Function
The composite SirenPose loss is constructed as
LSirenPose=Lpos+λgeoLgeo
where Lpos enforces absolute positional accuracy (L2 loss), and Lgeo regularizes the network in the SIREN's functional space by penalizing deviations in the sine-encoded relative keypoint vectors. This dual-term approach, with λgeo as a balancing parameter, constrains reconstructions to be both visually and geometrically consistent under challenging conditions.
Experimental Results
Quantitative and Qualitative Comparison
SirenPose demonstrates substantial improvements over MoSCA, 4D Gaussian Splatting, DS4D, and Monst3R across multiple datasets and benchmarks. On the DAVIS dataset, it reduces FVD by 17.8% (984 vs. 1197 MoSCA), FID by 28.7% (132.8 vs. 186.4), and LPIPS by 6% (0.3829 vs. 0.4074), also achieving a temporal consistency score of 0.91 versus MoSCA’s 0.81. For pose estimation, SirenPose attains 14.6% lower Absolute Translation Error, 28.8% lower Relative Pose Error (Translation), and 17.0% lower Relative Pose Error (Rotation) versus Monst3R. These gains are observed consistently on synthetic (Sintel) and real-world (Bonn, DAVIS) datasets.

Figure 2: SirenPose yields reconstructions free of local geometric fractures and motion blur as observed in baselines, while preserving high-frequency structure and temporal consistency.
Integration of SirenPose loss as a modular regularizer in alternative backbones (e.g., DS4D, 4DGS) yields immediate performance boosts, demonstrating the generalizability and architectural compatibility of the approach.
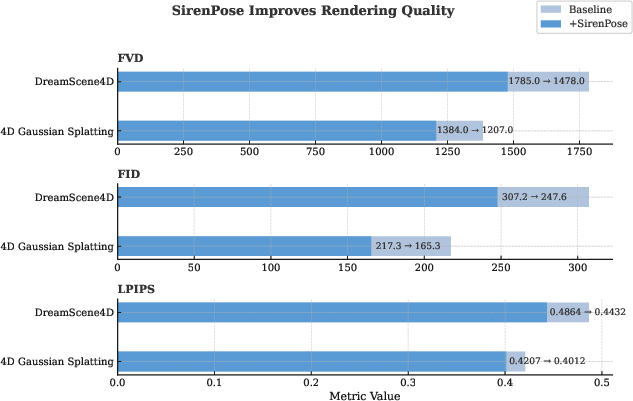
Figure 3: The inclusion of SirenPose loss universally improves FVD, FID, and LPIPS across baseline architectures, underscoring its effectiveness as a generic high-frequency geometric regularizer.
Temporal analysis exposes that SirenPose's predictions have substantially smoother error curves and minimal abrupt error spikes (Figure 4), highlighting enhanced robustness against drift and motion ambiguity, especially in complex dynamic environments.
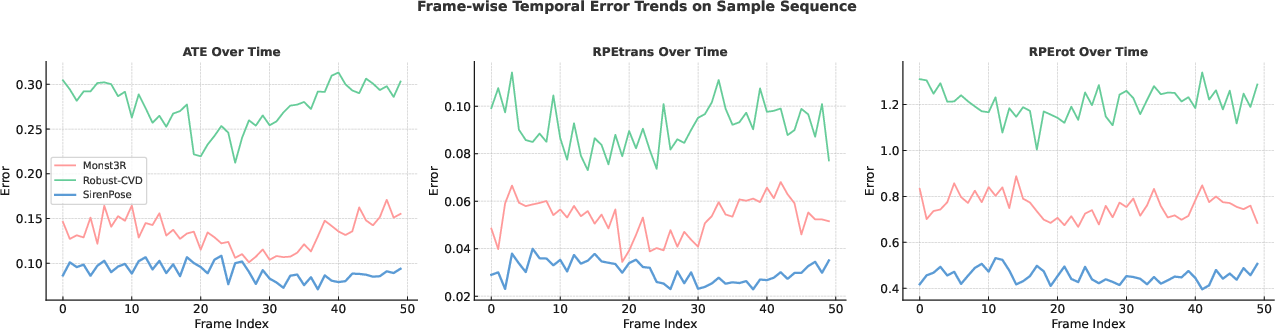
Figure 4: SirenPose maintains low, stable ATE/RPE trends, evidencing superior intra-sequence temporal consistency compared to state-of-the-art competitors.
Ablation Studies
Keypoint-level ablations reveal that reconstruction fidelity (geometric accuracy, MSE, FVD) strongly depends on the availability and integrity of keypoint supervision. Removal of keypoints systematically degrades both quantitative metrics and perceptual quality (Figure 5), emphasizing the centrality of geometric priors in dynamic scene understanding.
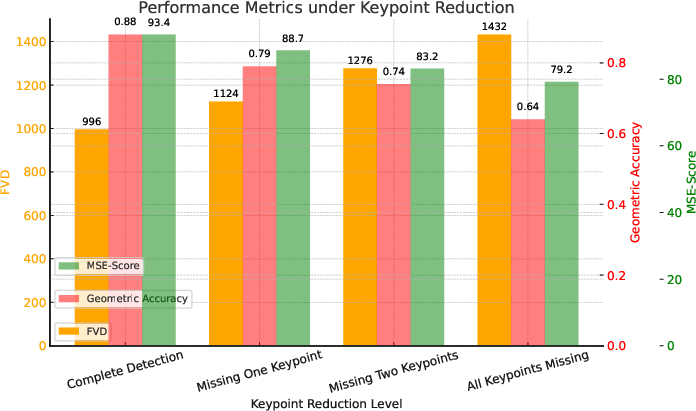
Figure 5: Reconstruction performance (accuracy, MSE, FVD) degrades monotonically as critical keypoints are excluded—demonstrating keypoint priors are essential for high-fidelity 4D reconstruction.
Module-level ablation further indicates both the high-frequency (SIREN) pathway and geometric keypoint supervision are necessary and complementary. Disabling either component, or both, results in significant performance regression in MSE and EPE metrics, affirming the necessity of frequency-aware geometric regularization.
Implications and Future Directions
The SirenPose paradigm demonstrates that frequency-aware representation, combined with structural geometric priors, is an optimal strategy for overcoming the limitations of current 4D scene reconstruction systems. Practically, this enables broader application of monocular dynamic scene understanding in settings previously dominated by multi-view or template-based approaches, such as AR/VR content creation, sports analytics, and autonomous robotics.
Theoretically, the paper highlights that the current generation of neural implicit representations can be made robust to high-frequency and rapid dynamic changes with appropriate supervisory losses aligned to their inductive bias. This eliminates the reliance on hand-crafted motion bases and allows for scaling to category-agnostic, open-world scenarios.
Future developments may include:
- End-to-end architectures that jointly train SIREN-based representations and category-agnostic keypoint detectors.
- Extension to dense geometric and physical priors beyond keypoints, including part-level and contact constraints.
- Integration with differentiable rendering and temporal propagation modules for real-time deployment on streaming video data.
- Adapting similar high-frequency geometric supervision concepts to other modalities, such as audio-visual fusion or medical imaging.
Conclusion
SirenPose provides a mathematically principled and empirically validated solution to dynamic scene reconstruction from monocular video. By unifying periodic high-frequency encoding and structural geometric supervision, the framework achieves substantial gains in visual fidelity and temporal coherence, outperforming state-of-the-art alternatives under rigorous quantitative and qualitative benchmarks. SirenPose establishes a new baseline for physically plausible, high-frequency-aware 4D scene understanding and opens directions for architecture-agnostic regularization strategies in computer vision and graphics (2512.20531).

