4D3R: Motion-Aware Neural Reconstruction and Rendering of Dynamic Scenes from Monocular Videos
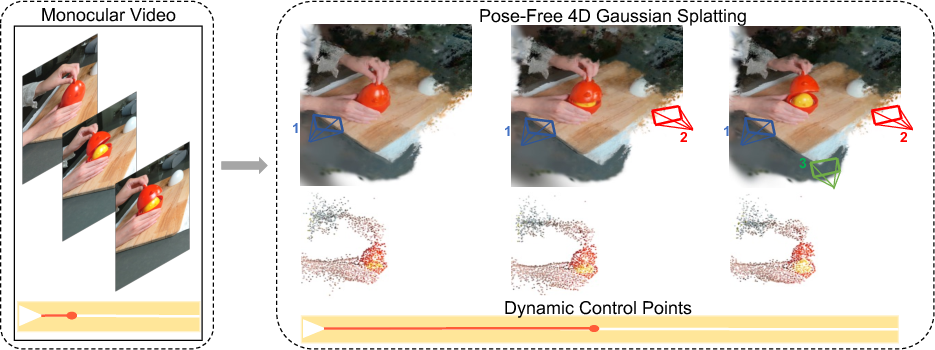
Abstract: Novel view synthesis from monocular videos of dynamic scenes with unknown camera poses remains a fundamental challenge in computer vision and graphics. While recent advances in 3D representations such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have shown promising results for static scenes, they struggle with dynamic content and typically rely on pre-computed camera poses. We present 4D3R, a pose-free dynamic neural rendering framework that decouples static and dynamic components through a two-stage approach. Our method first leverages 3D foundational models for initial pose and geometry estimation, followed by motion-aware refinement. 4D3R introduces two key technical innovations: (1) a motion-aware bundle adjustment (MA-BA) module that combines transformer-based learned priors with SAM2 for robust dynamic object segmentation, enabling more accurate camera pose refinement; and (2) an efficient Motion-Aware Gaussian Splatting (MA-GS) representation that uses control points with a deformation field MLP and linear blend skinning to model dynamic motion, significantly reducing computational cost while maintaining high-quality reconstruction. Extensive experiments on real-world dynamic datasets demonstrate that our approach achieves up to 1.8dB PSNR improvement over state-of-the-art methods, particularly in challenging scenarios with large dynamic objects, while reducing computational requirements by 5x compared to previous dynamic scene representations.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about turning a regular video taken with a single camera (like your phone) into a 3D scene you can look around in, even when things in the video are moving. The trick is doing this without knowing where the camera was at each moment and without special equipment. The authors call their method 4D3R. “4D” means 3D space plus time, and “R” stands for reconstruction and rendering (building the 3D scene and drawing new views of it).
What questions does the paper try to answer?
- How can we create new, realistic views of a moving scene from just one video, even if we don’t know the camera’s position and direction?
- How can we separate what’s moving (like people or objects) from what’s still (like the background) so we don’t get confused while building the 3D scene?
- How can we make this process fast and memory-efficient without losing image quality?
How does the method work? (In simple terms)
Think of the method as a two-part plan with some smart helpers:
- Find the camera and the moving parts
- The system uses big pre-trained AI models (like smart helpers) to:
- Guess the rough 3D shape of the scene and how far things are (depth).
- Spot which parts of the video are moving (like cutting out the moving objects with scissors).
- Then it refines the camera’s path (where it was and where it looked) by focusing only on the non-moving parts. This is important: moving things can trick the system, so it temporarily ignores them to get the camera right.
- Rebuild the scene with “soft points” and “puppet strings”
- The scene is drawn using millions of tiny, soft, colored blobs (called “Gaussians”) that, together, look like a detailed 3D world. Imagine painting a 3D scene with many soft dots.
- Moving parts are not moved one-by-one (that would be slow). Instead, the method places a small number of special “control points” (like the joints of a puppet) and uses them to smoothly move nearby blobs. This is like animating a character by pulling a few strings rather than moving every pixel.
