- The paper introduces DeepPHY, a multi-environment benchmark to rigorously assess the physical reasoning abilities of agentic VLMs through diverse interactive tasks.
- The paper demonstrates that evaluations with both VLA and WM prompts reveal significant deficits in causal reasoning, multi-step planning, and precise control, especially in complex environments.
- The paper outlines future directions, emphasizing integrated world modeling architectures and iterative feedback training to advance robust embodied intelligence.
DeepPHY: A Comprehensive Benchmark for Agentic VLM Physical Reasoning
Motivation and Benchmark Design
DeepPHY introduces a rigorous, multi-environment benchmark suite for evaluating the physical reasoning capabilities of agentic Vision-LLMs (VLMs). The motivation stems from the observation that while VLMs excel at static visual understanding and question answering, they exhibit substantial deficits in dynamic, interactive environments requiring causal reasoning, long-horizon planning, and precise control. Existing benchmarks either abstract away physical complexity or focus on symbolic, non-interactive tasks, failing to probe the core challenge of physical intelligence: the closed-loop cycle of perception, action, and feedback in physics-driven worlds.
DeepPHY aggregates six diverse environments—PHYRE, I-PHYRE, Kinetix, Pooltool, Angry Birds, and Cut the Rope—each selected for its unique physical dynamics and interaction modalities. The suite spans single-step planning (PHYRE), sequential timed actions (I-PHYRE), multi-component control (Kinetix), continuous control in billiards (Pooltool), projectile-based destruction (Angry Birds), and multi-objective, time-sensitive manipulation (Cut the Rope). This diversity ensures that the benchmark probes a wide spectrum of physical reasoning skills, from basic kinematics to complex tool use and spatiotemporal adaptation.
Each environment is formalized as a trial-based POMDP, with agents allowed multiple attempts per task. The agent must iteratively refine its internal world model fphy using the history of failed trials H(k), optimizing its policy π(k) to maximize the likelihood of success. This setup directly tests the agent's ability to learn from feedback and update its predictive model of the environment.
To mitigate the limitations of current VLMs in continuous control, DeepPHY discretizes action spaces and augments observation spaces with explicit annotations (e.g., gridded overlays, labeled interactive elements). This design choice shifts the evaluation focus from low-level perception to high-level physical reasoning and planning.
Evaluation Methodology
The benchmark evaluates 17 state-of-the-art VLMs (open- and closed-source) under two prompt formats: Vision-Language-Action (VLA) and World Model (WM). VLA prompts require direct action generation, while WM prompts additionally require prediction of environmental changes resulting from the chosen action. Metrics include Success Rate, Pass@K, and Average Attempts.
Empirical Findings
Across all environments, current VLMs exhibit substantial deficits in interactive physical reasoning. Most open-source models perform at or below the MOCK (random action) baseline, even with simplified action spaces. Closed-source models (e.g., GPT-o3, Gemini-2.5-Pro, Claude 4.0 Opus) demonstrate relative improvements, but a pronounced gap remains compared to human performance.
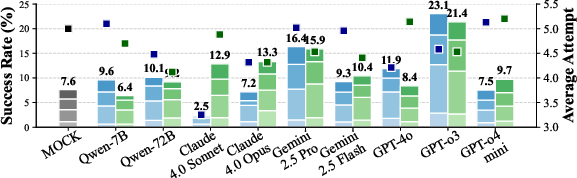
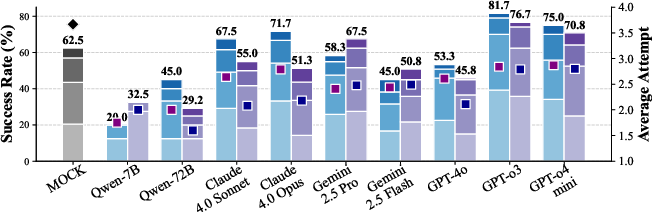
Figure 1: Performance comparison on the PHYRE (top) and I-PHYRE (bottom) environments. The stacked bars show cumulative success rates and average attempts for VLA and WM prompt formats.
PHYRE and I-PHYRE
In PHYRE, even the best models achieve <4% success on the first attempt, with only marginal improvements over multiple trials. This indicates poor in-advance planning and limited ability to learn from feedback. In contrast, I-PHYRE reveals that top models (e.g., GPT-o3) can reach >80% success after 10 attempts, suggesting that when the task structure aligns with the models' strengths in sequential reasoning, performance improves. However, open-source models still fail to generalize, highlighting a lack of robust temporal planning.
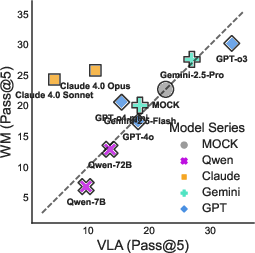
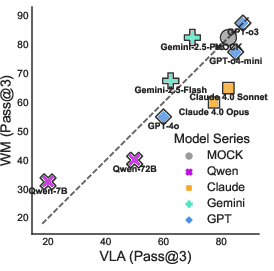
Figure 2: Performance comparison between prompt formats on PHYRE (Pass@5) and I-PHYRE (Pass@3). Points above the diagonal indicate WM advantage over VLA.
Kinetix
Kinetix exposes a steep decline in performance as task complexity increases. While models can handle basic single-component manipulation, they fail in multi-step, coordinated control tasks. Ablation studies show that explicit annotations help in simple tasks but become a cognitive burden in complex scenarios, especially under the WM prompt format.
