- The paper introduces MultiEgo, a dataset offering synchronized, multi-view egocentric videos that enable robust 4D dynamic scene reconstruction across diverse social interactions.
- It employs a rigorous acquisition pipeline featuring sensor fusion, sub-millisecond synchronization, and precise pose annotation to tackle challenges from rapid motion and complex lighting.
- Baseline evaluations reveal method-dependent performance, highlighting trade-offs between static background fidelity and the preservation of high-dynamic details in various scenes.
MultiEgo: A Multi-View Egocentric Dataset for 4D Scene Reconstruction
Motivation and Context
Recent progress in free-viewpoint video (FVV) and dynamic scene modeling has enabled high-fidelity immersive experiences across applications such as VR, entertainment, and human-computer interaction. State-of-the-art novel view synthesis techniques (e.g., 3D Gaussian Splatting [3DGS]) have dramatically improved reconstruction efficiency and fidelity. However, existing multi-view datasets rely on static camera arrays and lack data captured from authentically human-driven egocentric perspectives. While isolated egocentric datasets exist (e.g., Ego4D, Ego-Exo4D), they focus mainly on action recognition and video understanding, not scene reconstruction, and do not facilitate synchrony and fusion across multiple wearable perspectives.
MultiEgo addresses this significant gap by providing a multi-person, multi-egocentric video dataset captured in dynamic social scenes with high-resolution video, rigorous hardware-based synchronization, and accurate pose annotation. This resource enables evaluation and advancement of methods for dynamic scene reconstruction from multiple wearable user perspectives, and responds directly to the practical challenges posed by unconstrained, natural scene motion and complex illumination.
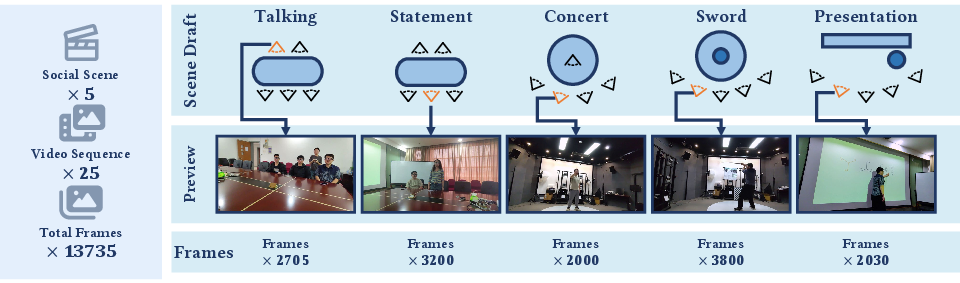
Figure 1: An overview of the MultiEgo dataset, comprising 5 dynamic scenes, each with 5 egocentric views and precise pose annotations, totaling 13,735 frames.
Dataset Composition and Acquisition Pipeline
MultiEgo consists of five challenging multi-person scenes, spanning meetings, performances, and presentations. Each scene includes participants equipped with RayNeo X2 AR glasses streaming 1080p 30 FPS video. Synchronization across views is achieved via a dedicated server-client architecture, with sub-millisecond temporal alignment supported by WiFi broadcast and device timestamping at 100 ns precision.
The acquisition system records real-time rotational sensor data, supporting robust pose estimation. Rigorous post-processing (white balance, exposure, de-flicker) ensures visual consistency; pose annotation integrates sensor fusion, spherical linear interpolation, SfM via COLMAP, and scale normalization through cross-frame keypoint displacement. Ultimately, all poses are synthesized into a globally referenced trajectory, enabling 4D domain reconstruction.