- A simple rule called “Linear Blend Skinning” blends the influence of nearby control points, so the motion looks smooth and natural—like skin moving over bones.
A few friendly translations of technical words:
- Pose-free: The system doesn’t need to know the camera’s exact position/angle ahead of time.
- SAM2/transformer: Modern AI tools that help find objects and understand motion in the video.
- Bundle adjustment: A clean-up step that fine-tunes the camera path and 3D structure so everything lines up better.
- 4D Gaussian Splatting: Drawing the scene with lots of soft 3D dots that can change over time (time is the “fourth dimension”).
What did they find, and why does it matter?
Here are the main results, in plain language:
- Better picture quality: Their method makes sharper, more accurate new views than other leading methods, with up to about 1.8 dB improvement in a common image-quality score (PSNR; higher is better).
- Works well with moving stuff: It handles scenes where big parts of the video move (like people, hands, or objects), which usually confuse other systems.
- Faster and lighter: It trains about 5× faster than many older methods and still runs at around 45 frames per second. It also uses less memory (about 80 MB in their setup), which is quite compact.
- No pre-set camera info: It doesn’t need you to provide the camera’s path. It figures it out on its own by paying attention to the still background and ignoring moving distractions while estimating the camera.
Why this matters:
- You can capture a normal phone video and later “step into” the scene to look from different angles.
- It’s useful for AR/VR, filmmaking, games, robotics, and digital twins—anywhere you want 3D scenes from regular videos.
What could this change in the future?
- Easier 3D from everyday videos: Making 3D scenes from single-camera clips could become common, not just a lab trick.
- Better tools for creators: Video editors, game designers, and AR apps could generate dynamic 3D content quickly, even with moving people/objects.
- Safer and more private: Because it avoids heavy old-school pipelines that store lots of sensitive data, it can be more practical in real-world use—though any 3D reconstruction still needs responsible use and consent.
Short note on limits:
- It still works best when there’s enough non-moving background to anchor the camera.
- Very complex, squishy motions (like cloth flapping wildly) are still hard.
- It uses pre-trained AI helpers; future work could reduce this dependence.
In short: 4D3R is a smart, efficient way to turn one moving video into a high-quality, time-changing 3D scene—without needing the camera’s path beforehand—by separating motion from background and animating the scene with a few “puppet-like” control points.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper leaves the following concrete gaps and unresolved questions that future work could address:
- Camera intrinsics and calibration: The method assumes or uses intrinsics but does not describe how to estimate , handle lens distortion, or rolling-shutter effects; robustness to unknown/noisy intrinsics remains untested.
- Metric scale recovery: Pose evaluation uses Sim(3) alignment, implying scale ambiguity; strategies for recovering metric scale from monocular input are not provided or evaluated.
- Reliance on foundation models: Performance depends on DUSt3R/MonST3R (scene coordinates), SAM2 (segmentation), and SEA-RAFT (optical flow); domain shift robustness, failure modes, and ablations without these models are missing.
- Dynamic mask sensitivity: No analysis of sensitivity to the top-K prompt sampling, confidence/depth thresholds (, ), or SAM2’s segmentation errors (e.g., occlusions, thin/transparent objects, motion blur).
- Minimal-static-content scenarios: The pipeline requires enough static regions for masked PnP and DBA; failure cases and recovery strategies when static content is small or absent are not studied.
- Temporal consistency: Beyond ARAP, there are no explicit temporal consistency constraints or metrics; flicker, pose drift, and consistency across time are not evaluated.
- Time interpolation/extrapolation: Claims of rendering across time steps are not supported by quantitative evaluation of temporal interpolation/extrapolation quality.
- Deformation modeling limits: LBS with fixed RBF weights and gradient detachment may struggle near object boundaries, under large non-rigid deformations, or topological changes; comparisons with learned weights or joint optimization are missing.