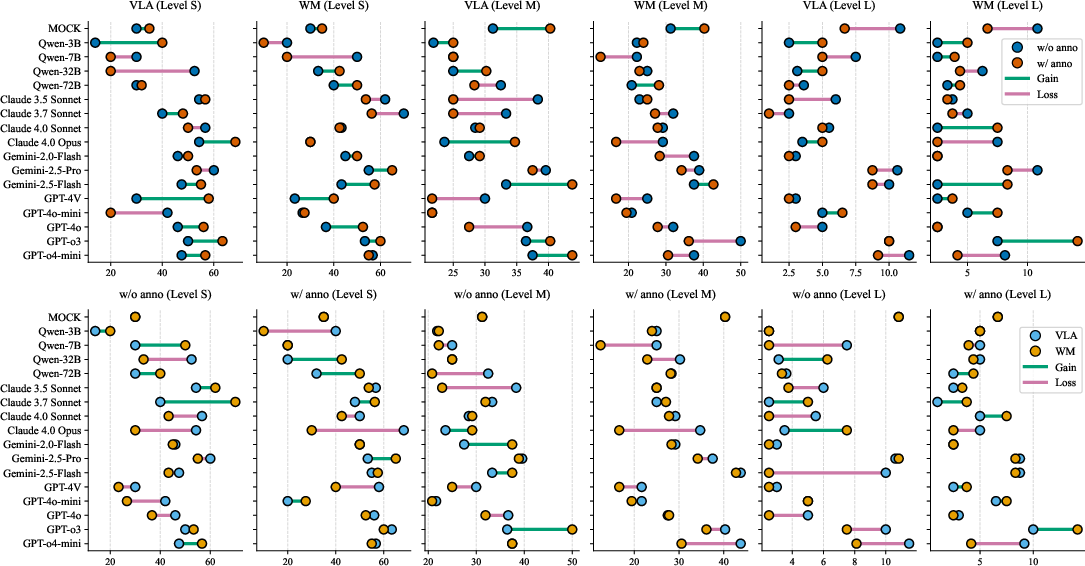
Figure 3: Model performance comparison in Kinetix across task difficulty, prompt format, and annotation ablation.
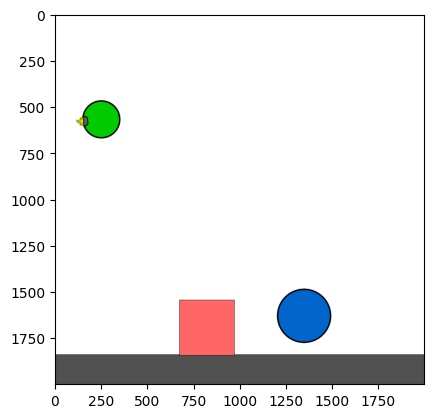
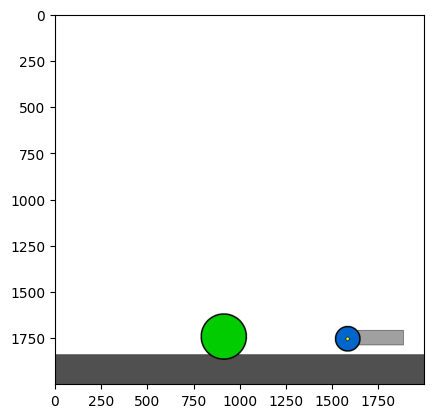
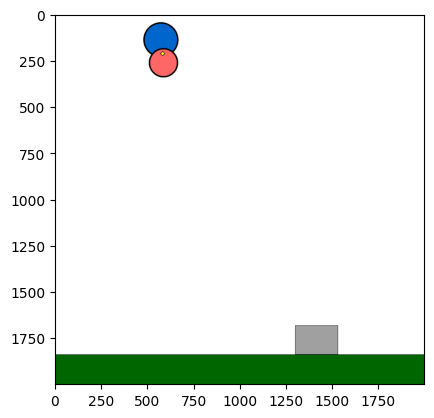
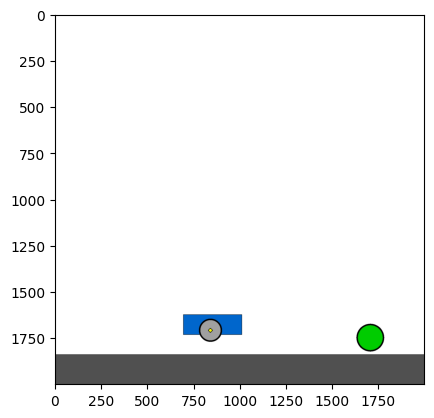
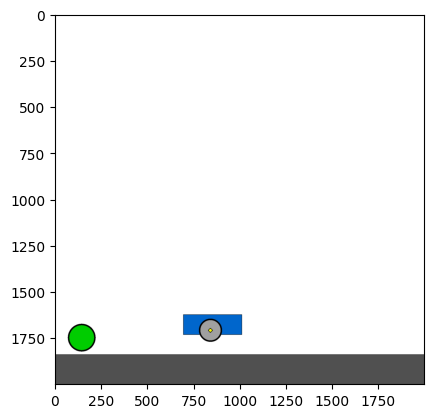
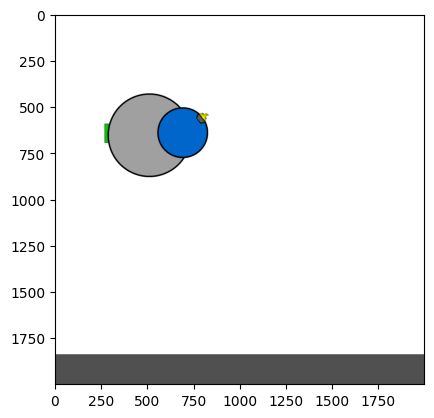
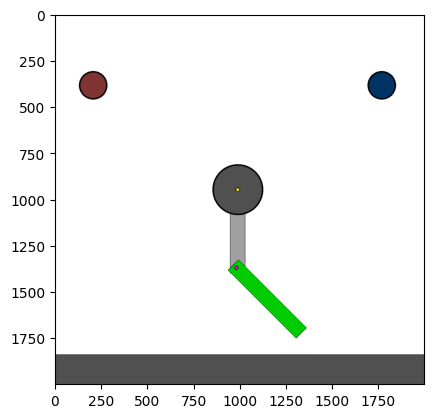
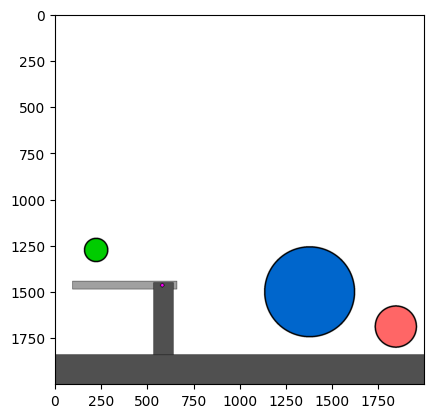
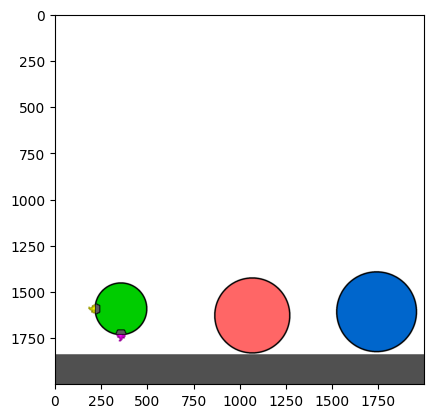
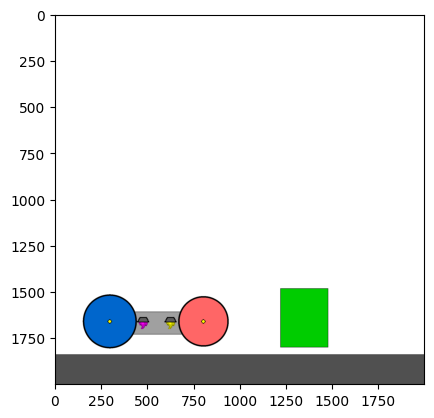
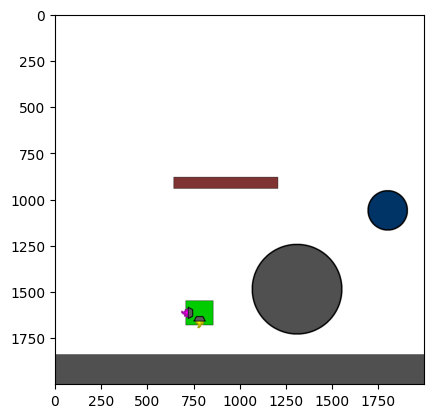
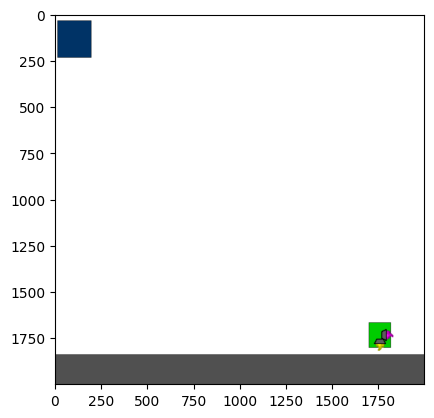
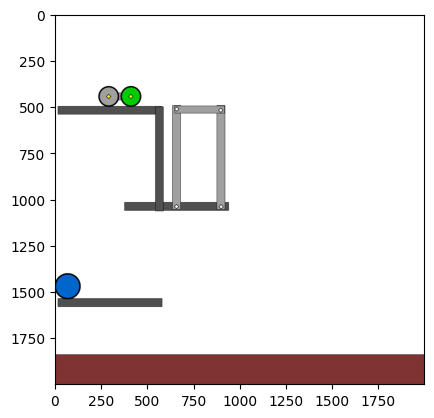
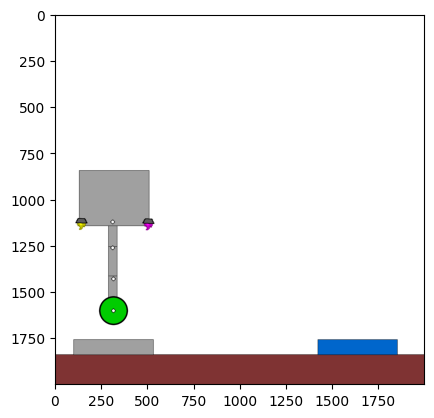
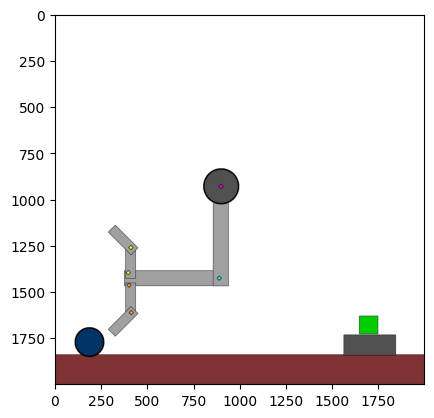