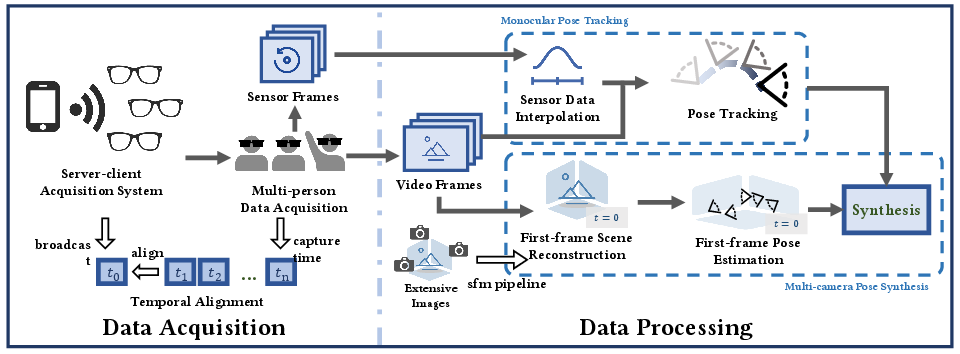
Figure 2: Data acquisition pipeline using a server-client system, multi-modal sensor fusion, and multi-view pose processing for 4D scene representation.
Scene Challenges
Each scene is structurally distinct, introducing specific technical obstacles:
- Talking: Rotational camera motion, complex lighting with specular reflections.
- Statement: Large body translations/rotations, occlusion, new content emergence.
- Concert: Dense spatial-temporal sampling from actor motion, dual audience/performer analysis.
- Sword: Extreme dynamic action, high angular velocities, challenging fast motion.
- Presentation: Dynamic occlusion shadows, chromatic variation from projection.
This design explicitly stresses reconstruction algorithms under realistic multi-user social interaction scenarios.
Baseline Evaluation
To validate MultiEgo's utility, the authors adapted leading dynamic scene reconstruction approaches—4DGaussian [4dgs], Deformable-3DGS [deformable-3dgs], 3DGStream [3dgstream]—to the novel multi-egocentric setting. Baseline data pipelines were hard-coded for compatibility. Quantitative metrics (PSNR, SSIM, LPIPS) indicate that reconstruction quality is scene-dependent, with static backgrounds and minimized rotational motion (e.g., sword, presentation) yielding superior scores across all baselines. Challenging scenarios (statement) with complex rotational dynamics and severe specular artifacts resulted in lower metrics, highlighting critical areas for method improvement.

Figure 3: Visualization of different baseline reconstructions on MultiEgo—methods show varying background fidelity and dynamic object handling.
Visual results demonstrate that 4DGaussian excels in static background reconstruction but fails to capture high-dynamic content due to excessive smoothing from MLP-based deformation fields. Conversely, 3DGStream retains high-frequency details at the cost of increased noise, better preserving rapid object motion such as in the sword scene.
Timestamp-aware experiments suggest that per-frame timestamps, when injected as view meta-data, have nuanced impacts on optimization: performance shifts are not statistically significant but might inform future work on synchronization-aware modeling.
Implications and Prospects
MultiEgo fills a crucial gap in dynamic scene reconstruction research—enabling design, training, and benchmarking of methods that must robustly handle multi-person egocentric data with realistic motion and lighting complexity. Its strict temporal alignment and diverse scene scenarios allow for systematic stress-testing of method generalizability, initialization sensitivity, and adaptability to novel movements.
Practically, MultiEgo paves the way for deployable FVV in real-world social interactions, including immersive meeting summarization and holographic event replay. It also drives theoretical advancement in multi-modal sensor fusion, view-consistent pose alignment, and scalable initialization.
Looking forward, anticipated developments include:
- Algorithms with enhanced resilience to rapid motion and illumination changes
- Data-driven approaches for joint ego-object reconstruction and understanding
- Systems classifying and resolving occlusions and multi-view ambiguities
- Multi-modal fusion with audio, depth, and ambient sensor streams for richer scene context
MultiEgo establishes a foundational resource and benchmark for multi-egocentric 4D dynamic scene modeling and is expected to catalyze further innovation both in dataset design and reconstruction algorithm sophistication.
Conclusion
MultiEgo is the first dataset dedicated to multi-view egocentric dynamic scene reconstruction, providing rigorously synchronized high-resolution video, accurate camera pose annotation, and challenging scene scenarios. It supports practical evaluation and fosters new research directions in social interaction capture, dynamic scene understanding, and free-viewpoint video synthesis. Baseline experiments confirm its utility and expose open challenges in reconstruction under natural motion and complex illumination, setting the stage for future multi-modal and scalable dynamic scene modeling advancements.