- Control point adaptation details: The gradient-based control point addition lacks thresholds, scheduling, stopping criteria, and sensitivity analysis; scalability to long sequences and large scenes is not quantified.
- Number and placement of control points: The choice of 512 control points is justified qualitatively; systematic ablation vs. scene complexity, motion magnitude, and spatial distribution is absent.
- Occlusion handling: Robustness of pose and deformation estimation under severe self-occlusions or multi-object occlusions is not analyzed.
- Photometric robustness: The rendering loss (L1 + DSSIM) assumes consistent appearance; handling of illumination changes, specularities, shadows, and view-dependent effects is not addressed.
- Pose robustness in real-world conditions: Evaluation is primarily on synthetic or controlled datasets; effects of sensor noise, motion blur, rolling shutter, and low-light conditions on MA-BA are unquantified.
- Dataset diversity: Validation lacks in-the-wild handheld smartphone videos where SfM typically fails; generalization to unconstrained captures remains uncertain.
- Efficiency and scalability breakdown: The reported 5× speedup and 80MB memory are not decomposed per module; scaling trends with sequence length, number of Gaussians, and control points are missing.
- Geometry accuracy: Beyond PSNR/MS-SSIM, there is no evaluation of geometric fidelity (e.g., depth error, surface reconstruction metrics) or motion accuracy (trajectory/flow metrics).
- Uncertainty modeling: The pipeline does not estimate or propagate uncertainties from masks, scene coordinates, optical flow, or poses; robust optimization under uncertainty is unexplored.
- Dynamic/static ratio analysis: While claiming robustness to dominant moving objects, there is no quantitative study across varying dynamic-to-static ratios or object sizes.
- Multi-object interactions: Strategies for segmenting, tracking, and jointly deforming multiple interacting dynamic objects (merging/splitting, occlusion ordering) are not detailed or evaluated.
- Hyperparameter ablations: Key hyperparameters (e.g., in K-NN for LBS, in RBF, , , thresholds , ) are not ablated; guidelines for selection are absent.
- Online/streaming operation: It is unclear whether the system can operate incrementally on streaming input (online pose/refinement) and what latency/throughput trade-offs exist.
- Privacy-preserving reconstruction: Although broader impact is discussed, concrete technical methods (e.g., on-device processing, anonymization, differential privacy for masks/poses) are not integrated or evaluated.
- Integration of multi-modal sensors: The role of IMU, event cameras, or audio for improving pose/motion estimation is mentioned as future work but not architecturally specified or validated.
Practical Applications
Overview
This paper introduces 4D3R, a pose-free, motion-aware neural reconstruction and rendering framework for dynamic scenes from monocular videos. Key innovations include: (1) Motion-Aware Bundle Adjustment (MA-BA) that refines camera poses using transformer-derived motion priors and SAM2 segmentation; and (2) Motion-Aware Gaussian Splatting (MA-GS) that models dynamics via sparse control points, a deformation field MLP, and linear blend skinning. The system achieves state-of-the-art quality in dynamic novel view synthesis with reduced compute and memory (up to 5× faster training, ~80MB storage, ~45 FPS), without pre-computed camera poses.
Below are practical applications derived from these findings and methods, organized as immediate and long-term opportunities across industry, academia, policy, and daily life.
Immediate Applications
- Real-time 4D scene capture for content creation (media/entertainment, software)
- Use handheld monocular video to reconstruct and render free-viewpoint dynamic scenes (actors, props, moving objects) for VFX, virtual production, and AR overlays.
- Tools/products/workflows: Unreal/Unity plugin for “pose-free 4D capture,” Blender add-on for MA-GS editing, a desktop app that ingests a single camera video and exports 4D assets.
- Assumptions/Dependencies: Requires a GPU (desktop-grade), textured scenes with sufficient static regions, reliable SAM2 segmentation and DUSt3R/MonST3R initialization; lighting and motion blur should be moderate for best results.