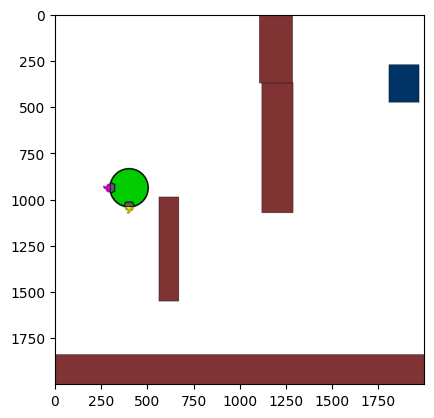
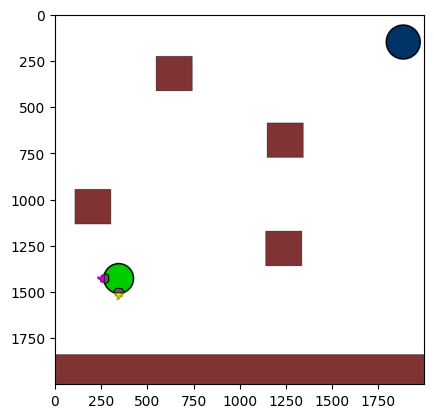
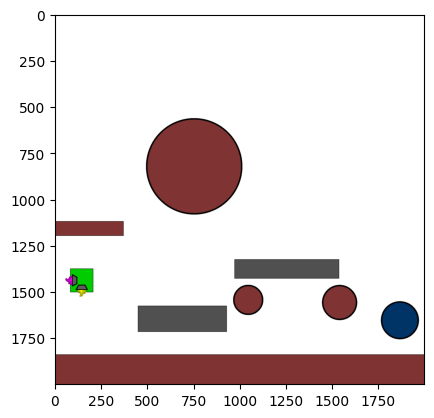
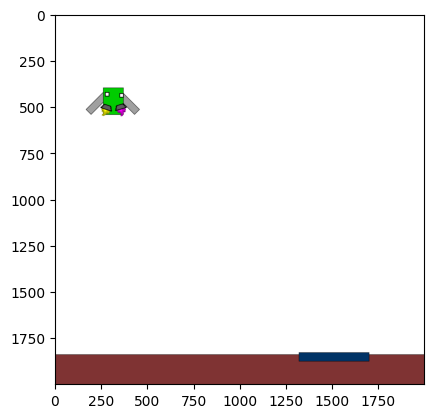
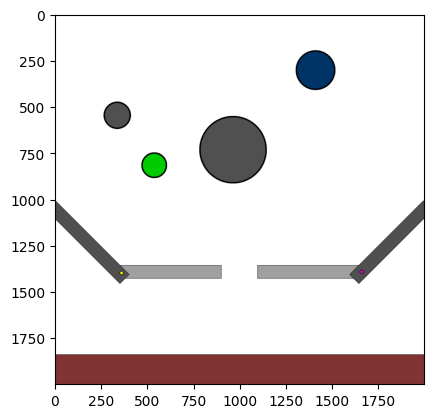
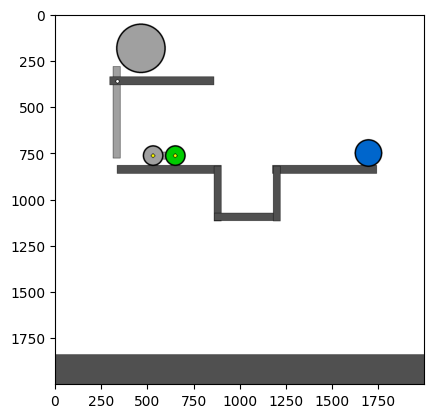
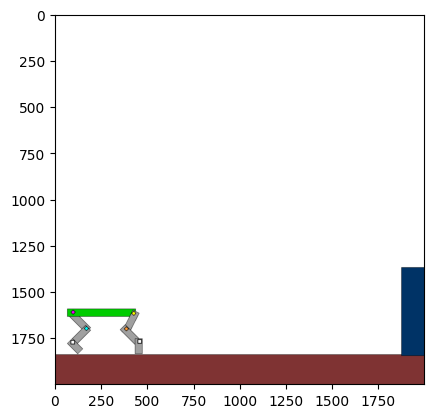
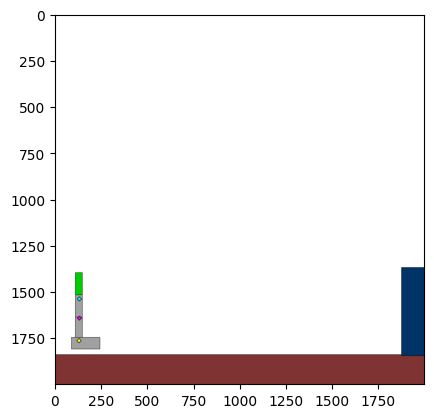
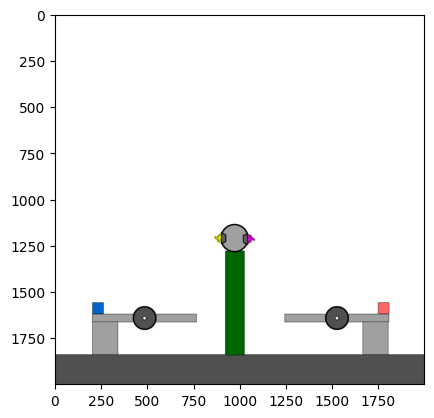
Figure 4: Kinetix Benchmark Observation Space. S-level, M-level, and L-level tasks illustrate increasing physical complexity.
Pooltool results are misleading: models like GPT-4o-mini achieve 100% success by deterministically repeating the same brute-force action, not by strategic cue ball control. No model demonstrates nuanced physical reasoning (e.g., use of spin or planning for next shots), exposing a fundamental lack of billiards physics understanding.


Figure 5: Top-down view of Pooltool, illustrating the simplified observation space for VLMs.
Angry Birds and Cut the Rope
Both environments reveal a dramatic gap between VLMs and humans. Success rates for top models are <40% (Angry Birds) and <27% (Cut the Rope), compared to 65% and 41% for humans, respectively. Models fail at multi-stage planning, chain reaction prediction, and precise timing. Even with annotated props, VLMs struggle with basic perception (e.g., counting ropes), necessitating extensive environment modifications for fair evaluation.

Figure 6: Visual scene of Angry Birds - Level 21 and its corresponding data representation.