- Broadcast and sports analytics from single-camera feeds (media/sports tech)
- Generate free-viewpoint replays and trajectory visualizations of dynamic plays using robust pose estimation that discounts moving subjects during BA.
- Tools/products/workflows: “Single-cam 4D replay” pipeline; integration with telestration/analytics tools; automated mask refinement using SAM2 prompts.
- Assumptions/Dependencies: Adequate resolution and texture; stable camera intrinsics; segmentation quality impacts pose refinement.
- Dynamic-aware mapping and odometry for robotics (robotics, software)
- Integrate MA-BA as a ROS2 node to improve pose estimation in dynamic environments by masking out non-static regions and leveraging dense BA.
- Tools/products/workflows: “Static-only BA” module for SLAM stacks; fusion with optical flow and SCR pipelines.
- Assumptions/Dependencies: Requires enough static background; on-device compute for real-time; accuracy depends on segmentation and flow calibration.
- E-commerce and product visualization with uncontrolled backgrounds (retail/software)
- Capture 3D/4D product views from consumer videos taken in everyday environments; MA-BA helps ignore background motion while MA-GS maintains high-quality rendering.
- Tools/products/workflows: “Turntable-free product capture” SaaS; web pipeline exporting glTF/GS assets; mask refinement to separate product from dynamic surroundings.
- Assumptions/Dependencies: Distinct product foreground; moderate camera motion; sufficient texture.
- Tele-rehabilitation and human movement visualization (healthcare)
- Reconstruct 4D motion of patients from a single camera for remote assessment and feedback in rehabilitation or sports training.
- Tools/products/workflows: Clinician dashboard for 4D playback; export to biomechanics tools; dynamic mask to isolate patient from environment.
- Assumptions/Dependencies: Non-rigid motion is supported but complex deformations may need additional priors; privacy/consent required.
- Digital heritage and site documentation in crowded scenes (cultural heritage)
- Reconstruct static structures from tourist videos while masking crowds; produce high-quality 3D models without multi-view capture.
- Tools/products/workflows: “Crowd-robust heritage capture” toolkit; static-only reconstruction pipeline using MA-BA and SAM2 masks.
- Assumptions/Dependencies: Sufficient static surfaces; segmentation should reliably separate humans/vehicles.
- Video editing and post-production free-viewpoint rendering (media/software)
- Plug-in for popular NLEs to generate novel views of dynamic shots from one take, reducing need for multi-camera setups.
- Tools/products/workflows: Mask-guided BA and MA-GS integrated as an effect in Premiere/Resolve; render at ~45 FPS for previews.
- Assumptions/Dependencies: Desktop GPU; scenes with adequate texture and moderate motion.
- Academic teaching and benchmarking in dynamic NVS (academia)
- Course modules demonstrating pose-free dynamic reconstruction; benchmark dynamic datasets using PSNR/MS-SSIM and pose metrics.
- Tools/products/workflows: Jupyter/Colab demos; assignment kits comparing MA-BA vs baselines; reproducible pipelines with provided pre-trained models.
- Assumptions/Dependencies: Availability of SAM2 and SCR models; dataset licensing; GPU access.
- Privacy-preserving reconstruction in practice (policy/industry)
- Immediate deployment of consent workflows and masking strategies to avoid reconstructing identifiable dynamic entities (e.g., people) by default.
- Tools/products/workflows: “Privacy-first masks” mode; automatic removal or obfuscation of dynamic human segments during export.
- Assumptions/Dependencies: Organizational policy adoption; accurate segmentation; local processing to minimize data sharing.
Long-Term Applications
- Consumer mobile AR capture of 4D scenes (daily life/software)
- On-device, pose-free dynamic reconstruction for social media posts and AR experiences, enabling users to share free-viewpoint memories.
- Tools/products/workflows: Mobile app with optimized MA-GS; compressed models for smartphone inference; cloud-assisted training on demand.
- Assumptions/Dependencies: Further optimization for mobile hardware; fast segmentation models; battery and thermal constraints.
- Live broadcast free-viewpoint experiences from a single camera (media/sports)
- Real-time rendering of dynamic scenes during live events (stadiums, concerts) using a single roaming camera; interactive viewing angles for audiences.
- Tools/products/workflows: Edge compute appliances running MA-BA/MA-GS; low-latency streaming of 4D assets; operator tools for quality control.
- Assumptions/Dependencies: Ultra-low latency pipelines; robust segmentation in dense motion; bandwidth for 4D streaming; professional-grade cameras.
- Autonomous robots with dynamic-aware mapping and planning (robotics)
- Full integration of motion-aware reconstruction into navigation stacks, enabling better obstacle handling and path planning in busy environments.
- Tools/products/workflows: SLAM+planning systems that fuse MA-BA with semantic segmentation and trajectory tracking; simulation-to-real workflows.
- Assumptions/Dependencies: Co-design with sensor stacks; onboard compute; safety certifications; resilience to adverse weather/lighting.
- Industrial inspection of moving machinery (manufacturing/energy)
- 4D reconstruction of equipment under operation to monitor deformation, detect anomalies, and analyze dynamics from a single camera.
- Tools/products/workflows: Inspection AI that compares 4D recon to nominal motion; alerts for deviations; maintenance reports.
- Assumptions/Dependencies: Robustness to specular/reflective surfaces; safety approvals; integration with plant IT/OT systems.
- Surgical and medical scene reconstruction (healthcare)
- Pose-free 4D reconstruction of surgical fields from monocular endoscopy/laparoscopy feeds to enhance training, guidance, and documentation.
- Tools/products/workflows: OR-friendly modules with sterile workflow; integration with surgical navigation; deformation priors for soft tissue.
- Assumptions/Dependencies: Significant research for non-rigid tissue modeling; clinical validation and regulatory approval; real-time constraints.
- Holographic telepresence and volumetric communications (telecom/media)
- Stream pose-free 4D reconstructions for lifelike telepresence; recipients can view from arbitrary angles in real time.
- Tools/products/workflows: Volumetric codecs; edge servers running MA-GS; standardized 4D formats interoperable with AR devices.
- Assumptions/Dependencies: Standards for 4D transmission; privacy and consent frameworks; high bandwidth and low-latency infrastructure.
- Generative 4D video editing and motion control (software/creative AI)
- Use control points and deformation fields as editable motion priors to drive generative video or 3D content, enabling fine-grained motion editing.
- Tools/products/workflows: “Motion graph” editors built atop MA-GS; integration with generative models that accept control-point constraints.
- Assumptions/Dependencies: Model hybridization research; user-interface innovation; legal clarity for content manipulation.
- City-scale scene understanding and digital twins (smart cities/urban planning)
- Build dynamic-aware digital twins from monocular urban cameras, distinguishing static infrastructure from dynamic entities for planning and simulation.
- Tools/products/workflows: City platforms ingesting CCTV feeds; privacy-preserving masking; temporal analytics of mobility patterns.
- Assumptions/Dependencies: Policy alignment on surveillance and data governance; scalability across thousands of cameras; fairness audits.
- Standards and governance for 4D reconstruction (policy/standards)
- Develop guidelines for consent, watermarking, access control, and anonymization in 4D captures to mitigate misuse and protect privacy.
- Tools/products/workflows: Standards bodies and industry consortia producing best practices; compliance checkers integrated in capture tools.
- Assumptions/Dependencies: Multi-stakeholder coordination; legal harmonization across jurisdictions; public awareness campaigns.
- Large-scale dataset curation and labeling (academia/industry)
- Automated pipelines to generate dynamic masks, camera poses, and 4D assets from raw videos for benchmarking and training advanced models.
- Tools/products/workflows: Data curation platforms; quality metrics (PSNR, MS-SSIM, ATE/RPE); reproducible capture protocols.