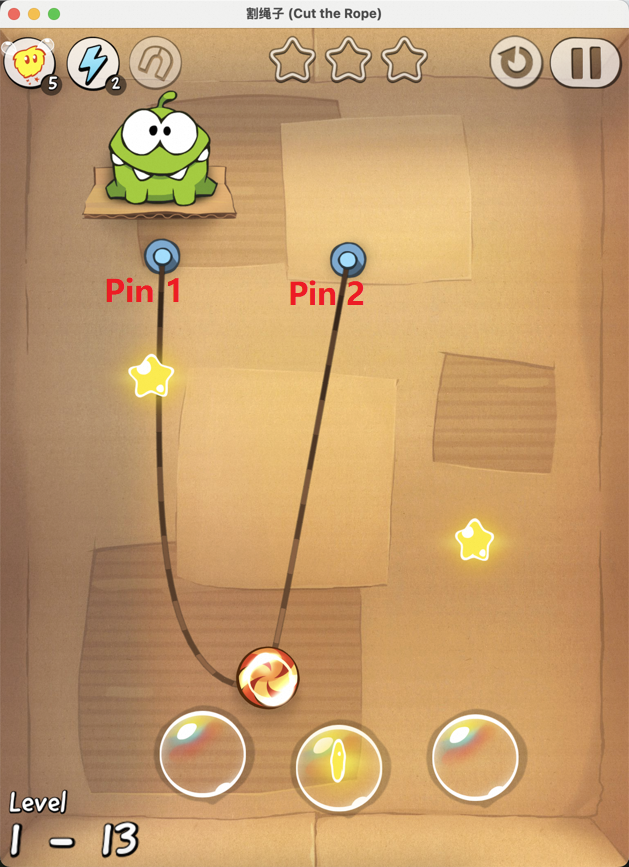
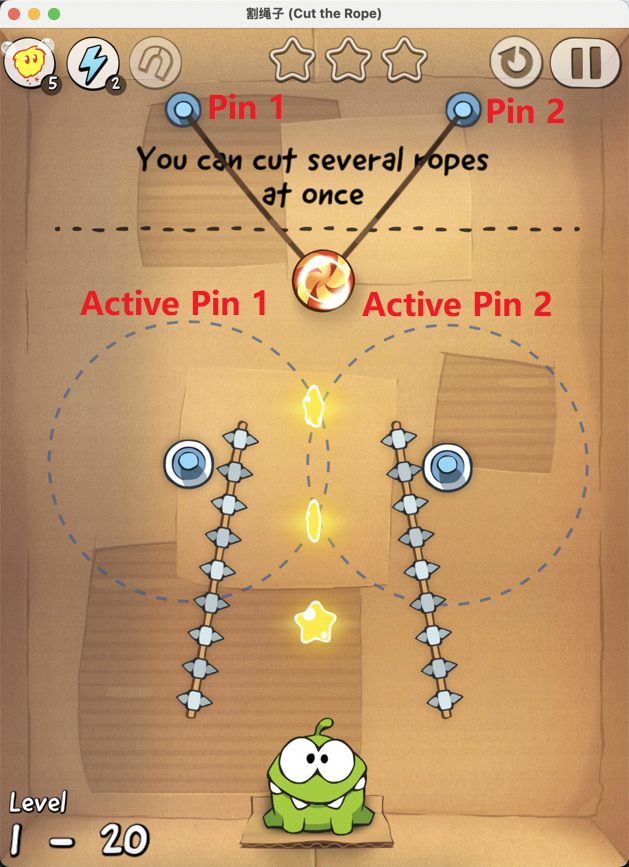
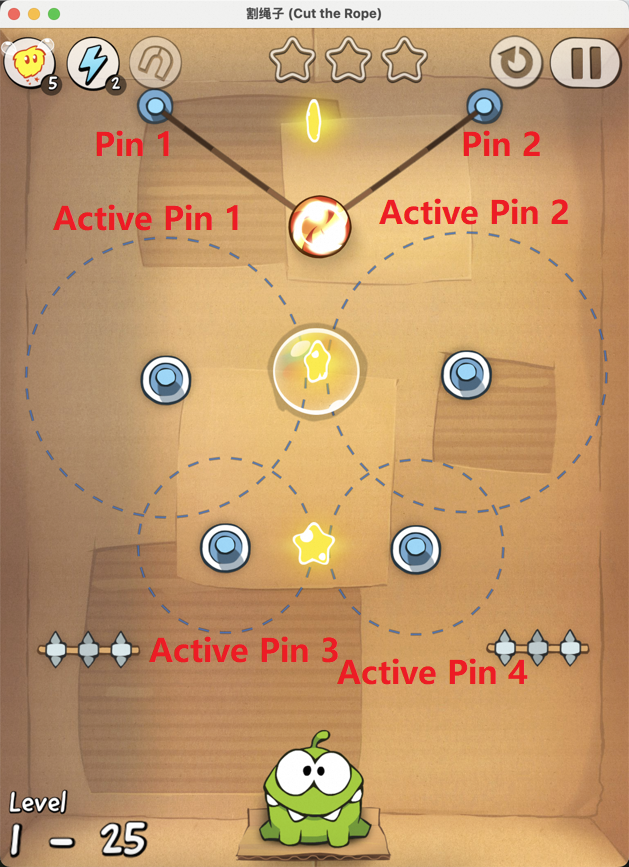
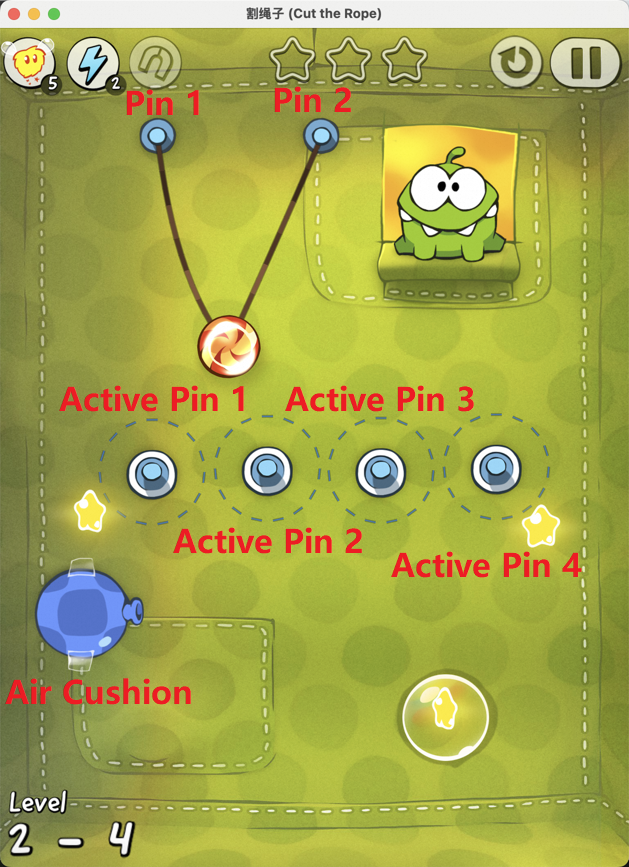
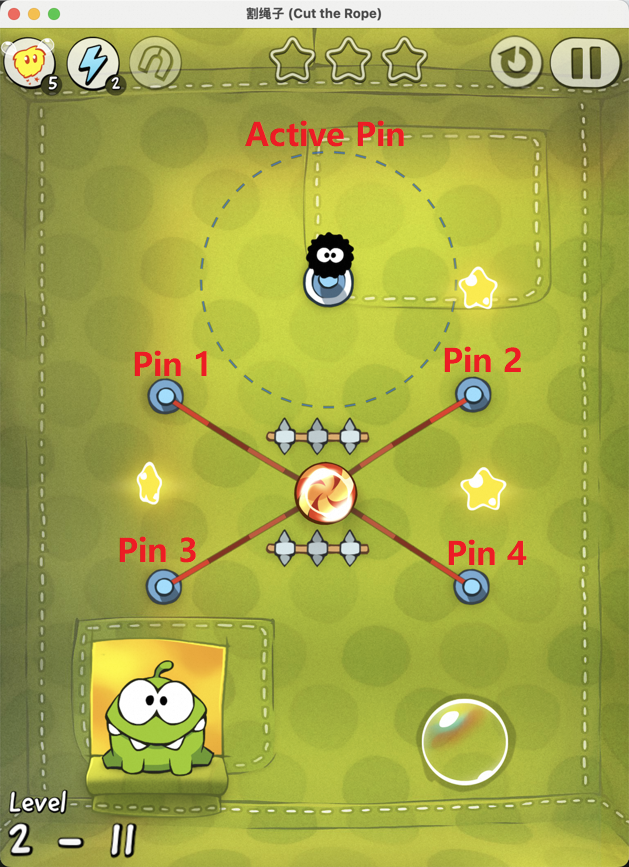
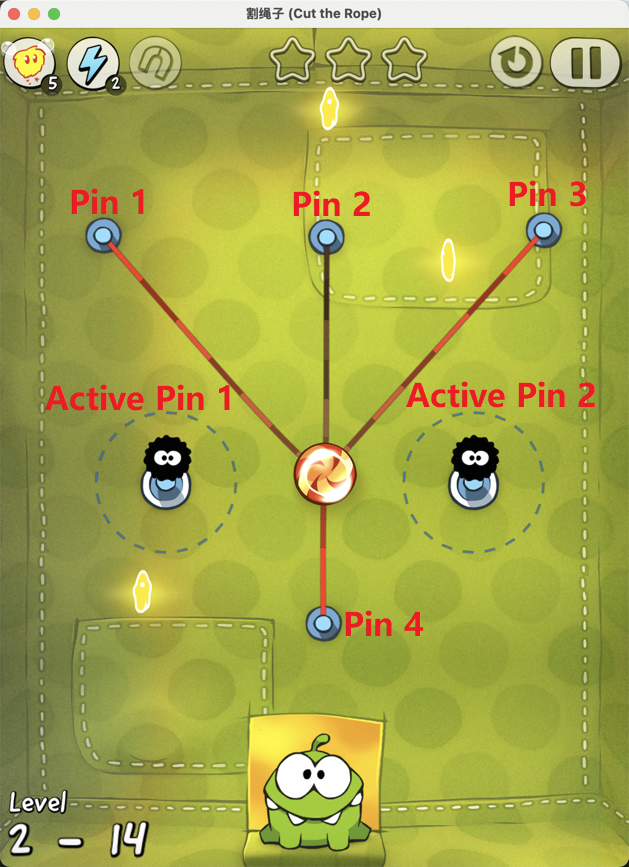

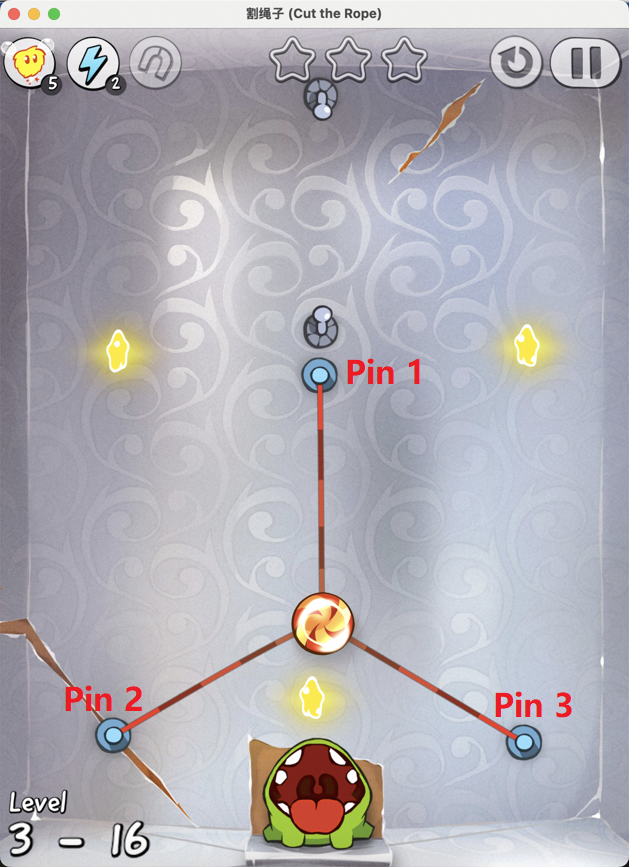

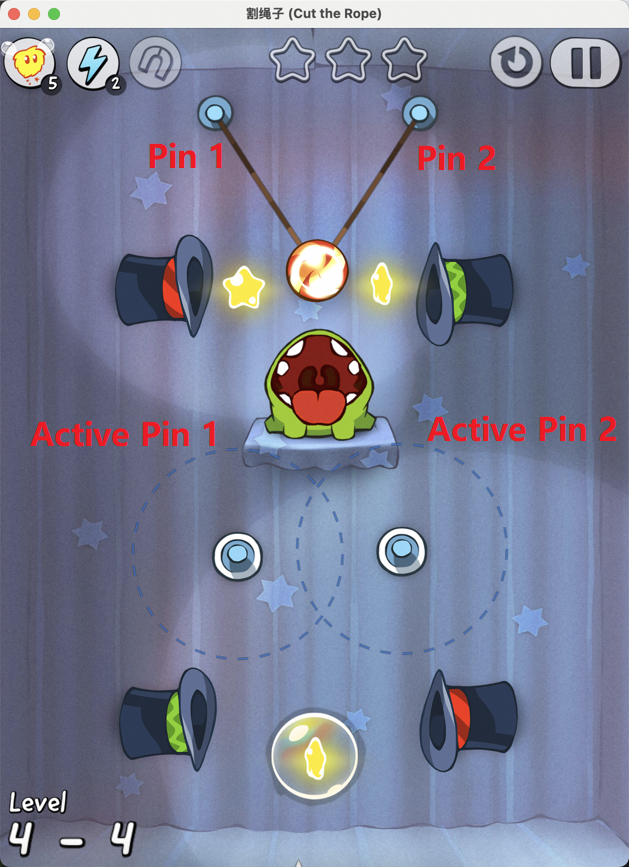

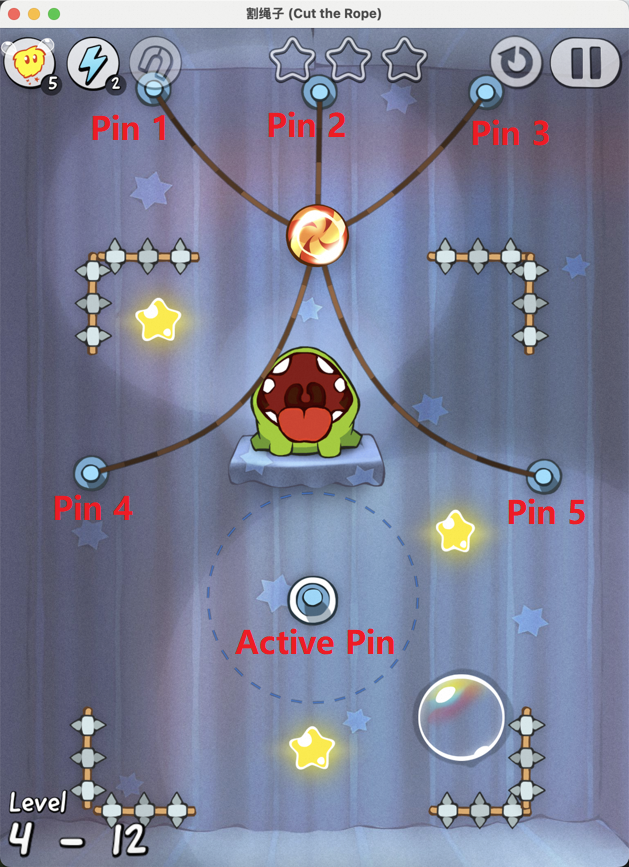
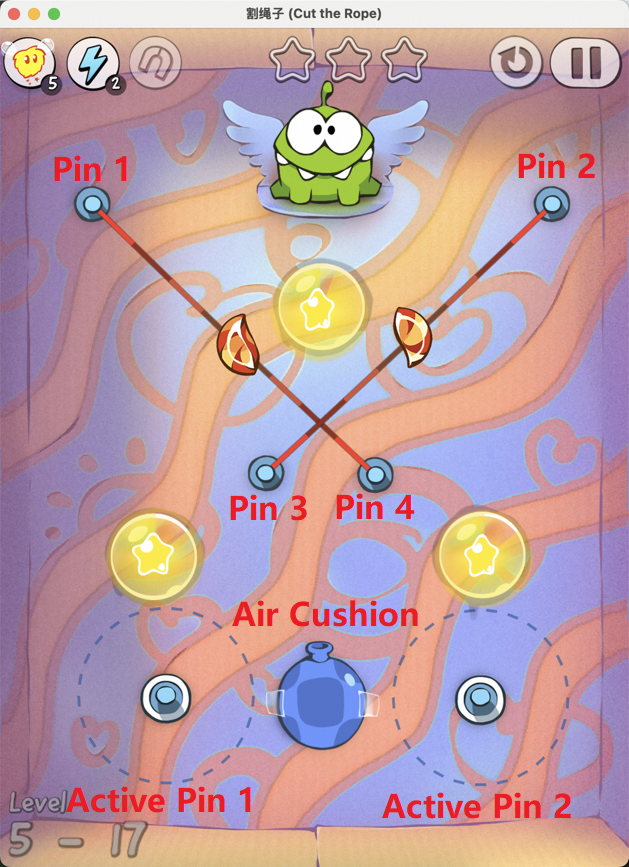
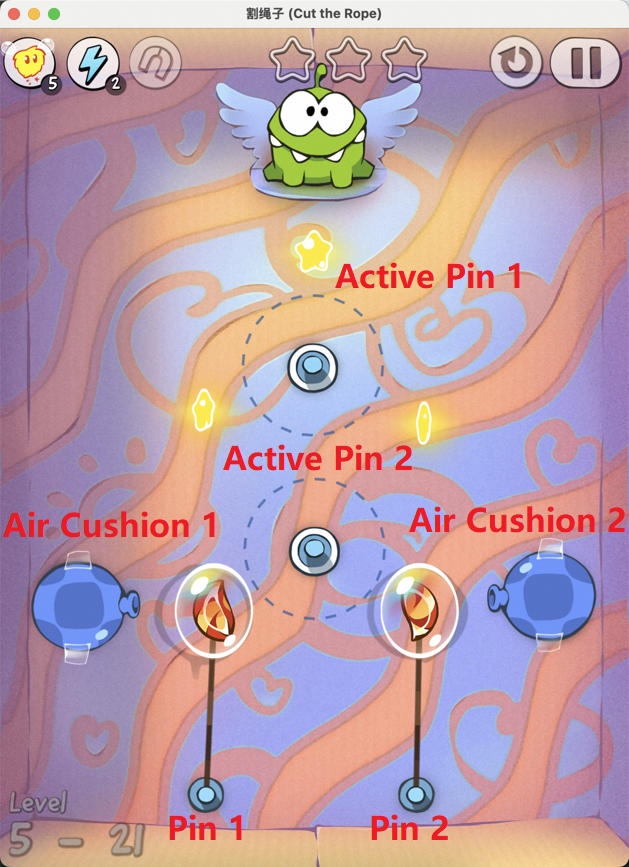
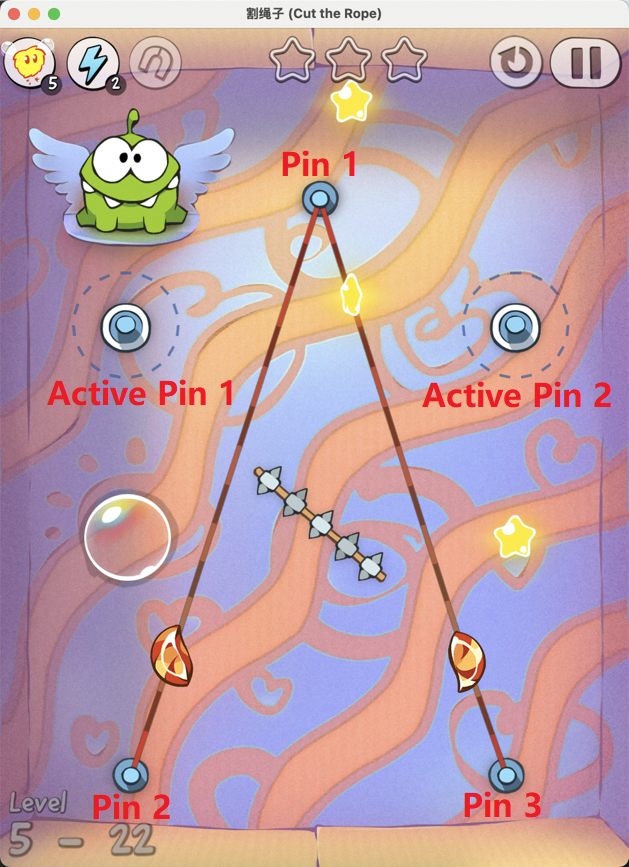
Figure 7: Examples of static element annotation in Cut the Rope, enabling accurate identification of key objects.