- Assumptions/Dependencies: Compute budgets; licenses for foundation models; standardized formats and metadata schemas.
Cross-cutting assumptions and dependencies
- Technical: Performance strongly depends on reliable dynamic segmentation (SAM2 or similar), high-quality scene coordinate regression (DUSt3R/MonST3R), sufficient static texture, moderate lighting and motion blur, and access to GPU resources.
- Legal/ethical: Consent and privacy must be considered for human-centric captures; organizations should adopt privacy-preserving defaults (e.g., masking) and clear disclosure.
- Operational: For real-time/broadcast-grade deployments, further engineering is needed for low-latency pipelines, model optimization, and hardware integration.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit 3D scene representation that rasterizes anisotropic Gaussian primitives for real-time neural rendering; "3DGS~\cite{kerbl3Dgaussians} introduced efficient rasterization of anisotropic 3D Gaussians, enabling real-time rendering without quality degradation."
- 4D-GS: Extensions of 3D Gaussian Splatting that model scene dynamics over time (4D) via deformations or motion bases; "Adapting 3DGS to dynamic scenes has led to the development of various 4D-GS approaches~\cite{wu20244d, huang2024sc} that incorporate deformation fields modeled by multi-layer perceptrons (MLPs), motion bases, or 4D representations."
- 6-DoF: Six degrees of freedom describing camera pose (3 for rotation, 3 for translation); "Estimation of 6-DoF camera poses typically involves establishing 2D-3D correspondences followed by solving the Perspective-n-Point (PnP)~\cite{gao2003complete} problem with RANSAC~\cite{fischler1981random}."
- Absolute Translation Error (ATE): A metric measuring absolute camera translation drift versus ground truth; "For camera pose estimation, we report the same metrics as~\cite{chen2024leap}: Absolute Translation Error (ATE), Relative Translation Error (RPE trans), and Relative Rotation Error (RPE rot), after applying a Sim(3) Umeyama alignment on prediction to the ground truth."
- alpha-blending: A compositing technique that accumulates transparent contributions along view rays; "The final color at each pixel is computed through -blending:"
- As-Rigid-As-Possible (ARAP) regularization: A deformation prior that encourages locally rigid transformations to stabilize non-rigid motion; "where enforces local rigidity with as-rigid-as-possible regularization~\cite{sorkine2007rigid}:"
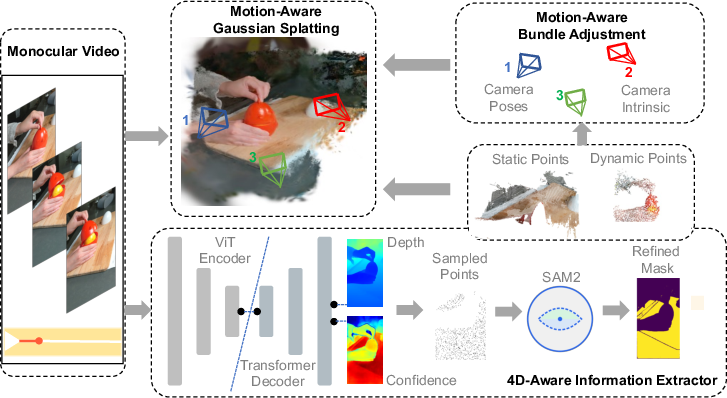
- Bundle Adjustment (BA): Joint optimization of camera poses and 3D structure to minimize reprojection error; "Our MA-BA module introduces an approach to camera pose estimation that explicitly models the separation between static and dynamic scene components, addressing a fundamental limitation in traditional bundle adjustment methods."
- COLMAP: A widely used Structure-from-Motion and Multi-View Stereo pipeline for pose and reconstruction; "Approaches for predicting 2D-3D correspondences can be broadly categorized into two main directions: Structure-from-Motion (SfM) methods such as COLMAP~\cite{schoenberger2016sfm, schoenberger2016mvs}, and scene coordinate regression (SCR)~\cite{shotton2013scene}."