Comparative analysis of VLA vs. WM formats reveals that WM offers limited benefits, primarily in simple tasks. In complex environments, WM often degrades performance, indicating that current models' world modeling capabilities are underdeveloped. Descriptive predictions do not translate into improved procedural control; models can describe outcomes but fail to generate effective control signals.

Figure 8: Case study of descriptive physical reasoning in Kinetix—Claude 4.0 Sonnet (WM) generates accurate descriptions but fails at control.
Implications and Future Directions
DeepPHY exposes a fundamental disconnect between descriptive physical knowledge and predictive, controllable reasoning in current VLMs. The benchmark demonstrates that scaling model size and data quality yields incremental improvements, but does not close the gap to human-level physical intelligence. The results suggest that future progress will require advances in:
- Integrated world modeling architectures capable of closed-loop simulation and planning
- Improved perception-action coupling, especially in dynamic, multi-objective environments
- Training regimes emphasizing iterative feedback, causal reasoning, and long-horizon adaptation
- Benchmarks and environments that probe not just descriptive understanding, but procedural and predictive control
The release of DeepPHY provides a standardized, rigorous testbed for evaluating and developing physically grounded AI agents, facilitating progress toward robust embodied intelligence.
Conclusion
DeepPHY establishes a new standard for benchmarking agentic VLMs in physical reasoning. The systematic evaluation across diverse environments reveals persistent limitations in multi-step planning, dynamic adaptation, and procedural control. The benchmark highlights the need for models that move beyond descriptive knowledge to true predictive and interactive physical intelligence, setting a clear agenda for future research in embodied AI.