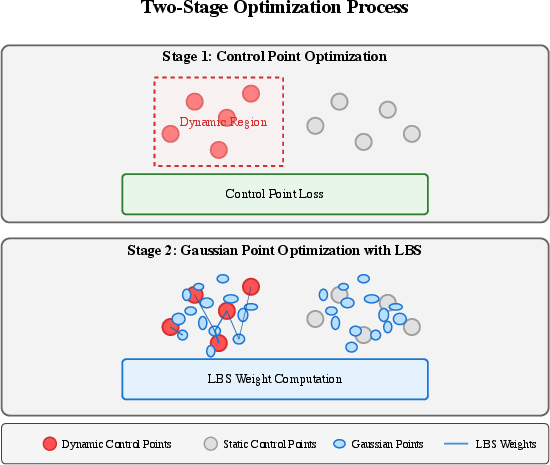
- Control points: Sparse 3D anchors used to drive deformations of many Gaussians via skinning; "We adopt a set of control points , where represents the 3D coordinate in the canonical space and defines the radius of the Radial Basis Function (RBF) kernel."
- Differentiable Dense Bundle Adjustment (DBA): A differentiable optimization layer that refines camera poses and depth with dense correspondences; "We further refine the camera poses through Differentiable Dense Bundle Adjustment (DBA) layer~\cite{teed2021droid}."
- DSSIM: A perceptual image dissimilarity metric derived from SSIM, used as a rendering loss; "using L1 and DSSIM metrics."
- DUSt3R: A foundation model that predicts dense 3D correspondences/coordinates from images using a ViT backbone; "Furthermore, DUSt3R~\cite{wang2024dust3r} employs a Vision Transformer (ViT)-based architecture to predict 3D coordinates using a data-driven approach and in the following work, MonST3R~\cite{zhang2024monst3r} extends DUSt3R to dynamic scenes by fine-tuning the model on suitable dynamic datasets."
- k-plane: A factorized scene representation using learned planes to model higher-dimensional fields efficiently; "such as the sparse motion basis~\cite{jeong2024rodygs}, sparse-control points~\cite{huang2024sc}, and k-plane~\cite{wu20244d}."
- Linear Blend Skinning (LBS): A weighted blending of control point transformations to deform geometry smoothly; "where is Linear Blend Skinning (LBS) weight~\cite{sumner2007embedded}."
- Mahalanobis distance: A distance metric that accounts for covariance, used here to weight residuals in BA; "is the Mahalanobis distance weighted by the confidence scores,"
- MonST3R: A model extending DUSt3R for dynamic scenes and pose, trained on motion-rich data; "However, the accuracy of camera poses predicted by MonST3R is not sufficiently stable, causing 4D-GS methods to struggle with reconstructing accurate scenes and resulting in poor rendering quality."
- Motion-Aware Bundle Adjustment (MA-BA): The paper’s BA variant that uses dynamic masks to separate static/dynamic regions for robust pose refinement; "4D3R introduces two key technical innovations: (1) a motion-aware bundle adjustment (MA-BA) module that combines transformer-based learned priors with SAM2 for robust dynamic object segmentation, enabling more accurate camera pose refinement;"
- Motion-Aware Gaussian Splatting (MA-GS): The paper’s dynamic GS representation using control points, a deformation MLP, and LBS; "and (2) an efficient Motion-Aware Gaussian Splatting (MA-GS) representation that uses control points with a deformation field MLP and linear blend skinning to model dynamic motion, significantly reducing computational cost while maintaining high-quality reconstruction."
- Multi-Layer Perceptron (MLP): A feedforward neural network used here to parameterize the deformation field; "Dynamic scene representation through motion-aware Gaussian Splatting parameters , motion-aware control points , and a deformation field MLP ."
- Neural Radiance Fields (NeRF): A neural implicit 3D representation that maps 5D coordinates to density and color for novel view synthesis; "While recent advances in 3D representations such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have shown promising results for static scenes, they struggle with dynamic content and typically rely on pre-computed camera poses."
- Optical flow: Pixel-wise motion field between frames used to aid pose/depth refinement; "We also include the optical flow from SEA-RAFT~\cite{wang2024sea}."
- Peak Signal-to-Noise Ratio (PSNR): A fidelity metric (in dB) for image reconstruction quality; "Extensive experiments on real-world dynamic datasets demonstrate that our approach achieves up to 1.8dB PSNR improvement over state-of-the-art methods, particularly in challenging scenarios with large dynamic objects, while reducing computational requirements by 5Ã compared to previous dynamic scene representations."
- Perspective-n-Point (PnP): The problem of estimating camera pose from 2D-3D point correspondences; "In contrast, SCR methods~\cite{shotton2013scene, brachmann2023accelerated, wang2024dust3r, zhang2024monst3r} utilize deep neural networks (DNNs) to directly predict the 3D coordinates of the image pixels, followed by running PnP with RANSAC for camera pose estimation."
- Quaternion: A 4D unit representation for 3D rotations used to parameterize Gaussian orientations; "Each Gaussian is characterized by its center position , covariance matrix (parameterized by rotation quaternion and scaling vector ), opacity value , and spherical harmonic coefficients for view-dependent appearance."
- RANSAC: A robust estimator that fits models while rejecting outliers (e.g., dynamic points) via consensus; "dynamic objects are commonly deemed to be outliers during the RANSAC process."
- Radial Basis Function (RBF) kernel: A spatial weighting function centered at control points to define influence radii; "We adopt a set of control points , where represents the 3D coordinate in the canonical space and defines the radius of the Radial Basis Function (RBF) kernel."
- Relative Pose Error (RPE): A local pose consistency metric reported for translation and rotation; "For camera pose estimation, we report the same metrics as~\cite{chen2024leap}: Absolute Translation Error (ATE), Relative Translation Error (RPE trans), and Relative Rotation Error (RPE rot), after applying a Sim(3) Umeyama alignment on prediction to the ground truth."
- Scene Coordinate Regression (SCR): Methods that directly predict per-pixel 3D coordinates for pose via PnP; "In contrast, SCR methods~\cite{shotton2013scene, brachmann2023accelerated, wang2024dust3r, zhang2024monst3r} utilize deep neural networks (DNNs) to directly predict the 3D coordinates of the image pixels, followed by running PnP with RANSAC for camera pose estimation."
- SE(3): The Lie group of 3D rigid body motions (rotation and translation) representing camera extrinsics; "and denotes the extrinsic parameters."
- Sim(3): The similarity transformation group (scaling + SE(3)) used for alignment; "after applying a Sim(3) Umeyama alignment on prediction to the ground truth."
- Spherical Harmonics (SH): Basis functions for representing view-dependent appearance in Gaussians; "and spherical harmonic coefficients for view-dependent appearance."
- Structure-from-Motion (SfM): A pipeline to recover camera poses and 3D structure from images via feature matching and triangulation; "Approaches for predicting 2D-3D correspondences can be broadly categorized into two main directions: Structure-from-Motion (SfM) methods such as COLMAP~\cite{schoenberger2016sfm, schoenberger2016mvs}, and scene coordinate regression (SCR)~\cite{shotton2013scene}."
- Umeyama alignment: A closed-form method for Sim(3) alignment between point sets/trajectories; "after applying a Sim(3) Umeyama alignment on prediction to the ground truth."
- Vision Transformer (ViT): A transformer architecture applied to images, here for learning 3D geometry/motion; "Furthermore, DUSt3R~\cite{wang2024dust3r} employs a Vision Transformer (ViT)-based architecture to predict 3D coordinates using a data-driven approach"
Collections
Sign up for free to add this paper to one or more collections.

